1. 项目背景
用户在众多新闻资讯中, ⼀定有更感兴趣的类别. 比如男生的历史, 军事, 足球等,⼥⽣的财经, ⼋卦, 美妆等. 如果能将用户更感兴趣的类别新闻主动筛选出来, 并进行推荐阅读, 那么点击量, 订阅量, 付费量都会有明显增长。将短文本自动进行多分类, 然后像快递⼀样的"投递"到对应的"频道"中, 因此本项目应运而生。
2. 数据集介绍
2.1 训练集数据 train.txt,共十八万条数据
2.2 测试集数据 test.txt,共10000条

2.3 验证集数据 dev.txt,共10000条

2.4 类别集合数据class.txt,共10条
3. Fasttext基线模型
3.1 数据预处理
将数据转化成fasttext需要的数据格式
文本:采用正常的连续字符串;
标签:采用labelname的格式。
python
import os
import sys
import jieba
id_to_label={}
idx=0
with open('./data/class.txt','r',encoding='utf-8') as f1:
for line in f1.readlines():
line=line.strip('\n').strip()
id_to_label[idx]=line
idx+=1
print('id_to_label:',id_to_label)
count=0
train_data=[]
with open('./data/train.txt','r',encoding='utf-8') as f2:
for line in f2.readlines():
line=line.strip('\n').strip()
sentence,label=line.split('\t')
#1.首先处理标签部分
label_id=int(label)
label_name=id_to_label[label_id]
new_label='__label__'+label_name
#2.处理文本部分,为了便于后续增加n-gram特性,可以按字划分,也可以按词划分
sent_char=' '.join(list(sentence))
#3.将文本和标签组合成fasttext规定的格式
new_sentence=new_label+' '+sent_char
train_data.append(new_sentence)
count+=1
if count%10000==0:
print(f'count={count}')
with open('./data/train_fast.txt','w',encoding='utf-8') as f3:
for data in train_data:
f3.write(data+'\n')
print('Fasttext训练数据预处理完毕!')处理后的结果如下:
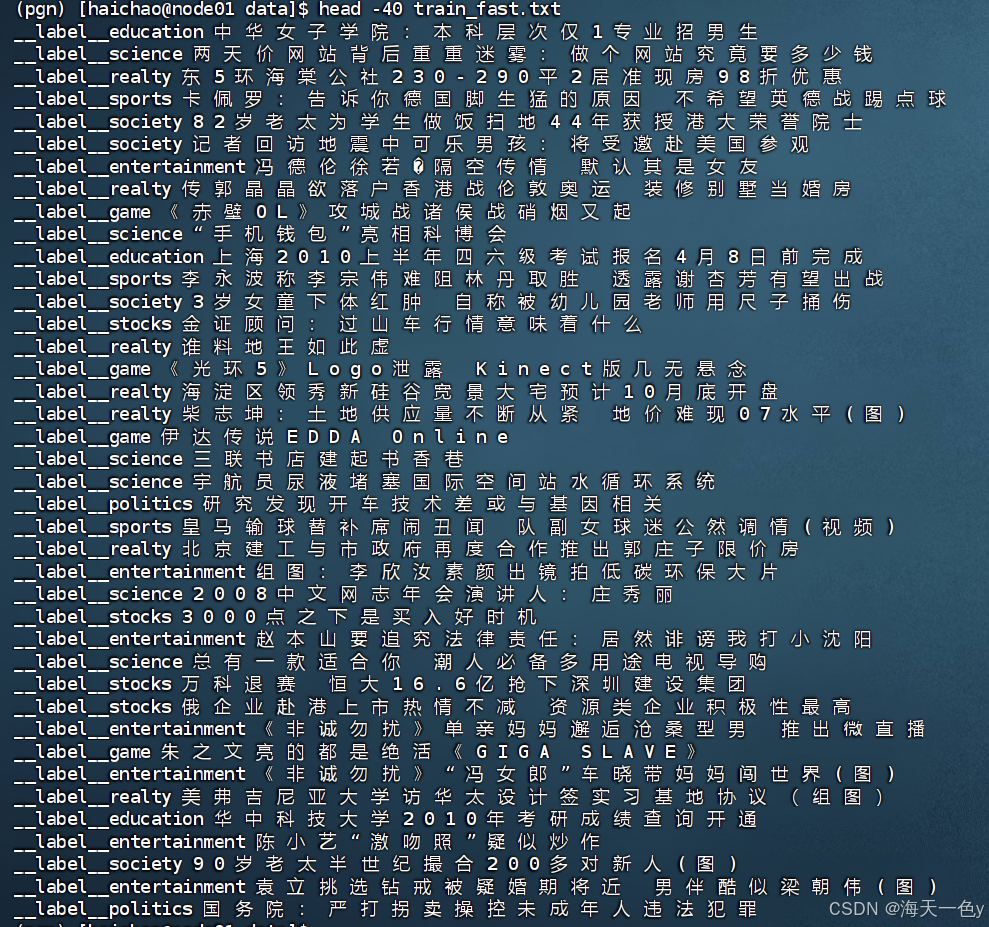
对test.txt,dev.txt采用相同的处理方法得到 test_fast.txt,dev_fast.txt.
3.2 模型构建
python
import fasttext
train_data_path='./data/train_fast.txt'
test_data_path='./data/test_fast.txt'
#开始模型训练
model=fasttext.train_supervised(input=train_data_path,wordNgrams=2)
#开始模型测试
result=model.test(test_data_path)
print(result)运行结果如下:

可以看到,在10000条的测试集上的模型精确率为91.47%,召回率为91.47%
对于任何表现良好的模型,优化的脚步都不能停止,下面开始对模型进行优化!!!
3.3 优化一
在真实的生产环境下, 对于fasttext模型一般不会采用费时费力的人工调参, 而都是用自动化最优参数搜索的模式。
python
import fasttext
import time
train_data_path ='./data/train_fast.txt'
dev_data_path='./data/dev_fast.txt'
test_data_path='./data/test_fast.txt'
#autotuneValidationFile参数需要指定验证数据集所在路径
model=fasttext.train_supervised(input=train_data_path,
autotuneValidationFile=dev_data_path,
autotuneDuration=600,
wordNgrams=3,
verbose=3)
result=model.test(test_data_path)
print(result)
#模型保存
time1=int(time.time())
model_save_path=f'./fasttext_{time1}.bin'
model.save_model(model_save_path)运行结果如下:
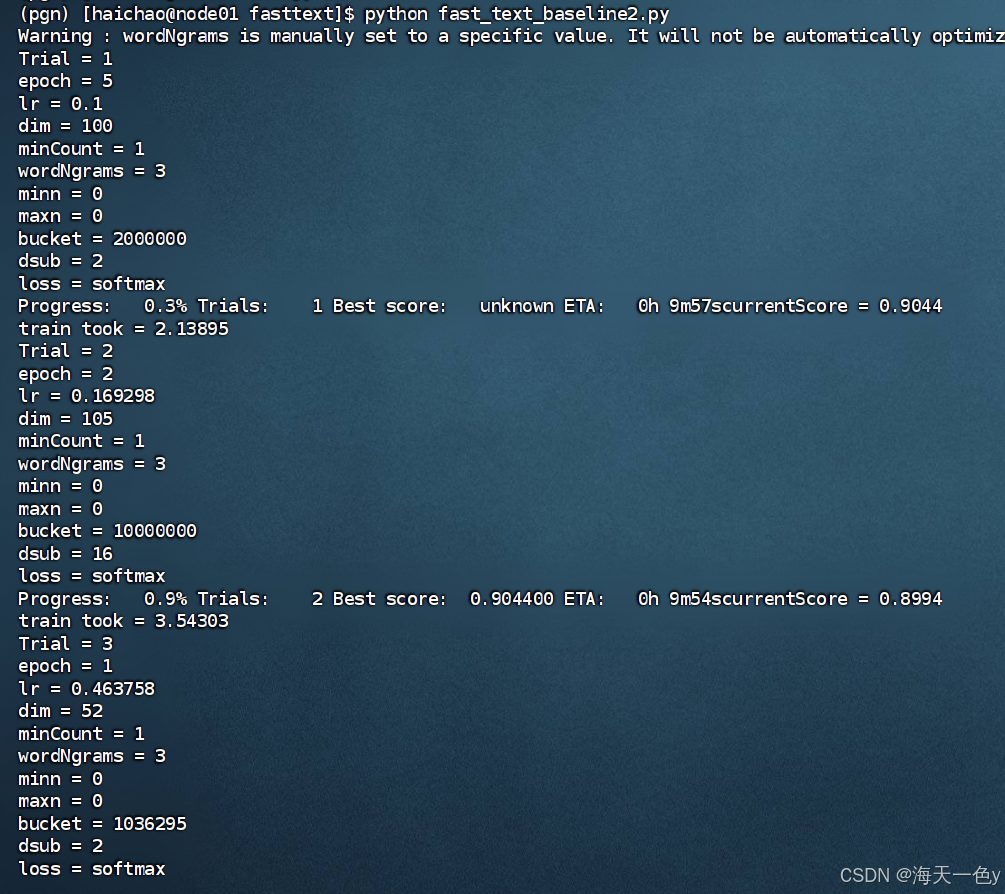
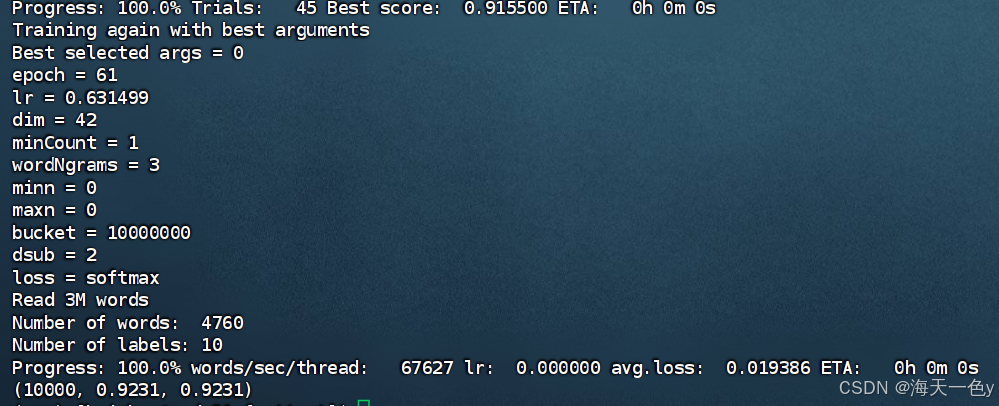
最终得到的模型精确率为92.31%,召回率为92.31%
得到的模型虽然效果好,但是占用很大的内存空间。
3.4 优化二
3.1数据预处理部分改成按词进行划分
python
import os
import sys
import jieba
id_to_label={}
idx=0
with open('./class.txt','r',encoding='utf-8') as f1:
for line in f1.readlines():
line=line.strip('\n').strip()
id_to_label[idx]=line
idx+=1
print('id_to_label:',id_to_label)
count=0
train_data=[]
#with open('./train.txt','r',encoding='utf-8') as f2:
#with open('./test.txt','r',encoding='utf-8') as f2:
with open('./dev.txt','r',encoding='utf-8') as f2:
for line in f2.readlines():
line=line.strip('\n').strip()
sentence,label=line.split('\t')
#1.首先处理标签部分
label_id=int(label)
label_name=id_to_label[label_id]
new_label='__label__'+label_name
#2.处理文本部分,为了便于后续增加n-gram特性,可以按字划分,也可以按词划分
sent_char=' '.join(jieba.lcut(sentence))
#3.将文本和标签组合成fasttext规定的格式
new_sentence=new_label+'\t'+sent_char
train_data.append(new_sentence)
count+=1
if count%10000==0:
print(f'count={count}')
#with open('./train_fast1.txt','w',encoding='utf-8') as f3:
#with open('./test_fast1.txt','w',encoding='utf-8') as f3:
with open('./dev_fast1.txt','w',encoding='utf-8') as f3:
for data in train_data:
f3.write(data+'\n')
print('Fasttext训练数据预处理完毕!')分别对train.txt,test.txt,dev.txt 进行处理分别得到train_fast1.txt,test_fast1.txt,dev_fast1.txt.
再次采用优化一中的方法,将数据文件改为train_fast1.txt,test_fast1.txt,dev_fast1.txt.
python
import fasttext
import time
train_data_path='./data/train_fast1.txt'
dev_data_path='./data/dev_fast1.txt'
test_data_path='./data/test_fast1.txt'
model=fasttext.train_supervised(input=train_data_path,
autotuneValidationFile=dev_data_path,
autotuneDuration=600,
wordNgrams=2,
verbose=3)
result=model.test(test_data_path)
print(result)
time1=int(time.time())
model_save_path=f'./toutiao_fasttext_{time1}.bin'
model.save_model(model_save_path)运行结果如下:
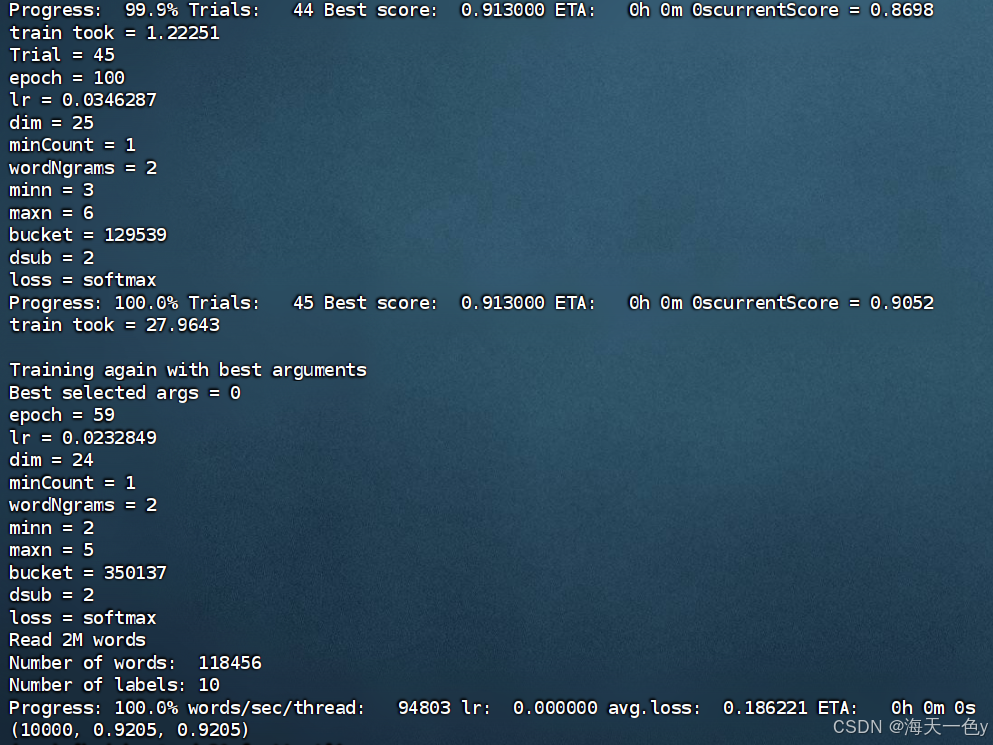
优化二得到的模型的精确率为92.05%,召回率为92.05%
查看模型大小,模型大小为45M,可以看出使用词向量得到的模型要小得多!!!

3.5模型部署
- 编写主服务逻辑代码 app.py
python
import time
import jieba
import fasttext
#服务框架使用Flask,导入工具包
from flask import Flask
from flask import request
app=Flask(__name__)
#导入发送http请求的requests工具
import requests
#加载自定义的停用词字典
jieba.load_userdict("./data/stopwords.txt")
#提供已训练好的模型路径+名字
model_save_path="toutiao_fasttext_1763748973.bin"
#实例化fasttext对象,并加载模型参数用于推断,提供服务请求
model=fasttext.load_model(model_save_path)
print('FastText模型实例化完毕...')
#设定投满分服务的路由和请求方法
@app.route('/v1/main_server/',methods=['POST'])
def main_server():
#接收来自请求方发送的服务字段
uid=request.form['uid']
text=request.form['text']
#对请求文本进行处理,因为前面加载的是基于词的模型,所以这里用jieba进行分词.
input_text=' '.join(jieba.lcut(text))
#执行预测
res=model.predict(input_text)
predict_name=res[0][0]
return predict_name- 启动Flask服务
bash
gunicorn -w 1 -b 0.0.0.0:5000 app:app- 编写测试代码 test.py
python
import requests
import time
#定义请求url和传入的data
url="http://0.0.0.0:5000/v1/main_server/"
data={"uid":"toumanfen",'text':'公共英语(PETS)写作中常见的逻辑词汇汇总'}
start_time=time.time()
#向服务发送post请求
res=requests.post(url,data=data)
cost_time=time.time()-start_time
#打印返回的结果
print('输入文本:',data['text'])
print('分类结果:',res.text)
print('单条样本预测耗时:',cost_time*1000,'ms')- 执行测试,并检验结果。
多测试几次,运行结果如下:
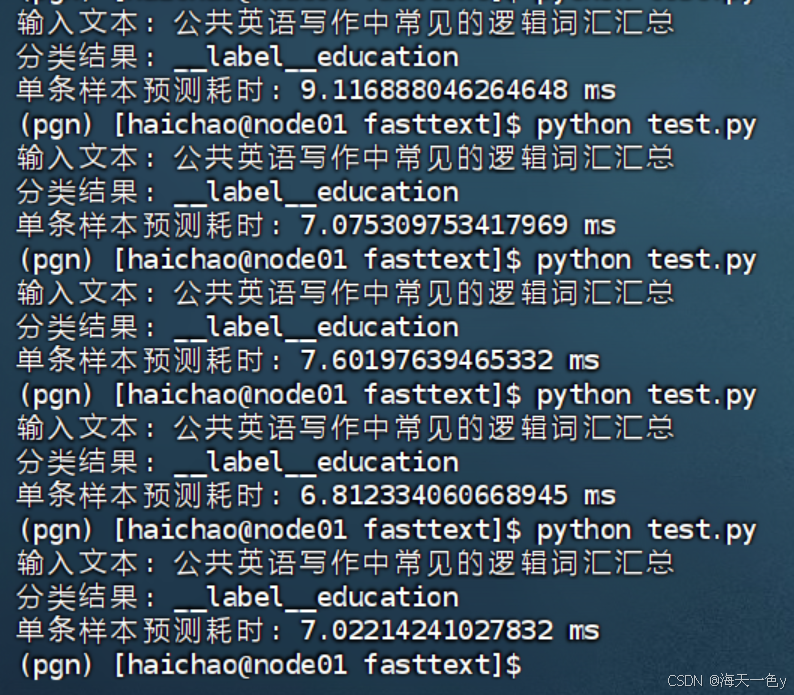
平均查询时间为6~9s.
4.Bert模型
Bert模型今天依然活跃在工业界的一线,小巧灵活。
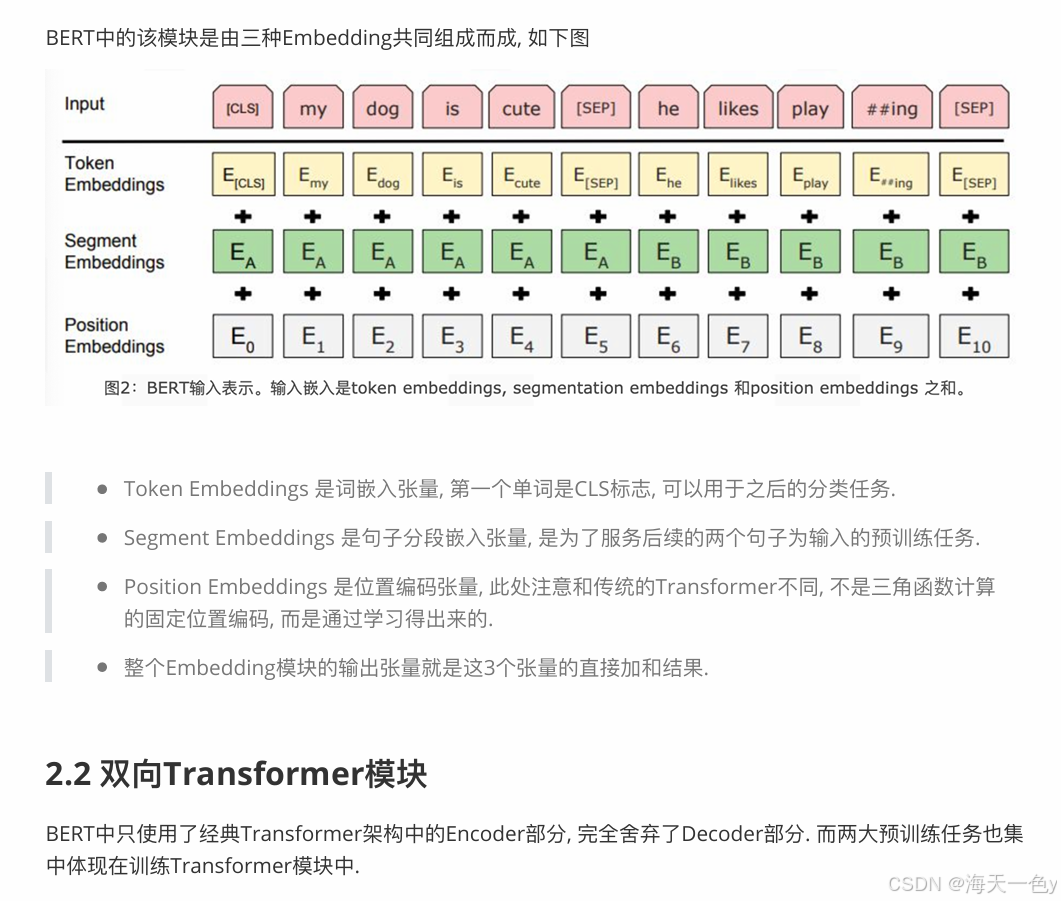 bert模型词嵌入部分
bert模型词嵌入部分
采用Bert模型对文本自动分类投递项目进行处理
4.1 编写工具函数 utils.py
python
from tqdm import tqdm
import torch
import time
from datetime import timedelta
# 常量定义(根据你的实际需要调整)
UNK = '<UNK>'
PAD = '<PAD>'
CLS = '[CLS]'
def build_vocab(file_path,tokenizer,max_size,min_freq):
'''
构建词汇表
:param file_path: 数据集文件路径
:param tokenizer: 分词器
:param max_size: 词汇表最大大小
:param min_freq: 词汇表最小频率
:return: 词汇表
'''
vocab_dic={}
with open(file_path,'r',encoding='utf-8') as f:
for line in f:
lin=line.strip()
if not lin:
continue
content=lin.split('\t')[0]
for word in tokenizer(content):
#统计单词出现频率
vocab_dic[word]=vocab_dic.get(word,0)+1
vocab_list=sorted([_ for _ in vocab_dic.items() if _[1]>=min_freq],
key=lambda x:x[1],reverse=True)[:max_size]
vocab_dic={word_count[0]:i for i,word_count in enumerate(vocab_list)}
vocab_dic.update({UNK:len(vocab_dic),PAD:len(vocab_dic)+1})
return vocab_dic
def build_dataset(config):
def load_dataset(path,pad_size=32):
contents=[]
with open(path,'r',encoding='utf-8') as f:
for line in tqdm(f):
line=line.strip()
if not line:
continue
content,label=line.split('\t')
token=config.tokenizer.tokenize(content)
token=[CLS]+token
seq_len=len(token)
mask=[]
token_ids=config.tokenizer.convert_tokens_to_ids(token)
if pad_size:
if len(token)<pad_size:
mask=[1]*len(token_ids)+[0]*(pad_size-len(token))
token_ids+=[0]*(pad_size-len(token))
else:
mask=[1]*pad_size
token_ids=token_ids[:pad_size]
seq_len=pad_size
contents.append((token_ids,int(label),seq_len,mask))
return contents
train=load_dataset(config.train_path,config.pad_size)
dev=load_dataset(config.dev_path,config.pad_size)
test=load_dataset(config.test_path,config.pad_size)
return train,dev,test
class DatasetIterater(object):
def __init__(self,batches,batch_size,device,model_name):
self.batch_size=batch_size
self.batches=batches
self.model_name=model_name
self.n_batches=len(batches)//batch_size
self.residue=False
if len(batches)%self.n_batches!=0:
self.residue=True
self.index=0
self.device=device
def _to_tensor(self,datas):
x=torch.LongTensor([_[0] for _ in datas]).to(self.device)
y=torch.LongTensor([_[1] for _ in datas]).to(self.device)
#pad前的长度
seq_len=torch.LongTensor([_[2] for _ in datas]).to(self.device)
if self.model_name=='bert' or self.model_name=='multi_task_bert':
mask=torch.LongTensor([_[3] for _ in datas]).to(self.device)
return(x,seq_len,mask),y
def __next__(self):
if self.residue and self.index==self.n_batches:
batches=self.batches[self.index*self.batch_size:len(self.batches)]
self.index+=1
batches=self._to_tensor(batches)
return batches
elif self.index>=self.n_batches:
self.index=0
raise StopIteration
else:
batches=self.batches[self.index*self.batch_size:(self.index+1)*self.batch_size]
self.index+=1
batches=self._to_tensor(batches)
return batches
def __iter__(self):
return self
def __len__(self):
if self.residue:
return self.n_batches+1
else:
return self.n_batches
def build_iterator(dataset,config):
iter=DatasetIterater(dataset,config.batch_size,config.device,config.model_name)
return iter
def get_time_dif(start_time):
end_time=time.time()
time_dif=end_time-start_time
return timedelta(seconds=int(round(time_dif)))4.2 编写模型类代码 bert.py(这里边采用Roberta_chinese预训练模型)
python
import torch
import torch.nn as nn
import os
from transformers import BertModel,BertTokenizer,BertConfig
class Config(object):
def __init__(self,dataset):
self.model_name='bert'
self.data_path='/home/haichao/MLSTAT/myproject/toutiao/data'
self.train_path=self.data_path+'/train.txt'
self.dev_path=self.data_path+'/dev.txt'
self.test_path=self.data_path+'/test.txt'
self.class_list=[x.strip() for x in open(self.data_path+'/class.txt').readlines()]
self.save_path='/home/haichao/MLSTAT/myproject/toutiao/src/saved_dict'
if not os.path.exists(self.save_path):
os.makedirs(self.save_path)
self.save_path+='/'+self.model_name+'.pt'
self.device=torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.require_improvement=1000
self.num_classes=len(self.class_list)
self.num_epochs=3
self.batch_size=128
self.pad_size=32
self.learning_rate=5e-5
self.bert_path='/mnt/workspace/toutiao/data/bert_pretrain'
self.tokenizer=BertTokenizer.from_pretrained(self.bert_path)
self.bert_config=BertConfig.from_pretrained(self.bert_path+'/bert_config.json')
self.hidden_size=768
class Model(nn.Module):
def __init__(self,config):
super(Model,self).__init__()
self.bert=BertModel.from_pretrained(config.bert_path,config=config.bert_config)
self.fc=nn.Linear(config.hidden_size,config.num_classes)
def forward(self,x):
context=x[0]
mask=x[2]
out=self.bert(context,attention_mask=mask)
out=self.fc(out.pooler_output)
return out
4.3 编写训练函数,测试函数和验证函数 train_eval.py
python
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from sklearn import metrics
import time
from utils import get_time_dif
from torch.optim import AdamW
from tqdm import tqdm
import math
import logging
def loss_fn(outputs,labels):
return F.cross_entropy(outputs,labels)
def train(config,model,train_iter,dev_iter):
start_time=time.time()
param_optimizer=list(model.named_parameters())
no_decay=['bias','LayerNorm.bias','LayerNorm.weight']
optimizer_grouped_parameters=[
{'params':[p for n,p in param_optimizer
if not any(nd in n for nd in no_decay)],'weight_decay':0.01},
{'params':[p for n,p in param_optimizer
if any(nd in n for nd in no_decay)],'weight_decay':0.0}
]
optimizer=AdamW(optimizer_grouped_parameters,lr=config.learning_rate)
total_batch=0
dev_best_loss=float('inf')
last_improve=0
flag=False
model.train()
for epoch in range(config.num_epochs):
total_batch=0
print('Epoch [{}/{}]'.format(epoch+1,config.num_epochs))
for i,(trains,labels) in enumerate(tqdm(train_iter)):
outputs=model(trains)
model.zero_grad()
loss=loss_fn(outputs,labels)
loss.backward()
optimizer.step()
if total_batch % 200 ==0 and total_batch!=0:
true=labels.data.cpu()
predic=torch.max(outputs.data,1)[1].cpu()
train_acc=metrics.accuracy_score(true,predic)
dev_acc,dev_loss=evaluate(config,model,dev_iter)
if dev_loss<dev_best_loss:
dev_best_loss=dev_loss
torch.save(model.state_dict(),config.save_path)
improve='*'
last_improve=total_batch
else:
improve=''
time_dif=get_time_dif(start_time)
msg='Iter:{0:>6},Train Loss:{1:>5.2},Train Acc:{2:>6.2%},Dev Loss:{3:>5.2},Dev Acc:{4:>6.2%},Time:{5} {6}'
print(msg.format(total_batch,loss.item(),train_acc,dev_loss,dev_acc,time_dif,improve))
model.train()
total_batch+=1
if total_batch-last_improve>config.require_improvement:
print('No optimization for a long time,auto-stopping...')
flag=True
break
if flag:
break
def test(config,model,test_iter):
model.eval()
start_time=time.time()
test_acc,test_loss,test_report,test_confusion=evaluate(config,model,test_iter,test=True)
msg='Test Loss:{0:>5.2},Test Acc:{1:>6.2%}'
print(msg.format(test_loss,test_acc))
print('Precision,Recall,F1-Score...')
print(test_report)
print('Confusion Matrix...')
print(test_confusion)
time_dif=get_time_dif(start_time)
print('Time usage:',time_dif)
def evaluate(config,model,data_iter,test=False):
model.eval()
loss_total=0
predict_all=np.array([],dtype=int)
labels_all=np.array([],dtype=int)
with torch.no_grad():
for texts,labels in data_iter:
outputs=model(texts)
loss=F.cross_entropy(outputs,labels)
loss_total+=loss.item()
labels=labels.data.cpu().numpy()
predic=torch.max(outputs.data,1)[1].cpu().numpy()
labels_all=np.append(labels_all,labels)
predict_all=np.append(predict_all,predic)
acc=metrics.accuracy_score(labels_all,predict_all)
if test:
report=metrics.classification_report(labels_all,predict_all,target_names=config.class_list,digits=4)
confusion=metrics.confusion_matrix(labels_all,predict_all)
return acc,loss_total/len(data_iter),report,confusion
return acc,loss_total/len(data_iter)4.4 编写运行主函数 main.py
python
import time
import torch
import numpy as np
from train_eval import train,test
from importlib import import_module
import argparse
from utils import build_dataset,build_iterator,get_time_dif
parser=argparse.ArgumentParser(description='Chinese Text Classification')
parser.add_argument('--model',type=str,required=True,help='choose a model:bert')
args=parser.parse_args()
if __name__=='__main__':
dataset='toutiao'
if args.model=='bert':
model_name='bert'
x=import_module('models.'+model_name)
config=x.Config(dataset)
np.random.seed(1)
torch.manual_seed(1)
torch.cuda.manual_seed_all(1)
torch.backends.cudnn.deterministic=True
print("Loading data for Bert Model...")
train_data,dev_data,test_data=build_dataset(config)
train_iter=build_iterator(train_data,config)
dev_iter=build_iterator(dev_data,config)
test_iter=build_iterator(test_data,config)
model=x.Model(config).to(config.device)
train(config,model,train_iter,dev_iter,test_iter)
test(config,model,test_iter)4.5 运行主函数
bash
python main.py --model bert模型训练过程:
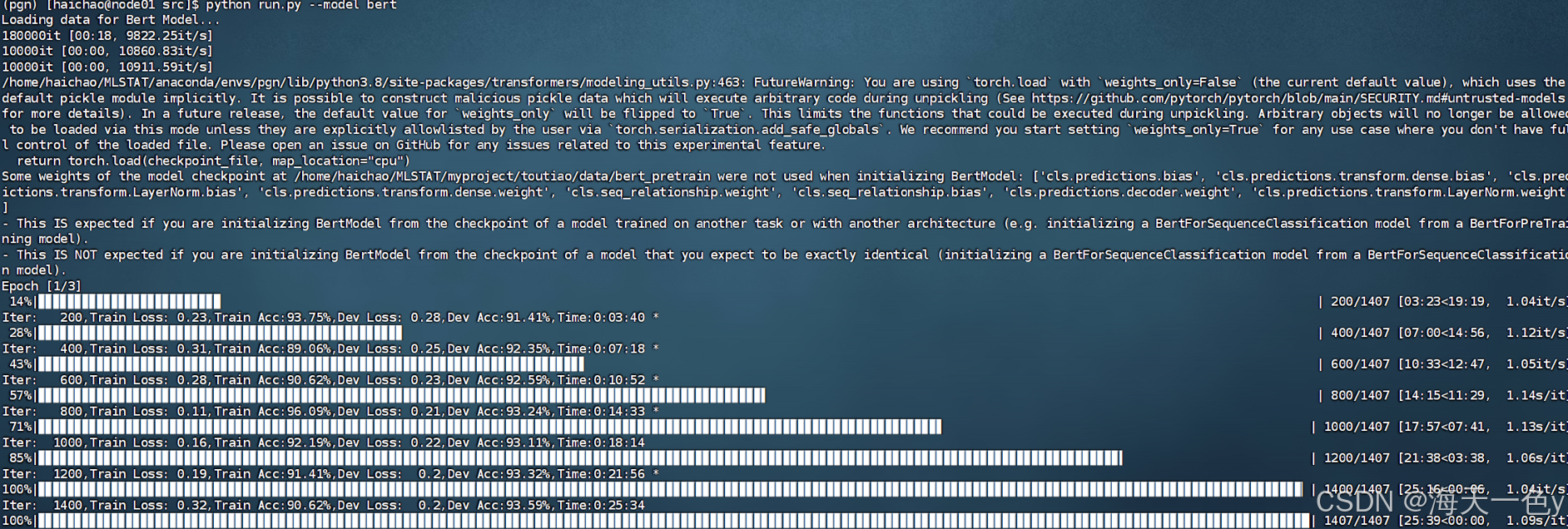
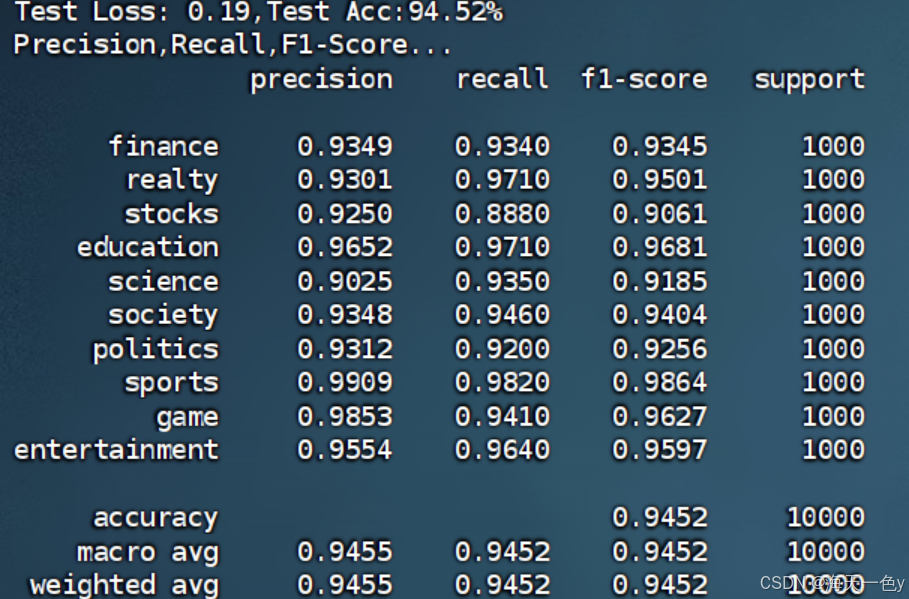
最终结果:测试集准确率为94.52%
不同类别对应的精确率、召回率和F1值如下:
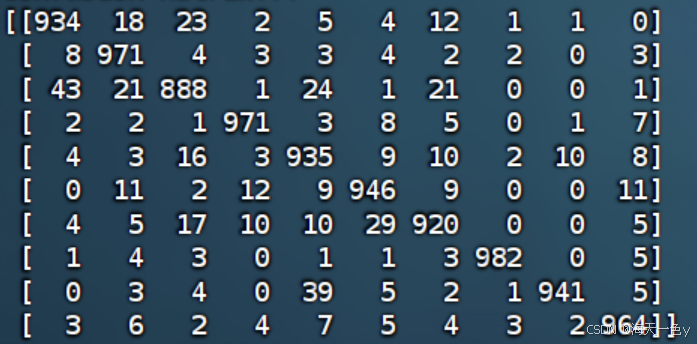
混淆矩阵如下:
需要原始数据和预训练模型的小伙伴可以私信我哦~