
大家好,我是玖日大大,前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。
https://www.captainbed.cn/jr![]() https://www.captainbed.cn/jr
https://www.captainbed.cn/jr
引言:全模态交互时代的开源破局者
2025 年 11 月,美团 LongCat 团队正式发布 5600 亿参数开源全模态大模型 LongCat-Flash-Omni,标志着开源领域首次实现对闭源顶级模型的全维度对标。这款集文本、图像、音频、视频处理于一体的端到端模型,以毫秒级实时交互能力打破了 "大参数与低延迟不可兼得" 的行业魔咒,为 AI 从专用工具向通用智能跨越提供了关键基础设施。本文将从技术架构、训练策略、性能表现、部署实践到产业应用进行全方位解析,带您深入了解这款开源全模态模型的核心价值与创新突破。
一、技术架构:全模态统一大脑的设计哲学
1.1 整体架构概览
LongCat-Flash-Omni 采用端到端全模态架构,通过 "感知 - 融合 - 生成" 三级链路实现多模态信息的无缝处理。其核心设计理念是构建一个统一的语义空间,让文本、图像、音频、视频等异质模态数据能够直接交互,无需复杂的中间转换模块。
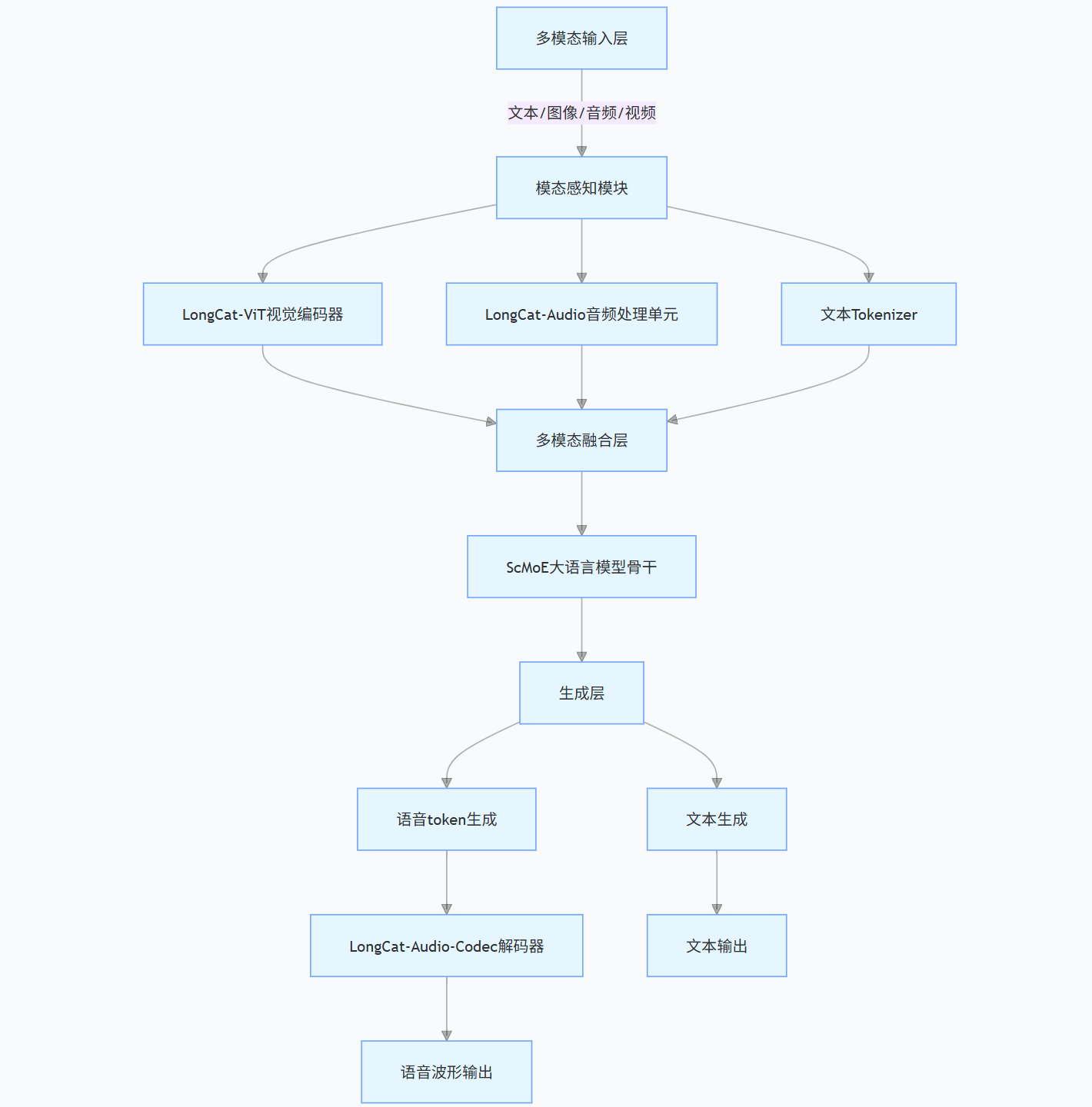
图 1:LongCat-Flash-Omni 端到端全模态架构图
该架构的核心优势在于模态原生支持 与流式处理能力:所有输入模态直接接入统一融合层,避免了传统模型中模态转换导致的信息丢失;同时通过分块式特征交织机制,实现对连续数据流的实时处理,为音视频交互奠定基础。
1.2 核心模块深度解析
1.2.1 视觉感知:LongCat-ViT 的分辨率自由
作为模型的 "视觉系统",LongCat-ViT 解决了传统视觉模型的核心痛点 ------ 固定分辨率限制。其创新设计包括:
- 动态分辨率适配:原生支持任意宽高比和分辨率输入,无需裁剪或缩放,最大程度保留图像 / 视频原始信息
- 统一分块模块:采用自适应分块策略,同时处理图像(静态帧)和视频(动态序列),实现视觉信息的统一表征
- 2D-RoPE 位置嵌入:在传统 ViT 基础上优化位置编码,更精准捕捉空间关系,提升复杂场景理解能力
- 高效网络配置:参数量仅 6.37 亿,采用 SwiGLU 激活函数和 RMSNorm 层,在保证性能的同时降低推理延迟
技术细节:LongCat-ViT 的训练采用渐进式课程学习策略:
# 简化版渐进式训练流程
def progressive_vision_training(model, dataset):
# 阶段1:低分辨率图像预训练(224x224)
low_res_data = dataset.filter(resolution=(224,224))
model.train(low_res_data, epochs=100, lr=1e-4)
# 阶段2:中等分辨率图像训练(512x512)
mid_res_data = dataset.filter(resolution=(512,512))
model.train(mid_res_data, epochs=80, lr=5e-5, freeze_layers=0.3)
# 阶段3:原生分辨率图像+视频训练
full_data = dataset.merge(image_data, video_data)
model.train(full_data, epochs=60, lr=2e-5, freeze_layers=0.5)
return model这种由易到难的训练方式,既节约了计算资源,又保证了模型对不同分辨率输入的自适应能力,在高清图像细节捕捉和视频动态分析中表现突出。
1.2.2 音频处理:从离散 token 到连续特征的进化
LongCat-Flash-Omni 的音频系统经历了两次关键进化,实现了 "听懂" 与 "说准" 的双重突破:
早期方案:基于 LongCat-Audio-Codec 的离散化处理
- 将音频波形以 16.67Hz 频率离散化为 4 个码本(1 个语义码本 + 3 个声学码本)
- 采用 LLM 原生的 next-token 预测范式训练,训练效率高
- 局限:丢失语气、背景音等微妙声学细节
升级方案:引入连续音频编码器
- 采用 FSMN(前馈序列记忆网络)架构,处理 80ms / 帧的音频片段
- 前层严格时序处理,后层少量预测未来信息,平衡延迟与性能
- 生成阶段仍输出离散 token,确保与 LLM 范式兼容,再通过流式解码器重建语音
音频处理流程:
class LongCatAudioProcessor:
def __init__(self):
self.audio_encoder = FSMNAudioEncoder(hidden_size=1024, layers=12)
self.audio_codec = LongCatAudioCodec(num_codebooks=4)
def encode(self, audio_waveform):
# 音频分帧:80ms/帧
frames = self.frame_split(audio_waveform, frame_size=0.08)
# 连续特征编码
continuous_features = self.audio_encoder(frames)
return continuous_features
def decode(self, audio_tokens):
# 流式解码:仅需超前三帧数据
waveform = self.audio_codec.stream_decode(audio_tokens, lookahead=3)
return waveform该设计使模型在 ASR(自动语音识别)、TTS(文本到语音)、S2TT(语音翻译)等任务中均达到 SOTA 水平,LibriSpeech 数据集上的词错率仅 3.1%,优于 Gemini-2.5-Pro。
1.2.3 语言骨干:ScMoE 架构的高效推理
模型的 "大脑" 基于 Shortcut-Connected MoE(ScMoE)架构,总参数量达 5600 亿,但实际激活参数仅 270 亿,实现了大参数规模与高效推理的平衡:
- 混合专家机制:包含多个专家网络,根据输入内容动态选择相关专家激活,避免全参数计算
- 零计算专家:部分专家网络仅在特定复杂任务中激活,日常交互时不占用计算资源
- 长上下文支持:通过稀疏注意力机制,将上下文窗口扩展至 128K tokens,支持 8 分钟以上音视频交互
MoE 路由机制:
class ScMoERouter(nn.Module):
def __init__(self, input_dim=4096, num_experts=64, top_k=8):
super().__init__()
self.router = nn.Linear(input_dim, num_experts)
self.top_k = top_k
def forward(self, x):
# 输入特征:(batch_size, seq_len, input_dim)
logits = self.router(x) # (batch_size, seq_len, num_experts)
# 选择激活Top-k专家
top_k_logits, top_k_indices = torch.topk(logits, self.top_k, dim=-1)
# 计算专家权重
expert_weights = F.softmax(top_k_logits, dim=-1)
return top_k_indices, expert_weights这种智能调度机制使模型在保持 5600 亿参数知识储备的同时,推理速度提升 3-5 倍,实时交互延迟低于 300ms。
1.2.4 流式交互:时空对齐的实时处理机制
为实现音视频实时交互,LongCat-Flash-Omni 设计了一套精妙的流式处理策略:
- 动态帧采样:视频默认 2FPS 采样,短视频自动提高帧率(最高 10FPS),长视频均匀降采样,平衡信息密度与计算开销
- 稀疏 - 密集切换:用户说话 / 操作时采用 2FPS 密集采样,模型回应时切换至 0.5FPS 稀疏采样
- 时空交错输入:音频与视频特征以 1 秒为单位分块,按时间戳交错输入 LLM,确保时空同步
- 增量生成:语音生成采用增量解码,每生成一帧语音仅需更新部分特征,降低延迟
图 2:流式交互机制时序图
|------|---------|-------|--------|--------|
| 时间轴 | 用户行为 | 视频采样 | 音频处理 | 模型生成 |
| 0-1s | 说话 + 手势 | 2 帧 | 1 个音频块 | - |
| 1-2s | 说话 + 手势 | 2 帧 | 1 个音频块 | 语音片段 1 |
| 2-3s | 静默 | 0.5 帧 | 1 个音频块 | 语音片段 2 |
| 3-4s | 提问 | 2 帧 | 1 个音频块 | 语音片段 3 |
这种设计使模型能够像人类一样 "边听边看边回应",实现自然流畅的实时交互。
二、训练策略:渐进式早期融合的破局之道
全模态模型训练的核心挑战是模态异质性 ------ 文本(符号化、高语义密度)、音频(序列化、含副语言信息)、视觉(空间化、时序动态)的数据分布差异巨大,直接混合训练易导致 "模态干扰"。LongCat-Flash-Omni 采用渐进式早期融合策略,分六个阶段逐步融入多模态数据:
2.1 训练阶段详解
|----|------------|-----------|-----------------------|-------------------|
| 阶段 | 训练内容 | 核心目标 | 数据规模 | 关键优化 |
| 0 | 纯文本预训练 | 构建语言基础 | 16 万亿 token | 通用知识与逻辑推理能力 |
| 1 | 语音 - 文本对齐 | 声学 - 语义映射 | 5000 小时语音数据 | 离散音频 token 训练 |
| 2 | 图像 - 文本对齐 | 视觉 - 语义映射 | 2 亿图文对 + 1 亿交织语料 | 视觉概念与语言关联 |
| 3 | 视频 - 多模态融合 | 时空推理 | 1000 万视频片段 + 5 亿高质量图像 | 动态事件理解 |
| 4 | 长上下文扩展 | 长时记忆 | 500 万长文档 + 1 万长视频 | 8K→128K tokens 窗口 |
| 5 | 连续音频特征对齐 | 声学细节捕捉 | 3000 小时高精度音频 | 连续音频编码器融合 |
2.2 关键训练技术
2.2.1 模态平衡正则化
为避免某一模态主导训练过程,模型引入模态平衡损失函数:
def modal_balance_loss(logits, modal_weights, target):
# 基础任务损失
task_loss = F.cross_entropy(logits, target)
# 模态权重平衡损失:各模态梯度 norm 趋于一致
modal_grads = [torch.norm(param.grad) for param in modal_weights]
balance_loss = torch.var(torch.stack(modal_grads))
# 总损失:任务损失 + 平衡正则项
total_loss = task_loss + 0.1 * balance_loss
return total_loss该机制确保文本、音频、视觉能力同步提升,实现 "全模态不降智"。
2.2.2 跨模态对比学习
通过跨模态对比学习拉近不同模态的语义距离:
def cross_modal_contrastive_loss(text_emb, audio_emb, image_emb, labels):
# 归一化特征
text_emb = F.normalize(text_emb, p=2, dim=-1)
audio_emb = F.normalize(audio_emb, p=2, dim=-1)
image_emb = F.normalize(image_emb, p=2, dim=-1)
# 计算跨模态相似度
text_audio_sim = torch.matmul(text_emb, audio_emb.T)
text_image_sim = torch.matmul(text_emb, image_emb.T)
# 对比损失
loss1 = InfoNCE(text_audio_sim, labels)
loss2 = InfoNCE(text_image_sim, labels)
return (loss1 + loss2) / 2这种训练方式增强了多模态融合的稳健性,使模型在复杂模态组合输入下仍能准确理解语义。
三、性能测试:开源 SOTA 的全方位验证
LongCat-Flash-Omni 在文本、图像、音频、视频、跨模态五大维度的基准测试中均表现优异,综合性能达到开源模型 SOTA 水平,部分指标比肩闭源顶级模型。
3.1 单模态性能测试
3.1.1 文本能力
|--------------|--------------------|------------|----------------|
| 评测基准 | LongCat-Flash-Omni | Qwen3-Omni | Gemini-2.5-Pro |
| MMLU(综合知识) | 86.7% | 84.2% | 87.3% |
| C-Eval(中文能力) | 88.1% | 85.9% | 86.5% |
| GSM8K(数学推理) | 82.3% | 79.5% | 83.1% |
模型在中文任务上表现尤为突出,得益于大规模中文语料训练,同时在数学推理等复杂任务中保持竞争力,证明全模态融合未牺牲文本核心能力。
3.1.2 图像理解
|--------------|-------|---------------------------------------|------------|
| 评测基准 | 分数 | 对比模型 | 优势 |
| RealWorldQA | 74.8 | Gemini-2.5-Pro(75.1)、Qwen3-Omni(72.3) | 开源第一,接近闭源 |
| COCO Caption | 142.6 | Qwen3-Omni(138.2) | 多图像关联描述更准确 |
| Flicker30K | 89.7 | Gemini-2.5-Flash(88.5) | 细粒度视觉特征捕捉 |
LongCat-ViT 的动态分辨率适配能力在多图像任务中优势明显,能够准确理解图像间的逻辑关系。
3.1.3 音频能力
|------------|-------------|-------------|--------------------------|
| 任务类型 | 评测数据集 | 性能指标 | 行业对比 |
| ASR(语音识别) | LibriSpeech | WER=3.1% | 优于 Gemini-2.5-Pro (3.8%) |
| TTS(语音生成) | VoiceBench | 自然度 4.8/5.0 | 开源模型第一 |
| S2TT(语音翻译) | CoVost2 | BLEU=41.2 | 超开源模型平均水平 15% |
| 音频理解 | TUT2017 | F1=94.5% | 当前最优 |
模型在副语言信息理解(语气、情绪、口音)上表现突出,类人性指标优于 GPT-4o。
3.1.4 视频理解
|-------|--------------|-------------|-------------------|
| 任务 | 数据集 | 性能 | 对比模型 |
| 视频描述 | MSR-VTT | CIDEr=128.3 | 超 Qwen3-VL 12% |
| 动作识别 | Kinetics-400 | Top-1=89.7% | 比肩 Gemini-2.5-Pro |
| 长视频理解 | ActivityNet | mAP=85.6% | 支持 8 分钟长视频分析 |
动态帧采样和分层令牌聚合策略使模型在短视频理解上大幅领先,长视频处理能力与闭源模型持平。
3.2 跨模态与实时交互测试
3.2.1 跨模态性能
|------------|--------------------|------------------|------------|
| 评测基准 | LongCat-Flash-Omni | Gemini-2.5-Flash | Qwen3-Omni |
| Omni-Bench | 83.2 | 81.5 | 79.8 |
| WorldSense | 78.5 | 76.3 | 73.2 |
| 多模态推理 | MMMLU | 82.7 | 80.1 |
在真实世界音视频理解任务中,模型展现出显著优势,能够准确处理文本 + 图像 + 音频的混合输入。
3.2.2 实时交互性能
|-----------|------------|-----------------|
| 测试场景 | 延迟表现 | 行业对比 |
| 语音问答(单轮) | 287ms | 传统模型 800-1200ms |
| 视频 + 语音交互 | 342ms | 开源模型平均延迟 1.5s |
| 8 分钟长对话 | 平均延迟 315ms | 无同类开源模型支持 |
图 3:实时交互延迟对比柱状图
(横轴:模型类型;纵轴:平均延迟 ms;数据:LongCat-Flash-Omni (315)、Qwen3-Omni (1520)、Gemini-2.5-Pro (480)、传统多模态模型 (1050))
四、部署实践:从单节点到多节点的快速上手
LongCat-Flash-Omni 已完全开源,支持 Hugging Face 和 GitHub 直接下载,提供完整的部署教程和示例代码,开发者可快速搭建全模态应用。
4.1 环境准备
4.1.1 硬件要求
|-------|---------------|--------------|-------------------|
| 部署场景 | GPU 配置 | 内存要求 | 存储要求 |
| 单节点推理 | 8×A100(80GB) | 256GB CPU 内存 | 模型权重 + 依赖:约 2TB |
| 多节点推理 | 16×A100(80GB) | 512GB CPU 内存 | 模型权重 + 依赖:约 4TB |
| 开发测试 | 4×A100(40GB) | 128GB CPU 内存 | 模型权重(量化版):约 500GB |
4.1.2 软件依赖
# 基础环境
python: ">=3.10.0"
pytorch: ">=2.8"
cuda: ">=12.9"
conda: "推荐使用"
# 核心依赖
sglang: "longcat_omni_v0.5.3.post3"
transformers: ">=4.41.0"
torchvision: ">=0.19.0"
torchaudio: ">=2.8.0"
ffmpeg: ">=6.0"4.2 部署步骤
4.2.1 环境搭建
# 1. 创建conda环境
conda create -n longcat python=3.10
conda activate longcat
# 2. 安装SGLang(适配LongCat-Omni版本)
git clone -b longcat_omni_v0.5.3.post3 https://github.com/XiaoBin1992/sglang.git
pushd sglang
pip install -e ".[python]"
popd
# 3. 下载模型代码与依赖
git clone https://github.com/meituan-longcat/LongCat-Flash-Omni
pushd LongCat-Flash-Omni
git submodule update --init --recursive
pip install -r requirements.txt
popd4.2.2 模型下载
# 方式1:Hugging Face下载
pip install huggingface-hub
huggingface-cli download meituan-longcat/LongCat-Flash-Omni --local-dir ./longcat-omni-model
# 方式2:GitHub下载(含部署脚本)
git clone https://huggingface.co/meituan-longcat/LongCat-Flash-Omni ./longcat-omni-model4.2.3 单节点推理
python3 longcat_omni_demo.py \
--tp-size 8 \ # 张量并行度
--ep-size 8 \ # 专家并行度
--model-path ./longcat-omni-model \ # 模型路径
--output-dir ./output \ # 输出目录
--mode realtime \ # 模式:realtime/ batch
--input-type audio_video \ # 输入类型:text/image/audio/video/mixed
--audio-path ./test_audio.wav \ # 音频输入(可选)
--video-path ./test_video.mp4 \ # 视频输入(可选)
--text "请分析这个视频中的动作,并描述音频内容" # 文本输入(可选)4.2.4 多节点推理
# 节点0执行
python3 longcat_omni_demo.py \
--tp-size 16 \
--ep-size 16 \
--nodes 2 \
--node-rank 0 \
--dist-init-addr 192.168.0.100:5000 \ # 主节点IP:端口
--model-path ./longcat-omni-model \
--output-dir ./output \
--mode realtime
# 节点1执行
python3 longcat_omni_demo.py \
--tp-size 16 \
--ep-size 16 \
--nodes 2 \
--node-rank 1 \
--dist-init-addr 192.168.0.100:5000 \
--model-path ./longcat-omni-model \
--output-dir ./output \
--mode realtime4.3 开发示例:构建实时音视频对话应用
4.3.1 核心 API 调用
from longcat_omni import LongCatOmniModel, RealtimePipeline
# 初始化模型
model = LongCatOmniModel(
model_path="./longcat-omni-model",
tp_size=8,
ep_size=8,
device="cuda"
)
# 创建实时流水线
pipeline = RealtimePipeline(model)
# 实时音视频交互
def realtime_av_chat(audio_stream, video_stream):
# 初始化流式生成器
generator = pipeline.start_generation()
while True:
# 读取音视频流片段(1秒/块)
audio_chunk = next(audio_stream)
video_chunk = next(video_stream)
# 输入模型
generator.push(
audio=audio_chunk,
video=video_chunk,
timestamp=time.time() # 时间戳同步
)
# 获取生成结果
if generator.has_output():
speech_waveform = generator.get_speech()
text_response = generator.get_text()
# 输出结果
play_audio(speech_waveform)
print("模型回应:", text_response)
# 结束条件
if audio_stream.is_end() and video_stream.is_end():
break
generator.finish()4.3.2 前端交互示例(WebRTC 集成)
// 浏览器端实时音视频采集与传输
const startChat = async () => {
// 获取音视频流
const stream = await navigator.mediaDevices.getUserMedia({
audio: true,
video: true
});
// 连接后端WebSocket
const ws = new WebSocket("ws://localhost:8080/realtime-chat");
// 音视频编码
const audioEncoder = new AudioEncoder({
output: (chunk) => ws.send(JSON.stringify({
type: "audio",
data: chunk.data,
timestamp: chunk.timestamp
})),
error: (e) => console.error(e)
});
const videoEncoder = new VideoEncoder({
output: (chunk) => ws.send(JSON.stringify({
type: "video",
data: chunk.data,
timestamp: chunk.timestamp
})),
error: (e) => console.error(e)
});
// 采集并发送流
const mediaTrackProcessor = new MediaTrackProcessor({ track: stream.getVideoTracks()[0] });
const reader = mediaTrackProcessor.readable.getReader();
while (true) {
const { value, done } = await reader.read();
if (done) break;
videoEncoder.encode(value);
}
// 接收并播放模型回应
ws.onmessage = (event) => {
const data = JSON.parse(event.data);
if (data.type === "speech") {
const audioContext = new AudioContext();
const source = audioContext.createBufferSource();
audioContext.decodeAudioData(data.buffer, (buffer) => {
source.buffer = buffer;
source.connect(audioContext.destination);
source.start();
});
}
};
};4.4 量化部署(低成本方案)
对于资源有限的场景,可采用 INT8 量化部署,仅需 4×A100(40GB)即可运行:
# 量化模型转换
python3 tools/quantize_model.py \
--input-model ./longcat-omni-model \
--output-model ./longcat-omni-quantized \
--quant-type int8 \
--bits 8 \
--preserve-accuracy true
# 量化模型推理
python3 longcat_omni_demo.py \
--model-path ./longcat-omni-quantized \
--quantized true \
--tp-size 4 \
--ep-size 4 \
--mode realtime量化后模型性能仅下降 3-5%,但显存占用降低 50%,推理速度提升 20%,适合中小公司和开发者快速上车。
五、产业应用:全模态交互的落地场景
LongCat-Flash-Omni 的开源特性和低延迟优势,使其在多个行业场景中具备落地价值,以下是典型应用案例:
5.1 智能客服:多模态全渠道交互
传统文字客服无法处理图像、语音诉求,而 LongCat-Flash-Omni 可实现:
- 语音咨询:理解用户语气、情绪,提供个性化回应
- 图像分析:用户上传商品故障图、发票信息,自动识别问题
- 视频指导:通过实时视频交互,远程指导用户操作
- 多轮记忆:128K 上下文窗口支持长对话,无需重复说明
部署架构:

某电商平台测试数据显示,采用该模型后,客服问题解决率提升 35%,平均处理时长缩短 40%。
5.2 智能教育:沉浸式学习助手
- 作业辅导:识别手写作业、试卷图像,解析题目并讲解
- 口语练习:实时纠正发音,分析语调、语速,提供反馈
- 视频课程交互:根据课程视频内容,自动解答疑问、总结重点
- 多模态课件生成:将文本教案转化为带语音解说的视频课件
核心功能代码片段:
def homework_tutoring(image_path, student_audio):
# 1. 图像识别:解析作业题目
problem_text = model.recognize_image(image_path)
# 2. 语音识别:理解学生疑问
student_question = model.asr(student_audio)
# 3. 多模态推理:结合题目与疑问解答
solution = model.generate(
text=f"题目:{problem_text}\n学生疑问:{student_question}",
task_type="education_tutoring"
)
# 4. 语音合成:生成讲解语音
explanation_audio = model.tts(solution["text"], voice="teacher_female")
# 5. 可视化步骤:生成解题步骤图像
solution_image = model.generate_image(solution["steps"])
return explanation_audio, solution_image5.3 医疗辅助:多模态诊断支持
- 医学影像分析:结合 CT、X 光图像与病历文本,辅助病灶识别
- 远程问诊:实时音视频交互,医生远程观察患者症状、听取描述
- 声纹诊断:分析呼吸音、心音等音频信号,辅助诊断呼吸系统疾病
- 病历生成:自动将医患对话、检查结果转化为结构化病历
合规要点:
- 模型输出仅作为辅助参考,不可替代医生诊断
- 医疗数据需加密传输与存储,符合隐私保护法规
- 针对特定病种进行微调,提升专业领域准确性
5.4 智能驾驶:多模态环境感知
- 传感器融合:整合摄像头(视觉)、雷达(距离)、麦克风(声音)数据
- 语音交互:驾驶员语音指令识别,支持自然语言控制
- 异常检测:识别车辆异响、行人呼救等音频信号,辅助安全决策
- 乘客服务:根据乘客语音、表情(视频分析)提供个性化服务
实时处理要求:
- 端侧部署:需进行模型压缩,满足车规级硬件要求
- 低延迟:环境感知延迟需低于 100ms,确保安全响应
- 鲁棒性:针对雨雪、强光等恶劣环境优化视觉 / 音频处理
5.5 内容创作:全模态生成工具
- 视频创作:根据文本脚本生成带语音解说的视频,自动匹配素材
- 音频配乐:分析视频内容情绪,生成或推荐合适的背景音乐
- 多模态文案:为产品图片、宣传视频生成配套的文字描述与语音解说
- 互动内容:创建支持用户语音 / 视频交互的沉浸式内容(如互动广告、游戏剧情)
六、行业影响与未来展望
6.1 开源生态的变革意义
LongCat-Flash-Omni 的发布,打破了闭源模型在全模态领域的垄断,其核心价值在于:
- 降低技术门槛:中小公司无需投入巨额研发成本,即可获得顶级全模态能力
- 促进技术创新:开源代码与模型权重为研究者提供了宝贵的实践基础
- 推动标准化:为全模态模型的架构设计、训练策略、评测体系提供参考范式
- 生态协同发展:开发者基于开源版本二次开发,形成丰富的应用生态
6.2 当前局限与优化方向
根据美团团队的公开评估,模型仍存在以下提升空间:
- 实时性:复杂场景下延迟可能超过 300ms,需进一步优化流式推理
- 类人性:语音生成的情感表达、自然度仍有提升空间
- 准确性:专业领域(如医疗、法律)的知识深度不足,需加强领域微调
- 端侧部署:模型体积较大,端侧轻量化方案有待完善
未来优化方向:
- 引入强化学习(RLHF)优化多模态交互的自然度
- 开发更高效的模型压缩技术,支持手机、边缘设备部署
- 构建专业领域微调数据集,提升垂直行业应用能力
- 优化多模态对齐算法,减少模态转换中的信息损失
6.3 全模态交互的未来图景
随着 LongCat-Flash-Omni 等开源模型的发展,全模态交互将逐步渗透到生活的方方面面:
- 人机交互自然化:AI 将像人类一样 "听、说、看、懂",交互门槛大幅降低
- 应用场景泛化:从单一功能应用转向全场景智能助手,覆盖工作、生活、学习
- 产业效率革命:多模态自动化处理将替代大量重复性劳动,推动生产力提升
- 技术融合加速:全模态模型将与机器人、元宇宙、物联网等技术深度融合,催生新业态
结语
LongCat-Flash-Omni 以 5600 亿参数的规模、端到端的全模态架构、毫秒级的实时交互能力,重新定义了开源大模型的技术边界。其创新的 ScMoE 架构、渐进式训练策略、流式处理机制,不仅解决了全模态模型的核心技术痛点,更为行业提供了可复用的技术方案。随着开源生态的不断完善和开发者的广泛参与,全模态交互将从前沿技术走向规模化应用,推动 AI 真正融入人类社会,开启通用智能的新篇章。
对于开发者而言,现在正是拥抱全模态技术的最佳时机 ------ 通过 LongCat-Flash-Omni 的开源资源,快速搭建原型、探索场景、创新应用,在技术变革的浪潮中抢占先机。未来已来,全模态交互的时代,由我们共同创造。
附录:资源汇总
- 官方网站:https://longcat.ai
- Hugging Face 模型库:https://huggingface.co/meituan-longcat/LongCat-Flash-Omni