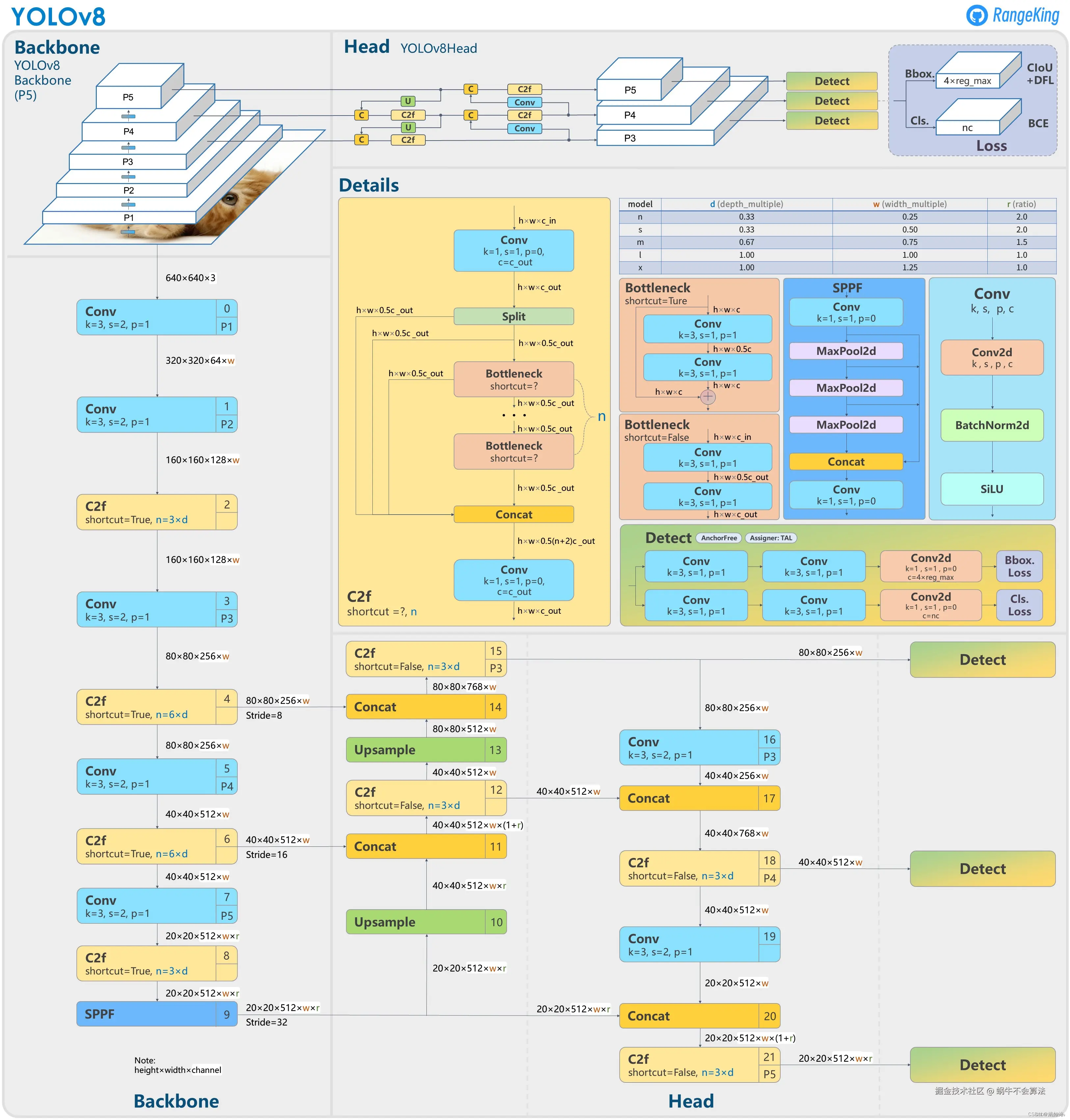
- Backbone :使用的依旧是CSP的思想,不过YOLOv5中的C3模块被替换成了C2f模块,实现了进一步的轻量化,同时YOLOv8依旧使用了YOLOv5等架构中使用的SPPF模块;
- PAN-FPN:毫无疑问YOLOv8依旧使用了PAN的思想,不过通过对比YOLOv5与YOLOv8的结构图可以看到,YOLOv8将YOLOv5中PAN-FPN上采样阶段中的卷积结构删除了,同时也将C3模块替换为了C2f模块;
- Decoupled-Head:是不是嗅到了不一样的味道?是的,YOLOv8走向了Decoupled-Head;
- Anchor-Free :YOLOv8抛弃了以往的Anchor-Base,使用了Anchor-Free的思想;
- 损失函数 :YOLOv8使用VFL Loss作为分类损失,使用DFL Loss+CIOU Loss作为分类损失;
- 样本匹配 :YOLOv8抛弃了以往的IOU匹配或者单边比例的分配方式,而是使用了Task-Aligned Assigner匹配方式。
YOLOv8网络使用的模块:
- 卷积模块:Conv + BatchNorm + SiLU
- 瓶颈模块:减少计算复杂度和参数数量,同时保留模型性能
- C2f模块:高效多分支多特征提取
- 空间金字塔快速(SPPF)模块:捕捉多尺度信息
- 检测模块:边界框检测和类别检测
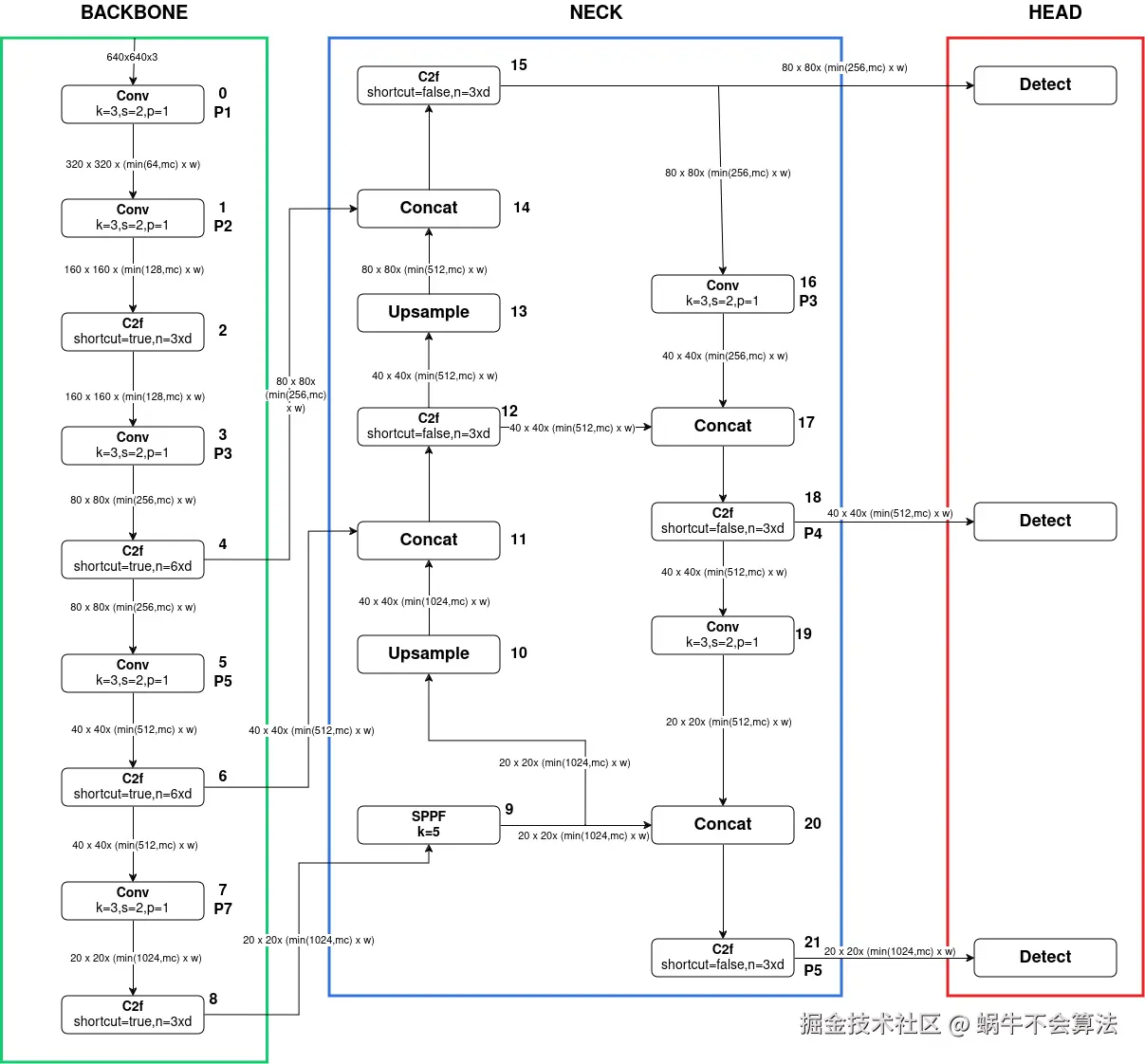
1. Backbone:C2f 高效特征提取模块 (核心创新)
Backbone负责特征提取 。C2f模块是YOLOv8 Backbone的核心,它取代了YOLOv5中的C3模块,在轻量化和梯度流方面表现更优。
1.1 C2f模块结构
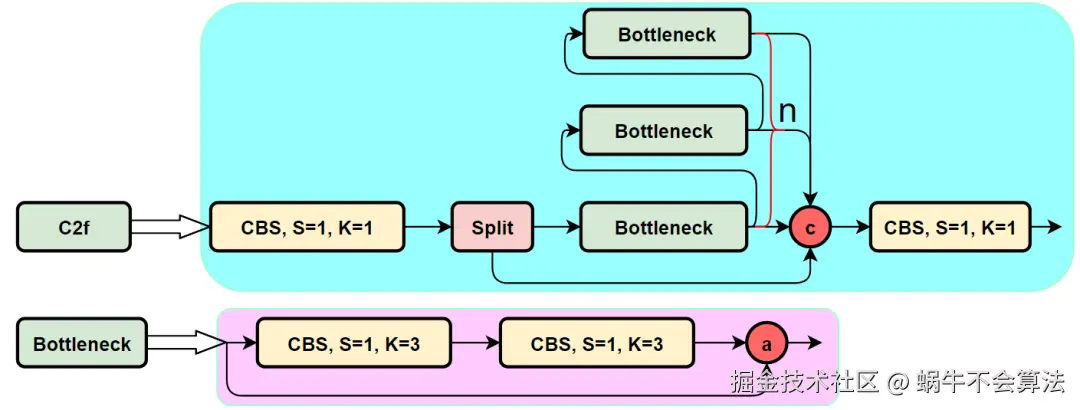
C2f 是 YOLOv8 系列(以及后续一些 YOLO 变体)中引入的一种高效特征提取 模块,名字常被解释为 "C2-fusion" 或 "C2 with better gradient Flow"。它属于 CSP(Cross Stage Partial,跨阶段部分残差连接)家族的改良版本,用来取代 YOLOv5/YOLOv7 风格的 C3 / BottleneckCSP 模块。
通俗说:C2f 是一个"把输入特征拆多路、依次加工、再把所有中间特征拼回来然后压缩融合"的结构。它的目标是:
- 强化梯度流(gradient flow),跳跃连接,缓解梯度消失问题,帮助训练更深的网络;
- 提高特征多样性(多分支、多阶段特征同时保留);
- 降低参数量和计算量(FLOPs),尤其在中小模型里;
- 保持导出友好(ONNX/TensorRT),适合工业部署。
C2f 最常出现的位置是 YOLOv8 的 Backbone(主干)和 Neck(特征融合颈部)中的主堆叠单元。可以把它当成 YOLOv8 的"主力积木块"。
CBS:C = Conv,B = BatchNorm,S = SiLU。也就是:卷积层 (Conv) → 批归一化 (Batch Normalization) → SiLU 激活函数
为什么非要Split?
- 参数共享:两个分支共享底层特征提取
- 特征一致性:来自同一卷积,特征分布相似
- 梯度统一:反向传播时梯度来源一致
结构细节:
js
输入 → 卷积 → 分割为两部分:
分支1: 直接传递(捷径连接)
分支2: 通过 n 个 Bottleneck 堆叠
每个Bottleneck结构:
输入 → Conv1x1(降维) → Conv3x3(特征提取) → Add(残差连接)
融合:分支1 + 分支2 → 卷积输出1.2 C2f内部原理

这个收集中间层输出再统一融合的思想,类似于 ELAN / E-ELAN 家族(YOLOv7 里提出的高效层聚合思想),也类似 DenseNet 的"密集连接"精神:保留每个阶段的中间特征,而不是只拿最后一层。
1.3 C2f设计优势
1.3.1 梯度流动(Gradient Flow)
多分支结构促进梯度反向传播,缓解梯度消失
深层网络训练时,越后面的层越难把梯度有效地传回前面 。如果所有中间特征都在最终 concat 里出现,那么早期的小残差块 (Y₀, Y₁, ...) 对最终输出有"直接话语权",它们的梯度会直接回传,而不会被长链条稀释。
这就像在很长的传话链上,每个人都能直接对老板说话,而不是只能悄悄跟下一个人说,指望消息能一路传到老板耳朵里。 相比之下,传统的层-接-层-接-层结构,最前面几层离最终输出很远,梯度可能在中途衰减。
1.3.2 特征多样性(Multi-scale / Multi-stage Features)
Concat(X_b, Y₀, Y₁, ...) 相当于把不同"深度级别 "的表达并列放在一起:
Y₀ 可能更偏局部/低级纹理; Y₅(比如某个后层)可能更偏高语义/抽象概念; X_b 是几乎未破坏的原始信息通道,保存细节。 模型后续就可以自由在这些"老照片+新照片"的堆叠里挑它想要的特征,而不是被迫只依赖"最新那张照片"。
这跟 DenseNet 的思路很像:把不同深度的特征一起当资源池。
1.3.3 计算效率(Parameter / FLOPs Efficiency)
C2f 利用的是:
- 小瓶颈块(Bottleneck)重复堆叠,而不是每一层都用大胖卷积;
- 1×1 卷积先降维、后融合,减少大通道数下的 3×3 卷积开销;
- 通道分流 + 部分残差,使得不是所有分支都要全算一遍重型操作。
结果:在同等、甚至更高的精度下,C2f 往往能比 YOLOv5 的 C3 模块或 YOLOv4 的 CSPDarknet 模块更省参数、更省算力,尤其是在小中等模型(n/s/m 级别)里性价比明显。
1.4 与 CSP / C3 / ELAN / C3k2 的关系
1.4.1 CSP / CSPDarknet(YOLOv4)
Cross Stage Partial(跨阶段部分残差)思想:把特征分成两路,一路走残差堆叠,另一路保持相对原样,最后再合并。这可减少重复计算,又保持梯度流动。
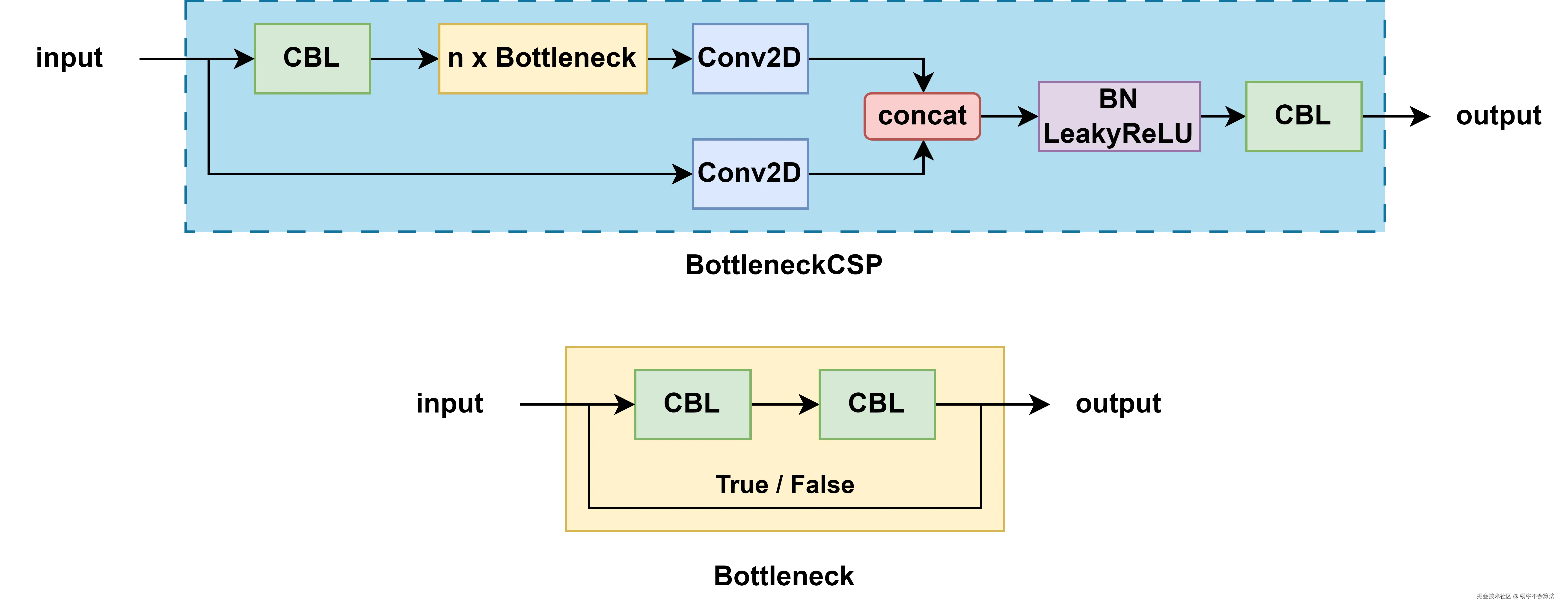 其中的 CBL 模块就是
其中的 CBL 模块就是Conv2D + BN + LeakyReLU 的组合,这里的 bottleneck 可以根据传入的参数决定是否带有 shortcut。如果是带有 shortcut 的话,就是正统的 residual 模块了,如果没有 shortcut,就是单纯的 2 个 CBL 串联。
1.4.2 C3(YOLOv5)
基于 CSP 的 Bottleneck 堆叠;在 PyTorch 化实现里叫 C3,是 YOLOv5 主干/颈部的基本块。它也会做通道分支,但中间特征的保留/聚合方式相对固定,聚合点更单一。
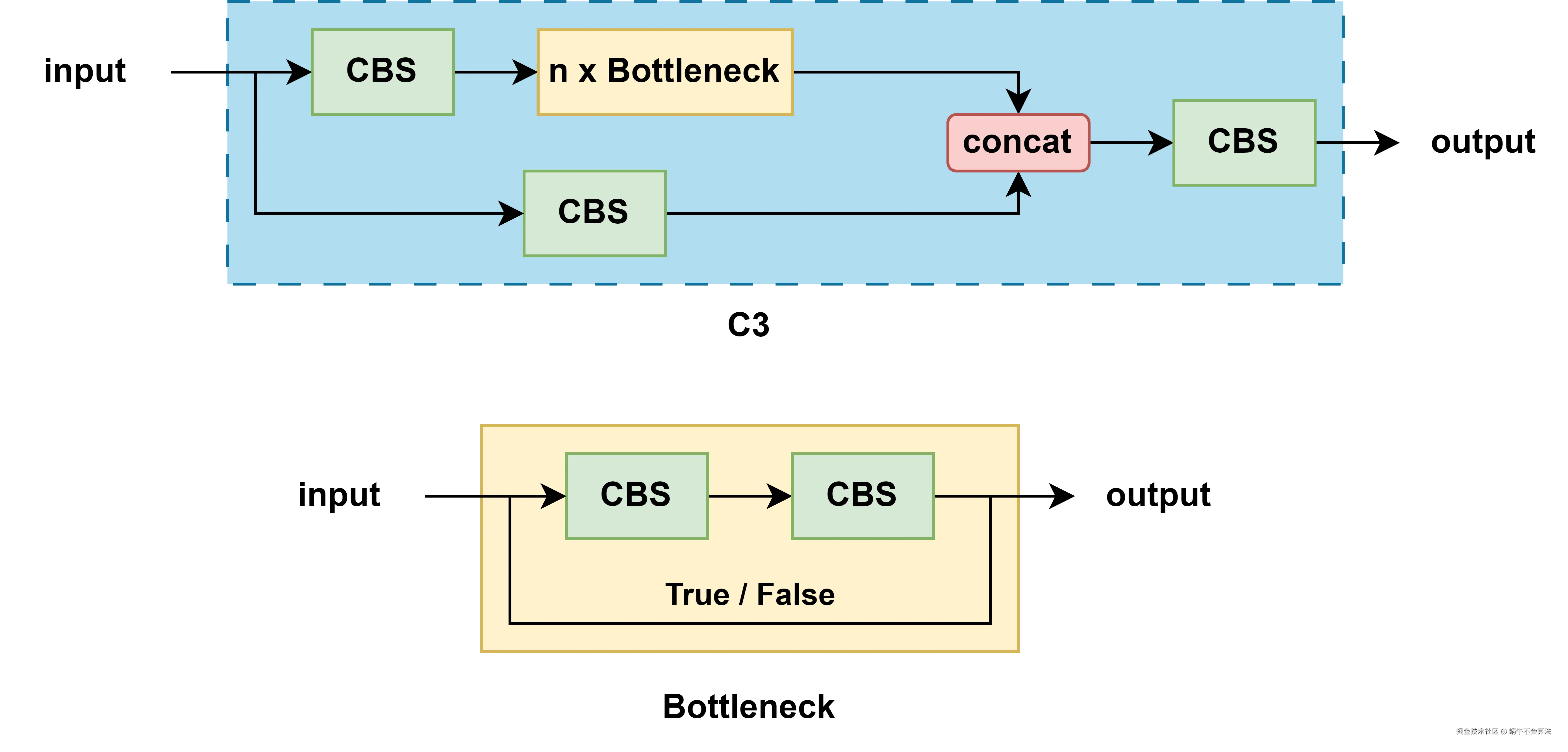 C3 模块因为内部有 3 个卷积模块,所以被命名为 C3 模块,去掉了 BottleneckCSP 中一些繁杂的 Conv2d 操作,并且将激活函数从 LeakyReLU 换成了 SiLU。 CBL 模块也因此变成了 CBS 模块。CBS 模块:
C3 模块因为内部有 3 个卷积模块,所以被命名为 C3 模块,去掉了 BottleneckCSP 中一些繁杂的 Conv2d 操作,并且将激活函数从 LeakyReLU 换成了 SiLU。 CBL 模块也因此变成了 CBS 模块。CBS 模块:Conv + BatchNorm + SiLU。和 BottleneckCSP 一样,内部的 bottleneck 也分为带 shortcut 和不带 shortcut 两种。
1.4.3 E-ELAN(YOLOv7)
Efficient Layer Aggregation Networks 的扩展。更激进地把中间层输出聚合在一起,强调"多分支并行 + 多阶段特征显式收集"。E-ELAN 让网络在不增加很多参数的情况下,仍能扩大有效深度和表达力,推动了 YOLOv7 的精度-速度前沿。
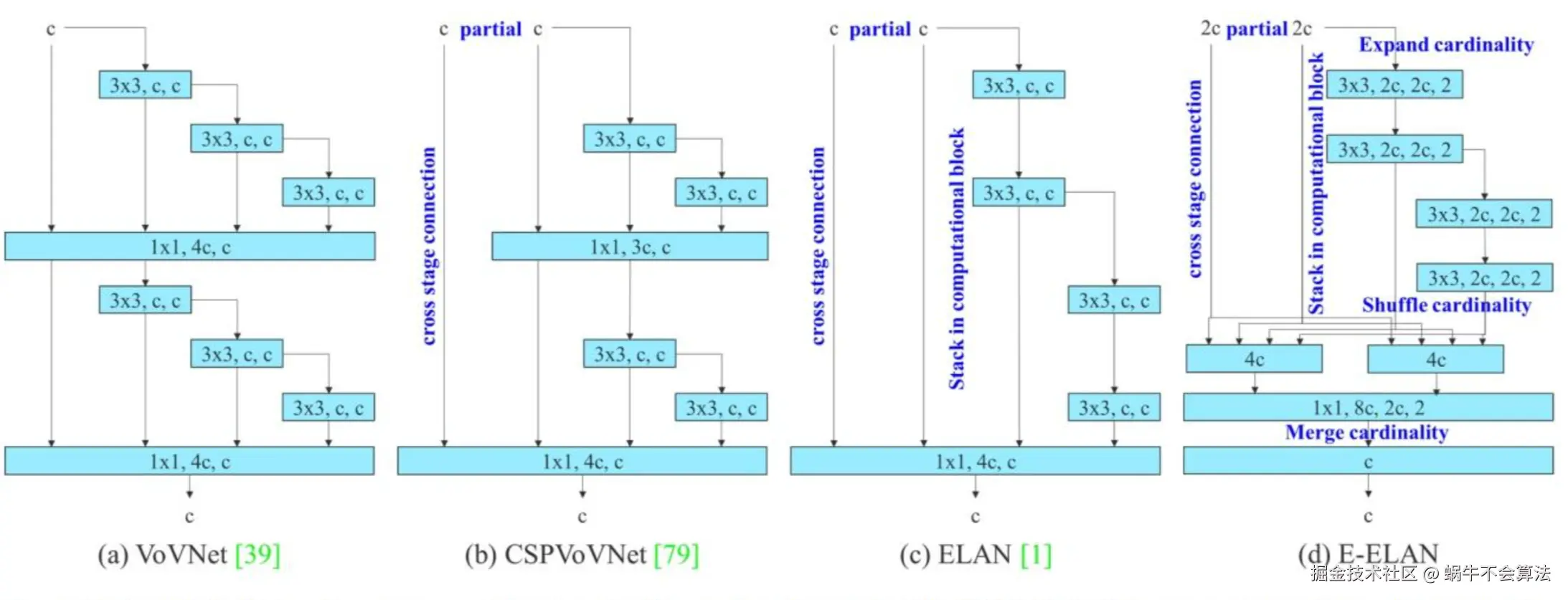 上图可知演变过程:
上图可知演变过程:VoVNet-->CSPVoVNet-->ELAN-->E-ELAN
- VoVNet 通过减少 DenseNet 的连接个数提升网络效率;
- CSPNet 通过 split 操作增加梯度信息,减少计算量;
- ELAN 则是通过考虑最短梯度路径使得可以堆叠更多 block;
- E-ELAN更进一步使用
expand, shuffle, merge cardinality来进一步让网络堆叠更多 block。
1.4.4 C2f(YOLOv8起)
- 可以理解成把 CSP 的分流哲学和 ELAN 的"
中间特征显式保留"合体,形成一种既轻量又高梯度流效率的模块。 - C2f 更利于 PyTorch/TensorRT 导出,结构规则、重复性高,易于自动扩展成 n/s/m/l/x 多个模型尺度。
1.4.5 C3k2 / C3k(YOLOv11等后续演进)
-
C3k(可定制卷积核):C3k是C3模块的一个变体,主要改进在于它允许自定义卷积核的大小 (kernel size)。可以更好地适应不同尺寸的图像特征,尤其是当我们需要捕捉更大范围的上下文信息时。当k设置为3时候,C3k在功能上与C3相等。 -
C3k2结合了C2f的速度优势和C3k的灵活性。它允许在运行时选择是否使用C3k层来处理特征,提供了很高的可配置性。 -
当
c3k参数设置为True时,C3k2将使用c3k层,能够利用不同卷积核大小的灵活性;否则,它将使用标准的瓶颈层,与c2f类似。
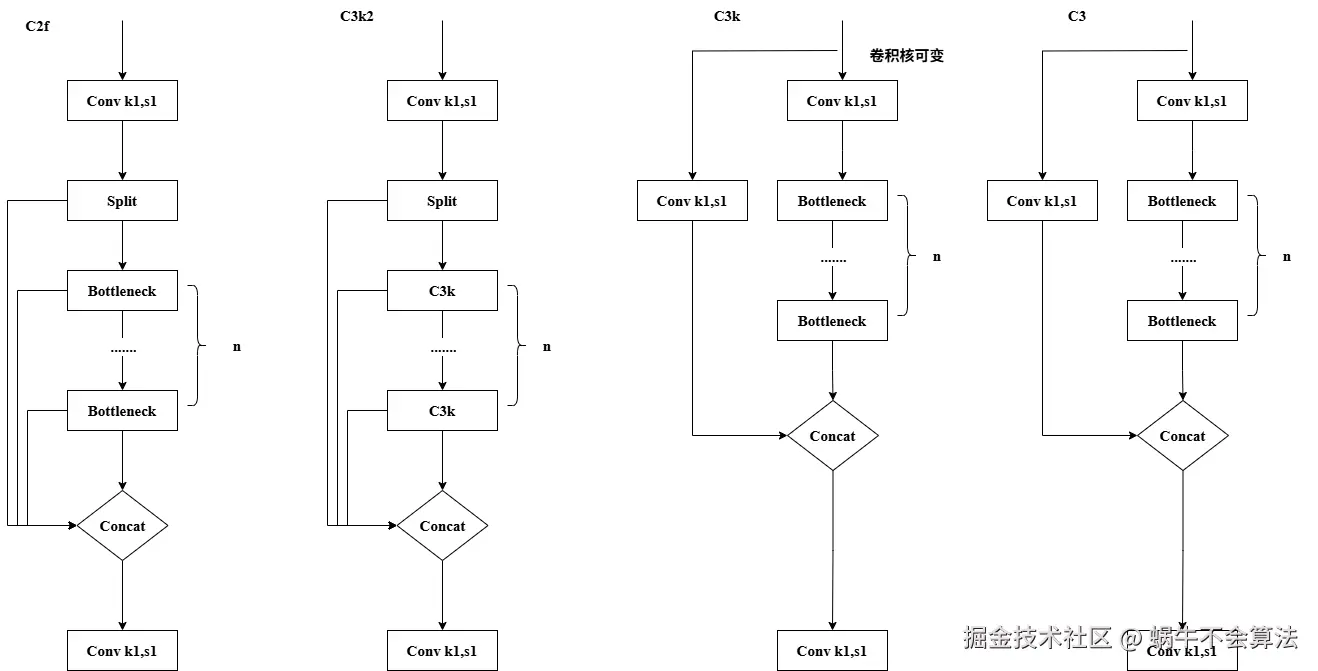
从这个族谱你可以看出:
- C2f 在 YOLOv7(E-ELAN)思路和 YOLOv5(C3/CSP)思路之间的折中:它保留"
显式多阶段特征聚合 + 强梯度流",但努力把它做得更规整、更轻、更适合自动缩放。
1.5 C2f对YOLO网络的优势
- 小目标 / 细节保留: 直通分支(X_b)保留了更原始、细颗粒度的空间信息。检测小目标时,这种精细纹理很关键。
- 高层语义 / 关系建模: 逐步堆叠的残差块 (Y₀→Y₁→...→Yₖ) 会逐渐提取更高级别、更加抽象的语义特征。这对分类决策("这个框到底是猫还是狗")非常重要。
- 稳定训练: 多阶段特征全部直接参与最后的 concat,意味着梯度能从输出端直接反向流向每个阶段。这在深层主干里可以减少梯度消失问题,让大模型/深模型也能在常规训练超参下稳稳收敛。
- 高性价比: 通过 1×1 降维 + 3×3 局部卷积的轻量瓶颈堆叠,C2f 保持了较低的参数量和 FLOPs,但仍能提供多尺度表达。这对于要在中低算力(Jetson、工业相机盒子)上跑实时检测的 YOLOv8/YOLOv9/YOLOv11 家族来说,尤为关键。
- 结构规整,易导出: C2f 的形状是规则的卷积+拼接+卷积,不需要花哨的动态图算子,非常容易被 ONNX、TensorRT、OpenVINO 等推理框架解析和加速,实现工业部署。
1.6 C2f总结
C2f 是 YOLOv8(以及之后的 YOLO 系列)里用来取代旧式 CSP/C3 模块的核心结构单元。它把输入特征拆成多路,一路保持原始/浅层细节,另一路通过一串小残差块逐步提取更深语义;然后把所有阶段的中间输出通通拼接,再用一个卷积统一融合。
分流+堆叠+concat+融合
2. Neck:PAFPN(Path Aggregation Feature Pyramid Network)
YOLOv8沿用并优化了PANet结构,实现多尺度特征的有效融合。
Neck部分负责多尺度特征融合,通过将来自Backbone不同阶段的特征图进行融合,增强特征表示能力。具体来说,YOLOv8的Neck部分包括以下组件:
- SPPF模块 (Spatial Pyramid Pooling Fast):用于不同尺度的池化操作,将不同尺度的特征图拼接在一起,提高对不同尺寸目标的检测能力。
- PAA模块 (Probabilistic Anchor Assignment):用于智能地分配锚框,以优化正负样本的选择,提高模型的训练效果。
- PAN模块 (Path Aggregation Network):包括两个PAN模块,用于不同层次特征的路径聚合,通过自底向上和自顶向下的路径增强特征图的表达能力。
结构流程:
js
Backbone输出特征图(P3,P4,P5) →
上采样路径(自顶向下):
P5 → 上采样 → 与P4融合 → 卷积 → 上采样 → 与P3融合
下采样路径(自底向上):
融合后的P3 → 下采样 → 与P4融合 → 下采样 → 与P5融合
最终输出三个尺度的特征图2.1 SPPF模块结构
SPPF模块(Spatial Pyramid Pooling Fast): 用于不同尺度的池化操作,将不同尺度的特征图拼接在一起,提高对不同尺寸目标的检测能力。 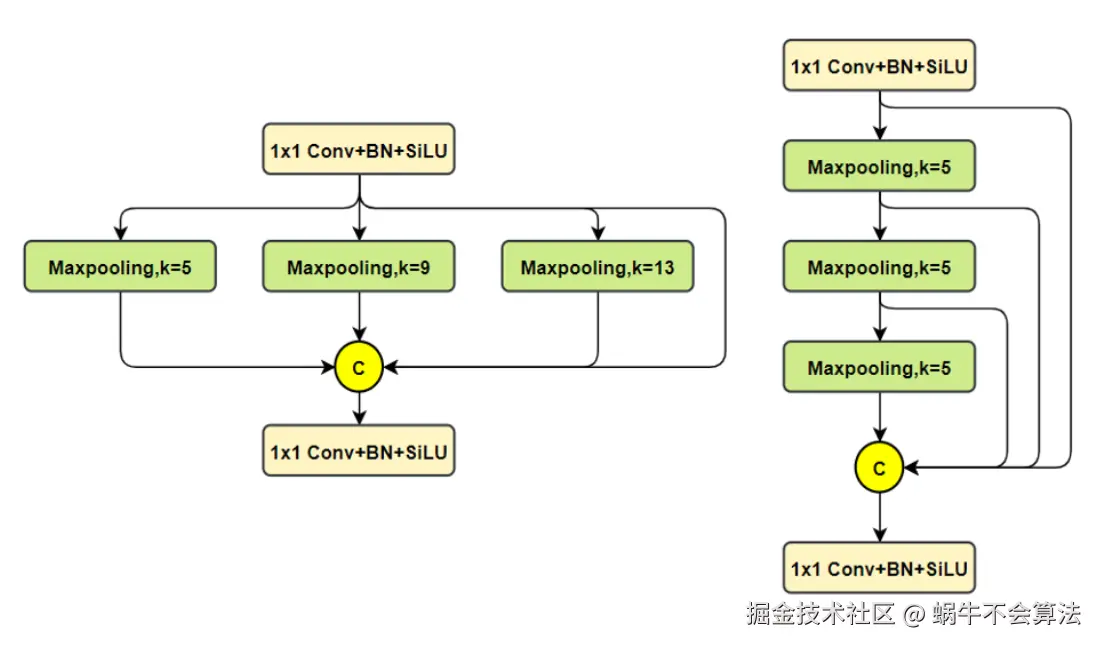
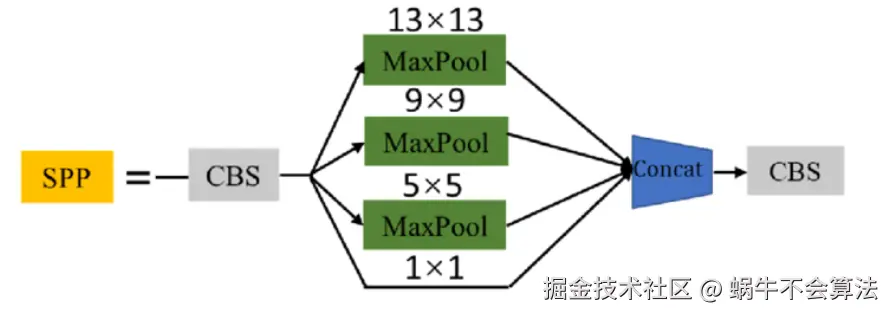
2.1.1 SPP模块结构
SPP模块是何凯明大神在2015年的论文 《Spatial Pyramid Pooling in Deep Convolutional Networks for VisualRecognition》中被提出。
SPP为空间金字塔池化结构,主要是为了解决两个问题:
- 有效避免了对图像区域裁剪、缩放操作导致的图像失真等问题;
- 解决了卷积神经网络对图相关重复特征提取的问题,大大提高了产生候选框的速度,且节省了计算成本。
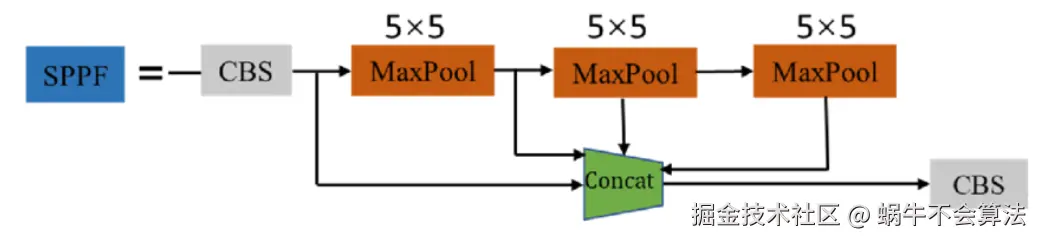
2.1.2 SPPF模块结构
这个是YOLOv5 作者Glenn Jocher 基于SPP提出的,速度较SPP快很多,所以叫SPP-Fast。SPPF是空间金字塔池化的快速版本,它是一种在卷积神经网络中用于处理不同尺寸输入 的技术。SPPF的核心思想是通过对输入特征图进行不同尺度的池化操作,生成固定长度的特征向量,从而使得网络能够处理任意尺寸的输入图像。
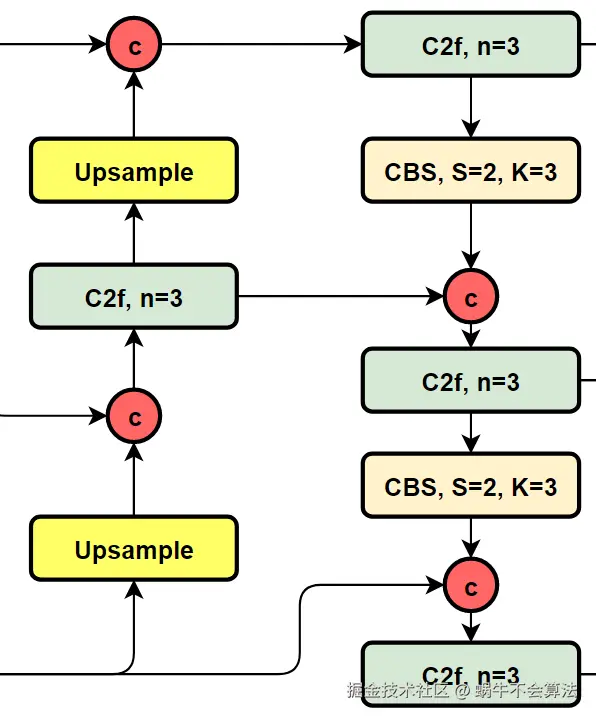
2.2 PAN-FPN模块结构
YOLOv8 中入了 PAN-FPN (Path Aggregation Network - Feature Pyramid Network) 为其特征金字塔网络,进一步增强了多尺度特征的表示能力。PAN-FPN 通过双向路径的融合,使得特征图包含更丰富的上下文信息和语义信息,增强了模型对不同尺度目标的检测能力。
相对于YOLOv5或者YOLOv6,YOLOv8将C3模块以及RepBlock替换为了C2f,同时细心可以发现,相对于YOLOv5和YOLOv6,YOLOv8选择将上采样之前的1×1卷积去除了,将Backbone不同阶段输出的特征直接送入了上采样操作。
YOLOv5的Neck 部分的结构图如下: 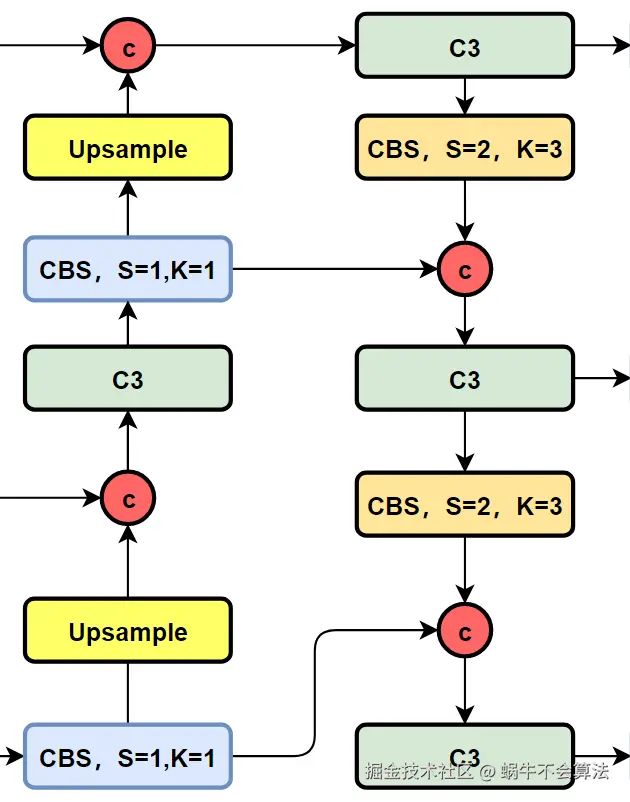
YOLOv6的Neck部分的结构图如下:
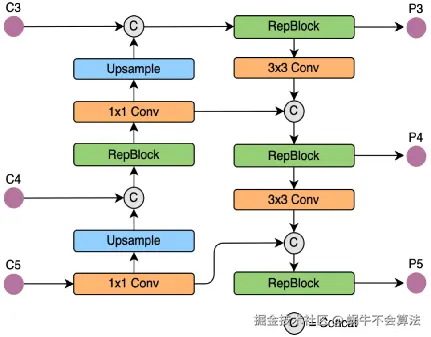
YOLOv8的结构图:
FPN网络pytorch代码
python
class FPN(nn.Module):
def __init__(self, num_blocks, num_classes, back_bone='resnet', pretrained=True):
super(FPN, self).__init__()
self.in_planes = 64
self.num_classes = num_classes
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
BatchNorm = nn.BatchNorm2d
self.back_bone = build_backbone(back_bone)
# Bottom-up layers
self.layer1 = self._make_layer(Bottleneck, 64, num_blocks[0], stride=1)
self.layer2 = self._make_layer(Bottleneck, 128, num_blocks[1], stride=2)
self.layer3 = self._make_layer(Bottleneck, 256, num_blocks[2], stride=2)
self.layer4 = self._make_layer(Bottleneck, 512, num_blocks[3], stride=2)
# Top layer
self.toplayer = nn.Conv2d(2048, 256, kernel_size=1, stride=1, padding=0) # Reduce channels
# Smooth layers
self.smooth1 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.smooth2 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
self.smooth3 = nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1)
# Lateral layers
self.latlayer1 = nn.Conv2d(1024, 256, kernel_size=1, stride=1, padding=0)
self.latlayer2 = nn.Conv2d( 512, 256, kernel_size=1, stride=1, padding=0)
self.latlayer3 = nn.Conv2d( 256, 256, kernel_size=1, stride=1, padding=0)
def _upsample(self, x, h, w): # upsample use 'bilinear' interpolate
return F.interpolate(x, size=(h, w), mode='bilinear', align_corners=True)
def _make_layer(self, Bottleneck, planes, num_blocks, stride):
strides = [stride] + [1]*(num_blocks-1)
layers = []
for stride in strides:
layers.append(Bottleneck(self.in_planes, planes, stride))
self.in_planes = planes * Bottleneck.expansion
return nn.Sequential(*layers)
def _upsample_add(self, x, y):
'''Upsample and add two feature maps.
Args:
x: (Variable) top feature map to be upsampled.
y: (Variable) lateral feature map.
Returns:
(Variable) added feature map.
Note in PyTorch, when input size is odd, the upsampled feature map
with `F.upsample(..., scale_factor=2, mode='nearest')`
maybe not equal to the lateral feature map size.
e.g.
original input size: [N,_,15,15] ->
conv2d feature map size: [N,_,8,8] ->
upsampled feature map size: [N,_,16,16]
So we choose bilinear upsample which supports arbitrary output sizes.
'''
_,_,H,W = y.size()
return F.interpolate(x, size=(H,W), mode='bilinear', align_corners=True) + y
def forward(self, x):
# Bottom-up
c1 = F.relu(self.bn1(self.conv1(x)))
c1 = F.max_pool2d(c1, kernel_size=3, stride=2, padding=1)
c2 = self.layer1(c1)
c3 = self.layer2(c2)
c4 = self.layer3(c3)
c5 = self.layer4(c4)
# Top-down
p5 = self.toplayer(c5)
p4 = self._upsample_add(p5, self.latlayer1(c4))
p3 = self._upsample_add(p4, self.latlayer2(c3))
p2 = self._upsample_add(p3, self.latlayer3(c2))
# Smooth
p4 = self.smooth1(p4)
p3 = self.smooth2(p3)
p2 = self.smooth3(p2)
return p2, p3, p4, p52.2.1 特征金字塔网络(FPN)
论文: 1612.03144 Feature Pyramid Networks for Object Detection
FPN 通过结合 深层语义信息 (高层特征)和 浅层细节信息(低层特征),构建多尺度的特征金字塔,显著提升目标检测模型对不同尺寸目标的检测能力。
在YOLOv8中,FPN主要负责构建从低层到高层 的多尺度特征图。其主要过程如下:
1.自顶向下路径:
- 从深层特征开始,逐层向上采样。
- 每一层的上采样特征与相应的低层特征进行融合,以补充空间信息和增强语义信息。
2.横向连接:
- 利用1x1卷积调整通道数,使得上采样特征与低层特征的通道数一致。
- 通过逐层相加的方式进行特征融合。
FPN网络大致结构如下:一个自底向上的线路、一个自顶向下的线路、横向连接
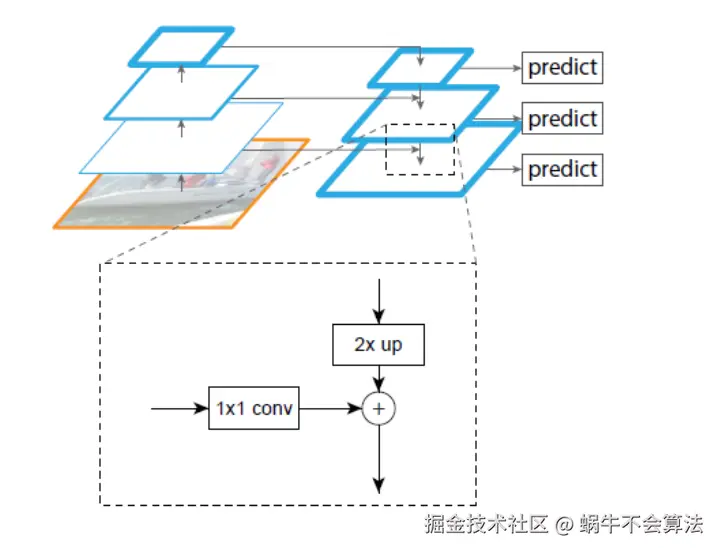
结来说,FPN = top-down的融合 + 在金字塔各层进行prediction
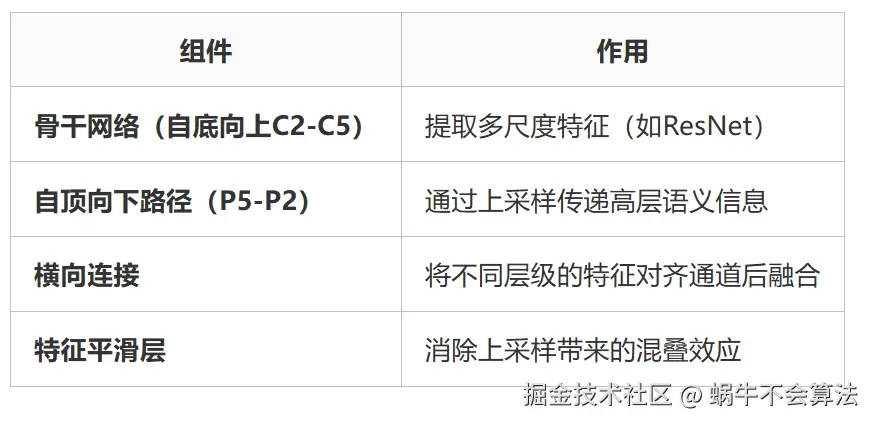 FPN(Feature Pyramid Network) 通过自顶向下的路径构建特征金字塔,但存在两个关键问题:
FPN(Feature Pyramid Network) 通过自顶向下的路径构建特征金字塔,但存在两个关键问题:
- 语义信息稀释:深层特征经过多次上采样传递到浅层时,丢失细节信息。
- 定位精度不足:小目标依赖浅层特征,但浅层语义信息较弱。
2.2.2 路径聚合网络(PAN)
论文:2018年在CVPR 1803.01534 Path Aggregation Network for Instance Segmentation
PANet的核心创新在于引入了自底向上的路径聚合机制,形成了双向特征融合路径,解决了FPN单向信息传递的局限性。这一改进使得低层的高分辨率特征能够更有效地传递到高层,同时高层的语义信息也能充分影响低层特征,实现了更全面的多尺度特征交互。
PAN是在FPN的基础上,进一步增强特征金字塔网络的结构,具体过程如下:
1.自底向上的路径:
- 从底层特征开始,逐层向上传递特征。
- 每一层的特征图通过自底向上的路径,与高层特征图进行融合。
2.特征融合:
- 在每一层,将自顶向下路径和自底向上路径的特征进行融合,确保每一层的特征都包含不同尺度的信息。
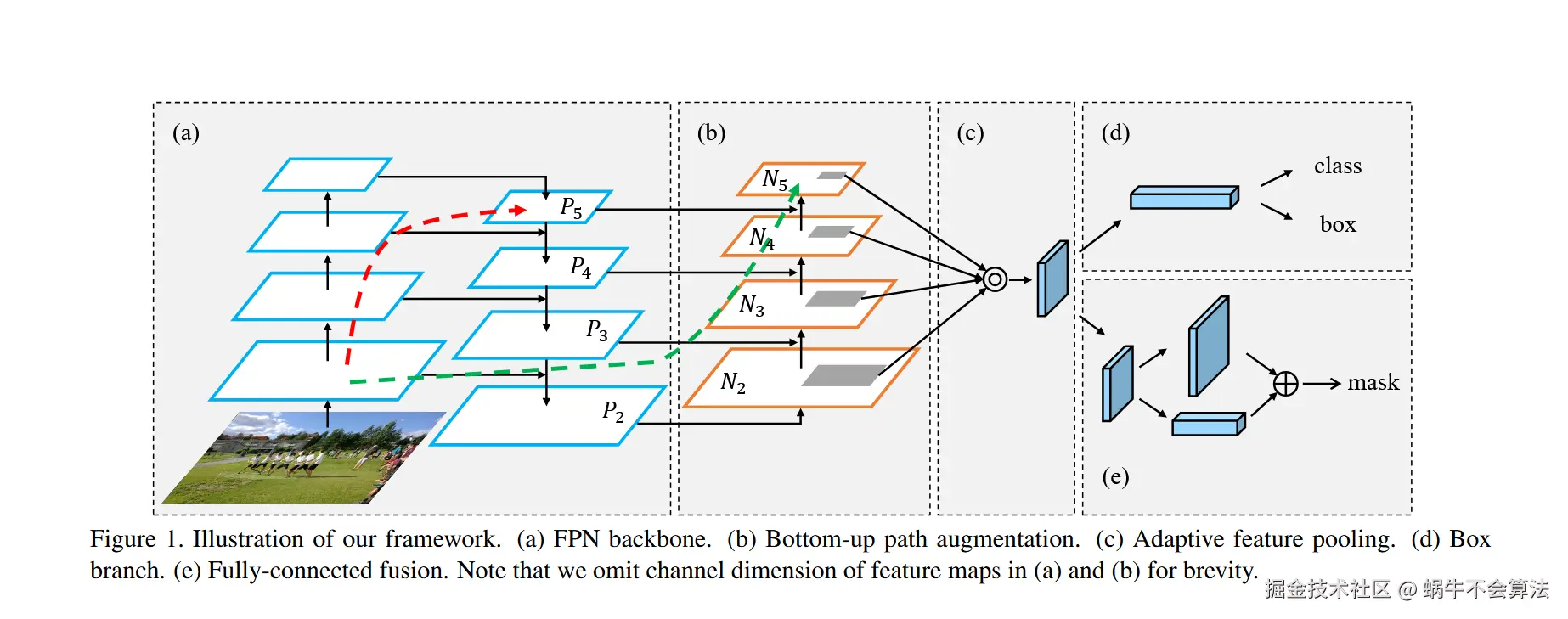
2.2.3 FPN和PANet区别
FPN更适合基础目标检测任务和资源受限环境,例如轻量化移动端部署或实时视频流处理。其简单高效的结构设计使其在计算资源有限的场景下仍能保持良好的检测性能。
PANet则适用于需要高精度的场景,特别是在处理极小目标或复杂背景环境时。例如在自动驾驶系统中检测车辆周围的小障碍物,或在医学图像分中识别微小病灶时,PANet的双向特征融合和自适应特征池化技术能够显著提升检测和分割的准确性。
FPN的参数量约为25M,FLOPs约为200B;而PANet的参数量增加到32.5M,FLOPs达到235.6B。
2.3 Neck创新点
-
双融合路径:
- 上采样路径:传播强语义信息(利于分类)
- 下采样路径:传播强定位信息(利于检测)
-
跨尺度连接:使用Concat而非Add,保留更多特征信息
-
适配不同尺度:针对80×80(小目标)、40×40(中目标)、20×20(大目标)特征图优化融合策略。
2.4 PAN-FPN在YOLOv8中的具体实现
在YOLOv8中,PAN-FPN的实现结合了FPN和PAN的优点,具体如下:
1. 多尺度特征提取:
- YOLOv8的主干网络首先提取出不同尺度的特征图。
- 通过FPN构建自顶向下的特征金字塔,实现多尺度特征的初步融合。
1. 双向特征融合:
- 在FPN的基础上,引入PAN的自底向上路径,将低层特征逐层传递到高层,进一步丰富多尺度特征。
- 通过横向连接,将不同尺度的特征进行融合,确保每一层的特征都包含丰富的上下文信息。
2. 增强的特征表示:
- PAN-FPN通过双向路径的融合,使得特征图包含更丰富的上下文信息和语义信息,增强了模型对不同尺度目标的检测能力。
3. Head:Decoupled-Head + DFL + CIoU(检测头革新)
YOLOv8将检测头改为 解耦形式,并引入了先进的损失函数。
在YOLOv8中,Head部分负责将Neck部分输出的特征进行进一步处理,以生成最终的检测结果。Head部分的主要功能是将特征图转换为目标检测所需的具体信息,包括类别、位置和置信度。
解耦头结构:
js
共享特征 → 三个独立分支:
1. 分类分支:Conv + Conv → 类别置信度
2. 回归分支:Conv + Conv → 边界框坐标
3. 分布焦点分支:Conv + Conv → 边界框分布(DFL)3.1 卷积层和激活函数
Head部分通常包括若干卷积层和激活函数。这些卷积层用于进一步处理Neck部分输出的特征图,以提取更多的高级特征。常见的激活函数包括ReLU或Leaky ReLU,能够引入非线性,从而提升特征表达能力。
3.2 预测层 (Prediction Layers)
在YOLOv8中,预测层是关键组件,负责生成最终的检测结果。预测层包括三个主要输出:
- 边界框回归(Bounding BoxRegression):预测目标的位置和大小。通常输出四个值,分别对应边界框的中心坐标(x,y)和宽度、高度(w,h)。
- 置信度评分(Confidence Scores):预测每个边界框内是否包含目标,以及目标的置信度。
- 类别概率(Class Probabilities):预测目标属于每个类别的概率。
3.2.1 DFL(Distribution Focal Loss)
js
传统:直接回归边界框坐标
DFL:将坐标预测建模为离散概率分布
步骤:
1. 预测边界框的分布(如y = Σ[P(i)×i])
2. 使用Focal Loss优化分布
优势:
- 更准确的小目标检测
- 对模糊边界更鲁棒3.2.2 损失函数组合
js
总损失 = 分类损失 + 回归损失 + DFL损失
分类损失:BCEWithLogitsLoss 或 VarifocalLoss(可选)
回归损失:CIoU Loss(考虑重叠、中心距离、长宽比)
DFL损失:监督边界框分布学习其他优化
除了上述结构外,YOLOv8还引入了一些新的优化技术,如:
- Anchor-free机制:减少了锚框的超参数设置,通过直接预测目标的中心点来简化训练过程。
- 自适应非大值抑制NMS(Non-Maximum Suppression) :改进了传统的NMS算法,通过自适应调整阈值,减少误检和漏检 ,提高检测精度。 最终的预测结果会经过非极大值抑制处理,以去除重复的检测框。NMS保留置信度最高的边界框,并移除与之重叠度高的其他边界框,确保每个目标只被检测一次。
- 自动混合精度训练(Automatic Mixed Precision Training):通过在训练过程中动态调整计算精度,加快训练速度,同时减少显存占用。
总结复习
(1)特征金字塔网络是啥? (2)空间金字塔池化是啥? (3)C2f是啥? (4)路径聚合网络是啥? (5)特征金字塔网络和路径聚合网络区别? (5)YOLO为什么使用两层特征金字塔结构? (7)预测层会输出什么? (8)怎么去除重复的检测框和减少误检和漏检?NMS (9)为什么检测小物体需要用大的特征图?
(10)为什么要用双分支?
- 丰富特征表示:不同分支学习不同特征
- 梯度多样性:缓解梯度消失,帮助训练
- 信息冗余:提升模型鲁棒性
(11)连接处的c和a的区别?
连接处的c通常代表"拼接/连接(concatenate)"操作 连接处的a是add(加法操作/残差连接)
(12)TD和BU是什么?
- TD = T op-Down = 自上而下 = 语义信息下传
- BU = B ottom-Up = 自下而上 = 位置信息上传
参考资料
1什么是 C2f: YOLOv8 中引入的一种高效特征提取模块_c2f模块
2万字详解YOLOv8网络结构Backbone/neck/head以及Conv、Bottleneck、C2f、SPPF、Detect等模块_yolov8网络架构