在知识驱动应用越来越重要的今天,如何把分散、杂乱的数据,快速转化为"可用的知识",成为很多企业和团队绕不开的问题。
本期《qKnow 知识平台核心能力解析》,我们聚焦一个关键能力 ------ 结构化抽取,带你完整了解从原始数据到高质量知识图谱的全过程。
一、什么是结构化抽取?为什么它很重要?
简单来说,结构化抽取就是:
从多源异构数据中,自动识别实体、关系与属性,并精准生成"主体 - 关系 - 客体"的三元组,将原始内容高效转化为结构化知识。
这一步,是知识图谱构建、智能问答、语义检索等上层应用的核心基础。
在 qKnow 知识平台中,结构化抽取不仅追求"抽得出来",更关注 结果是否准确、是否可追溯、是否可持续更新,从源头保障知识质量。
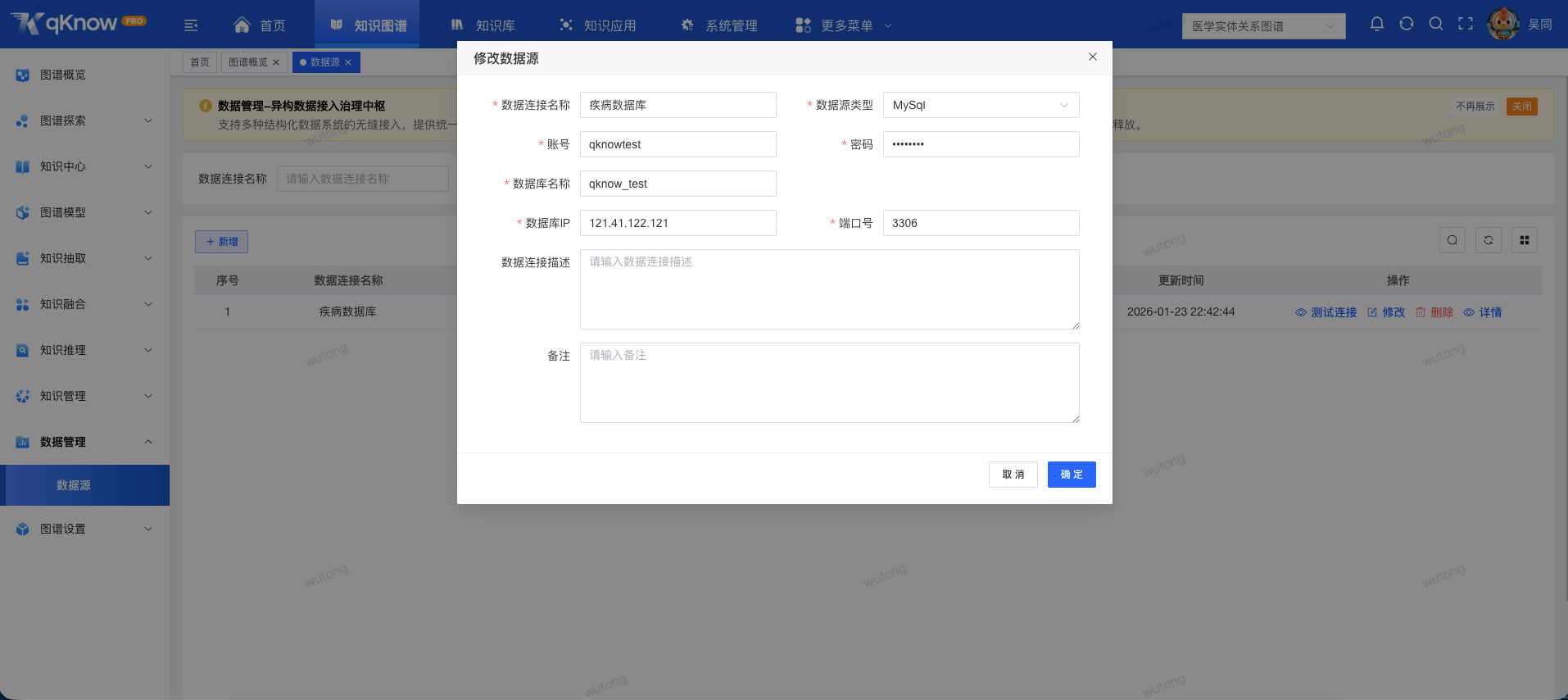
二、多数据源支持:先把"原材料"准备好
想要高效完成结构化抽取,第一步当然是搞定数据源。
qKnow 在数据接入层面,提供了对多种主流数据库的原生支持,包括:
- MySQL
- Oracle
- DM(达梦)
- 人大金仓
- ......
面对不同系统、不同业务场景的数据存储方式,无需额外改造,就能快速接入,真正做到 多源异构数据统一抽取。
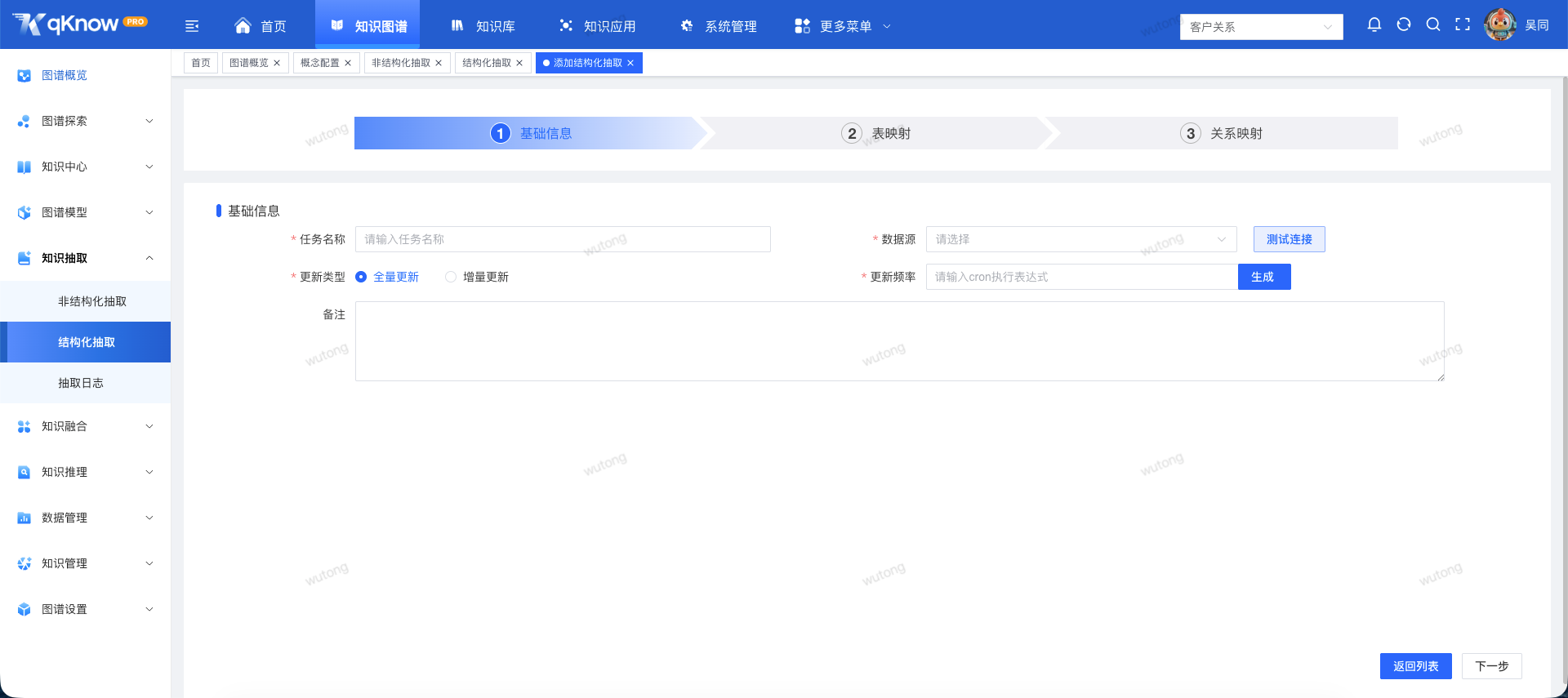
三、任务精细化管理:抽取过程可控、可配置
在 qKnow 中,结构化抽取并不是"一刀切"的黑盒流程,而是一个高度可配置、可管理的任务体系。
1️⃣ 抽取任务全流程自定义
你可以根据业务需要,自由配置:
- 任务名称
- 数据源选择
- 抽取模式:全量 / 增量
- 更新频率设置
无论是一次性初始化,还是持续数据更新,都能轻松应对。
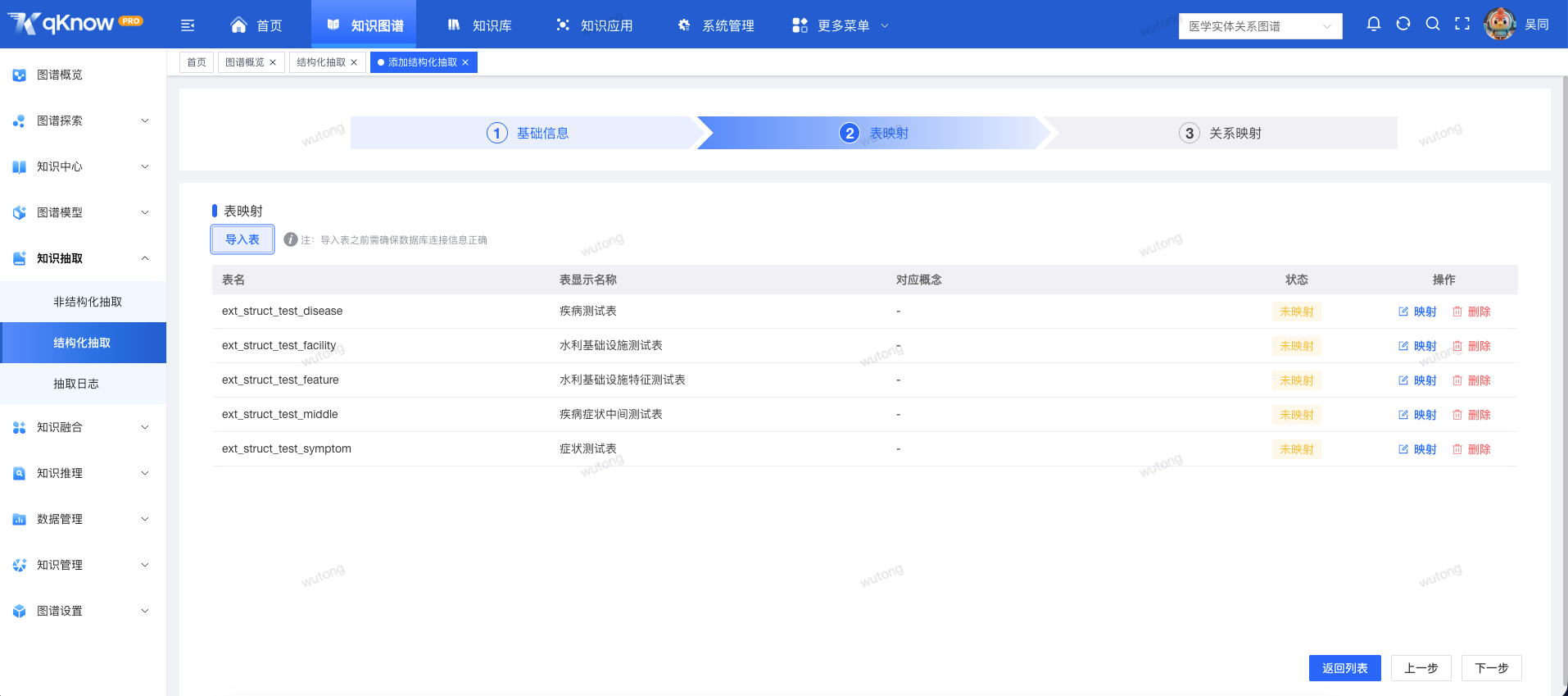
2️⃣ 表级别绑定图谱模型
- 支持选择数据源中的具体数据表
- 每张表可精准绑定到图谱模型中的对应概念
让"数据 → 知识"的映射关系更加清晰,避免无目标、无约束的低效抽取。
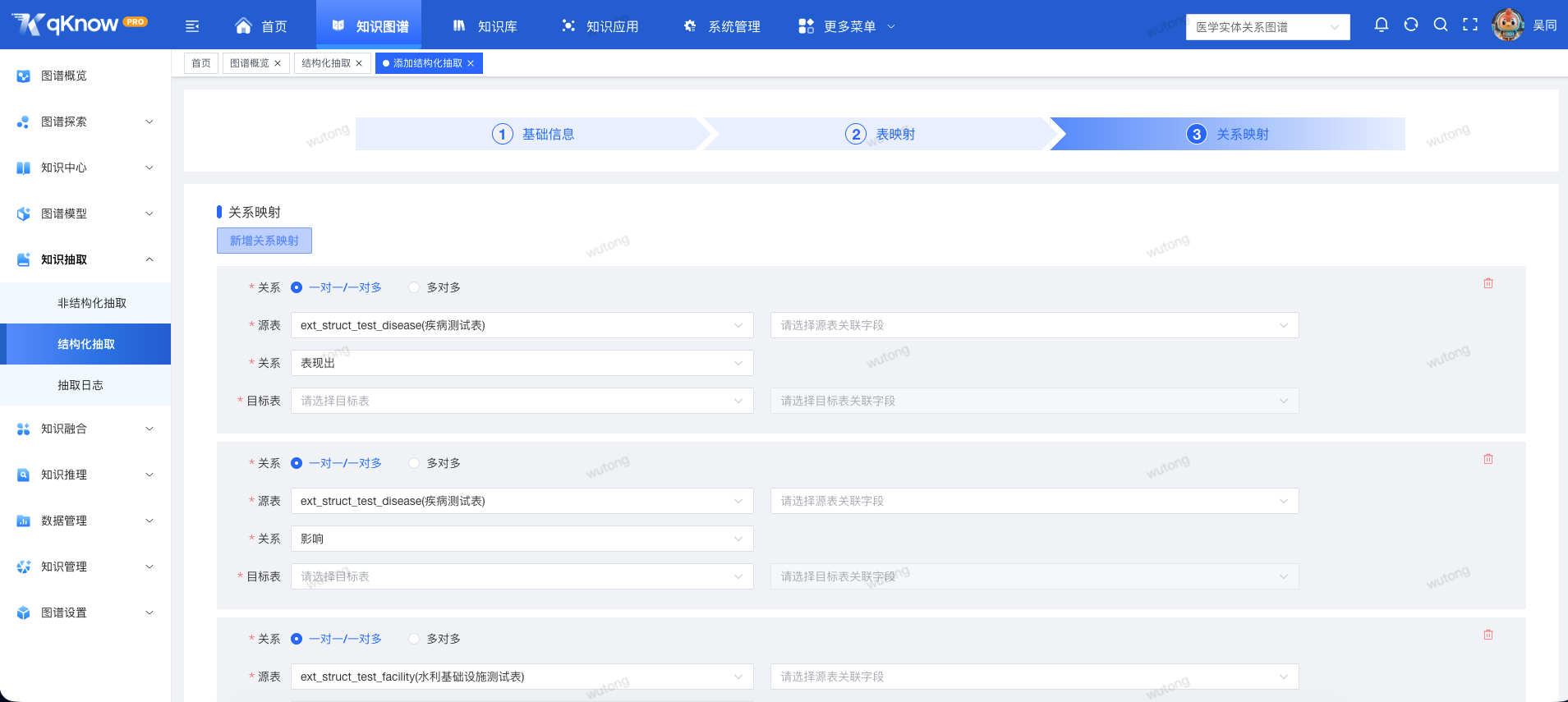
3️⃣ 多种关系映射方式,抽取更精准
qKnow 支持灵活的关系映射策略:
- 一对一
- 一对多
- 多对多
同时支持直接绑定图谱模型中的关系定义,提前明确抽取方向与语义含义,告别"抽了一堆却用不上"的无效结果。
四、异步抽取能力:不打断你的工作节奏
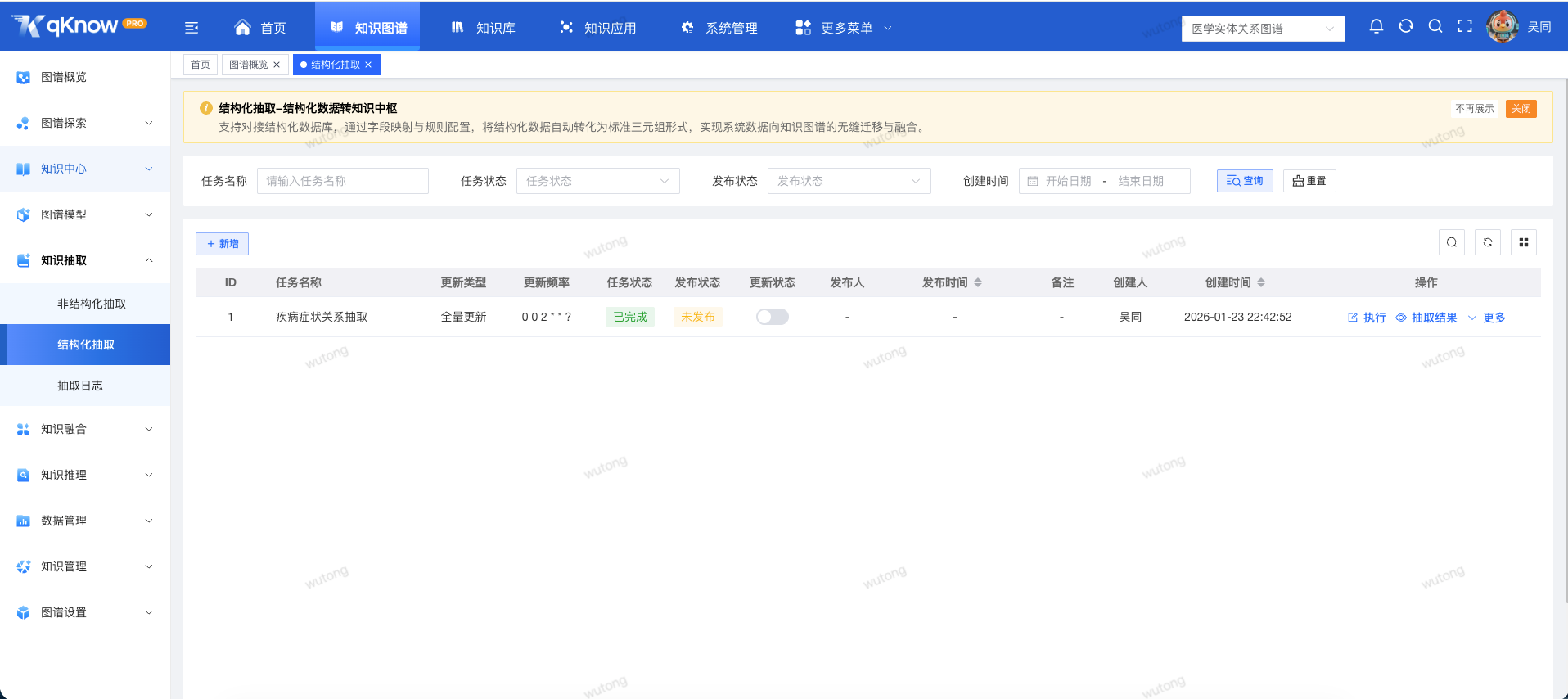
在任务执行层面,qKnow 提供了异步抽取模式:
- 任务提交后后台执行
- 无需长时间等待或人工值守
- 不占用当前工作流程
同时,系统会通过清晰直观的任务状态展示:
- 等待中
- 执行中
- 已完成 / 异常
让你随时掌握抽取进度,效率与体验兼顾。
五、抽取结果可视化:看得见、改得动、能追溯
结构化抽取完成后,结果并不是冷冰冰的数据表,而是以图谱形式直观呈现:
- 实体关系一目了然
- 抽取结果清晰可查
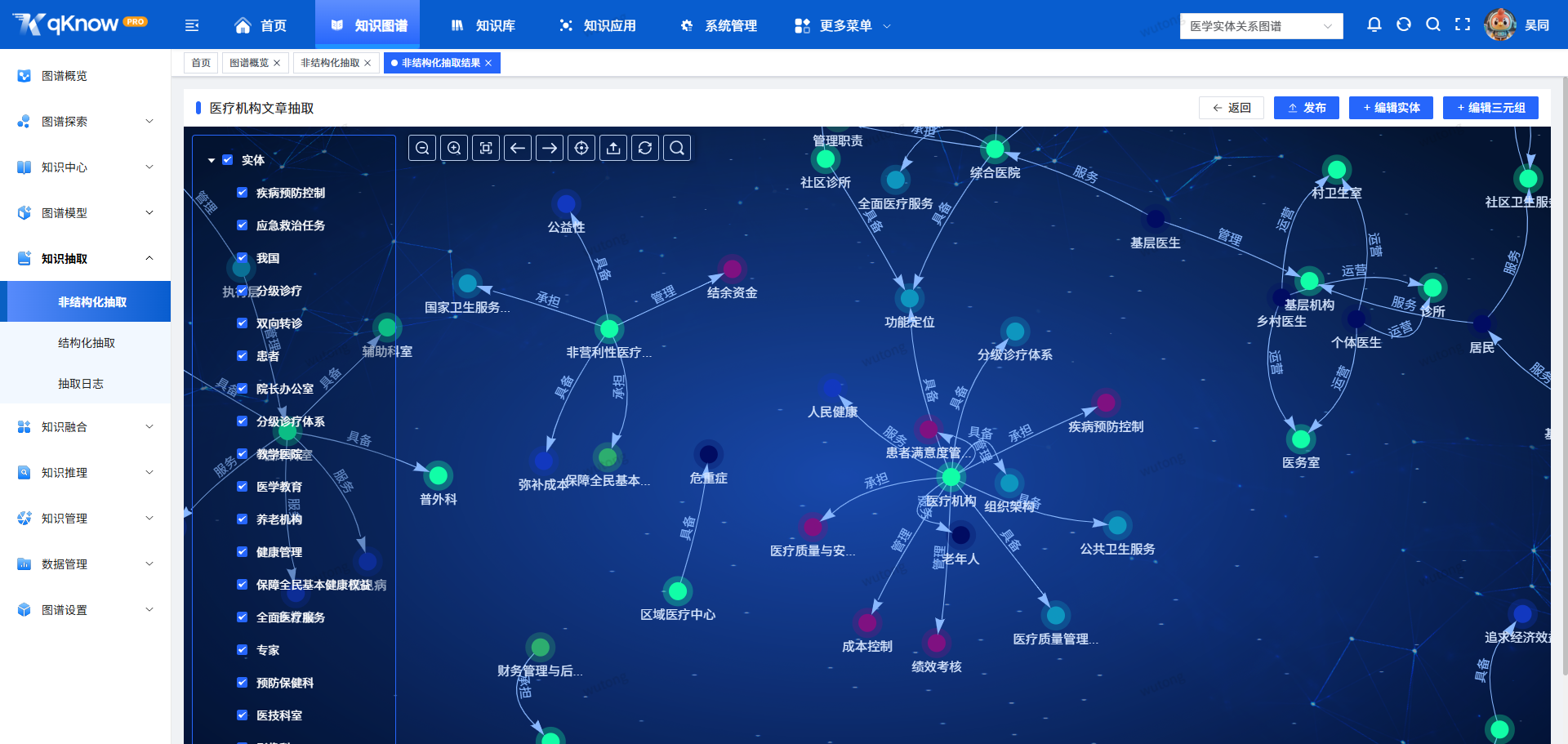
🔍 人工审查 & 一键修改
- 支持人工核验抽取结果
- 可对细微偏差进行快速修正
让"自动化"与"人工把控"形成有效互补。
🔗 实体溯源能力
每一条知识,都支持:
- 查看关联数据源
- 回溯原始数据内容
信息来源清晰可查,知识可信度有保障,杜绝"来源不明、无法验证"的风险。
六、快速发布上线:让知识真正用起来
当结构化抽取结果完成核验后,只需简单操作,即可:
- 将知识图谱快速发布上线
- 直接支撑搜索、问答、分析等实际应用
真正实现 从数据 → 知识 → 业务价值 的闭环。
总结
以上就是本期**《qKnow 知识平台核心能力解析|结构化抽取能力全流程介绍》** 的全部内容。
通过这次解析,希望大家能更清晰地理解:
- 结构化抽取在知识体系中的核心价值
- qKnow 如何用一套完整流程,让数据高效转化为可信知识
下一期,我们也将继续拆解 qKnow 的更多关键能力,欢迎持续关注 🚀
如果你对结构化抽取或知识图谱建设有更多想法,也欢迎在评论区一起交流。