目录
前言
随着地理信息技术的飞速发展以及移动互联网的普及,地图服务已成为人们日常生活中不可或缺的一部分。从出行导航到位置查询,从周边设施搜索到地理信息分析,地图服务的应用场景日益丰富。百度地图凭借其庞大的地理数据资源、精准的定位技术和强大的检索功能,为用户提供了全方位的地理信息服务。然而,对于众多企业和开发者而言,如何将百度地图的深度检索能力与自身业务系统或应用进行高效集成,以满足用户对地理信息检索的个性化需求,是一个极具挑战性且意义重大的课题。在之前的博文中,我们对百度地图的深度检索服务进行了详细的介绍,对如何使用DeepSeek和地图的结合进行了很好的实践,智绘未来:当 DeepSeek 遇上百度地图。作为一名Java应用开发程序员,我们是否可以将百度地图的深度检索服务集成到后台服务中呢?答案是可以的。
在这样的背景下,Java WebFlux 技术的出现为百度地图深度检索集成提供了一种全新的解决方案。Java 语言以其强大的功能、跨平台的特性以及完善的生态系统,在企业级应用开发中占据着主导地位。它能够构建出稳定、可靠且易于维护的系统架构。然而,传统 Java Web 开发模式在处理高并发地理信息检索请求时,可能会面临性能瓶颈。这是因为地理信息检索往往涉及大量的数据交互和复杂的查询逻辑,传统的阻塞式 I/O 模型可能会导致服务器资源的浪费和响应速度的下降。而 WebFlux 技术基于响应式编程模型,能够以非阻塞的方式处理高并发请求,充分利用现代多核处理器的性能优势,从而显著提升系统的吞吐量和响应速度。
本文将详细探讨 Java WebFlux 技术在百度地图深度检索集成中的实践应用。首先,对 WebFlux 技术进行简要介绍,阐述其在处理高并发地理信息检索请求时的优势以及与传统 Java Web 开发模式的对比。接着,深入分析百度地图深度检索 API 的功能特点、使用方法以及在实际应用中的注意事项。然后,通过具体的代码示例和项目实践,展示如何在 Java WebFlux 应用中实现百度地图深度检索的集成,包括请求的发起、数据的处理、结果的展示以及异常的捕获等关键环节。最后,总结在实践过程中遇到的常见问题及其解决方案,并对未来的发展趋势进行展望。
通过本文的介绍,读者将能够全面了解 Java WebFlux 技术在百度地图深度检索集成中的应用,掌握实现深度检索集成的关键技术和方法,从而为自己的项目开发提供有益的参考和借鉴。无论你是地理信息系统的开发者,还是对地图服务集成感兴趣的 Java 开发人员,本文都将为你提供一个清晰的实践指南,帮助你构建出更加高效、智能的地理信息检索应用,为用户提供更加优质的地理信息服务体验。
一、WebFlux技术简介
将 Java WebFlux 技术与百度地图深度检索集成,不仅可以充分发挥 WebFlux 在高并发处理方面的优势,还能深度挖掘百度地图的地理数据资源和检索功能,为用户提供更加精准、快速且个性化的地理信息检索服务。这种集成方式在多个领域具有广泛的应用前景。例如,在物流行业,企业可以通过集成百度地图深度检索,实时查询货物运输路线周边的路况信息、加油站位置等,优化运输路径,提高物流效率;在旅游行业,旅游平台可以借助集成的百度地图深度检索功能,为用户提供目的地周边的景点、酒店、餐厅等信息的深度查询,帮助用户更好地规划行程;在城市规划和地理信息研究领域,研究人员可以利用集成系统进行地理数据的深度分析和挖掘,为城市规划决策提供数据支持。通过交互式的应用接入,让业务系统变得更加智能,更加理解用户的需求。为了让大家对WebFlux有一个基本的认识,这里我们对其进行一个简单的介绍。
1、WebFlux是什么
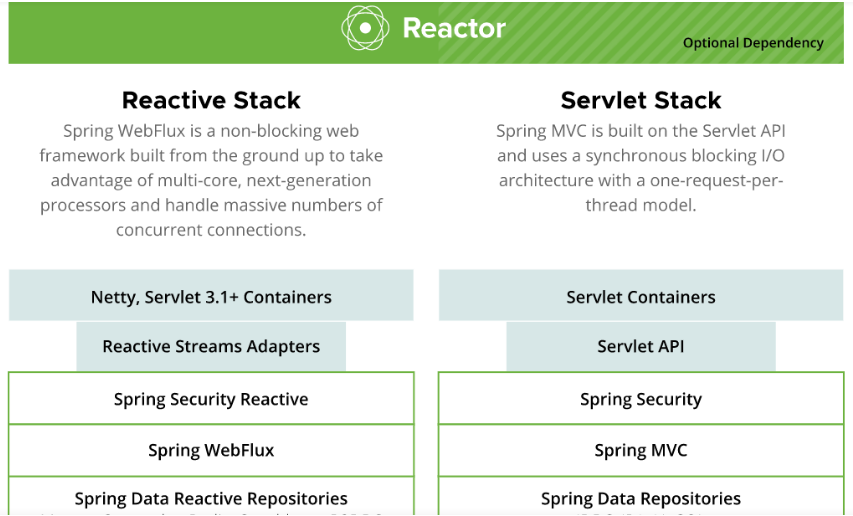
Spring WebFlux 是 Spring Framework 5.0 引入的一个响应式 Web 框架。它基于 Reactive Streams 规范,采用非阻塞 I/O 和响应式编程模型,支持异步处理。与传统的 Spring MVC 不同,WebFlux 不依赖于 Servlet API,而是通过 Reactor 项目实现,适用于高并发和低延迟的场景。
2、WebFlux有哪些组件
WebFlux 的核心组件包括:
-
DispatcherHandler:类似于 Spring MVC 中的 DispatcherServlet,负责将 HTTP 请求分发给相应的处理器。
-
HandlerMapping:用于映射请求到具体的处理器。
-
HandlerAdapter:将处理器适配到具体的执行逻辑,支持多种处理器类型,如注解控制器、函数式路由等。
-
HandlerResultHandler:处理处理器的返回结果,生成 HTTP 响应。
-
ServerHttpRequest 和 ServerHttpResponse:用于处理 HTTP 请求和响应,支持异步非阻塞操作。
-
Flux 和 Mono:Reactor 库中的两个基本响应式类型,分别表示包含 0 到 N 个元素和 0 或 1 个元素的异步序列
关于WebFlux的更多基础知识,这里不进行更多赘述,大家可以到WebFlux的官方网站进行学习,也可以到C站上查找更多资源。
3、WebFlux的使用场景
WebFlux 适用于以下场景:
-
高并发 Web 应用:如大型互联网平台、金融交易系统等,WebFlux 的异步非阻塞 I/O 能够在有限资源下处理更多请求,提高系统性能和响应速度。
-
实时数据应用:如实时股票行情展示、物联网设备监控等,WebFlux 的响应式编程和 WebSocket 支持能够实现实时数据推送。
-
微服务架构:WebFlux 的异步非阻塞特性使得微服务能够更好地处理请求,减少服务间延迟,且与 Spring 生态集成良好,方便开发和管理
这里尤其需要介绍物联网监控应用,使用WebFlux框架后可以很大的程序的提高程序效率,像这里的百度深度检索服务的集成,也可以很好的利用这种特性。也是这种场景的一个落地实例。
二、WebFlux集成百度深度检索
上一节对WebFlux的基本知识进行了简单的介绍后,相信大家对WebFlux已经有了一个基本的认识,那么从本节开始,我们就来对如何在WebFlux中集成百度地图的深度检索服务进行一个讲解。主要包含Maven资源的引入、业务层的具体实现、控制层的实现和程序启动效果。需要说明的是,这里业务层的实现仅是一个示例,为了讲解技术的集成,简单方便大家入门。
1、Maven资源引入
要想使用WebFlux,首先我们需要在Maven中引入相关的资源,这里以SpringBoot2.7.8为例,引入的关键代码如下:
XML
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.7.18</version> <!-- 兼容JDK 8的Spring Boot版本 -->
<relativePath /> <!-- lookup parent from repository -->
</parent>然后再引入WebFlux的依赖,代码如下:
XML
<!-- Spring Boot WebFlux (包含WebClient) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-webflux</artifactId>
/dependency>
<!-- Spring Boot Web (可选,如果也需要传统Web MVC) -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>这里需要注意的是,我们可以根据需要同样引入web Mvc,如果不需要的话,在资源定义中移除即可。
2、业务层实现
引入资源后,就可以来进行业务层的实现。业务层是核心的实现,主要负责连接通道的建立和实现信息的收发。当然,如果涉及返回数据的解析,也是可以放在这一层进行实现的。这里直接给出百度深度搜索服务的实现方法,代码如下:
java
package org.yelang.service;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Service;
import org.springframework.web.reactive.function.client.WebClient;
import reactor.core.publisher.Flux;
import reactor.core.scheduler.Schedulers;
import java.time.Duration;
import java.util.ArrayList;
import java.util.List;
@Service
public class BaiduMapSSEService {
private static final String AK = "您的ak";
private final ObjectMapper objectMapper = new ObjectMapper();
public void streamBaiduMapData() {
WebClient client = WebClient.create();
final List<String> reasonBuffer = new ArrayList<>();
Flux<String> eventStream = client.get()
.uri(uriBuilder -> uriBuilder
.scheme("https")
.host("api.map.baidu.com")
.path("/api_place_agent/v1/deepsearch")
.queryParam("ak", AK)
.queryParam("query", "长沙市美食推荐")
.queryParam("region", "长沙")
.queryParam("location", "28.198418,112.97061")
.build())
.accept(MediaType.TEXT_EVENT_STREAM)
.retrieve()
.bodyToFlux(String.class)
.timeout(Duration.ofMinutes(10))
.publishOn(Schedulers.boundedElastic())
.doOnSubscribe(subscription -> System.out.println("开始接收流式数据..."))
.doOnTerminate(() -> System.out.println("流式数据接收完成"))
.doOnError(error -> System.err.println("发生错误: " + error.getMessage()));
eventStream.subscribe(eventData -> {
try {
// 解析JSON数据
JsonNode data = objectMapper.readTree(eventData);
JsonNode isEndNode = data.get("is_end");
if (isEndNode != null && !isEndNode.isNull()) {
boolean isEnd = isEndNode.asBoolean();
if (!isEnd) {
JsonNode reasonNode = data.get("reason");
if (reasonNode != null && !reasonNode.isNull()) {
String reason = reasonNode.asText();
if (reason.contains("\n") || reason.contains("\r")) {
// 先输出缓存
if (!reasonBuffer.isEmpty()) {
System.out.println(String.join(" ", reasonBuffer));
reasonBuffer.clear();
}
// 输出当前reason
String reasonPretty = reason.replace("\n", "\n").replace("\r", "\n").trim();
System.out.println(reasonPretty);
} else {
reasonBuffer.add(reason.trim());
}
}
} else {
// 输出缓存
if (!reasonBuffer.isEmpty()) {
System.out.println(String.join(" ", reasonBuffer));
reasonBuffer.clear();
}
JsonNode resultNode = data.get("result");
if (resultNode != null) {
System.out.println("搜索结果: " + resultNode.toString());
}
}
} else {
System.out.println("未知数据: " + data.toString());
}
} catch (Exception e) {
System.err.println("解析数据出错: " + e.getMessage() + ", 原始内容: " + eventData);
}
});
}
}这里我们默认以检索长沙的美食推荐作为背景,实现长沙市内的美食推荐。如果服务连接成功,百度地图会通过SSE协议将数据返回给我们的Client,Client则可以接收到具体的数据,从而完成深度检索的功能。
3、控制层实现
相对于业务层,控制层的实现就比较简单的。与传统的WebMvc模式一致,这里我们可以直接采用一个控制层来实现请求的对接。为了避免有阻塞,在控制层中我们使用模拟的多线程来进行切换。关键业务代码如下:
java
package org.yelang.controller;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import org.yelang.service.BaiduMapSSEService;
@RestController
@RequestMapping("/api/baidu-map")
public class BaiduMapController {
@Autowired
private BaiduMapSSEService baiduMapSSEService;
@GetMapping("/stream")
public String streamData() {
// 在新线程中启动SSE流处理,避免阻塞HTTP请求
new Thread(new Runnable() {
@Override
public void run() {
baiduMapSSEService.streamBaiduMapData();
}
}).start();
return "已开始接收流式数据,请查看控制台输出";
}
}4、程序启动
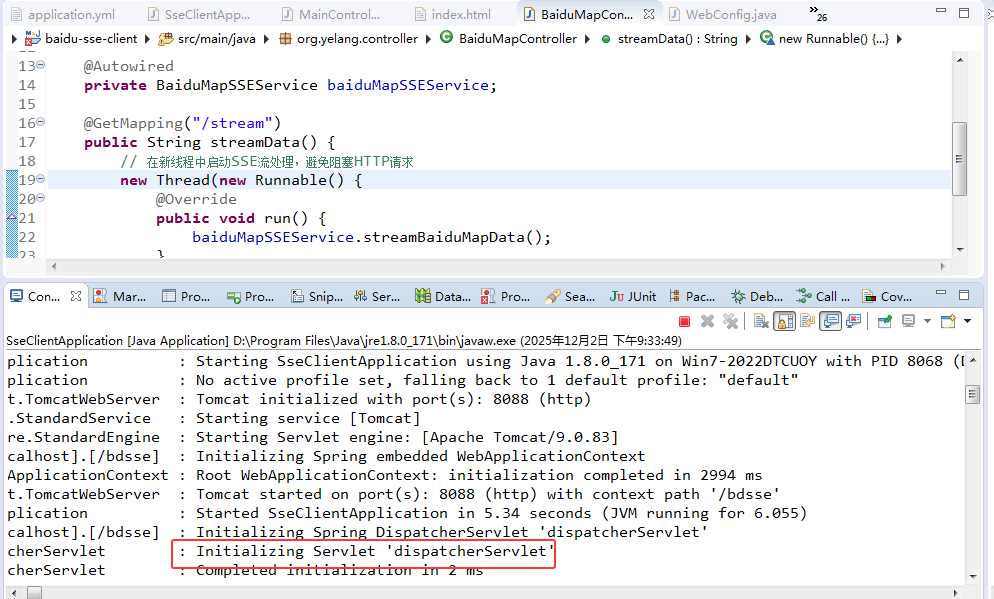
经过以上的步骤,我们基本上就实现了基于WebFlux的客户端接入,在SpringBoot的启动程序中运行程序,在控制台中看到以下输出表示成功启动:
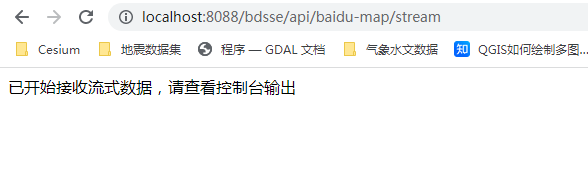
下面就可以对我们的结果进行一个输出和展示。服务运行之后,我们可以直接访问后台,如下:
三、成果输出及对比
本节将以查询"长沙市美食推荐"为例,对比我们的百度深度检索输出、DeepSeek以及Kimi的检索能力。
1、百度深度检索输出
首先,程序运行之后,使用浏览器访问上述地址,可以很明显的看到,后台在一致刷新,跟大模型会自动思考一样,它也在不停的接收来自百度服务的数据。最后来看一下对于这个问题,百度的深度检索服务给出的答案是什么?
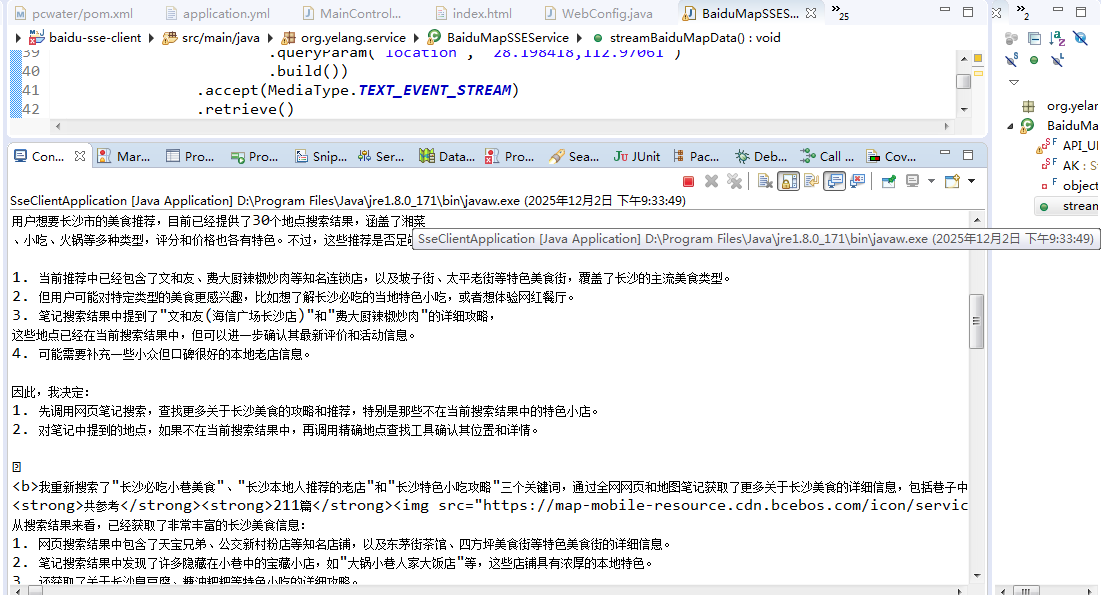
是不是挺有意思的,跟我们常用的大模型工具是不是差不多的?
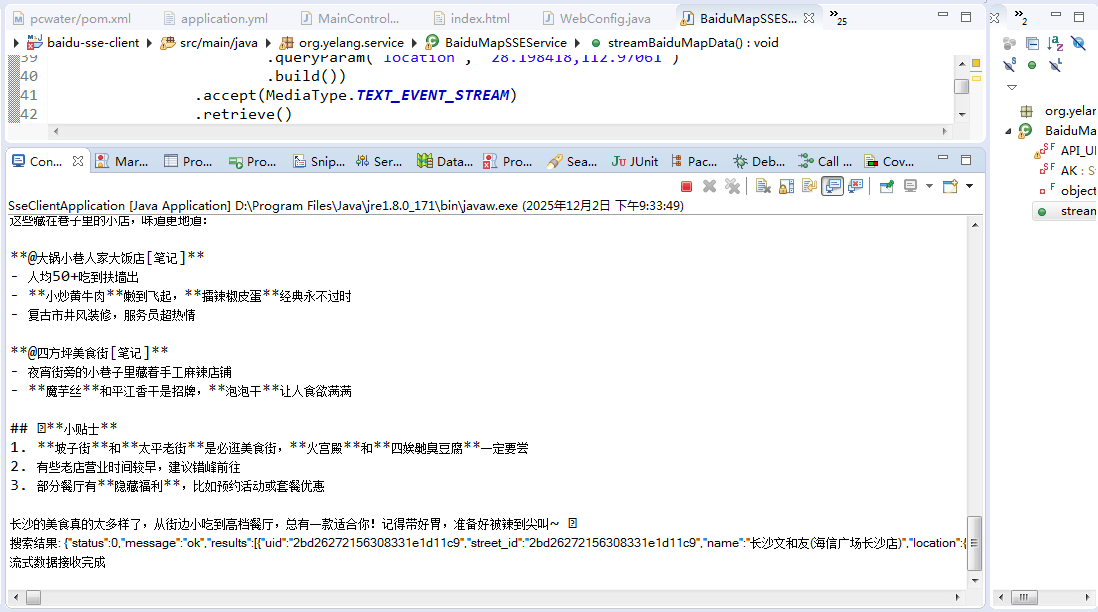
最后来对检索的结果进行一个格式化输出,可以看到最终的结果是:
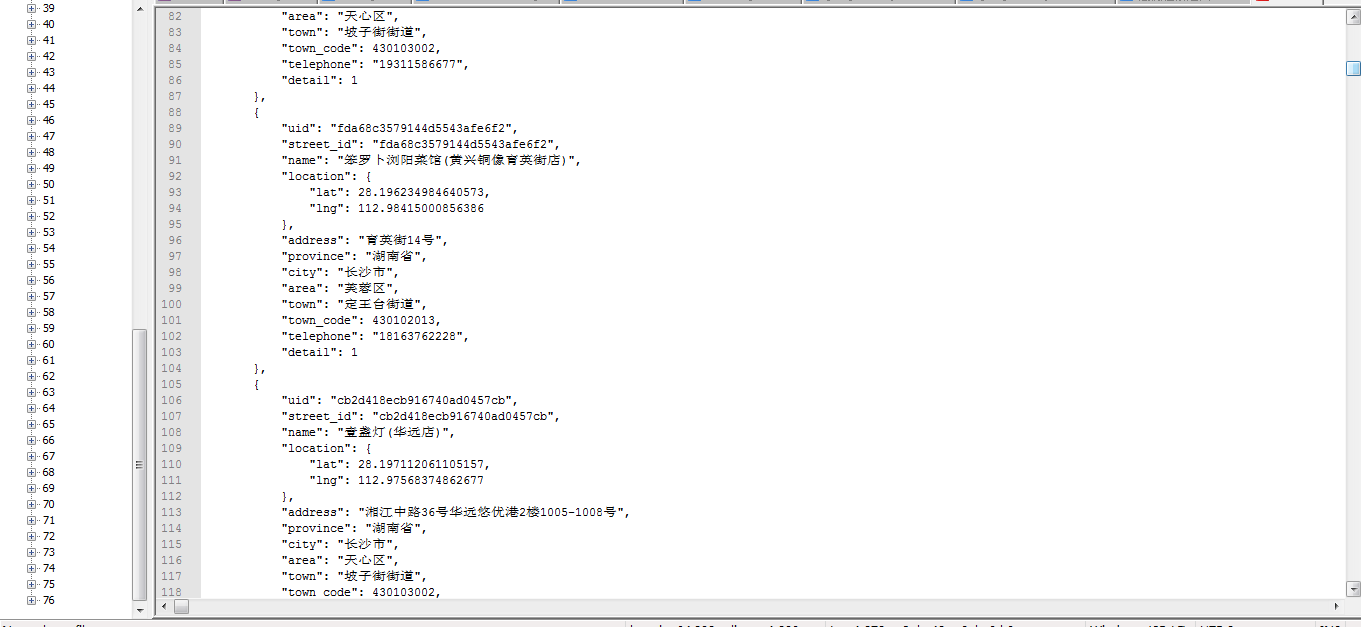
内容有点多,不一一列举,确实百度的深度检索返回了很多有效的内容。
2、DeepSeek检索输出
作为对比,我们来看看在DeepSeek对这个问题的回答又是什么呢?

上述是DeepSeek的思考过程,而它的答案是:
bash
二、正餐湘菜推荐
剁椒鱼头
特点:鱼头鲜嫩,铺满剁椒,辣中带鲜。
推荐店铺:坛宗剁椒鱼头(IFS店)、钰湘宴(岳麓总店)。
小炒黄牛肉
特点:牛肉嫩滑,搭配辣椒爆炒,锅气十足。
推荐店铺:炊烟小炒黄牛肉(连锁品牌,曾上《舌尖》)。
辣椒炒肉
特点:湘菜灵魂,肥瘦相间的猪肉与辣椒完美结合。
推荐店铺:费大厨辣椒炒肉(连锁店多)。
四、饮品与甜品
茶颜悦色
特点:长沙标志性奶茶,幽兰拿铁、声声乌龙必点。
提示:市区门店密集,可择近购买。
紫苏桃子姜
特点:酸甜爽口,解腻佳品。
推荐地:东瓜山夜市小摊。
冰粉/凉粉
特点:夏日解辣神器,常配红糖、水果。比起百度地图的深度搜索少了一些内容,但是做很很好的分类。
3、Kimi检索输出
同样的问题,我们来看看Kimi有没有什么别的见解,
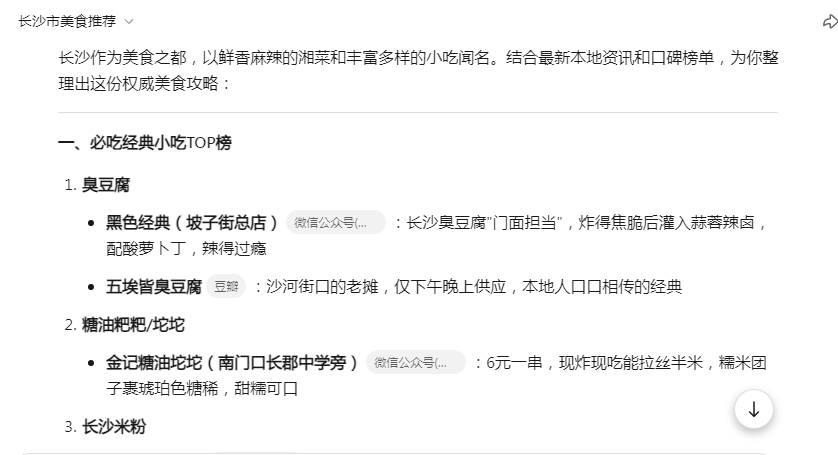

关于Kimi的这份推荐,你又觉得如何呢?关注技术的小伙伴可以自行开发程序来体验。
四、总结
以上就是本文的主要内容,本文将详细探讨 Java WebFlux 技术在百度地图深度检索集成中的实践应用。首先,对 WebFlux 技术进行简要介绍,阐述其在处理高并发地理信息检索请求时的优势以及与传统 Java Web 开发模式的对比。接着,深入分析百度地图深度检索 API 的功能特点、使用方法以及在实际应用中的注意事项。然后,通过具体的代码示例和项目实践,展示如何在 Java WebFlux 应用中实现百度地图深度检索的集成,包括请求的发起、数据的处理、结果的展示以及异常的捕获等关键环节。与其它的WebAPI不同,大家可以看到,百度地图深度检索API在官方API中没有Java的示例,因此本文可以作为Java的同学进行深度检索服务集成的一个友好示例,帮助大家进行入门实践。最后,总结在实践过程中遇到的常见问题及其解决方案,并对未来的发展趋势进行展望。行文仓促,定有许多的不足之处,欢迎各位朋友在评论区批评指正,不胜感激。