何恺明团队再次推出创新成果,延续其"回归本质"的研究理念,提出"Just image Transformers"(JiT)框架。
该技术突破性地使扩散模型能够直接生成清晰图像,而非传统噪声或含噪量预测,为高维自然数据生成开辟了更简洁高效的路径。
"扩散模型+Transformer"架构凭借其卓越的生成质量、强大的扩展性和精准的多模态控制能力,目前已广泛应用于高分辨率图像生成、三维重建以及自监督去噪等多个前沿领域,成为学术界持续聚焦的研究热点。
这一技术组合正推动着生成式AI的边界不断扩展。
DDT: Decoupled Diffusion Transformer
主要内容:
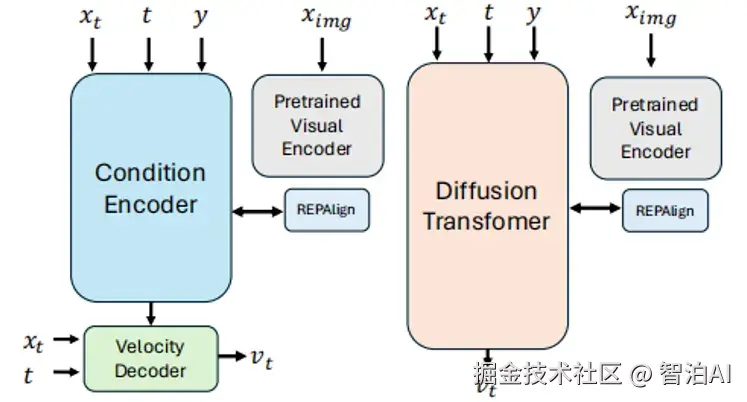
本研究创新性地引入解耦扩散 Transformer(DDT),其采用专用条件编码器实现语义特征提取,结合速度解码器精准还原高频细节,从而有效克服传统模型的优化瓶颈。
实验结果表明,在 ImageNet 数据集上,该模型在 256×256 分辨率下取得 FID 1.31,512×512 分辨率下 FID 降至 1.28,同时训练收敛速度显著提升至 4 倍,并借助统计动态规划技术进一步优化推理效率。
The Ingredients for Robotic Diffusion Transformers
主要内容:
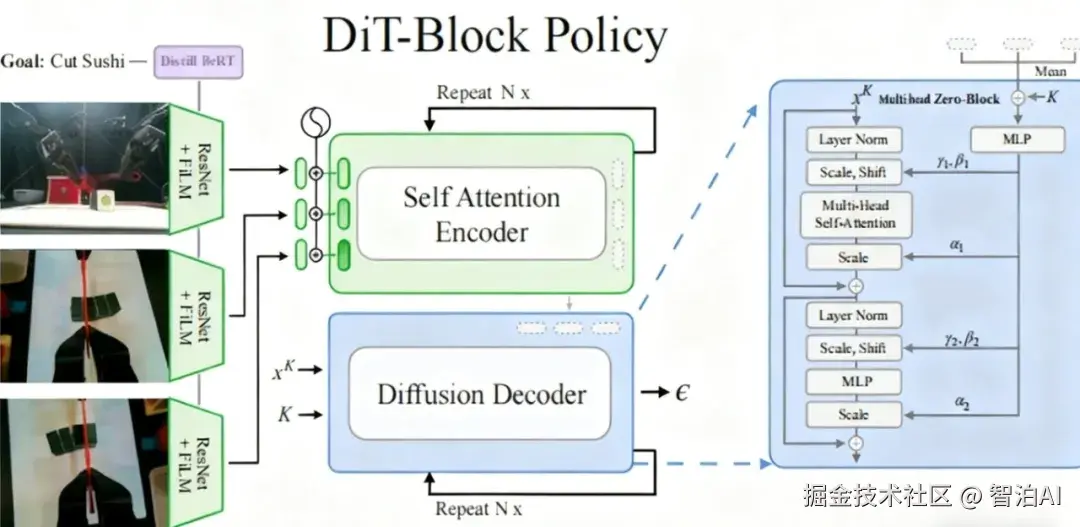
面向机器人操作任务,本研究设计DiT-Block Policy架构,结合Transformer的可扩展优势与扩散模型的生成特性。
通过adaLN-Zero注意力块实现训练稳定性,利用ResNet架构处理多视角相机输入,在双臂ALOHA与单臂Franka机器人平台验证多任务执行能力,性能较现有基线提升20%,并公开BiPlay语言标注数据集。
TinyFusion: Diffusion Transformers Learned Shallow
主要内容:
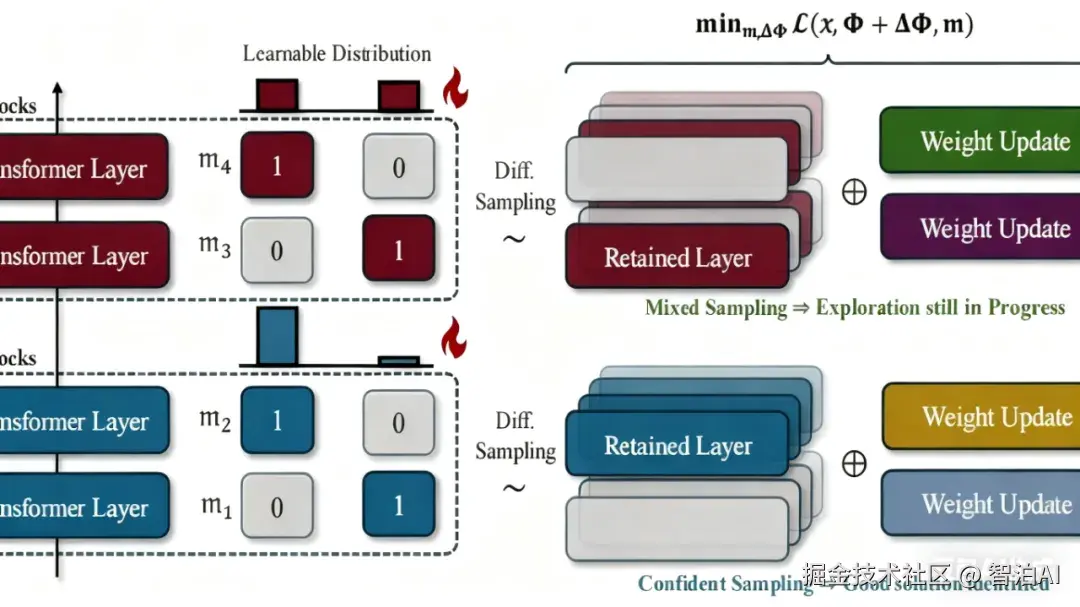
研究团队创新性地开发了深度剪枝框架TinyFusion,该方法采用可微分采样技术并结合参数联合优化策略,有效识别并压缩扩散Transformer中的冗余层级。
在显著降低计算资源需求的前提下(仅需7%的原始预训练成本),该技术成功推动DiT-XL模型FID指标优化至2.86,同时在DiT、MAR等多种架构中实现推理速度提升2倍。
此外,通过引入掩码知识蒸馏机制,进一步强化了模型性能的恢复能力。
Effective Diffusion Transformer Architecture for Image Super-Resolution
主要内容:
设计用于图像超分辨率的扩散 Transformer(DiT-SR),创新性地融合 U 型架构的多尺度特征提取能力与各向同性设计优势,通过空间-频率域协同优化提升重建质量。
提出频率自适应时间步调节模块 AdaFM 替代传统 AdaLN,动态适应不同频段特征的学习需求,显著提升训练稳定性和收敛效率。
在 RealSR 等数据集上,该模型以仅 5% 的参数量超越多数现有方法,实现从 scratch 训练的高性能超分,同时支持计算效率与重建精度的双重突破。

·更多AI大模型学习视频及资源,都在智泊AI。