TCP服务器代码的补充:
客户端进一步增加,此时就需要搭配多线程/线程池
操作系统中内置了IO多路复用,本质上是一个线程同时负责处理多个客户端的请求~
三个人吃三种不同的饭,方案一A买饭 A买三种(单线程) 方案二ABC各自买饭(多线程) 效率是高了同时系统开销也大了 方案三A去刀削面这边说老板来个刀削面 再去鸡蛋灌饼那里说老板来个鸡蛋灌饼加蛋加肠 一会过来拿 然后去C... 最后等就行了 下单的时候很快速 喊一嗓子 此时三个老板正在加工ing 哪个做好了老板就喊 这样就相当于用来一份等待的时间,同时等待三个任务的完成 (这就是IO多路复用)
多个客户端就是多个小摊的老板 每个客户端绝大部分时间是沉默的 工作线程只需要等待~等到客户端发来数据的时候,线程再来处理就可以了 (这样一个线程也能处理多个客户端了)
IO多路复用 提高了效率 系统开销也小 是当前开发服务器的主流核心技术(操作系统内置的 只需要调用api就可)
目录
[1.0 Http协议](#1.0 Http协议)
[(3)报头 header](#(3)报头 header)
[3.0 构造http请求的工具](#3.0 构造http请求的工具)
[1.0 介绍](#1.0 介绍)
[(1) 概念](#(1) 概念)
应用层协议
一、基本概念
1.0了解
(1)应用层
程序员写的代码 只要是涉及网络通信的 都可以视为是应用层的一部分
应用层是程序员打交道最多的层次 这些协议的理解,是我们写网络代码的基础 ~
应用层中涉及到的网络通信协议(约定) 很多也是程序员子自定制的 TCP/IP协议只不过是大佬订的
(2)如何自定义协议?
协议只是一种约定 但凡实现一个具体的程序,写代码之前,一定是要先约定应用层协议的格式的
例子: 饿了么的雏形
大学生订饭和老板打电话 后来慢慢的多了 做了一个网站来串起来这些信息 成为一个这种特定功能的工具
下面简单介绍一下这个发展的流程:
1.根据需求 明确传输那些信息
客户端-服务器传递信息:首页会显示一个商家列表 请求:用户的位置 用户的id 响应:商家的id 商家的名字 评分 配送费 图片等等
2.约定好信息组织的格式
行文本方式
例如 用户id,用户的位置\n 一个响应由多行构成 每一行是一个商家 每个商家中包含一些信息

哪种方式 自己说了算 咋用都行 只要客户端和服务器都按照这同一套规则来进行构造/解析数据就行了~~
xml格式来约定 请求和响应的数据~~
html 和 xml都是成对的标签构成的键值对结构(只不过html标签都是固定的 大佬们约定好的 你不能乱写 xml的标签内容和格式都是可以自定义的)

xml格式应用于很多场景 组织一段格式化数据 数据可以用来网络传输 作为配置 都行
优点是可读性好 但是冗余信息多(消耗更多的带宽) 对于服务器来说 带宽是最贵的
json格式当下最流行的数据格式组织的方案
最初来自于js 后面spring/spring Cloud都是基于json这一套展开~

优点是:可读性也是很好的 消耗的带宽 也比刚才谈到的xml更节省
缺点:还是存在冗余信息
protobuf 格式
基于二进制的格式 对数据进行压缩 不涉及到json/xml冗余信息了
带宽消耗最少 可读性变差了

性能要求高的场景就需要使用 性能要求不高 用json就行
*数据组织方式还有其他方式 这里暂不介绍了
(3)大佬们定好的协议
FTP文件传输 SSH远程操作主机 telnet网络调试工具
**HTTP协议(重点)**当前web开发中最核心的协议 使用网站 都会用到http~~ spring围着http转
HTTP S https://www.xxxxxxxxx.com/ https=http基础上+安全层(S表示安全层 SSL)
二、HTTP
1.0 Http协议
(1)简述
客户端发一个请求 服务器就返回一个响应 请求和响应一一对应
(也有其他模型 多问一答 上传大文件 一问多答 下载大文件 多问多答 todesk)
(2)报文格式
HTTP报文是客户端和服务器之间通信的数据格式,分为请求报文和响应报文两种
需要搭配一个抓包工具进行学习 抓包工具相当于代理
代替客户端干活(正向) 代替服务器干活(反向)
抓包:抓包就是捕获和分析网路数据包的过程,就像是给网络通信"录音"一样
你网络上所有的网络通信 都会先发给这个抓包程序 抓包程序再把数据转发给服务器
你电脑上的所有网络通信 都会先发给这个抓包程序 抓包程序再把数据转发给服务器
抓包工具:wireshark知名抓包工具 好用但是使用门槛比较高
fiddler 专门抓http的 功能更简单(也足够用) 使用更简单
Fiddler Everywhere 针对于 Windows(下载网址)
简单设置一下 支持https
左上角tools 然后options 然后https 把对勾统统都勾选上就可以了
(弹出一个对话框 提示你是否要信任人家的根证书 一定要选择yes 没点yes只能卸载重装了)
(电脑上很多程序都不安分 在后台搞动作 在fiddler这里可以看到 下面展示一下我的界面哈哈)
接下来就可以通过抓包工具来抓取一些和网站交互的东西
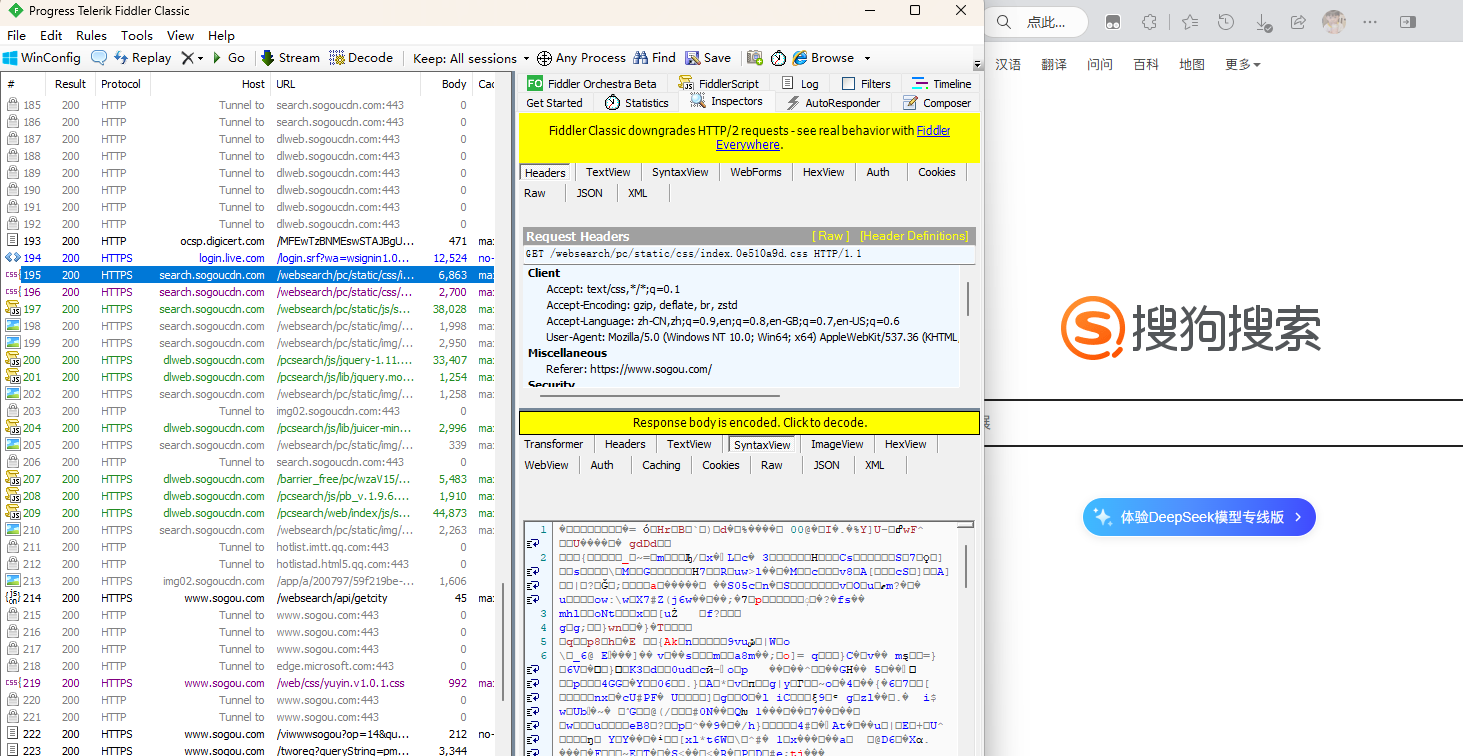

红色表示报错 蓝色表示这个请求得到了这个网页 绿色表示得到了一个js 灰色表示这个响应的数据已经被缓存了
蓝色的部分是https请求的消息 点击右下角那个地方 能用记事本打开 这样更加的方便看
(字体改为22 取消自动换行看着更加舒服一点)
响应数据 经常是压缩后传输的 为了节省网络带宽
通过fiddler打开了新世界的大门 用fiddler可以做到很多事情 例如 爬虫 本质上就是HTTP的客户端(自己的代码实现的) (自己写代码 伪造出差不多的请求,就可以达成类似的功能效果了~~)
(3)http协议
http协议 传输层这里基于TCP实现的(版本号<=2.0) 所谓的HTTP协议,就是把字符串构造成HTTP约定的格式 就是下面的这些内容组成的字符串



2.0协议内容
协议每个部分的具体详情~
(1)URL
引入:学习jdbc的时候 创建DataSource 设置url 设置user 设置password中 设置url提到了url
jdbc:mysql://127.0.0.1:3306/java113?characterEncoding = utf8&useSSL = false
(一个简单的url)
*jdbc:mysql 是协议名称 url不是http专属的概念 可以给各种协议提供支持
*127.0.0.1:3306 要访问的服务器的ip地址或者域名 (域名和ip可以相互转换 这个过程通过DNS域名解析系统来完成 dns既是一套服务器系统 也是一种应用层协议)3306是端口号 用来区分哪个应用程序
*java113 是带有层次的路径 每一层就相当于目录 目录里面还可以有子目录 每个程序使用网络的时候都会关联一个空闲端口号 (前面我们已经访问了ip和端口 下一步就是确定某个程序里面的资源 这个资源可以是一个虚拟的资源 可以是硬盘上的一个逻辑)
*characterEncoding=utf8&useSSL=false 查询字符串 前面的各种结构从协议名称到程序上的某个资源 这里的内容是查询字符串 对要访问的资源补充说明 也是键值对结构 键值对之间使用&分割 键和值之间使用 =分割
*例子 http:s//怡膳园:10/小碗菜/辣椒炒肉/?葱=多放&香菜=多放&辣椒=微微辣
http协议 怡膳园10号档口叫小碗菜的地方点辣椒炒肉 补充多放葱多放香菜微微辣
完整版的url:

片段标识符:区分当前这个而页面的哪个部分的 现在也有 不是很多了 ~~~ 文档类的网站经常有
urlencode
像/ ? : # & =等这样的字符,已经被url当作特殊意义理解了 因此这些字符不能随便出现
//键值对 键:参数的名字 值:参数的具体内容
万一query stir那个里也包含了特殊含义的符号咋办? 转义操作 不仅仅是标点符号 对于中文等其他非常英语系的文字 也是需要转义的 只不过很多浏览器为了用户看起来方便 显示的时候显示转义之前的 实际上 抓包就能看到
没有进行转义 就可能会使这里的请求失败~
rulencode把数据的二进制内容 每个字节取出来 十六进制表示 前面加上%
(2)方法
方法:描述我们这次请求要干啥
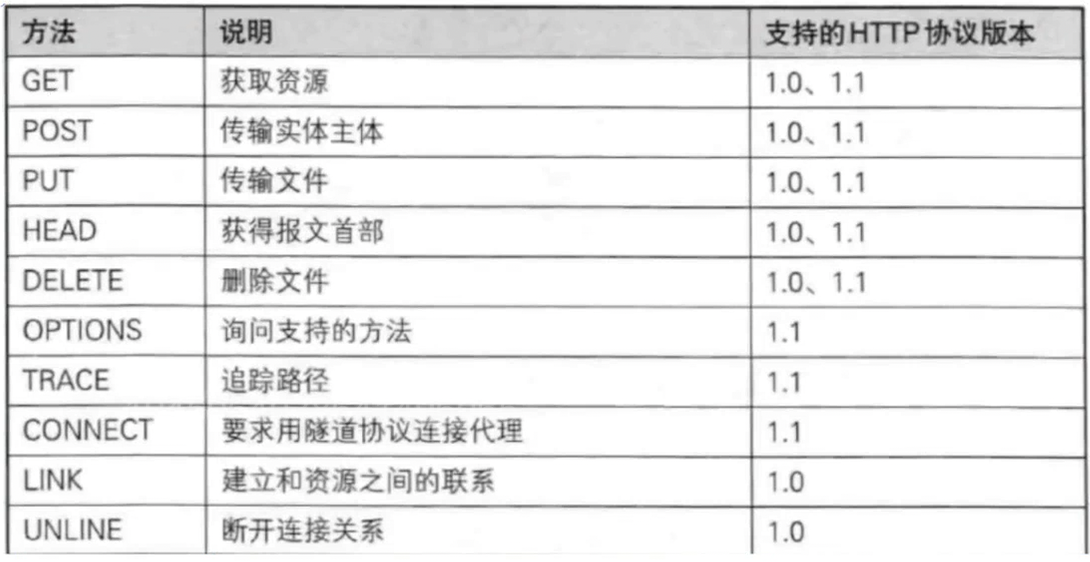
掌握GET POST PUT DELETE就够了
GET和POST的区别
语意上的区别 携带数据的方式(一个equery 一个body 也不是绝对)
GET和POST没有本质区别 经常是能够混用的
1.获取html 获取js等操作 都是get 登录 上传是post
//ctrl + f5 f5是刷新 ctrl+f5是强制刷新 在抓包工具能看到多了好多紫色和绿色的条条 浏览器的缓存机制 浏览器从服务器/通过网络加载网页 (最快cpu 内存 硬盘 网络) 通常情况下 从网络加载数据比硬盘慢 浏览器为了加快访问页面的速度 就会把页面以来的一些静态资源(css js 图片 字体 mp3)这些内容缓存到硬盘上 第一次访问服务器需要加载这么多东西 后续再访问 就不必重新加载~~~
2.携带数据的方式
GET请求一般都是没有body的 如果需要通过GET给服务气发送一些数据 通过query string 传递过去的~
POST来说有body 两个典型的场景 登录和上传其中上传请求是带有正文的 正文就是保存了当前上传的数据的内容(后面那一长段的代码就是图片的内容) (这个是针对图片二进制进行了转码 把二进制转换为文本 body其实也可以直接填二进制数据)
下面是我在gitee上上传了一个头像之后的POST

3.GET请求通常建议设置成 幂等的 POST无要求
幂等:请求是一定的 得到的响应也是一定的 输入A产生B 不会产生C产生D
服务器开发中需要考虑一个环节~~ 服务器开发需要考虑一个环节 尤其是像支付这样的场景 通常要考虑幂等性~ 简单来说:就是不管来多少次,效果跟只来一次是一样的
4.GET设计成幂等 就可以允许GET请求的结果被缓存 POST由于不要求幂等 经常是不幂等的 就认为不能被缓存的
//实际上现在GET不幂等的情况太常见了 现在的互联网产品 都讲究"个性化推荐" 刷新一下不一样
5.网上对于GET和POST的说法有待商榷~~
POST比GET更安全
登录场景 输入用户名和密码 GET用户名和密码会放到url的query string中 就会显示在浏览器地址栏上了 看似更加不安全 其实保证安全的关键加密传输
GET传输数据有长度限制
上古时期 IE浏览器的年代 IE对于url的长度是有限制的 传的数据太多就会被截断 随着时代的发展 现在的主流服务器都没有这样的限制了
GET只能传输文本,POST可以传输二进制
GET确实url只能放文本 可以把二进制通过base64转码成文本的
GET也不是完全不能带body (有些客户端/服务器不支持)
PUT DELETE方法
实现Restful风格的api的时候 会用到~ 设计服务器接口的一种"习惯"
新增:POST 删除:DELETE 修改:PUT 查询:GET
这四个操作的任何一个 都可以进行增删改查 完全是取决于你代码咋写~
(3)报头 header
键值对结构 分成很多行 每一行是一个键值对 键和值之间使用:空格 分割
键/值都是标准规定的 ~~ REC标准文档
一些常见的报头的含义:
Host
表示服务器主机的地址和端口
Host:当前请求访问的服务器在哪里 和url的信息是重合的 url里面也有服务器的信息
url变化 例如使用了代理 即使使用了代理 也可以通过Host来获取到最原始的目标
Http协议中,传输的时候可能会涉及到"加密"(HTTPS) url部分是不会被加密的 被加密的是header和body
Content-Length
表示body中的数据长度 单位是字节
对于tcp来说 一个连接上可以发多个请求~服务器这边收到数据的时候就得区分一下 从哪里到哪里是一个完整的http请求数据 没有body的http请求 读到空行 就可以认为是结束了 有body的http请求呢 先读取首行和header 读到空行 解析header中的content--Length 根据这里的值 接下来再读取固定字节长度
Content-Type
表示请求的body中的数据格式
提示了接收方是如何解析body中的数据~http这里面能够携带的数据种类是比较多的
例如html css js json 图片 等格式 浏览器会根据数据格式解析 把标签转换成界面显示
请求和响应 都会用到这两个header~
User-Agent(简称UA)
里面表示了用户使用的设备的浏览器和操作系统的情况

为什么ua要表示这些内容?
user agent发生在互联网快速发展的早期~ 最早,互联网主要是类似于"报纸杂志"这种感觉~
这个时候浏览器只要能显示文本就行了 后来网页中加入了图片~ 后来加入各种样式 后来加入js 实现了各种逻辑 后来加入js 多媒体.....
同一个时间段内,有些用户浏览器版本是比较旧的 支持的功能少
有些用户浏览器版本更新 支持的功能多
根据用户使用的设备 进行区分 通过UA中的浏览器版本/操作系统版本 区分当前用户的设备 最多支持哪些特性~~
UA还有另一个用途~~ 可以用来区分用户的设备 windows/mac pc ios/android
根据用户的设备,返回不同版本的页面(例如手机的页面小一点)
//前端里面的"响应式编程"
Referer
描述了页面的来源 这个页面是从哪个页面跳转过来的
例:refer :https://www.sougou.com/ 是主页跳到搜索页 搜索页的referer
应用场景:广告系统按点击计费 需要统计某个广告在一定时间内一共点击了多少次 需要搜狗和广告主统计 两边都统计,对数字
搜狗的统计方式好办,点击广告跳转的时候,先访问搜狗的:计费服务器(记录日志) 再从计费服务器跳转到广告页面 广告主服务器这边也有日志 这里的统计就需要考虑到referer(因为这个广告主可能会同时在多个平台投放广告~ 广告主需要区分广告量来自哪几个平台)
问题:是否存在可能有人把referer给改了 十年之前非常普遍 对于广告平台造成一定的损失~ 背后是运营商劫持 它们是有能力办到的 因为用户上网的时候 http请求都经过运营商的路由器或者交换机 运营商有可能会通过在路由器里面安装软件 分析数据流量 然后把一些广告的数据的http数据进行修改就可以了~(运营商也有自己的广告平台 它和搜狗/百度 是竞争关系) 2014年的时候互联网还是新鲜东西 很多关于网络的falv的条文是不完善的 官司要打 大概率也能赢 中间的过程也很复杂也很漫长) 最后是百度拉着其他广告平台进行技术上的反制 ----> 大家一起把广告平台从http升级到https https协议能有效的对http数据报进行加密传输 包括refer
Cookie
较复杂的一个属性
cookie的引入:浏览器展示页面的过程中,页面里面虽然可以通过js来实现一些逻辑 但是js代码无法访问你的硬盘的(文件系统) 这是怕要是js能操作用户的系统文件,给你瞎搞(例如给你删除了你的系统文件) 实际开发中,有些时候还是希望能把某些数据保存到本地硬盘的
cookie就是浏览器允许网页在本地硬盘存储数据的一种机制 不是让网页直接访问文件系统 而是做了一层抽象
cookie按照键值对的方式存储数据
在浏览器 f12 然后appliaction 能查看cookie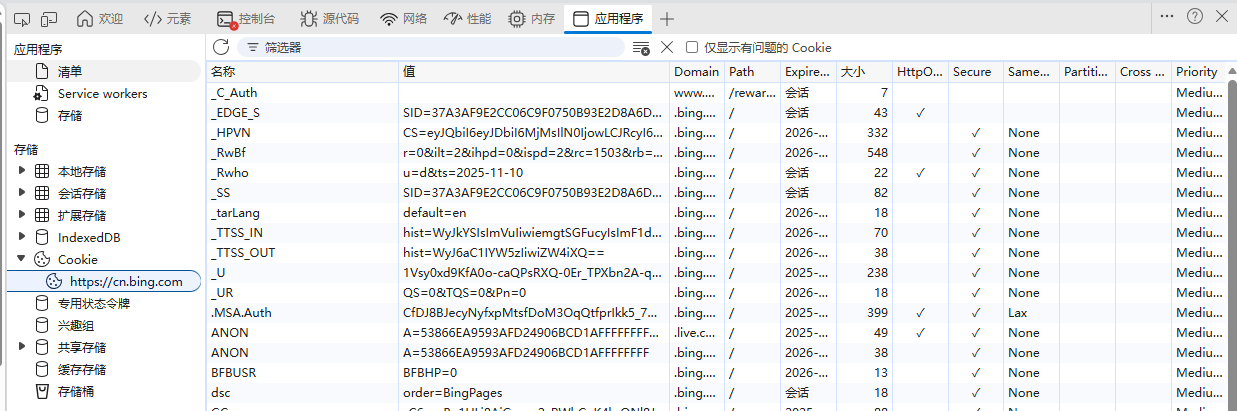
浏览器保存了这些cookie之后 就会在给后续的服务器发送请求的时候 把这些键值对放到 请求cookie header中传输给服务器
cookie是从服务器这边来的(后端开发程序员 决定的) 最终发回给服务器

cookie是可能会过期的 服务器返回cookie的时候 是可以设置有效事件 如果cookie中sessionld国企了 此时就需要用户重新登录了 有得网站对于安全性要求不高的 过期时间就长 例如娱乐网页 b站 抖音 有的网站 对于安全要求很高 过期时间就短 例如银行里面的操作网站 公共电脑等
会话:描述客户端和服务器之间的一种交互关系 假设一个朋友进去了 你去探视 进行探视的过程 就可以称为是一次会话 你一次会话过程就会涉及到一些关键信息 (你是谁 你探视谁 你和他聊了啥)
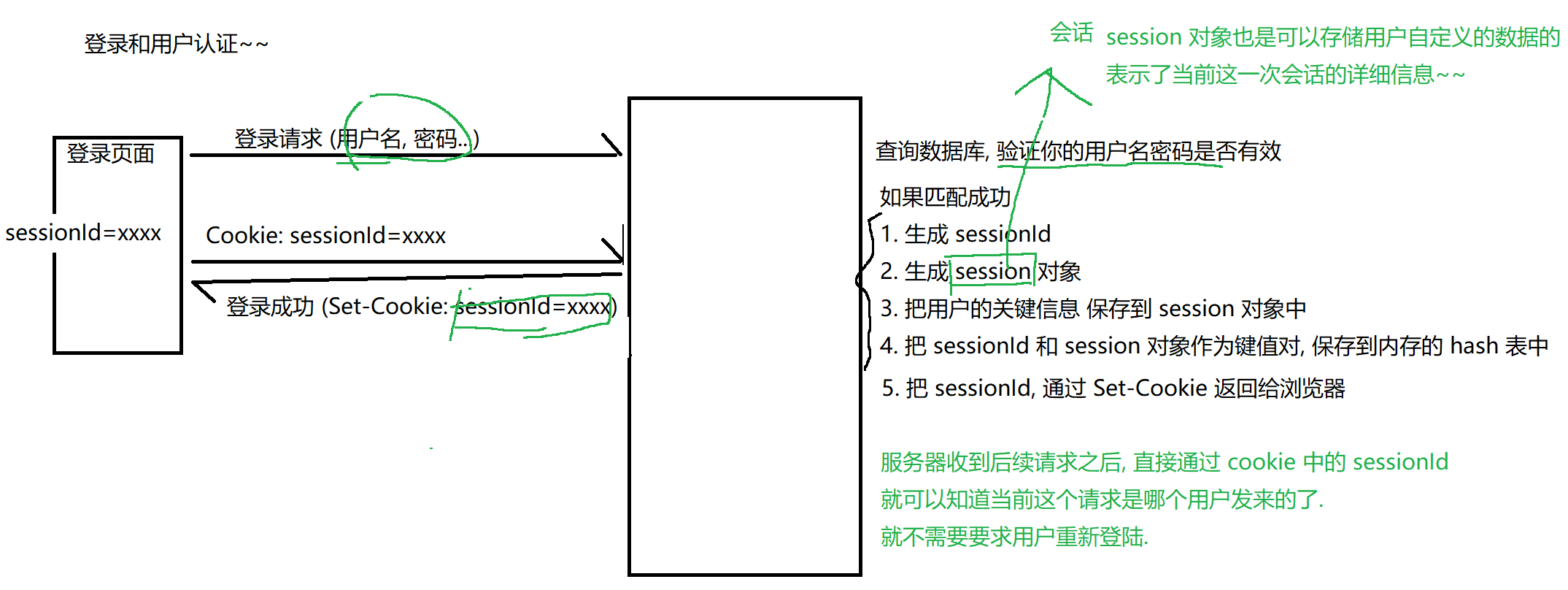
cookie里面的数据都是程序员自己定义的 业务相关的 但是有一个典型的场景 属于"通用业务" 登录和用户认证:
状态码
描述了响应结果 正确还是出错 以及出错是啥原因(计算机的大佬提前定义好了状态码)
几个常见的状体码
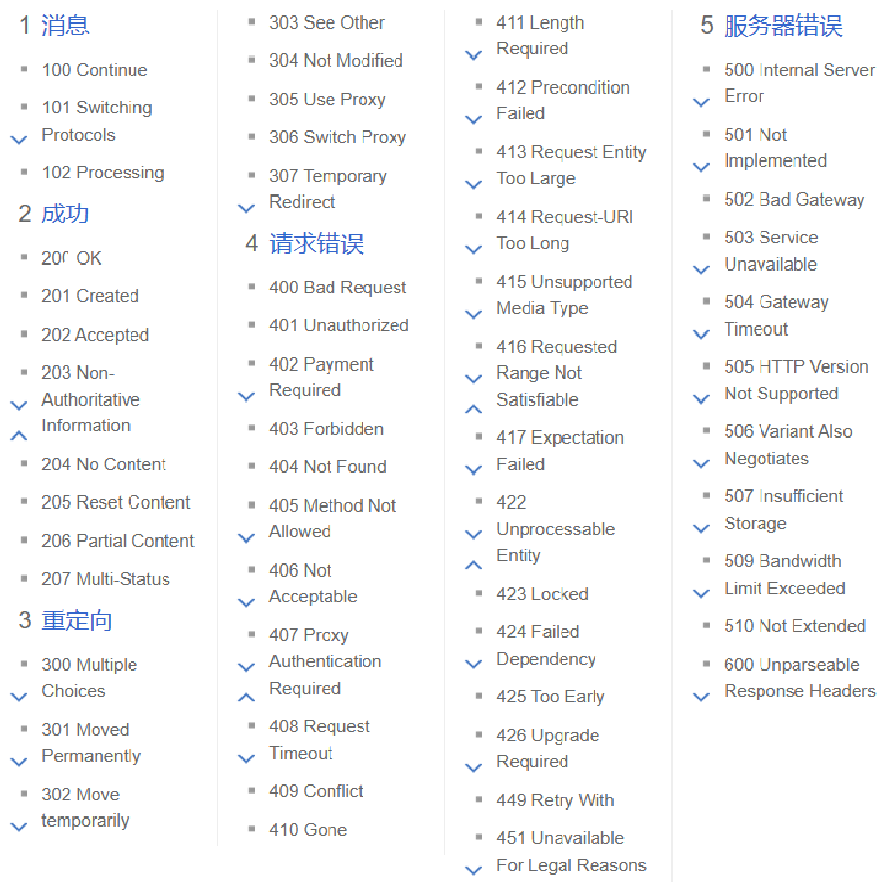
每个开头都是一类状态码 有相似的功能 下面我们列举几个
200k 最常见的状态码 表示成功
302 Move temporarily 重定向:访问服务器A 服务器告诉你去找B 如果直接迁移了 就会使所有保存旧域名的同学都无法访问了 把服务器架在新域名上 给旧域名设置重定向 可以重定向到新域名
404Not Found 这个表示防问的资源还没有找到 path定位到程序管理的资源在服务器上面没有


403 Forbidden 访问被拒绝(没有权限)
405 Method Not Allowed 网上找别人的网站出现405是比较难找的 但是在咱们自己开发的过程中 很容易出现405 请求的方法和服务器这边生声明的注解不匹配 就会出现405
500 Internal Server Error 服务器出现错误 服务器处理逻辑的代码中抛出异常 但是你没有catch
504 Gateway Timeout 网关 网关是网络的入口 相当于古城的大门
程序员主要是关注这个5开头的 是服务器出问题了大概率就是你的代码有bug
3.0 构造http请求的工具
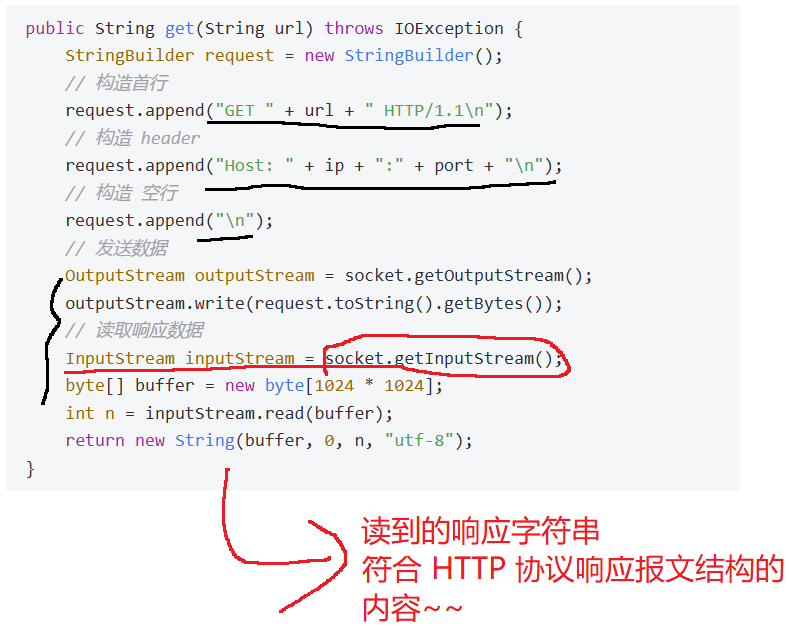
通过Java socket构造HTTP请求
Http请求 本质上就是TCP请求 只需要构造字符串 符合HTTP协议格式 写入到TCP socket中
通过Postman工具构造http请求
实际开发中 除了写爬虫 很少用Java构造http请求------>引入postman工具
你写一个服务器程序 肯定得测试 但是我们是后端的前端的代码还不太了解呢 那么如何测试自己的程序呢 使用专业的接口测试工具
故事:postman是老牌的http构造工具了 最初是chrome的一个插件 后来就单独独立出来
打开之后是这个界面:
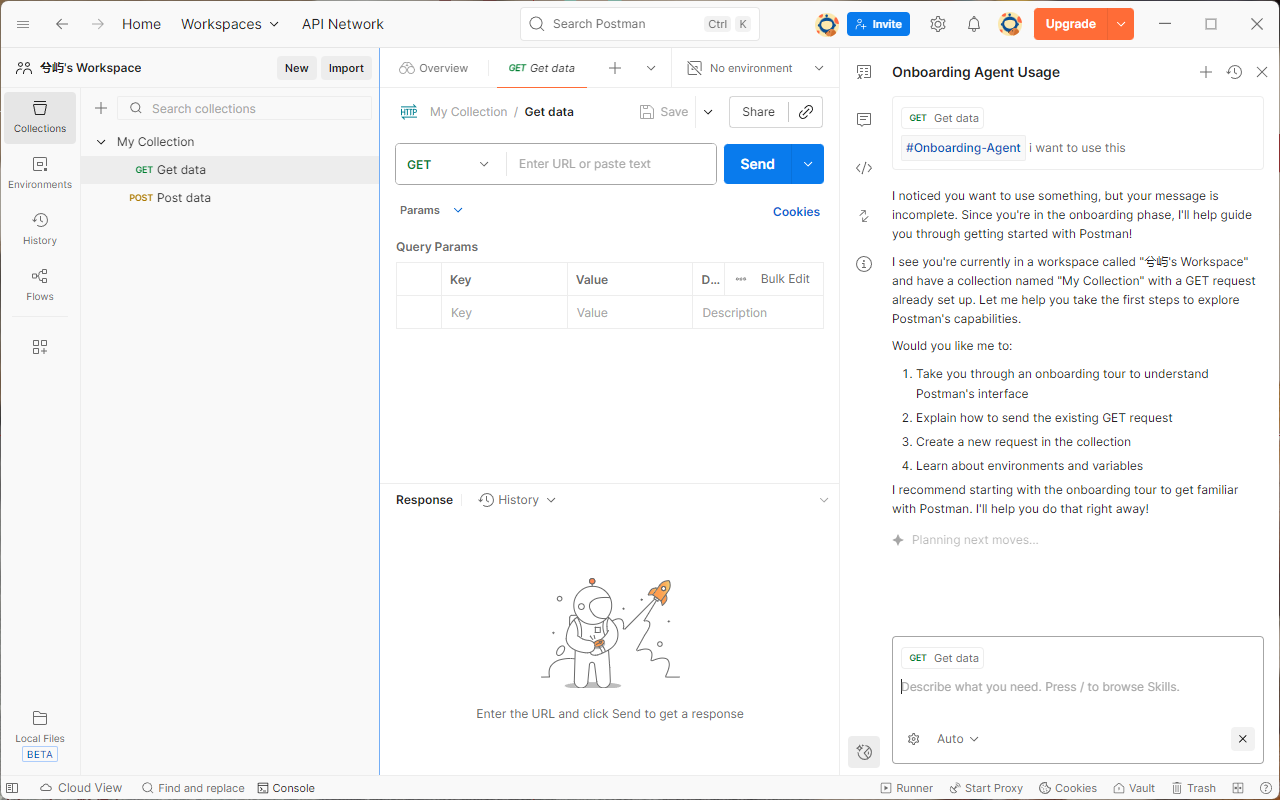
创建一个workspace 然后构建 这个工具能帮你构造http 点击对应的地方就是

右面侧边栏 code 可以帮你构建代码 当年觉得真牛的功能 现在ai时代 很容易构造
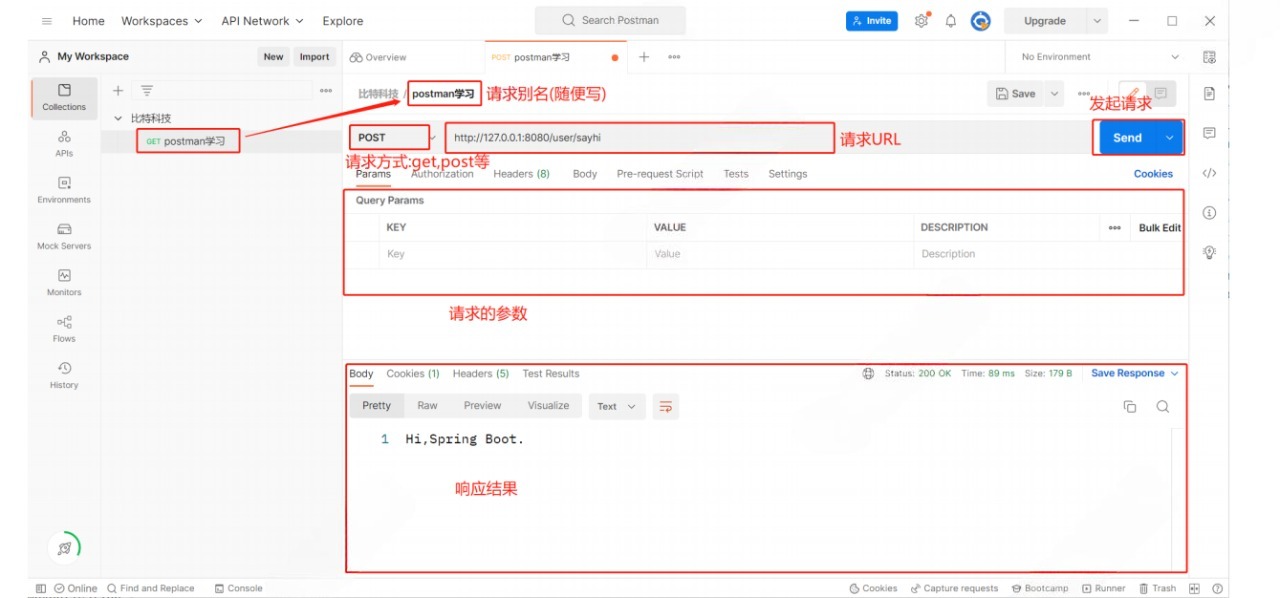
通过apifox构造http请求
上面的postman是歪果仁制作的工具 咱们也有更加符合中国健康宝宝体制的工具---> apifox
在运行页面里面就和postman是一样的 自己研究吧嘟嘟
公司用哪一个 都有 postman清一色都是 apifox属于是后起之秀
三、HTTPS
1.0 介绍
(1) 概念
网络上几乎是https 实现了加密 //讲refer的时候的例子 运营商劫持 : 下载某个应用 却下载了应用宝 然后让你在应用宝宝里面下载软件 如果加密 通过密文来传输 加密解密
HTTPS = HTTP + S(SSL/TLS) //SSL也是一个应用层协议 专门负责加密
明文和密文:明文(初始信息)经过加密得到密文 计算机中有门学科叫密码学(概率论 数论)
(2)密钥
两种方式
对称加密:加密和解密使用同一个密钥
非对称加密:加密使用一个密钥 解密使用一个密钥 存在关联关系 但是很难猜
经常会把其中一个公开出去 叫公钥 另一个自己保存好 叫私钥
可以公钥加密 私钥解密 反之也可以
(3)HTTPS工作原理
http是明文传输 客户端和服务器的过程中黑客很容易获取到你传输的内容 也很容易篡改
密文传输:
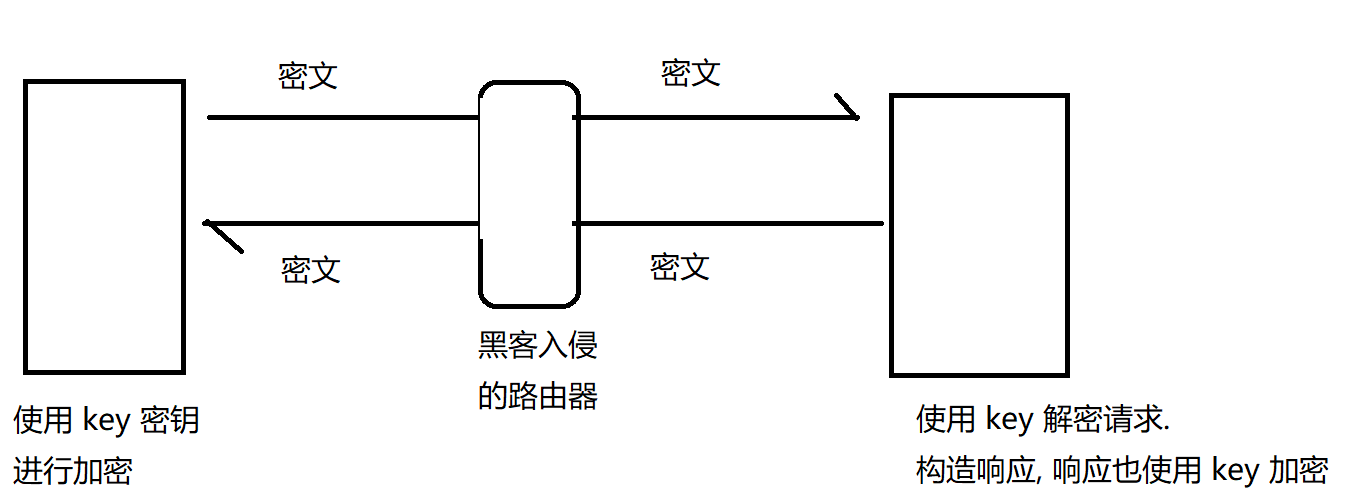
服务器要给N个客户端提供服务 多个客户端 密钥必须是不同的
如果大家都是相同的密钥 意味着黑客自己搞个客户端就能拿到密钥了~
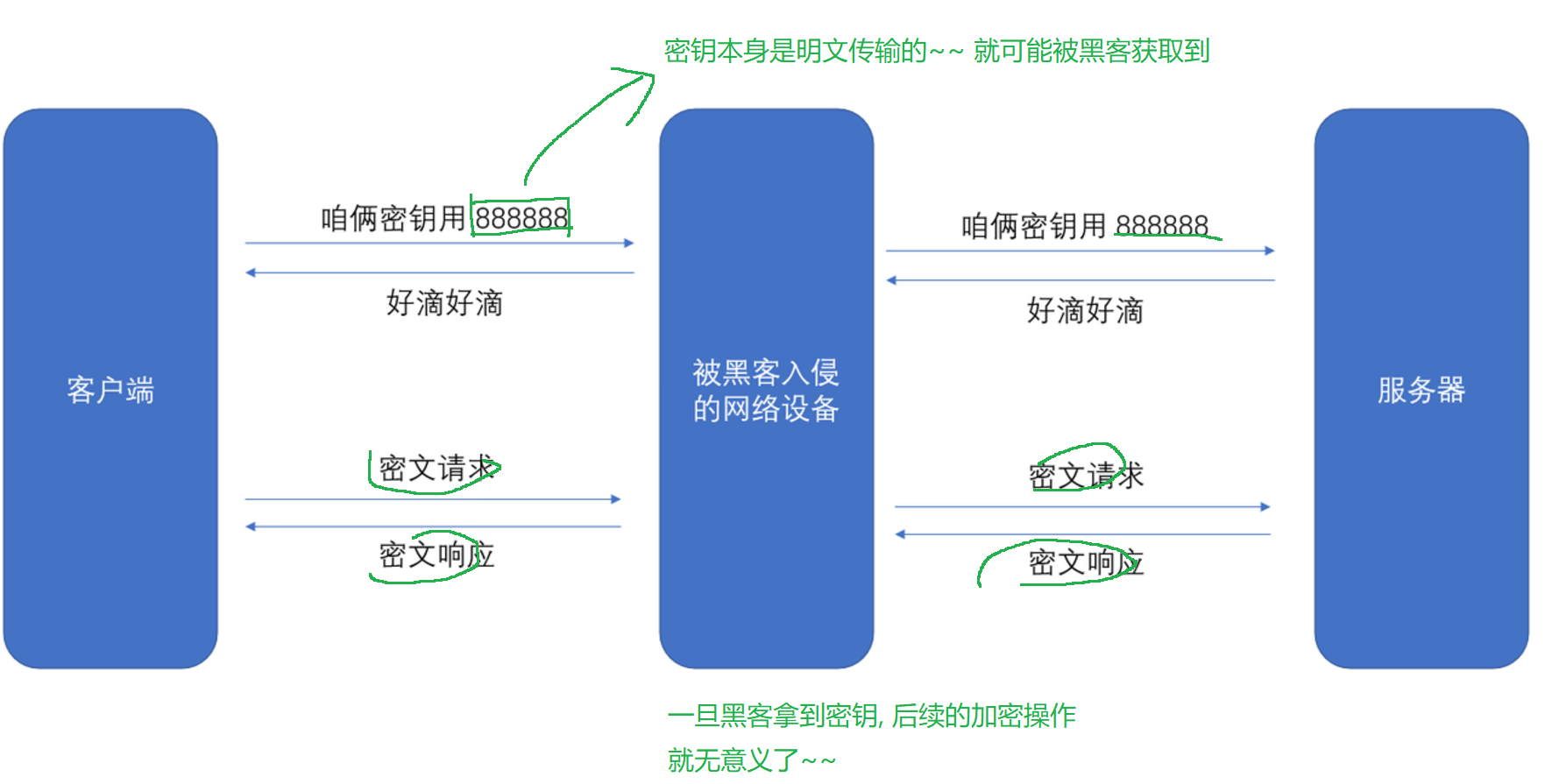
继续优化 我们可以对密钥进行加密 key1 key2 key3 难道搞个key4加密key3吗
无论多少层 都有一层明文传输破解
这个时候引入非对称加密 就是为了解决密钥传输的安全性问题~~
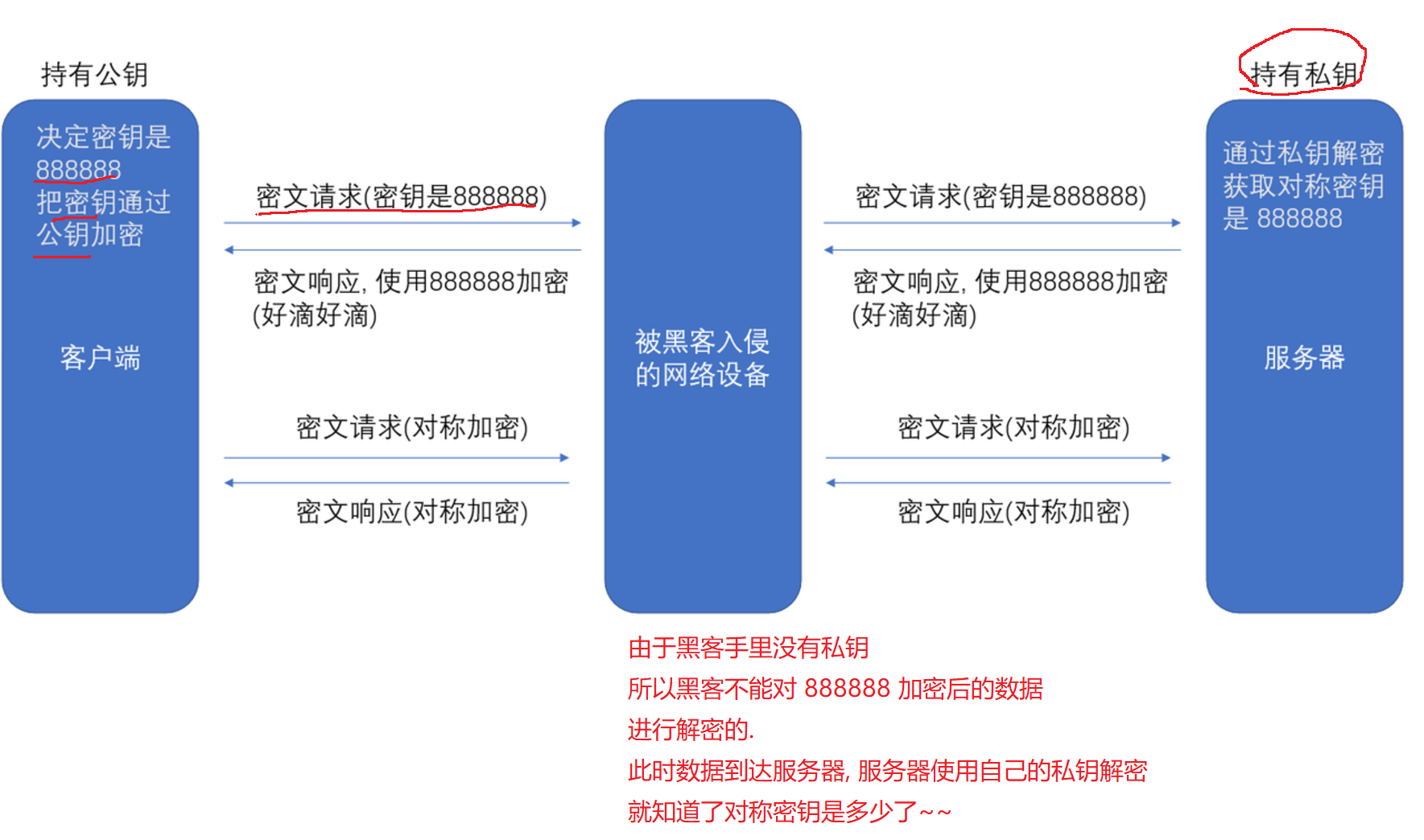
这样的话 黑客得到公钥 但是由于得不到私钥 所以也没有办法(上述方案仍然存在严重漏洞)
黑客能否侵入服务器 把私钥拿到呢? 理论上是可行的,实际上 难度 要比入侵网络设备 更难~~成本更高 苍蝇不叮无缝的蛋 黑客入侵 都是需要借助一些"现有的漏洞"
对称加密 运算速度快 开销小 适合针对大量数据进行加密
非对称加密 运算速度慢 开销大 加密小的数据
继续优化 (黑客可以通过特殊手段 来获取到对称密钥 破坏后续传输的安全性)
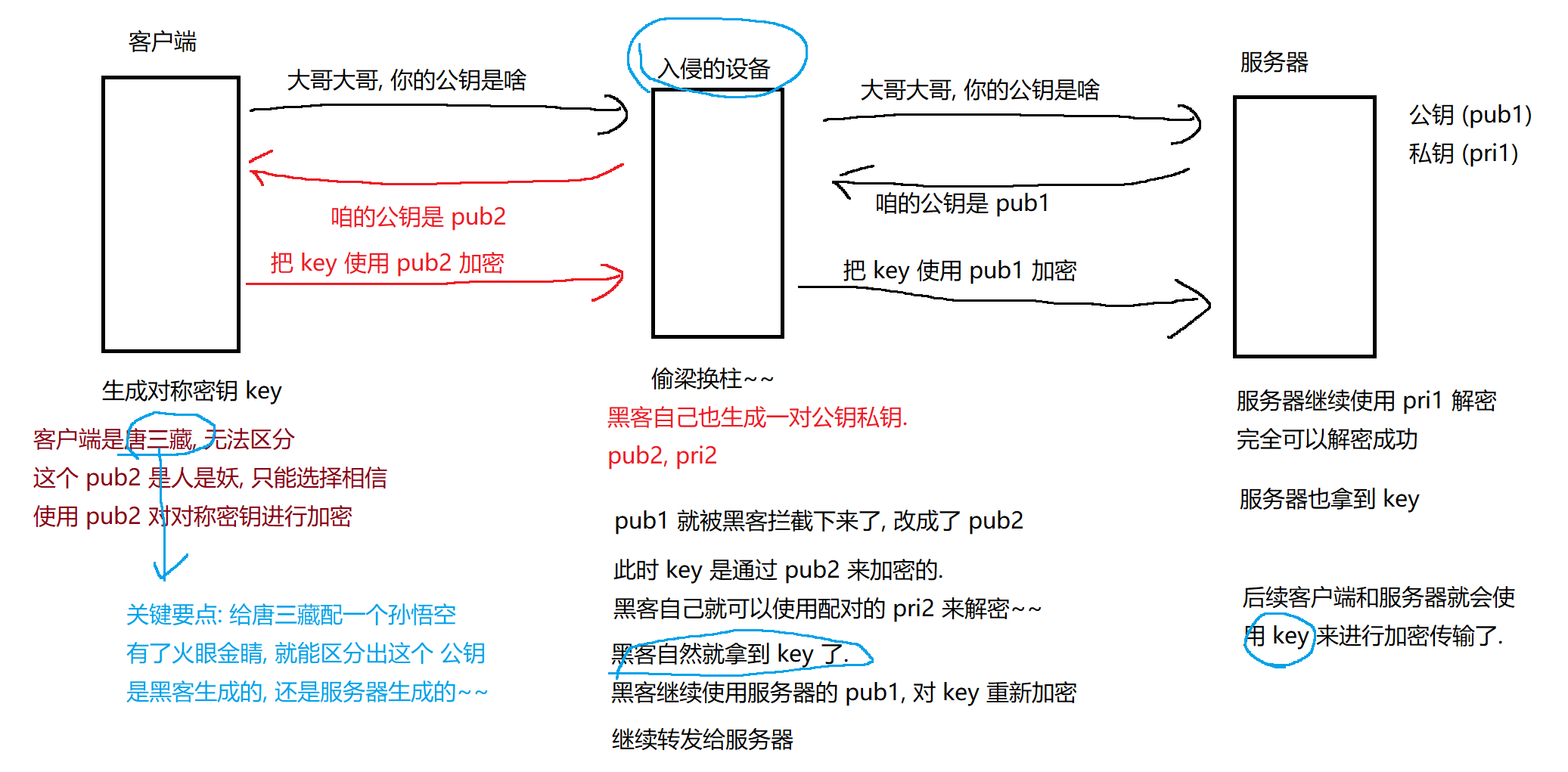
中间人攻击过程:
 引入校验机制
引入校验机制
中间人攻击的关键 在于客户端无法区分收到的公钥是否是服务器真实的公钥还是被黑客篡改的公钥 需要想办法能够对公钥是否正确 进行校验~
解决方式:
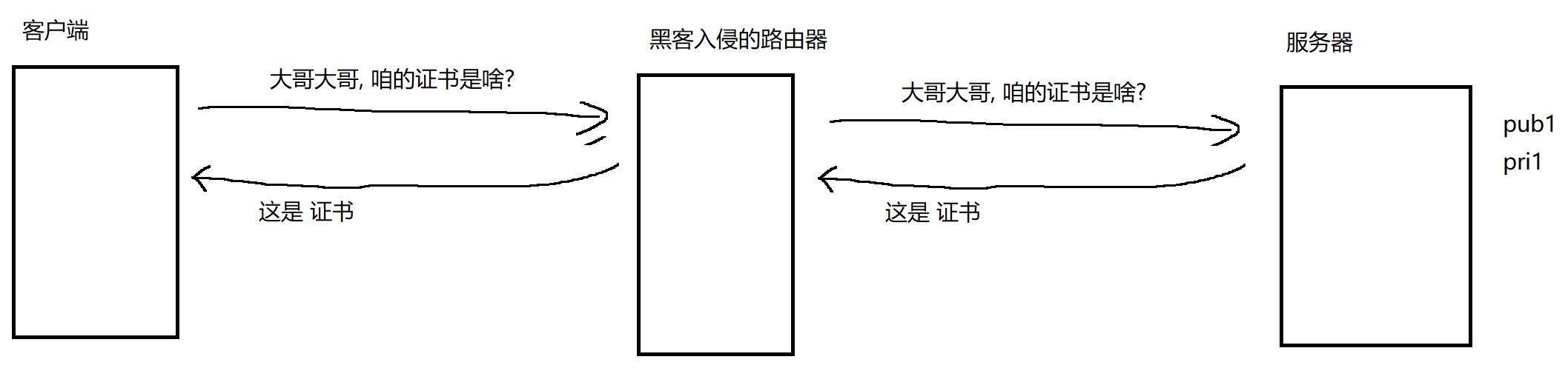
证书:(图片中黄色的部分)
数字签名:本质上是一个被加密的校验和 这个校验和是由证书的颁布机构是谁 证书的有效期是啥时候 服务器的公钥是谁 服务器的拥有者(域名)是啥 等这些关键信息作为输入算出来的
针对校验和进行加密:第三方认证机构也生成一对非对称密钥 使用自己的私钥进行加密
服务器搭建的时候 申请一次就可以了 申请到的证书 服务器保存好
"大哥大哥 公钥是啥" 变成了 "大哥大哥 证书是啥"
客户端收到证书,就要校验 客户端需要针对证书中的其他字段 使用相同的算法 再算一次校验和 得到校验和1 再通过公正机构的公钥pub2 对数字签名进行解密 得到校验和2
对比校验和1 和 校验和2 是否相同 如果相同 说明证书是没有被修改过的 如果不同 证书无效 中间被人篡改了
这种方式通俗的解释:
服务器需要像网络派出所申请一个印章(数字签名)
客户端收到消息的时候 要看这个印章是否合法
骗子也可以劫持 做出一个自己的防伪印章 但是它做出来的防伪印章 客户端用网络派出所发的公开验证器一扫 就会显示"二维码无效 非官方认证"
//合法印章就不是通过网络传输的 而是操作系统中内置的~~(安装好系统 系统就内置了一系列知名公正机构的公钥)(只要你安装的是正版系统 我们就可以信任印章的正确)
中间人攻击 只是黑客的一种攻击手段而已 黑客的攻击手段还有很多~
网络安全水是很深(bug不可能消除 漏洞始终存在 黑客也就会始终存在 例如:人类不可能消灭疾病 程序不可能消灭bug~~)