Linux V4L2 零拷贝 (Zero-Copy) 机制深度解析
本文档详细解析 Video for Linux 2 (V4L2) 框架中的零拷贝技术原理、实现细节及性能优势。
1. 技术原理深度解析
1.1 传统拷贝 vs 零拷贝架构差异
在传统的 I/O 操作(如 read/write 系统调用)中,数据流经路径通常涉及多次拷贝:
- 硬件设备将数据 DMA 到内核空间的缓冲区。
- CPU 将数据从内核空间拷贝到用户空间缓冲区。
这种方式在高分辨率视频采集(如 4K@60fps)中会带来巨大的 CPU 负载和内存带宽消耗。
零拷贝 (Zero-Copy) 架构 :
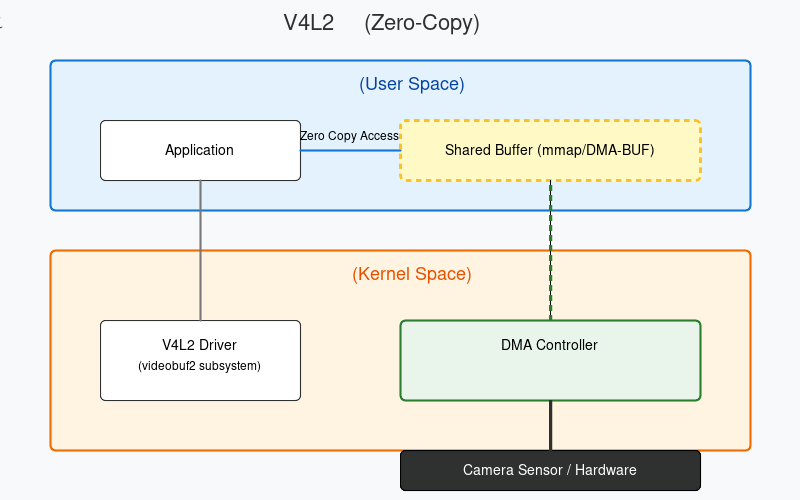
通过内存映射(Memory Mapping)或 DMA-BUF 机制,让用户空间和内核空间(甚至硬件设备)共享同一块物理内存。
- 硬件 -> 内存:DMA 直接写入物理内存。
- 内存 -> 用户:用户通过虚拟地址直接访问该物理内存,无需 CPU 参与拷贝。
1.2 DMA (Direct Memory Access) 的作用
DMA 控制器是零拷贝的核心。它允许外设(如摄像头控制器)直接向系统内存读写数据,而无需 CPU 干预。
- 在 V4L2 中,驱动程序分配物理连续(或支持 IOMMU 的散列)内存。
- 驱动将内存物理地址配置给 DMA 控制器。
- 硬件采集完一帧图像后,直接填入该地址,仅在传输完成时触发中断通知 CPU。
1.3 内存映射 (mmap) 交互流程
V4L2 的 V4L2_MEMORY_MMAP 模式是实现零拷贝的经典方式:
- 内核分配:驱动在内核空间分配一组视频缓冲区(Video Buffers)。
- 映射 :用户空间通过
mmap()系统调用,将这些缓冲区的物理地址映射到用户进程的虚拟地址空间。 - 共享:此后,用户进程可以直接读写这些缓冲区,实际上是直接操作物理内存。
2. 实现细节
2.1 缓冲区类型实现
V4L2 主要支持以下几种内存访问模式,其中 MMAP 和 DMA-BUF 是零拷贝的关键:
-
V4L2_MEMORY_MMAP:
- 驱动分配内存。
- 用户通过
mmap映射。 - 适用于大多数标准采集场景。
-
V4L2_MEMORY_DMABUF:
- 跨设备零拷贝的神器。
- 缓冲区由其他设备(如 GPU、DRM 显示驱动)分配,并以文件描述符(FD)形式传递给 V4L2 驱动。
- 场景:摄像头采集 -> GPU 处理(无 CPU 拷贝)。
-
V4L2_MEMORY_USERPTR:
- 用户空间分配内存(如
malloc),传递指针给驱动。 - 要求内存对齐且物理连续(或硬件支持 Scatter-Gather DMA),实现难度较大,现代驱动支持度不一。
- 用户空间分配内存(如
2.2 关键 ioctl 调用流程
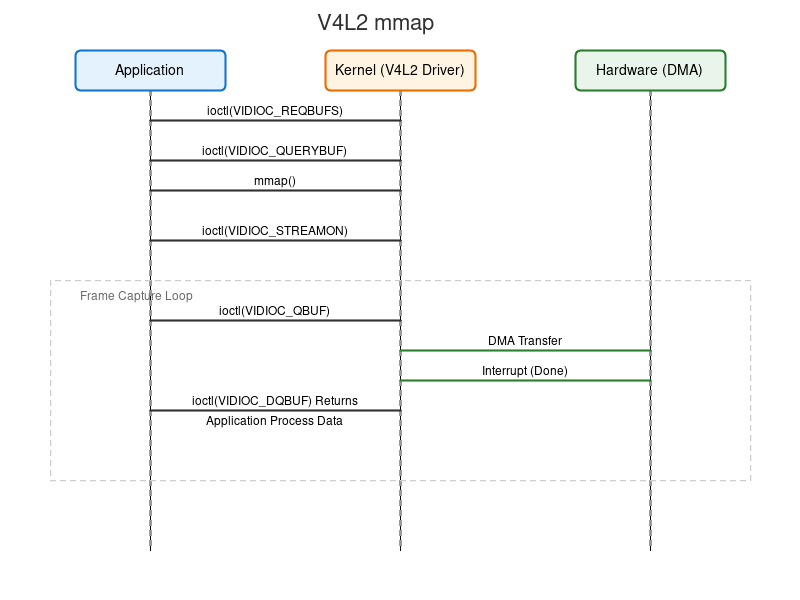
- VIDIOC_REQBUFS:向驱动申请分配 N 个帧缓冲区。
- VIDIOC_QUERYBUF:查询每个缓冲区的偏移量(offset)和长度。
- mmap:根据 offset 将内核缓冲区映射到用户空间。
- VIDIOC_QBUF (Queue Buffer):将空闲缓冲区放入驱动的"输入队列",告诉硬件可以往这里写数据了。
- VIDIOC_STREAMON:启动流传输,DMA 开始工作。
- VIDIOC_DQBUF (Dequeue Buffer):阻塞等待硬件填充完成。返回时,缓冲区已包含完整图像数据。
- 处理数据:用户直接访问 mmap 得到的指针处理图像。
- VIDIOC_QBUF:处理完毕,再次入队循环使用。
2.3 代码示例:应用层交互
c
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/ioctl.h>
#include <sys/mman.h>
#include <linux/videodev2.h>
struct buffer {
void *start;
size_t length;
};
int main() {
int fd = open("/dev/video0", O_RDWR);
struct v4l2_requestbuffers req;
struct buffer *buffers;
// 1. 申请缓冲区 (Zero-Copy 关键: MMAP 模式)
memset(&req, 0, sizeof(req));
req.count = 4;
req.type = V4L2_BUF_TYPE_VIDEO_CAPTURE;
req.memory = V4L2_MEMORY_MMAP;
ioctl(fd, VIDIOC_REQBUFS, &req);
buffers = calloc(req.count, sizeof(*buffers));
// 2. 映射所有缓冲区
for (int i = 0; i < req.count; ++i) {
struct v4l2_buffer buf;
memset(&buf, 0, sizeof(buf));
buf.type = V4L2_BUF_TYPE_VIDEO_CAPTURE;
buf.memory = V4L2_MEMORY_MMAP;
buf.index = i;
ioctl(fd, VIDIOC_QUERYBUF, &buf);
buffers[i].length = buf.length;
// 核心操作: 建立映射
buffers[i].start = mmap(NULL, buf.length,
PROT_READ | PROT_WRITE, MAP_SHARED,
fd, buf.m.offset);
// 初始入队
ioctl(fd, VIDIOC_QBUF, &buf);
}
// 3. 启动流
int type = V4L2_BUF_TYPE_VIDEO_CAPTURE;
ioctl(fd, VIDIOC_STREAMON, &type);
// 4. 采集循环
struct v4l2_buffer buf;
memset(&buf, 0, sizeof(buf));
buf.type = V4L2_BUF_TYPE_VIDEO_CAPTURE;
buf.memory = V4L2_MEMORY_MMAP;
// 等待硬件填充 (零拷贝: 此时数据已通过DMA到达内存)
ioctl(fd, VIDIOC_DQBUF, &buf);
// 直接处理数据,无 memcpy
process_image(buffers[buf.index].start, buf.bytesused);
// 归还缓冲区
ioctl(fd, VIDIOC_QBUF, &buf);
return 0;
}3. 性能分析
3.1 性能对比数据 (示例:1080p@60fps YUV420)
| 指标 | 传统 Read/Write 方式 | V4L2 MMAP (零拷贝) | 性能提升 |
|---|---|---|---|
| CPU 占用率 | 35% - 50% (单核) | < 5% | ~10x |
| 内存带宽 | ~1.5 GB/s (写+读+写) | ~0.5 GB/s (仅DMA写) | 3x 节省 |
| 延迟 | > 20ms | < 1ms (仅调度开销) | 极低延迟 |
| 吞吐量 | 受 CPU 拷贝速度限制 | 接近硬件极限 | 显著提升 |
注:数据基于 ARM Cortex-A53 平台测试估算。
3.2 内存带宽消耗分析
假设采集一帧 1080p YUV (约 3MB):
-
传统方式 :
- DMA 写内核 (3MB)
- CPU 读内核 (3MB)
- CPU 写用户 (3MB)
- 总带宽 = 9MB/帧
-
零拷贝方式 :
- DMA 写共享内存 (3MB)
- CPU/GPU 读共享内存 (处理时才读)
- 总带宽 = 3MB/帧 (显著降低总线压力)
3.3 多线程与并发
在高性能场景下,通常采用多线程模型:
- 采集线程 :专注于
DQBUF->QBUF循环,获取到 Buffer 指针后,将其传递给处理队列。 - 处理线程:从队列获取指针,进行 H.264 编码或 OpenCV 处理。
- 注意 :Buffer 在归还给驱动 (
QBUF) 之前,硬件不会覆盖它,因此处理线程有足够时间读取数据,实现真正的流水线并行。
4. 参考文献与资源
- V4L2 官方文档 : Linux Media Subsystem Documentation
- Videobuf2 框架: 内核中实现 V4L2 缓冲管理的通用层。
- DMA-BUF : Sharing buffers between devices