RAG + Agent + Prompt工程上
首先介绍一下rag是什么吧
相信你们在日常使用ai中,都会遇到ai胡说八道的情况,特别是当提问一些比较专业的问题时,而rag的作用就是解决这个问题,本质上就是创建一个自己的向量数据库,每次询问ai时就会先将我们的问题与数据库中的数据进行一个相似性搜索,将相似度达到一定水平时便将改数据库中的该段内容加入我的提问中一起给大模型,以做到一个丰富内容的效果
话不多说,直接上项目
先来一个比较简单的例子试试水
我们要实现的功能是:将我的简历传入,我可以询问ai有关我自己的问题,并得到满意的答案
这里我们使用到技术栈是:Ollama + LangChain.js + Supabase(pgvector)+ Node.js
- Ollama :一个本地运行大语言模型(LLM)的工具,支持一键下载、运行和管理开源模型(如 Llama 3、DeepSeek、Nomic 等)。在本项目中,我们用它来提供两个能力:一是通过
nomic-embed-text模型生成文本的向量嵌入(embedding),二是通过deepseek-v3.1:671b-cloud模型回答用户问题。所有推理都在本地完成,无需联网或付费。 - LangChain.js :LangChain 的 JavaScript/TypeScript 实现,是一个专为构建 LLM 应用设计的开发框架。它提供了标准化的组件(如文档加载器、文本分割器、向量存储接口、提示模板、链式调用等),让我们能快速搭建 RAG(检索增强生成)系统。在本项目中,LangChain 负责:读取 PDF 简历 → 切分文本 → 调用 Ollama 生成 embedding → 将向量存入 Supabase → 在问答时检索相关片段 → 构造带上下文的 prompt 并交由 LLM 回答。可以说,LangChain 是串联整个 RAG 流程的"胶水"和"脚手架" 。
- Supabase(集成 pgvector) :一个开源的 Firebase 替代品,底层基于 PostgreSQL。我们特别启用了它的
pgvector扩展,使其具备向量存储与相似度搜索 能力。在本项目中,Supabase 充当向量数据库 的角色:存储每段简历文本及其对应的 768 维 embedding 向量,并通过自定义的match_documents函数,根据用户问题的向量快速检索出最相关的简历片段。相比本地内存或文件存储,Supabase 提供了持久化、可扩展、支持复杂查询的云端向量检索服务。 - Node.js:作为运行时环境,支撑整个 JavaScript 应用的执行,包括文件读取、HTTP 请求(与 Ollama 和 Supabase 通信)、异步流程控制等。
LangChain生态系统
LangChain 是一个开源框架,用于构建基于大语言模型(LLM)的应用程序 。它的核心目标是:让 LLM 能够与外部数据、工具和逻辑结合,从而打造更强大、可控、实用的 AI 应用。
LangChain = 让大模型"能干活"的脚手架 ------ 接数据、连工具、记历史、做决策。 LangChain使这些复杂流程变得简单,让开发者可以专注于业务逻辑而不是底层实现细节。
1. 链(Chains)
链是LangChain的核心概念,允许将多个组件按特定顺序组合起来,完成复杂任务。
javascript
// 简单链示例
import { LLMChain } from "langchain/chains";
import { ChatOpenAI } from "langchain/
chat_models/openai";
import { PromptTemplate } from "langchain/
prompts";
const llm = new ChatOpenAI({ temperature: 0.9 });
const prompt = PromptTemplate.fromTemplate("什么
是{topic}?");
const chain = new LLMChain({ llm, prompt });
const result = await chain.call({ topic: "人工智能
" });2. 模型(Models)
LangChain支持多种类型的模型:
- LLMs : 文本生成模型
- Chat Models : 对话模型,支持结构化消息
- Text Embedding Models : 文本嵌入模型,用于向量表示
3. 提示词(Prompts)
提供模板化管理和优化提示词的工具:
js
import { PromptTemplate } from "langchain/
prompts";
const prompt = new PromptTemplate({
template: "请用{style}风格解释{topic}",
inputVariables: ["style", "topic"]
});4. 索引(Indexes)
用于结构化和检索外部数据,包括:
- Document Loaders : 从各种数据源加载文档
- Text Splitters : 将长文本分割成可管理的块
- Vector Stores : 存储和检索向量嵌入
- Retrievers : 从存储中检索相关文档
5. 记忆(Memory)
为链和代理提供持久化状态,使对话具有上下文感知能力:
js
import { ConversationBufferMemory } from
"langchain/memory";
const memory = new ConversationBufferMemory({
memoryKey: "chat_history",
returnMessages: true
});6. 代理(Agents)
代理使用LLM决定执行哪些动作,可以动态选择工具:
javascript
import { initializeAgentExecutor } from
"langchain/agents";
import { SerpAPI } from "langchain/tools";
import { Calculator } from "langchain/tools";
const tools = [new SerpAPI(), new Calculator()];
const agent = await initializeAgentExecutor
(tools, llm, "zero-shot-react-description");JavaScript/TypeScript版本
- langchain : 核心库
- @langchain/openai : OpenAI集成
- @langchain/community : 社区贡献的集成
- langchain/chains : 预构建链
- langchain/embeddings : 嵌入模型
如何去存储我传入的数据
我们已经知道了ai会将我们的问题与数据库中的每一条数据进行相似性搜索,这就需要我们去使用向量数据库去存储我们的信息,将信息以向量的形式存储便于我们进行相似性搜索,在这个项目中我们使用到的是线上数据库supabase(当然由于这是一个线上数据库,后续就难免涉及到收费等问题,主包就是在创了两个数据库后要收我的钱了,不然你之前的数据就没了),那具体如何去用呢?
环境配置
.env
# Supabase 配置
SUPABASE_URL=每个库对应一个url
SUPABASE_ANON_KEY=
SUPABASE_TABLE_NAME=documents在下图的位置可以找到url 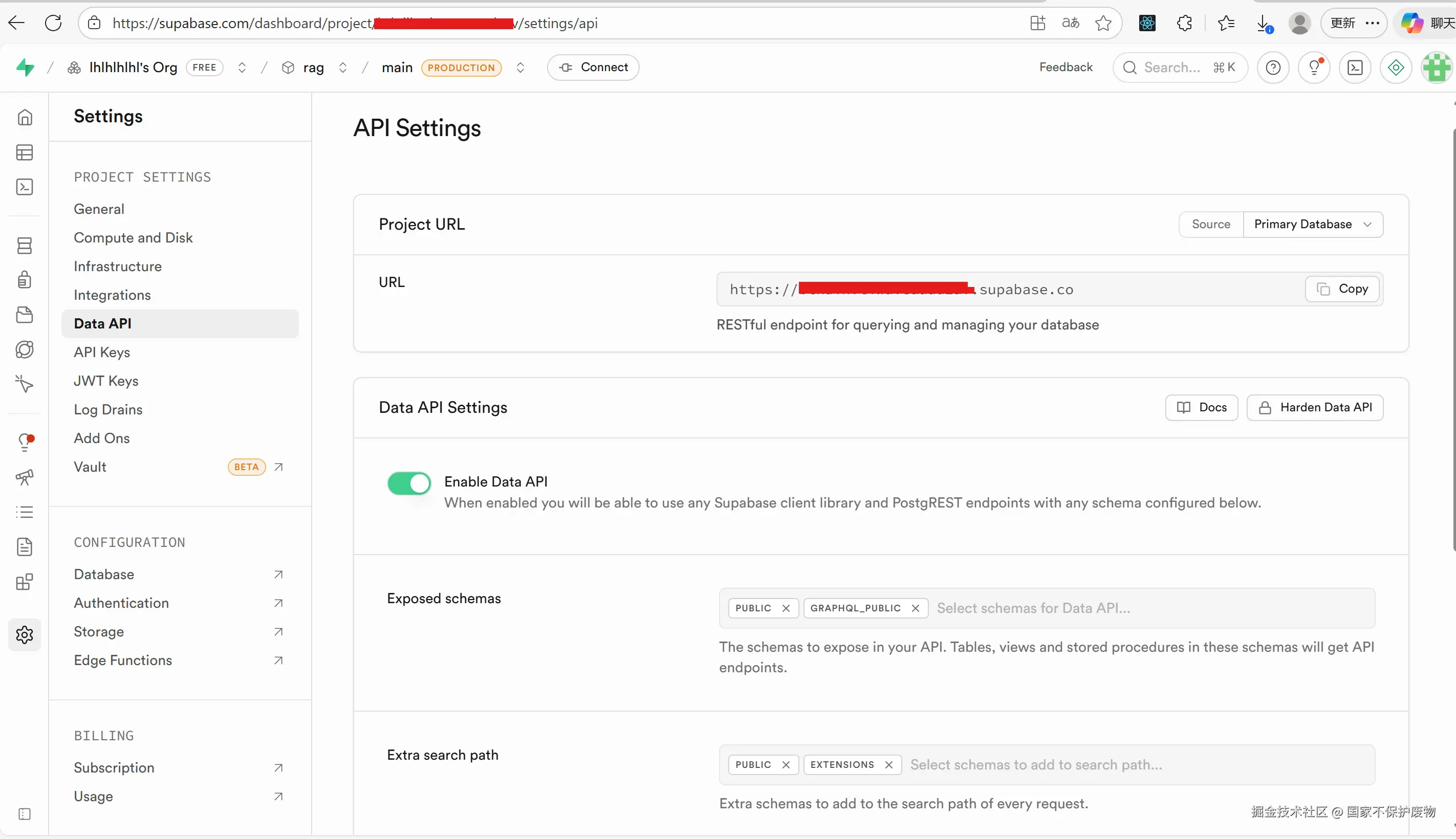
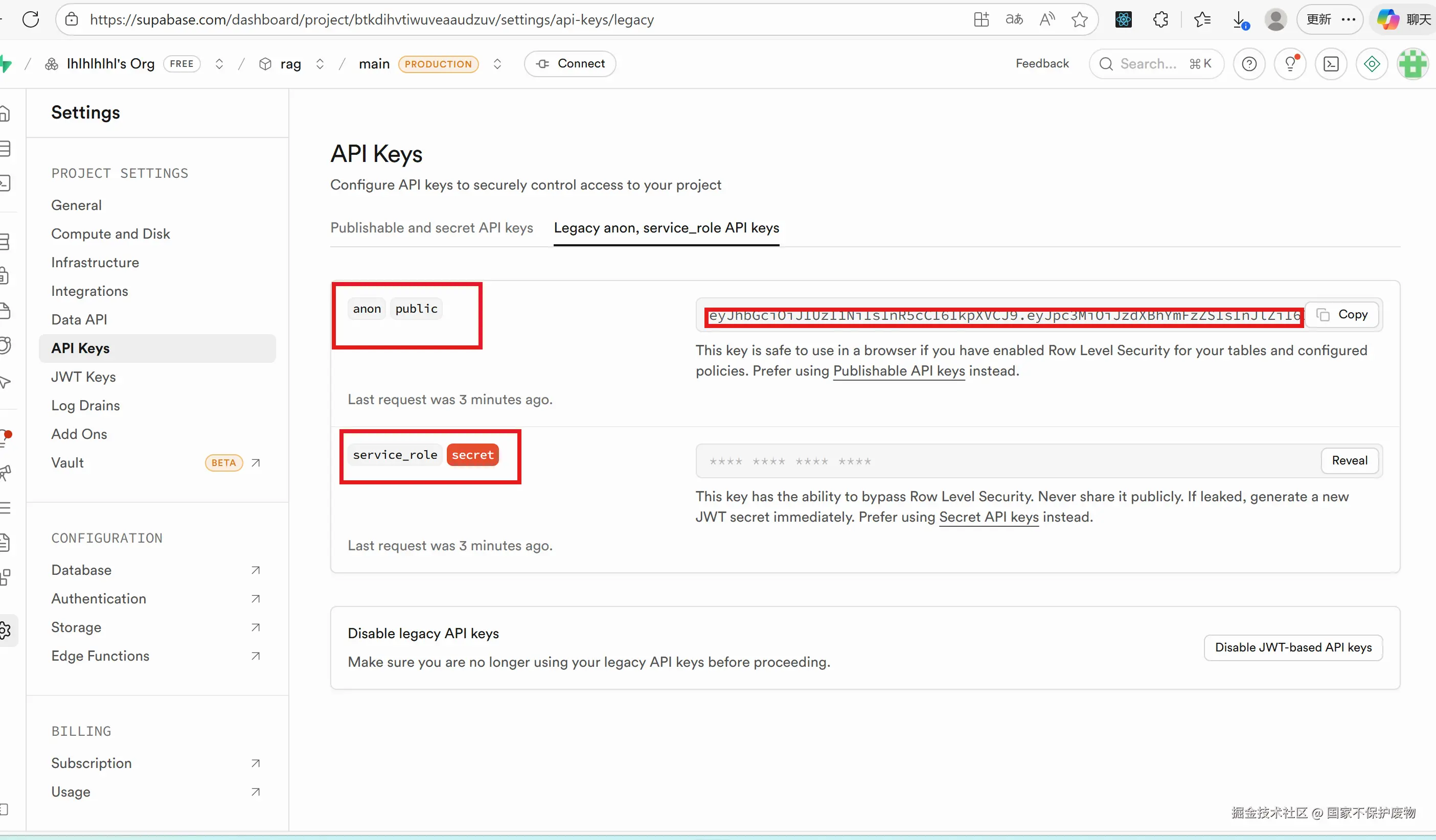
api的话要注意有两个,而我们需要用到的就是上面anon``public的那个api
- anon 密钥 应该只用于客户端应用,权限受限,默认只能读取公开数据
- service_role 密钥 应该用于服务端操作,拥有完全权限,可以绕过所有行级安全策略(RLS)
而我们使用 anon 密钥能够写入数据的原因是:表权限设置 :documents表没有启用RLS,所以默认情况下,任何有效的API密钥(包括anon密钥)都有权限插入数据。虽然这样不太安全
更安全的做法应该是:
- 启用RLS: ALTER TABLE public.documents ENABLE ROW LEVEL SECURITY;
- 创建适当的策略,例如:
- 允许所有人读取: CREATE POLICY "Enable read access for all users" ON public.documents FOR SELECT USING (true);
- 只允许服务角色写入: CREATE POLICY "Enable insert for service role only" ON public.documents FOR INSERT WITH CHECK (current_setting('request.jwt.claims', true)::json->>'role' = 'service_role'); 这样就可以确保只有服务端(使用service_role密钥)才能写入数据,而客户端(使用anon密钥)只能读取数据。
但是我们先不考虑那么远,先偷个懒,就这样
创建一个数据库中的数据表
在supabase官网中找到编辑表的地方,选择这个,便可以直接使用sql语句去创建表了 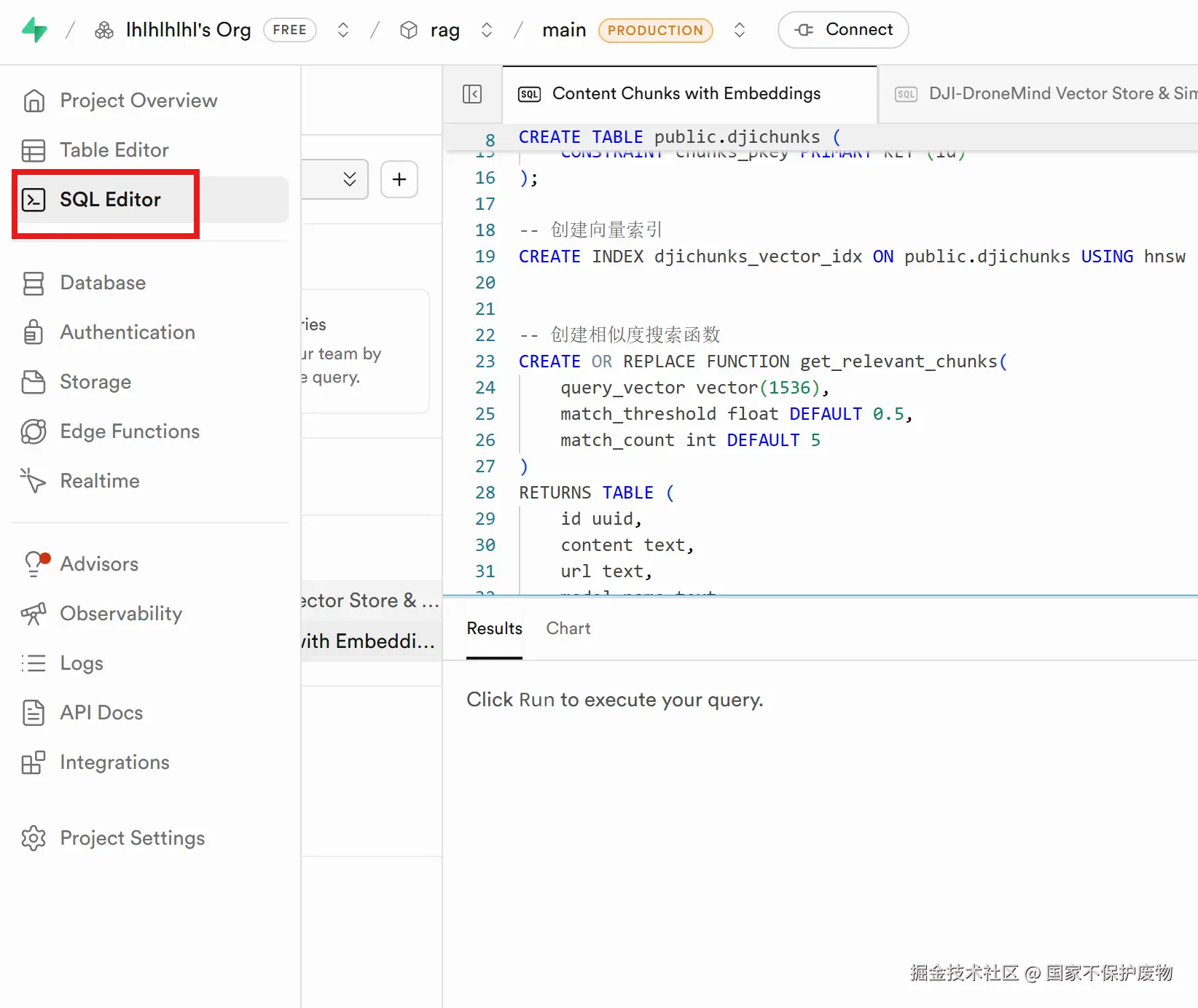
这里我们要注意要启动 pgvector 扩展,否则将会创建失败,我们在这里不仅声明了表的结构还创建了向量相似度搜索函数,后续进行相似度判断时会使用到这个函数
js
-- 启用 pgvector 扩展
CREATE EXTENSION IF NOT EXISTS vector;
-- 创建 documents 表(根据项目配置使用documents作为表名)
CREATE TABLE IF NOT EXISTS public.documents (
id uuid NOT NULL DEFAULT gen_random_uuid(),
content text null,
embedding vector(768) null, -- nomic-embed-text生成768维向量
metadata jsonb null,
CONSTRAINT documents_pkey PRIMARY KEY (id)
);
-- 创建向量相似度搜索函数
CREATE OR REPLACE FUNCTION match_documents(
query_embedding vector(768),
match_threshold float DEFAULT 0.7,
match_count int DEFAULT 5,
filter jsonb DEFAULT '{}'
)
RETURNS TABLE (
id uuid,
content text,
metadata jsonb,
similarity float
)
LANGUAGE sql STABLE
AS $$
SELECT
id,
content,
metadata,
1 - (documents.embedding <=> query_embedding) as similarity
FROM documents
WHERE 1 - (documents.embedding <=> query_embedding) > match_threshold
ORDER BY similarity DESC
LIMIT match_count;
$$;往数据库中写入数据
将supabase的配置文件写好了之后咱们就要去用了
话不多说,直接上代码
js
// utils/supabase.js
import { createClient } from "@supabase/supabase-js";
import dotenv from "dotenv";
dotenv.config();
const supabase = createClient(process.env.SUPABASE_URL, process.env.SUPABASE_ANON_KEY);
export default supabase;先实例化supabase,后续可以直接通过supabase进行写入数据
js
// ingest.js
import { PDFLoader } from "langchain/document_loaders/fs/pdf";
import { RecursiveCharacterTextSplitter } from "langchain/text_splitter";
import { SupabaseVectorStore } from "@langchain/community/vectorstores/supabase";
import { OllamaEmbeddings } from "@langchain/community/embeddings/ollama";
import supabase from "./utils/supabase.js";
import dotenv from "dotenv";
dotenv.config();
async function ingestDocument() {
console.log("开始文档植入流程...");
// 1. 加载 PDF
console.log("正在加载 PDF 文件...");
const loader = new PDFLoader("documents/assessment_report.pdf");
const docs = await loader.load();
console.log(`加载完成,共 ${docs.length} 页`);
// 2. 分块
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 500,
chunkOverlap: 50,
});
const splitDocs = await textSplitter.splitDocuments(docs);
console.log(`分块完成,共 ${splitDocs.length} 个文本块`);
console.log(`文本块:${splitDocs[0].pageContent}`);
// 3. 初始化 embedding 模型
const embeddings = new OllamaEmbeddings({
model: process.env.EMBEDDING_MODEL, // "nomic-embed-text"
baseUrl: process.env.OLLAMA_BASE_URL,
});
// 4. 存入 Supabase 向量数据库
console.log("正在将向量写入 Supabase...");
try {
await SupabaseVectorStore.fromDocuments(splitDocs, embeddings, {
client: supabase,
tableName: process.env.SUPABASE_TABLE_NAME,
queryName: "match_documents", // LangChain 会自动创建这个函数
});
console.log("文档已成功存入 Supabase 向量数据库!");
} catch (error) {
console.error("存入 Supabase 失败:", error.message);
}
}
ingestDocument();(((φ(◎ロ◎;)φ))),这些都是啥啊,我怎么都看不懂,别着急,我们一起来看看
我看整个代码,感觉都围绕着一个东西langchain,在上面我们已经知道了langchain大概是什么了,那我们就先看看具体是怎么用的吧(详细讲述为什么要使用langchain,为什么在这里使用这个东西)
很明显,我们这跟结构化和检索外部数据有关,所以跟索引这个核心概念有关,
- Document Loaders : 从各种数据源加载文档
- Text Splitters : 将长文本分割成可管理的块
- Vector Stores : 存储和检索向量嵌入
这三个组件,我们肯定是要用到的,并且我们需要将文字转换成向量,所以还需要使用到一个向量大模型 所以总体的流程就是:
- 文档加载 : PDFLoader 加载PDF文档
- 文本分割 : RecursiveCharacterTextSplitter 分割文本
- 向量化 : OllamaEmbeddings 生成文本向量
- 向量存储 : SupabaseVectorStore 存储和检索向量
那为什么要用 LangChain 呢?
因为如果没有 LangChain,你需要自己手动完成以下事情:
- 自己写代码解析 PDF(比如用 pdf-parse 或 pdf.js),处理编码、分页、格式丢失等问题;
- 自己实现文本分块逻辑(比如按字符、句子或语义边界切割),还要考虑重叠以保留上下文;
- 自己调用 Ollama 的 API 发送文本获取 embedding 向量,处理 HTTP 请求、错误重试、批量处理;
- 自己构造 SQL 查询或 RPC 调用 Supabase 的
match_documents函数,拼接向量、设置阈值、解析返回结果; - 最后还要手动拼接 prompt,把检索到的内容塞进问题里,再调用 LLM 接口。
这些步骤虽然技术上可行,但重复性高、容易出错、难以维护,而且不同模型、数据库、文件格式之间的适配成本极高。
而 LangChain 的价值就在于:它把上述所有环节都封装成了标准化的模块 (Document Loaders / Text Splitters / Embeddings / VectorStores),你只需要像搭积木一样组合它们,就能快速构建一个完整的 RAG 流程。更重要的是,这些模块是可插拔、可替换的------今天你用 Supabase + Ollama,明天换成 Pinecone + OpenAI,只需改几行配置,核心逻辑几乎不用动。
在这个项目中,我们之所以选择 LangChain,正是因为:
- 它提供了
PDFLoader直接读取简历 PDF; - 它内置了智能的
RecursiveCharacterTextSplitter,能按段落、句子合理切分,避免切断关键信息; - 它通过
OllamaEmbeddings无缝对接本地 Ollama 的 embedding 模型; - 它的
SupabaseVectorStore已经实现了与 pgvector 的深度集成,自动调用你创建的match_documents函数; - 整个流程被抽象为清晰的"加载 → 切分 → 向量化 → 存储"管道,极大降低了开发复杂度。
换句话说,LangChain 让你专注于"我要做什么",而不是"怎么一行行代码去实现底层细节" 。这正是现代 AI 应用开发所需要的生产力工具。 运行node ingest.js
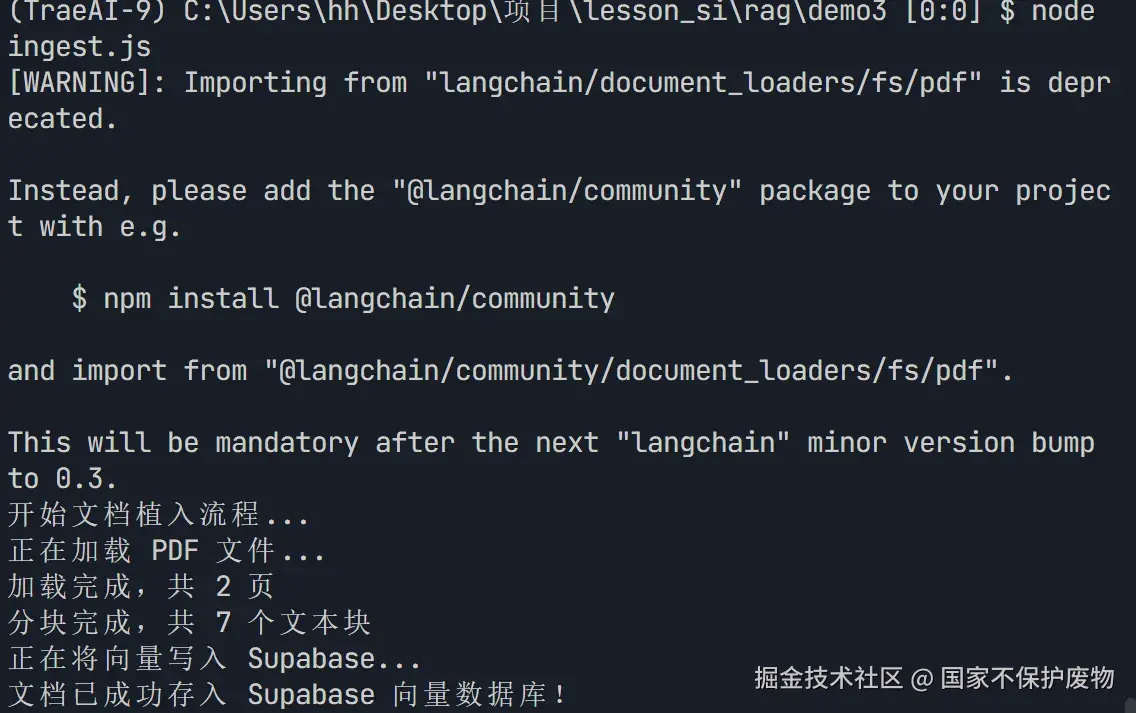 经过上面几个步骤,我们已经 成功将数据存入数据库中了,现在就是如何将数据与我们的大模型相结合了
经过上面几个步骤,我们已经 成功将数据存入数据库中了,现在就是如何将数据与我们的大模型相结合了
如何将在LLM中去使用我的数据
这里由于是简单的一个例子,目的是为了让我们知道大致rag的流程,我们便使用简单的ollama进行举例,但是前提是你本地已经下载了ollama,并且在终端运行ollama run deepseek-v3.1:671b-cloud和 ollama run nomic-embed-text,如此方可使用
首先进行基础配置 在原先的.env文件中添加ollama配置
.env
# Ollama 配置
OLLAMA_BASE_URL=http://localhost:11434
OLLAMA_MODEL=deepseek-v3.1:671b-cloud
EMBEDDING_MODEL=nomic-embed-text
js
// qa_resume.js - 针对简历内容的问题
import { createClient } from '@supabase/supabase-js';
import { OllamaEmbeddings } from '@langchain/community/embeddings/ollama';
import { Ollama } from "@langchain/community/llms/ollama";
import dotenv from 'dotenv';
dotenv.config();
const supabaseUrl = process.env.SUPABASE_URL;
const supabaseKey = process.env.SUPABASE_ANON_KEY;
async function askResumeQuestion(question) {
console.log(`\n问题: ${question}`);
try {
// 1. 初始化 embedding 模型
console.log("1. 初始化embedding模型...");
const embeddings = new OllamaEmbeddings({
model: process.env.EMBEDDING_MODEL,
baseUrl: process.env.OLLAMA_BASE_URL,
});
// 2. 生成查询向量
console.log("2. 生成查询向量...");
const queryEmbedding = await embeddings.embedQuery(question);
// 3. 执行向量相似度搜索
console.log("3. 执行向量相似度搜索...");
const supabase = createClient(supabaseUrl, supabaseKey);
const { data: documents, error } = await supabase
.rpc('match_documents', {
query_embedding: queryEmbedding,
match_threshold: 0.5,
match_count: 8,
filter: {}
});
if (error) {
console.error('向量搜索失败:', error.message);
return;
}
console.log(`找到 ${documents.length} 个相关文档`);
if (documents.length === 0) {
console.log('没有找到相关文档');
return;
}
// 4. 构建上下文
// console.log("4. 构建上下文...");
const context = documents.map((doc, index) =>
`[文档${index + 1}]\n${doc.content}`
).join('\n\n');
// 5. 初始化 LLM
// console.log("5. 初始化LLM...");
const llm = new Ollama({
baseUrl: process.env.OLLAMA_BASE_URL,
model: process.env.OLLAMA_MODEL,
temperature: 0.3,
});
// 6. 构建提示词
const prompt = `基于以下简历内容,请回答问题:
上下文:
${context}
问题:${question}
请用中文回答,并确保答案准确、简洁。如果上下文中没有相关信息,请明确说明。`;
// 7. 生成回答
console.log("请稍等,正在生成回答...");
const answer = await llm.invoke(prompt);
console.log(`回答: ${answer}`);
return answer;
} catch (error) {
console.error("问答失败:", error.message);
console.error("错误详情:", error);
}
}
// 测试针对简历的问题
await askResumeQuestion("这位候选人的主要技能是什么?");
await askResumeQuestion("候选人有哪些项目经验?");
await askResumeQuestion("他的教育背景如何?");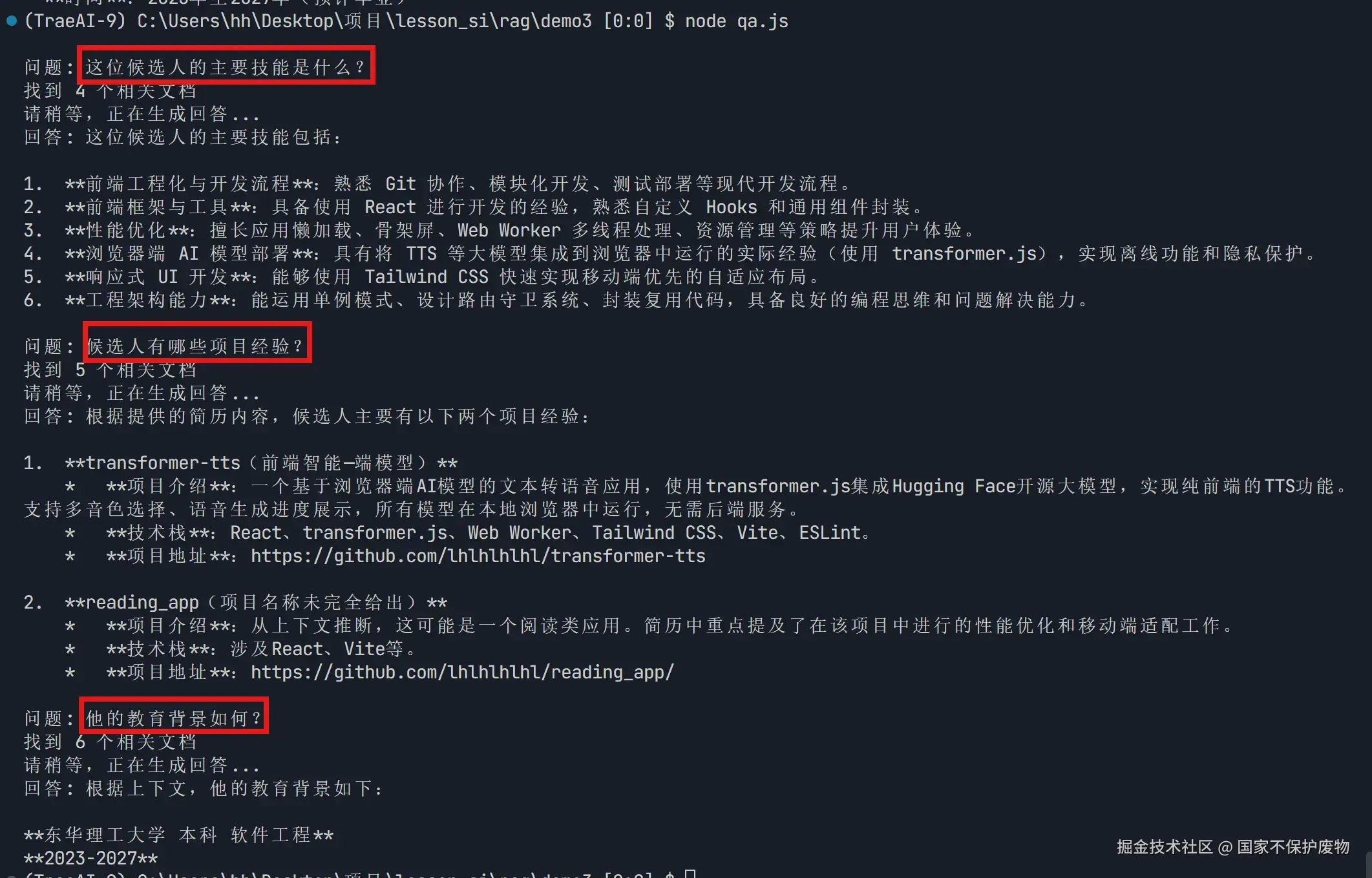
总结
通过这个简单的项目,我们完整走通了 RAG(检索增强生成) 的核心流程:
将个人简历(PDF)作为私有知识源,利用 LangChain.js 自动完成文档加载、文本切分、向量化和存储;借助 Supabase + pgvector 构建轻量级向量数据库,实现高效的语义相似性检索;最后结合本地运行的 Ollama 大模型,在注入上下文的前提下精准回答关于简历的问题。
整个方案完全运行在本地或低成本云服务上,无需依赖 OpenAI 等商业 API,既保护了数据隐私,又有效避免了大模型"胡说八道"的问题------因为它的回答始终基于你提供的真实内容。
更重要的是,这个架构具备极强的可扩展性:
- 换个 PDF,就能变成"公司知识库问答";
- 加入多个文档,就支持跨文件检索;
- 接入 Agent 和工具(如日历、邮件),还能实现"根据我的经历自动写求职信"等智能任务。
这只是一个起点。
接下来,我们将尝试引入更复杂的rag项目,还有很多需要优化的部分需要去完善,像文本切割是否可以更加人性化,是否可以通过langchain内的组件进行进一步的开发,比如实现流式输出,对话历史存储之类的,还有之前埋下的伏笔,有没有可以在本地直接运行的免费向量数据库,这些都会在之后的文章中写到