actor-critic 和A-C recurrent的区别
- recurrent版本的内部维护了LSTM/GRU网络,A-C 内部是MLP/CNN
- A-C只看当前的observation,A-C- R使用的是历史隐藏状态(带有记忆)
- A-C 不需要hidden state(LSTM内部存储的记忆状态),但是A-C-R需要
- A-C不能建模时间信息,A-C-R可以建模时间信息
- A-C-R对于长时间的任务表现更好,适用于障碍物规避等任务,简单的locomotion任务A-C就可以完成
- A-C-R训练复杂度更高
Actor-Critic
- 其中的actor负责学习策略,提供动作分布,critic负责评估状态价值,提供学习信号
完整的运行流程
-
初始化阶段
- 创建ACTOR网络的MLP
- 创建critic网络的MLP
- 初始化观察归一化器:初始归一化器作用是用来归一化观测值的不同尺度
- 初始化动作噪声的参数mean, std:作用是action ~ Normal(mean, std)

-
经验的收集阶段
- 对于每个环境步骤
- 获取状态观测obs
- actor网络: obs → 动作分布 → 采样动作 a
- 环境执行动作 a → 新观察obs ' ,并获得奖励r
- critic网络: 通过obs获取价值估计V(s)
- 存储(obs, a, r , V(s), log_prob(a|s))
- 其中的 log_prob(a|s)反应的物理意义是:策略执行动作 a 的"自信程度",或者说这个动作的"自然性/合理性"。
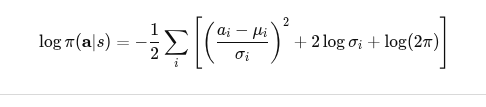
- 对于每个环境步骤
-
策略更新阶段(PPO更新)
-
对于每一个epoch
- 对于每一个mini-batch
-
Actor网络:重新计算动作概率πθ(a|s),用当前新参数 \theta 重新计算旧动作a 的log_prob。 从而比较新策略和旧策略之间的差异,方便计算ratio
-
计算重要性采样比率ratio:作用是衡量新策略和旧策略之间的偏离程度,这一步可以告诉我们新策略相比于之前的策略变强了多少,偏离是多少
-
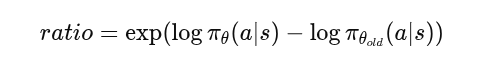
-
计算裁剪之后的策略损失(PPO clip):作用是防止策略更新的太快,导致崩掉。也就是即使此时的优势A很大,也不允许策略一步变化太多。
-
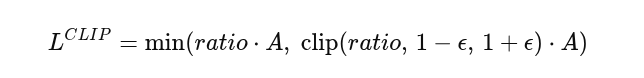
-
Critic重新评估价值V(s) :作用是用当前的critic_θ重新预测每个状态的价值
-
计算价值损失函数:作用是让critic能够对未来价值估计更准确,稳定advantage计算
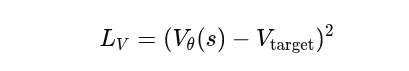

-
计算熵奖励:作用是增加策略的随机性,从而避免过早的收敛到错误的策略,熵的值对应的是PPO损失的一部分,所以熵过小会导致PPO损失过大,所以会保持继续探索
-
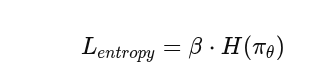
-
更新网络参数:作用是对Actor和Critic进行梯度下降,根据PPO的目标函数更新神经网络
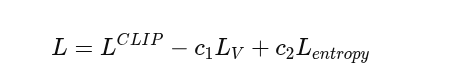
-
更新观察归一化器:作用是更新obs的mean/std,用于下一次迭代对新的obs做标准化
-
- 对于每一个mini-batch
一些训练过程中量的计算方法与作用
- advantage物理意义

