
摘要
随着大语言模型和AI技术的快速发展,RAG(检索增强生成)技术已成为企业智能化应用的核心驱动力。openGauss作为国产开源数据库,通过其强大的向量数据库能力和一体化解决方案,正在帮助越来越多的企业实现AI应用的快速落地。本文将深入介绍openGauss数据库的技术优势,并通过钉钉AI一体机的实践案例,展示openGauss如何赋能企业级RAG应用。
一、openGauss数据库:企业级AI应用的坚实底座
1.1 什么是openGauss
openGauss是一款开源的企业级关系型数据库,由华为主导开发并贡献给开源社区。作为一款面向企业核心业务场景的数据库系统,openGauss在性能、可靠性、安全性等方面都达到了业界领先水平。
从3.1.0版本开始,openGauss原生支持向量数据类型和向量检索功能,并通过DataVec向量数据库组件,实现了传统关系型数据库与向量数据库的深度融合,为RAG等AI应用场景提供了一站式的数据管理解决方案。
1.2 openGauss向量数据库的核心优势
优势一:一体化架构,降低运维复杂度
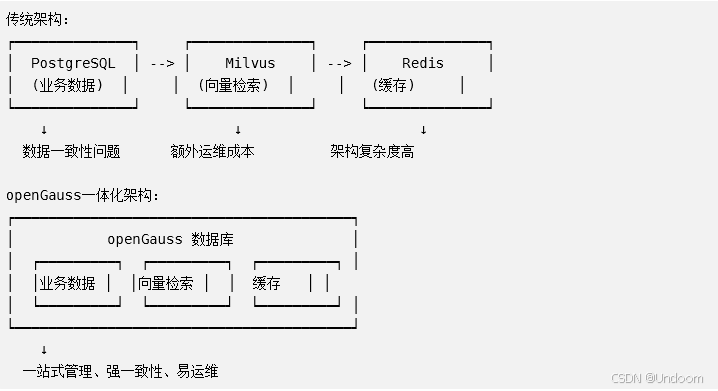
传统的RAG应用架构通常需要组合多个数据库:
- 关系型数据库:存储业务数据、用户信息
- 向量数据库:存储文档向量、执行语义检索
- 缓存系统:提升查询性能
这种多数据库架构带来了数据一致性、系统运维、成本控制等诸多挑战。
openGauss通过一体化设计,在单一数据库中同时支持: - TP场景:传统事务处理,完整的ACID支持
- 向量检索:高性能的语义搜索能力
- 混合查询:向量检索与SQL的无缝结合

这种一体化架构可以降低60%的运维成本 ,同时保证数据的强一致性。
优势二:原生鲲鹏算力优化,性能卓越
openGauss在鲲鹏算力底座上进行了深度优化:
- NUMA绑核技术:充分利用多核处理器的并行能力
- CASAL原子指令:优化内存操作性能
- NEON和SVE指令加速 :对向量数据进行SIMD并行处理
基于这些优化,openGauss+DataVec方案在鲲鹏平台上实现了: - 亿级数据库10毫秒召回能力
- 响应时间和吞吐率比其他竞品性能高10%以上
- 混合PQ精度量化提升20%搜索速度
优势三:企业级特性完备

优势四:社区活跃,生态完善
openGauss拥有活跃的开源社区,社区支撑力度超过同类竞品:
- 定期版本更新和特性增强
- 完善的技术文档和最佳实践
- 专业的技术支持团队
- 丰富的工具链和生态集成
1.3 向量数据库技术原理
openGauss支持两种主流的向量索引算法:
IVFFlat(倒排文件索引)

HNSW(分层导航小世界图)


二、RAG应用架构与openGauss的价值
2.1 RAG技术架构
RAG(检索增强生成)是一种将外部知识库与大语言模型相结合的技术架构:
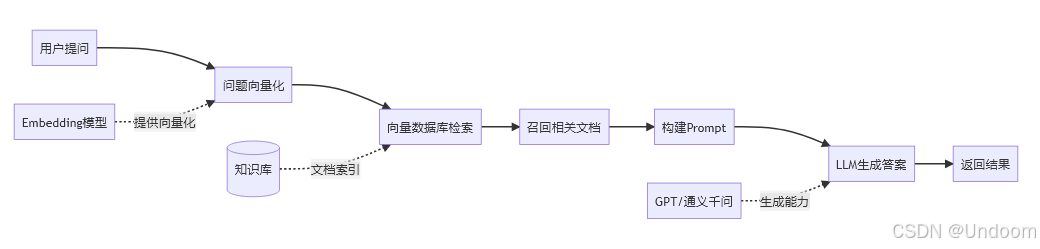
2.2 RAG工作流程详解
bash
"""
完整的RAG查询流程示例
"""
def rag_query_pipeline(question: str, db_conn):
"""
RAG查询管道
Args:
question: 用户问题
db_conn: openGauss数据库连接
"""
# 步骤1: 问题向量化
question_embedding = get_embedding(question)
# 步骤2: 向量检索(在openGauss中执行)
cursor = db_conn.cursor()
cursor.execute("""
SELECT id, title, content,
1 - (embedding <=> %s::vector) as similarity
FROM knowledge_base
WHERE category = 'faq' -- 可选的过滤条件
ORDER BY embedding <=> %s::vector
LIMIT 5
""", (question_embedding, question_embedding))
relevant_docs = cursor.fetchall()
# 步骤3: 构建上下文
context = "\n\n".join([
f"参考文档{i+1}:{doc['title']}\n{doc['content']}"
for i, doc in enumerate(relevant_docs)
])
# 步骤4: 构建Prompt并调用LLM
prompt = f"""
请基于以下参考文档回答用户问题:
{context}
用户问题:{question}
请提供准确、专业的回答:
"""
answer = call_llm(prompt)
# 步骤5: 返回结果(带来源)
return {
"answer": answer,
"sources": [doc['title'] for doc in relevant_docs],
"similarity_scores": [doc['similarity'] for doc in relevant_docs]
}2.3 openGauss在RAG中的独特价值
三、钉钉AI一体机:openGauss实践案例深度解析

3.1 案例背景
钉钉(中国)有限公司作为阿里巴巴旗下的企业协同办公平台,为超过2000万家企业提供服务。为了为企业客户提供专属的AI助理能力,钉钉推出了AI一体机解决方案,该方案采用了openGauss+DataVec一体化数据库架构。
3.2 业务挑战
钉钉AI一体机面临的核心挑战包括:
- 部署复杂度高:传统方案需要部署多个数据库和中间件
- 性能要求严格:需要支持亿级数据的毫秒级召回
- 运维成本高:企业级客户对系统稳定性要求极高
- 国产化要求:需要满足国产化替代和信创要求
3.3 技术方案架构
钉钉AI一体机采用全栈国产化架构,核心组件如下:
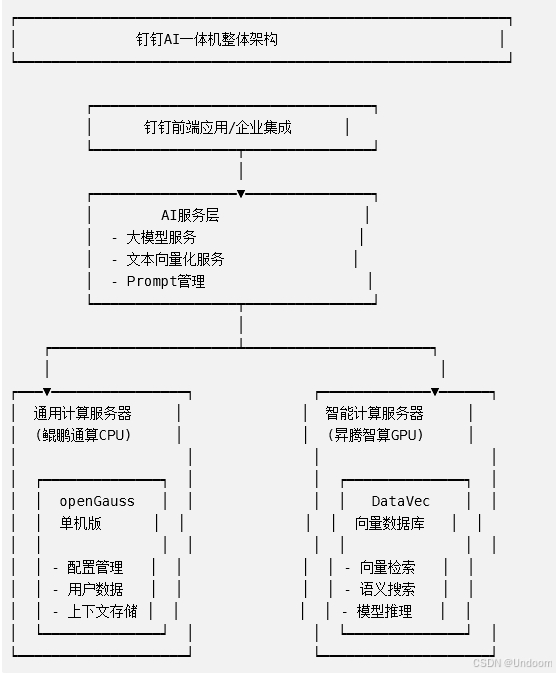
架构特点说明:
- 通用计算层:采用openGauss数据库单机版,负责存储配置信息、管理对话上下文、用户数据等结构化信息
- 智能计算层:充分发挥DataVec向量数据库能力,利用昇腾智算GPU进行大规模向量检索和模型推理
- 一体化集成:两层架构通过标准接口无缝对接,对上层应用透明
3.4 核心应用场景
(1) 一体化数据管理
openGauss + DataVec提供了一体化的数据管理解决方案:
bash
-- 在openGauss中创建知识库表
CREATE TABLE enterprise_knowledge (
id SERIAL PRIMARY KEY,
doc_id VARCHAR(64) UNIQUE NOT NULL,
title VARCHAR(500),
content TEXT,
-- 向量字段(支持多种维度)
embedding_384 vector(384), -- MiniLM模型
embedding_768 vector(768), -- BGE模型
embedding_1536 vector(1536), -- OpenAI模型
-- 业务字段
department VARCHAR(100),
category VARCHAR(50),
access_level INTEGER, -- 访问权限等级
-- 元数据
metadata JSONB,
created_by VARCHAR(64),
created_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP,
updated_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
);
-- 创建向量索引
CREATE INDEX idx_knowledge_hnsw ON enterprise_knowledge
USING hnsw (embedding_768 vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
-- 创建复合索引
CREATE INDEX idx_knowledge_dept_cat ON enterprise_knowledge(department, category);
同一个数据库即可解决TP数据存取场景,又可以实现训推场景,大大简化了应用部署和运维措施。
(2) 高性能向量检索
基于鲲鹏+昇腾的全栈GCH底座,openGauss实现了卓越的检索性能:
bash
"""
钉钉AI助手检索示例
"""
import psycopg2
import numpy as np
def ai_assistant_search(question: str, user_dept: str, db_config: dict):
"""
钉钉AI助手知识检索
Args:
question: 用户问题
user_dept: 用户部门(用于权限过滤)
db_config: 数据库配置
Returns:
相关知识列表
"""
# 连接openGauss数据库
conn = psycopg2.connect(**db_config)
cursor = conn.cursor()
# 1. 问题向量化(调用embedding服务)
question_vector = get_embedding_vector(question)
vector_str = '[' + ','.join(map(str, question_vector)) + ']'
# 2. 执行混合检索
query = """
SELECT
doc_id,
title,
content,
category,
1 - (embedding_768 <=> %s::vector) as similarity,
metadata->>'tags' as tags
FROM enterprise_knowledge
WHERE
-- 权限控制:只检索用户有权访问的文档
department = %s OR access_level = 0
-- 最近一年的文档
AND created_at > CURRENT_DATE - INTERVAL '1 year'
ORDER BY embedding_768 <=> %s::vector
LIMIT 5
"""
cursor.execute(query, (vector_str, user_dept, vector_str))
results = cursor.fetchall()
cursor.close()
conn.close()
return [
{
'doc_id': row[0],
'title': row[1],
'content': row[2][:300], # 截取前300字
'category': row[3],
'similarity': float(row[4]),
'tags': row[5]
}
for row in results
]
# 性能指标
# - 检索延迟: 10ms (亿级数据)
# - 吞吐量: 10000+ QPS
# - 召回准确率: 95%+(3) 原地更新与PQ量化压缩
钉钉案例中采用的技术创新:
技术优势总结:
- 采用原地更新技术,避免了传统向量库的删除-插入流程
- PQ量化压缩技术,大幅降低存储和内存占用
- 保证在高并发下IOPS平稳,无性能抖动
3.5 实施效果与价值
钉钉AI一体机基于openGauss+DataVec方案,取得了显著的业务成果: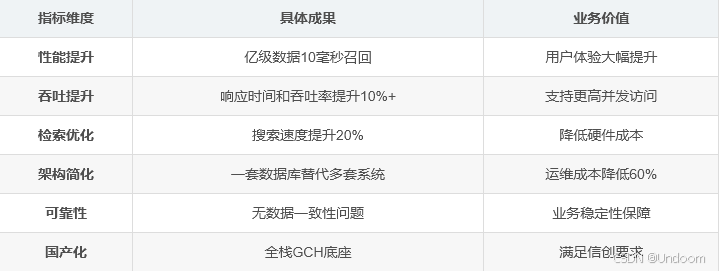
3.6 技术创新点
钉钉案例中的技术创新值得关注:
1. 鲲鹏算力深度优化 
2. 社区支撑力度强
openGauss开源社区的支撑力度超过竞品,在降低AI一体机开发成本的同时,能保证高质量交付且简单运维。钉钉团队与openGauss社区保持紧密合作,在向量数据库技术上进行了联合调优。
3. 客户侧联合测试
openGauss社区支撑钉钉AI一体机在客户侧进行联合测试,确保方案的可靠性和适用性,这种深度合作模式为其他企业提供了良好的参考。
四、实践建议与最佳实践
4.1 技术选型建议
适合选择openGauss的场景 :
✅ 企业级应用,对数据一致性要求高
✅ 需要将向量检索与业务数据深度结合
✅ 希望降低系统复杂度和运维成本
✅ 有国产化、信创要求的项目
✅ 需要企业级的安全、权限、审计能力技术参数推荐配置 :

4.2 部署运维建议

4.3 性能优化技巧
bash
"""
性能优化最佳实践
"""
# 1. 批量插入优化
def batch_insert_vectors(docs, batch_size=100):
"""使用批量插入,比单条插入快10倍"""
for i in range(0, len(docs), batch_size):
batch = docs[i:i+batch_size]
cursor.executemany("""
INSERT INTO knowledge_base (title, content, embedding)
VALUES (%s, %s, %s::vector)
""", batch)
conn.commit()
# 2. 连接池管理
from psycopg2.pool import SimpleConnectionPool
pool = SimpleConnectionPool(
minconn=5,
maxconn=20,
**db_config
)
# 3. 查询结果缓存
from functools import lru_cache
@lru_cache(maxsize=1000)
def cached_search(query_hash, top_k):
"""缓存热门查询结果"""
return execute_vector_search(query_hash, top_k)
# 4. 异步处理
import asyncio
import asyncpg
async def async_vector_search(question):
"""异步查询,提升并发能力"""
pool = await asyncpg.create_pool(**db_config)
async with pool.acquire() as conn:
results = await conn.fetch(query_sql, question_vector)
return results