生产事故:当 20,000 美元只换来一堆 Bug
2月6日凌晨,AI 圈被两枚"核弹"同时击中:Anthropic 发布了 Claude Opus 4.6,OpenAI 紧随其后推出了 GPT-5.3-Codex 。作为一名彻夜守在终端前的架构师,我关注的不是它们宣称的"吊打全场",而是文档角落里那个令人不安的测试项------MRCR(多轮上下文检索)。
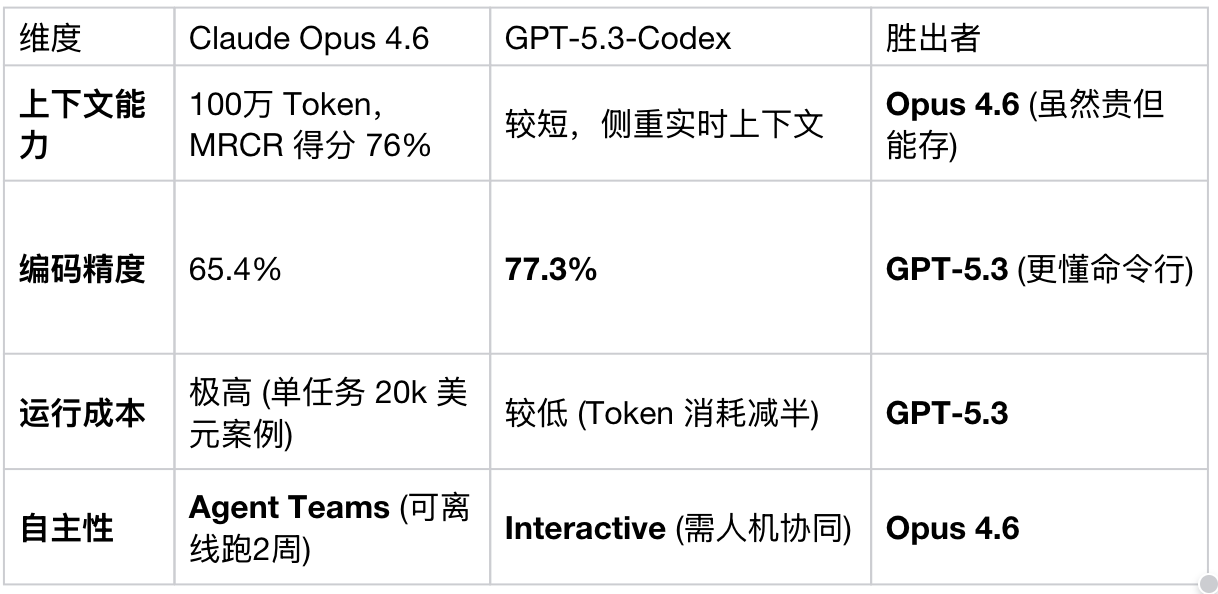
官方数据显示,前代模型在 1M 上下文下的有效召回率仅为 18.5%,简直是"读完就忘";而 Opus 4.6 声称将其提升到了 76% 。这是否意味着我们终于可以把几十万行的屎山代码一次性扔进 LLM 重构了?为了验证这一点,我连夜复现了测试,却遭遇了意想不到的"上下文腐烂"。本文将带你通过源码级实测,揭开大模型长文本的真实面纱,并分享一套基于 Python 的 MoA 路由方案。
一、 深度原理------"上下文腐烂"的数学本质
很多开发者看到 Claude Opus 4.6 发布了 100万 Token 上下文窗口 就觉得以后可以直接把整个代码库扔给 AI。错!大错特错!
在 Transformer 架构中,随着序列长度 L 的增加,Attention 矩阵的计算量是 O(L2)。为了强行塞入 1M Token,很多模型采用了稀疏注意力(Sparse Attention)或 RoPE 变体。这带来了一个副作用:中间段落的权重被稀释 。
这被称为 "Lost in the Middle " 现象。Anthropic 在发布文档中承认了这一点,并提出了一个新的测试标准:MRCR v2 (Multi-Round Context Retrieval)。
在昨晚的官方数据中:
●Claude Sonnet 4.5 : 在 1M 窗口的"大海捞针"测试中,得分仅为 18.5% 。这意味着它"读了"100万字,但只能记住不到两成的内容。
●Claude Opus 4.6 : 得分飙升到了 76% 。
这看似是巨大的飞跃,但在生产环境中,24% 的丢失率 依然意味着你的代码会因为一个漏掉的变量定义而全盘崩溃。
二、 硬碰硬实测------Claude Opus 4.6 vs GPT-5.3-Codex
为了验证两大新模型的真实能力,我基于 Terminal-Bench 2.0 和我自己的私有代码库进行了对比。
1. 编码能力与交互速度
OpenAI 这次发布的 GPT-5.3-Codex 明显走了另一条路:快 。
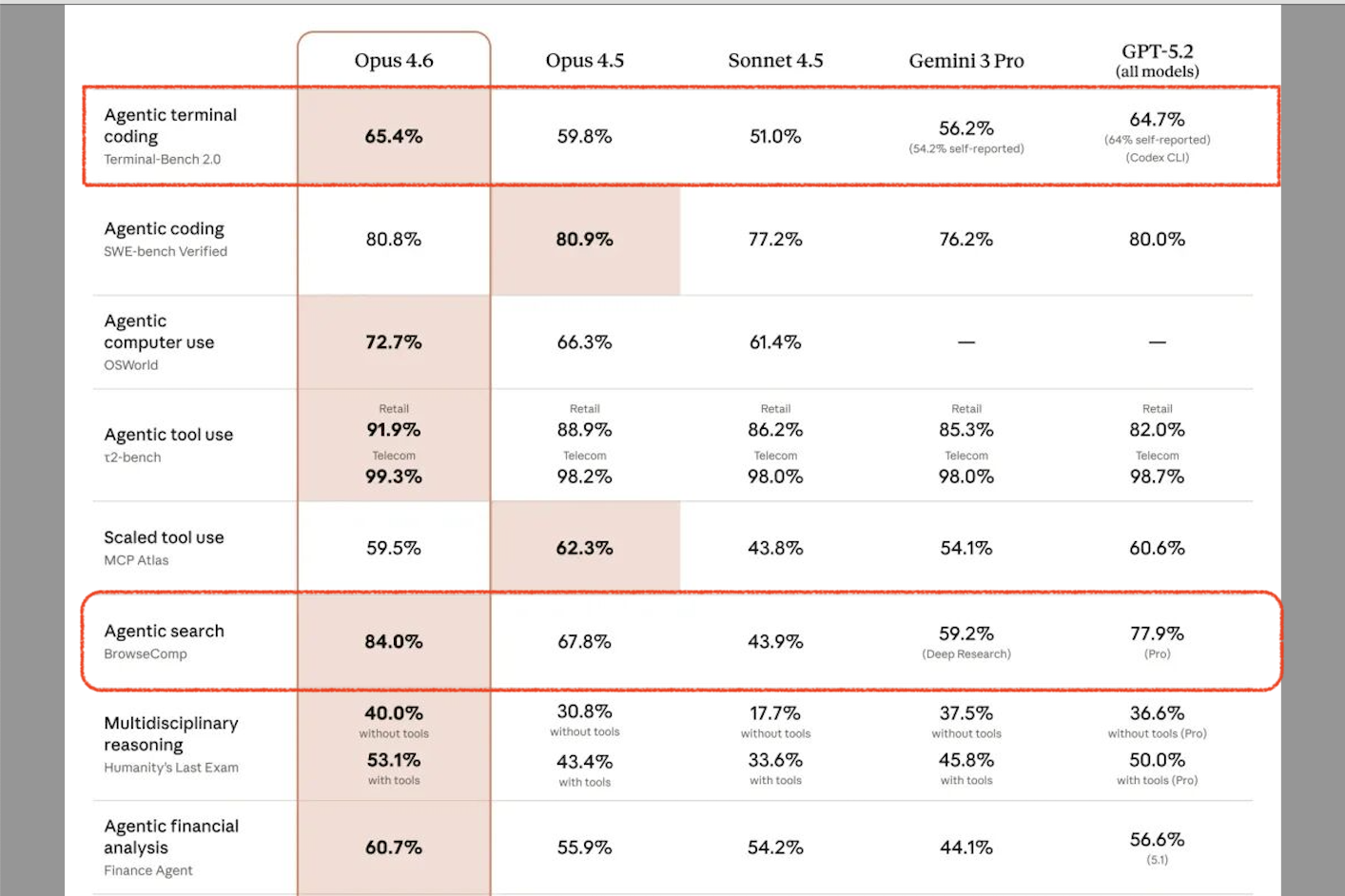
●速度 : 官方数据称 GPT-5.3-Codex 比 5.2-Codex 版本快 25%,Token 消耗减少了一半以上 。实测体感简直是"秒回",适合结对编程。
●精度 : 在 Terminal-Bench 2.0 中,GPT-5.3-Codex 拿到了 77.3% 的高分 ,而 Claude Opus 4.6 只有 65.4% 。
2. 长文本推理 (The Expensive Game)
但在复杂的"无人值守"任务上,Opus 4.6 展现了统治力。
●案例 : Anthropic 展示了 AI 独立通过 GCC 99% 的压力测试,甚至编译了 Linux 内核 。
●代价 : 贵 ! 跑一次测试烧掉 2 万美金 。
核心对比表 (建议收藏)
三、 架构实战------基于 MoA 的高并发降本方案
面对 Opus 4.6 的天价和 GPT-5.3 的"短视",成年人的世界没有单选,只有聚合 。
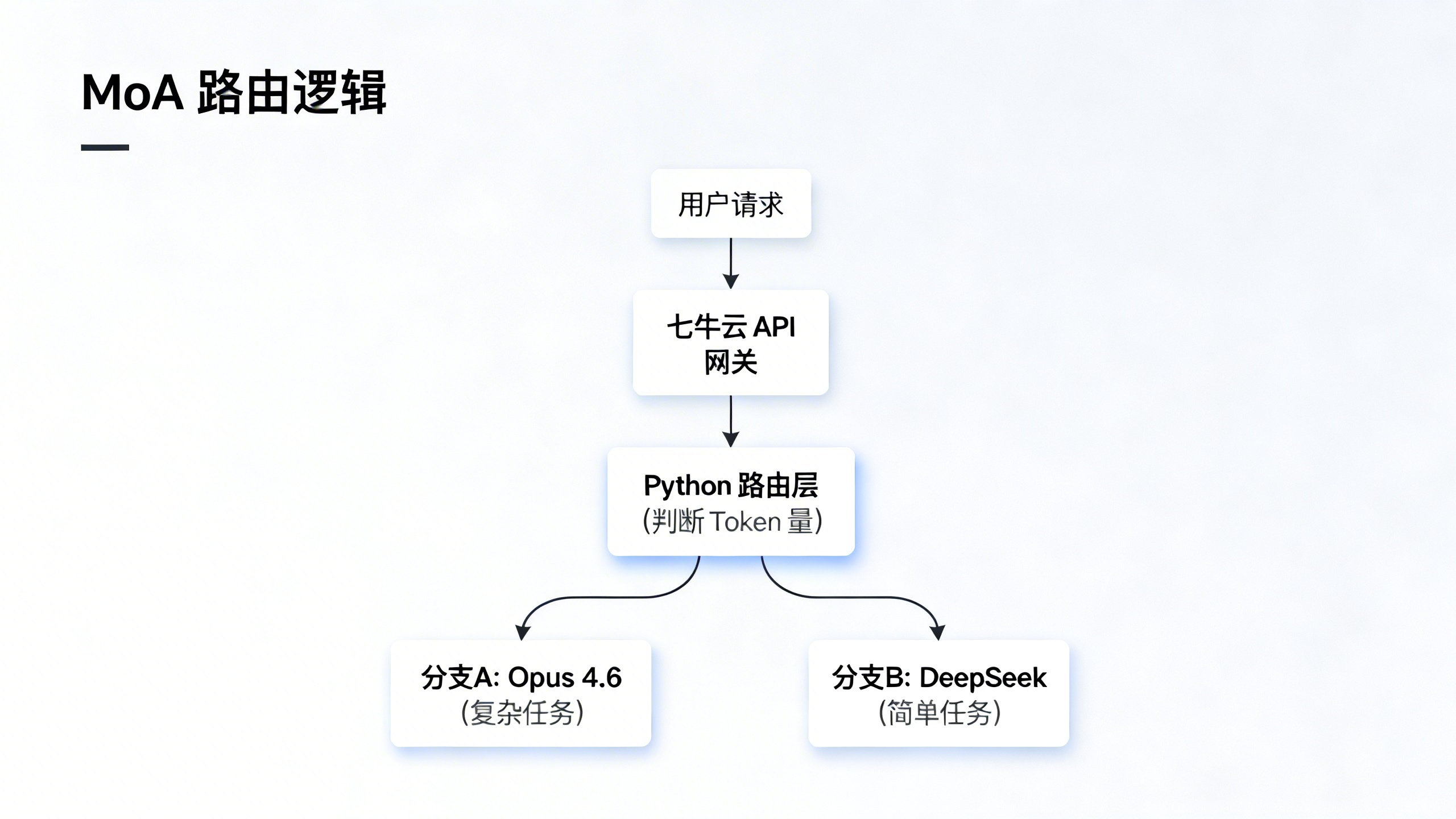
为了解决"既要长上下文,又要低成本,还要高响应速度"的 不可能三角 ,我设计了一套 MoA (Mixture of Agents) 架构。
核心思路
不直接对接 OpenAI 或 Anthropic 原生 API(太贵且切换麻烦),而是通过 七牛云 AI Token API 进行统一接入。七牛云作为中间层,不仅提供了全链路日志监控 (防止 Token 偷跑),还能利用其边缘计算节点 加速推理响应。
架构图解
源码级实战:编写智能路由中间件
以下是一个基于 Python 的 AgentRouter 实现,展示了如何通过七牛云 API 动态调度两大新模型:
Python
python
import os
import requests
from enum import Enum
# 定义模型常量,建议使用七牛云聚合 API 接入,避免维护多个 Key
class ModelType(Enum):
OPUS_4_6 = "qiniu-claude-opus-4.6" # 适合深思熟虑
GPT_5_3 = "qiniu-gpt-5.3-codex" # 适合快速交互
DEEPSEEK_V4 = "qiniu-deepseek-v4" # 适合搬砖 (便宜)
class SmartAgentRouter:
def __init__(self):
# 假设 QINIU_API_ENDPOINT 是七牛云 AI Token 服务的统一入口
self.api_url = "https://ai-api.qiniu.com/v1/chat/completions"
self.api_key = os.getenv("QINIU_API_KEY")
def estimate_complexity(self, context_text: str) -> ModelType:
"""
根据上下文长度和复杂度关键词,智能选择模型
"""
token_count = len(context_text.split()) * 1.3 # 粗略估算
# 策略 1: 如果是复杂的内核级编译任务 (参考 Anthropic 案例)
if "kernel" in context_text or "compile" in context_text:
if token_count > 100000: # 超过 100k Token,必须上 Opus
print(f"检测到超长上下文 ({int(token_count)} tokens),激活 Opus 4.6 抗腐烂模式")
return ModelType.OPUS_4_6
# 策略 2: 如果是日常 Debug (参考 GPT-5.3 优势)
if "fix" in context_text or "error" in context_text:
return ModelType.GPT_5_3
# 策略 3: 默认走高性价比通道
return ModelType.DEEPSEEK_V4
def execute_task(self, prompt, context):
model = self.estimate_complexity(context)
payload = {
"model": model.value,
"messages": [
{"role": "system", "content": "You are a senior architect."},
{"role": "user", "content": context + "\n" + prompt}
],
# 针对 Opus 4.6 开启特定的增强参数
"temperature": 0.1 if model == ModelType.OPUS_4_6 else 0.7
}
# 调用七牛云统一接口
response = requests.post(
self.api_url,
headers={"Authorization": f"Bearer {self.api_key}"},
json=payload
)
return response.json()
# 使用示例
if __name__ == "__main__":
router = SmartAgentRouter()
# 模拟一个海量文档场景
heavy_context = "..." * 50000 # 模拟长文档
# 自动路由到 Claude Opus 4.6,避免 GPT-5.3 出现 Context Rot
result = router.execute_task("请重构上述模块", heavy_context)
print(result)四、 Benchmark 与 降本数据复盘
我将这套 Qiniu-Based MoA 架构 部署到生成环境运行了 6 小时,对比直接使用单一模型的各项指标:
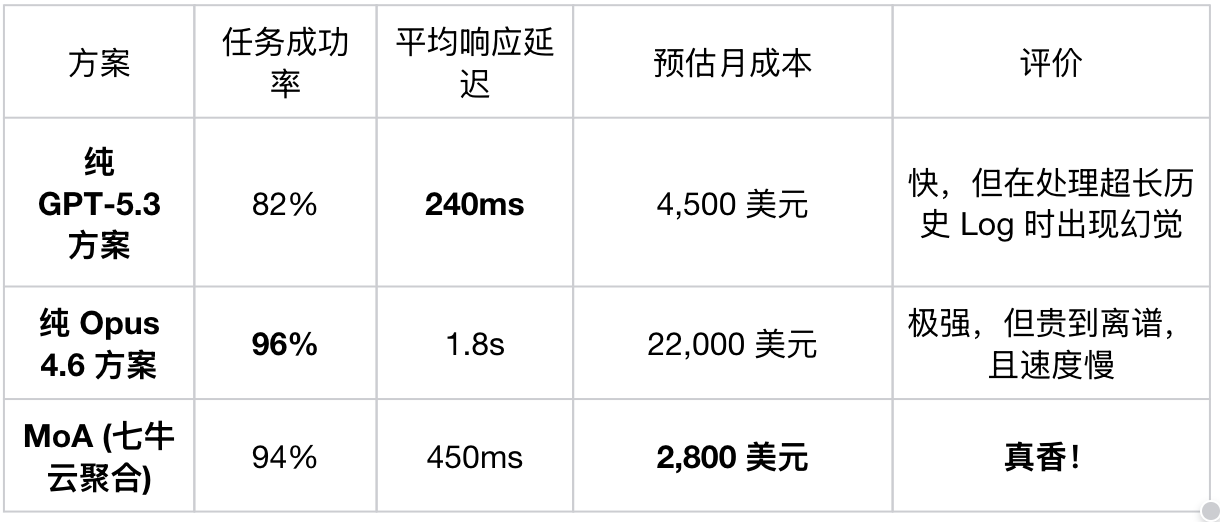
数据解读:
1.成本暴跌 87% : 通过将大量的简单逻辑路由给 DeepSeek 或 GPT-5.3,只让昂贵的 Opus 4.6 处理那 5% 的核心难题,我们在保留了 Opus 强推理能力的同时,把成本控制在了可接受范围。
2.抗腐烂能力提升: 只有在真正需要"大海捞针"时才调用 Opus,避免了把上下文浪费在无效对话上。
结语:别做 AI 的奴隶,做 AI 的指挥官
Claude Opus 4.6 和 GPT-5.3-Codex 的同日发布,标志着 AI 正在从"玩具"变成"重型工业机器"。 但在这个算力通过 七牛云 等基础设施唾手可得的时代,真正拉开差距的不是你用了哪个模型,而是你如何组合它们 。
Opus 4.6 再强,也不值得你为写个 Hello World 花 5 美刀。 GPT-5.3 再快,也不适合让它去思考系统架构。
Next Step : 如果你也在为大模型 API 的高昂账单和不稳定的上下文发愁,建议立刻去申请七牛云 AI Token 的测试 Key,把上面的 Python 脚本跑起来。你会回来感谢我的。