小团队或独立开发者的核心约束是成本、性能和开发速度。Next.js 给前端带来完整的路由、SSR/ISR 和边缘渲染能力,Cloudflare 提供全球 Anycast 网络和边缘计算,让你不用自建多层基础设施。
Vercel 和自建云都能跑 Next.js,但 Cloudflare 的优势在"网络 + 计算一体化"。
Vercel 更偏前端体验,后端生态相对有限;自建云需要你自己拼 CDN、WAF、LB 和证书。
网络与架构设计
传统单 Region + CDN/LB 架构的痛点是跨洲 RTT 高、出口带宽贵、缓存命中离散。
Cloudflare 用 Anycast 把同一 IP 广播到 300+ PoP,TLS/WAF/缓存/Worker 都在第一跳完成,Argo/骨干负责回源,避免公网抖动。
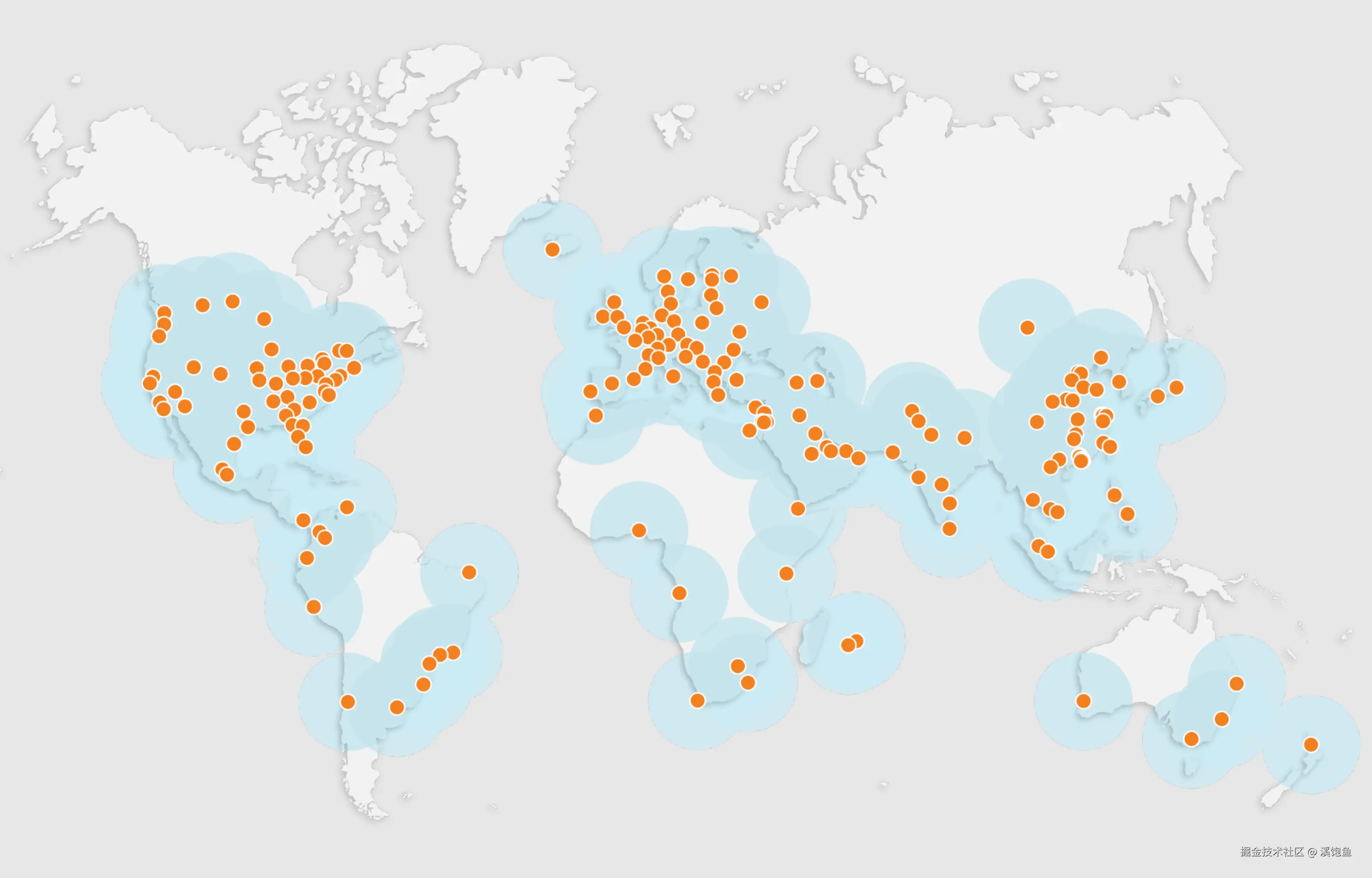
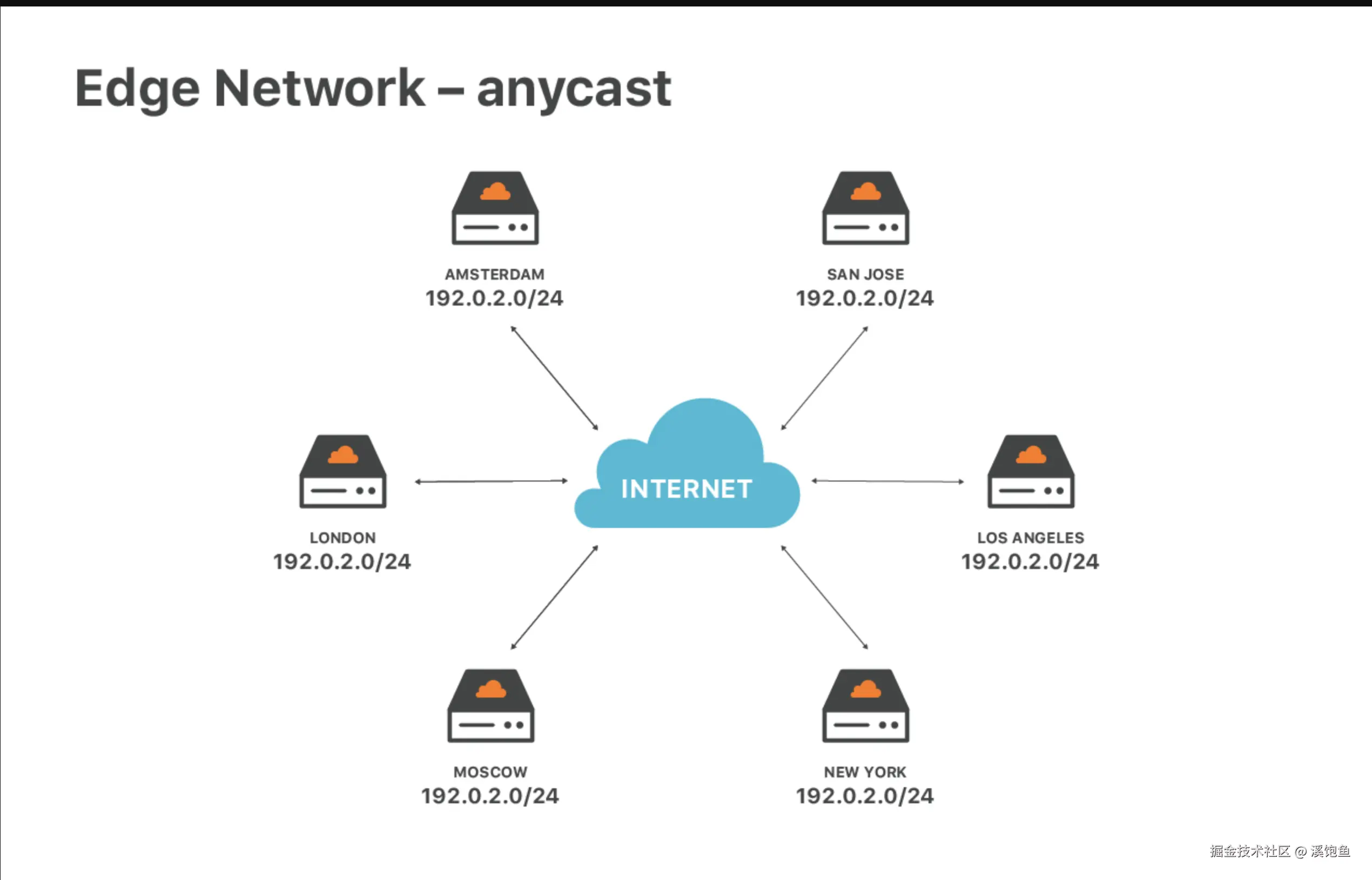
什么是Anycast
Anycast 是一种网络寻址和路由方法,可以将传入请求路由到各种不同的位置或"节点"。在 CDN 环境中,Anycast 通常将传入流量路由到最近的能够有效处理请求的数据中心。
举个例子:传统做法是 Unicast,你的服务器在美国,它有一个IP,比如1.2.3.4,接着全球所有请求打到 1.2.3.4,最后都要跑到这一个机房去。然后那在 Anycast 里,Cloudflare 会在全球很多机房里都部署一份服务,这些机房 都对外宣告同一段 IP 前缀(通过 BGP,GPT一下就知道了),当你访问这个 IP,互联网中的路由器会根据路径最短/代价最低的原则,把流量送到 "网络拓扑上最近" 的那个 Cloudflare 机房(不是物理距离的最近)。
放在Cloudflare上理解就是当你把域名接入 Cloudflare(换 NS 之后),Cloudflare 会给你的站配一组 Anycast IP:比如 104.x.x.x / 172.x.x.x 那些,这组 IP 在全球所有 Cloudflare 边缘机房都存在,用户访问美国用户 → 就近接入美国某个 PoP,欧洲用户 → 去欧洲某个 PoP,中国用户 → 去最近的能到达的 Cloudflare 节点(看运营商 & 国际出口)
Cloudflare 官方文档写得很直白:anycast IP 用来在 Cloudflare 网络中分发流量,既加速,又顺便帮你做 DDoS 防护。
什么又是POP
POP 一般指 Point of Presence,就是"接入点的意思"。
我们可以把 POP 想成运营商或 Cloudflare 在某个城市/机房里放的一坨设备:路由器、交换机、CDN 缓存服务器、防火墙 / WAF、DNS / Anycast 入口、Cloudflare的 Workers、D1、R2 的边缘网关逻辑。
这些东西合在一起,对外就是一个"节点",也就是一个 POP。
你不能把它当场那种传统机房的概念,它其实更偏抽象和逻辑上的网络入口节点,比大区机房离用户更近,数量更多,分布更散。机房可能就是大物流仓,然后POP就菜鸟驿站,快递先送到驿站去拿而不是去大物流仓拿。
结合上文,其实就是 IP 广播一大圈 POP,然后你的流量被"吸"到最近的 POP。
什么是Worker

跑在 Cloudflare POP 节点上的一小段 JS 程序,用来在"路上"拦截、修改、生成请求和响应。
也就是菜鸟驿站可以跑代码啦,做各种逻辑啦,以前它就是个中转+缓存。
什么是Cloudflare骨干网
Cloudflare 自己修的一圈"全球高速公路",Cloudflare 在全球几百个城市有自己的 PoP / 数据中心,这些点之间不是随便丢到公网乱飞,而是大量用自己租/买的光纤、暗纤,把这些点连成一张 私有的高带宽、低抖动的专用网络,这条网就叫 Cloudflare Global Backbone(骨干网)。
-
互联网 = 到处都是红绿灯的小马路
-
Cloudflare 骨干网 = Cloudflare 自己修的一圈城市间高速公路
所以上文提到的"网络 + 计算一体化",其实主要是在这个地方,Cloudflare有D1、R2这种数据库和内存KV设施,但他们都可以直接走自己的骨干网,而不用走站外流量。一方面是能省很多钱,另外一方面就是真的很快。
什么是Argo
首先Argo是收费的,上文都是免费的基础设施。
Cloudflare 自己的是这么讲的:普通路由 = 看纸质地图,按距离选路。Argo(Smart routing) = Waze / 高德,实时看路况,给你选一条当下最快的路线。
但我觉得这样理解可能好一些,比如本身没开Argo是公网回源,而开了Argo会把请求转发到最近进行回源。
这里会把大家绕晕,可能大家会问: "Anycast会找到最近节点,为什么Argo又有一个最近回源的概念?"
实际上,Anycast的作用是把用户请求引到最近的 Cloudflare POP;到 POP 为止,路径优化由互联网路由决定。
但回源阶段:POP 到源站之间走谁的网络、走哪条路由,Anycast 不管。默认是公网 BGP,路由质量随缘。
Argo的作用是在 POP 出口时挑一条更优的 Cloudflare 私网路径到源站附近的出口 POP,再短跳回源。这个"最近/最佳回源"是指从"POP → 源"的路径优化,而不是用户入口。
Anycast ≠ 端到端最短路,它只解决用户到边缘;Argo 才是在边缘到源的段做"最优出口"。但其实真实感觉是速度有一些提升,但不是很多,时快时慢的,我的建议是别开。
路线
路线1:传统网络架构(云主机 + Nginx/ALB + CDN)
用户 → 公网 CDN → ALB/Nginx → 服务 → 返回用户
- 时间:同洲 RTT 50
150ms,跨洲 180300ms(取决于公网路径与 CDN 回源)。
路线2:Cloudflare + 源站(反向代理加速)
用户 → Cloudflare Anycast 边缘(TLS/WAF/缓存/Argo 可选)→ 源站/ALB → 内网服务 → 返回用户
- 时间:同洲 20
80ms;跨洲 120220ms(命中缓存更低;未命中需回源)。
路线3:Cloudflare + Worker(边缘渲染/中间层)
用户 → Cloudflare 边缘(Worker 运行 Next.js/Pages Functions) → 返回用户
- 时间:同洲 10
40ms;跨洲 40120ms(多数请求在边缘完成,少量写入或回源略高)。
对比
-
线路1:全部依赖公网/CDN,多层回源。
-
线路2:入口在 Cloudflare,静态边缘缓存,动态回源。
-
线路3:逻辑与数据前移到边缘,回源最少。
数据和基础设施的优势
上述是基础网络层的Cloudflare的优势,但大头还是在数据库和后端基础设施层面。
为什么数据要跟网络绑在一起
前文的"入口近用户 + 骨干回源"解决了请求路由问题,但数据如果还停在单 Region 的数据库里,跨洲写入和一致性依然会卡住。
Cloudflare 把数据层也搬到了 POP 附近:KV/Cache → 纯缓存,D1 → 轻量关系型,R2 → 对象存储,Durable Objects → 单点有序状态,Queues/Cron → 事件驱动。
整套体系的关键是:数据库边缘网关 → Cloudflare 骨干 → 源站,无需走公网。
组件拆解
-
Workers KV / Cache API:极低成本的边缘 K/V 缓存,TTL/命中率高,适合页面片段缓存、Feature Flag、配置。
-
D1:SQLite 语义的关系型,自动做多副本;延迟以 POP 就近为主,不需要你搭读写分离。缺点是还在 Beta/Preview,吞吐和 SQL 功能有上限。
-
R2:对象存储,特点是出网免费,跟 Workers/PAGES 内网读写几乎不要钱,做媒体/静态资源/用户上传比 S3 + CDN 省。
-
Durable Objects (DO):每个 key 一把"锁"一段逻辑,保证在单实例串行处理,适合房间/会话、计数器、防重放。你可以把它当成状态型微服务。
-
Queues + Cron Triggers:补全异步链路,配合 Worker 做任务队列、重试、延时任务。
可用性与高并发
这两个话题永远是后端开发要关注的问题,但在Cloudflare生态中,直接被基础生态解决了。
-
入口级冗余:Anycast 天然多活,POP 挂一个会自动飘到下一站;TLS/WAF/缓存/Worker 在边缘层拆分,避免单 Region 热点。
-
数据级冗余:D1/R2 内建多副本,不需要你自己做主从;KV 跨 POP 复制,读多写少天然高可用。
-
串行化热点:用 Durable Objects 把写热点"锁"成单实例,避免竞态和双写;并发读可以走 KV/R2/D1 只写 DO 的结果。
-
水平分片:DO key 自然就是分片键,按用户/房间/租户切分,避免单 key 挡住吞吐;D1 按表/租户拆库或拆表。
-
压测策略 :边缘逻辑比中心化服务更容易被放大,要在本地
miniflare/wrangler dev做 burst 测试,再用 Load Testing 工具打 POP 入口,看 DO/Queue 延时。 -
降级路径:KV 读失败回源 D1/R2;DO 超时走幂等重试/队列;Queue 消费失败自动重试 + 死信,确保高峰不丢单。
问题
-
D1 还不支持事务/触发器/大部分高级 SQL,容量和 QPS 有上限,吞吐和一致性都需要按产品路线图来等。
-
CPU 时间和内存有限制(如 50ms+ 增量计费),长尾逻辑必须拆成 DO/Queue;对重 CPU/IO 的任务不友好。
-
本地模拟不完全等于线上:miniflare/wrangler dev 能跑 DO/KV/Queues,但和真实 POP 行为有差异,需要早做预发验证。
-
观测链路还在补齐:Logpush/Analytics 有用但成本也不低,想要分布式追踪或 APM 级体验需要自己拼。
-
迁移绑定度高:KV/DO 是 Cloudflare 专有模型,未来要上公有云数据库或 K8s 需要写适配层。
但这些问题,都是可以通过逻辑和系统设计来绕开的,是完全能覆盖中小型企业的需求。
成本
同等流量下,Cloudflare 的"边缘 + 内网"计费模型对出海站点很友好,但也要看业务形态。下面是一个粗粒度对比(以小团队常用的免费/入门档为例,价格会随区域和档位浮动):
| 项目 | Cloudflare | Vercel | AWS(CloudFront+Lambda@Edge+S3/RDS) | 传统云自建(CDN+ALB+ECS/DB) |
|---|---|---|---|---|
| 入口/网络 | Anycast 免费,基础 WAF/DDoS 免费,Argo 计费 | Pro 计费,Edge Functions 含在请求费里 | CloudFront 按流量 + 请求计费,WAF 另收 | CDN/ALB 按带宽/请求计费,WAF 另收 |
| 动态计算 | Workers 免费档每天 10M 请求,超出按请求+CPU 时间 | Edge Functions 按执行次数 + 执行时长 | Lambda@Edge 按调用和时长 | ECS/VM 按实例数,需自运维 |
| 静态/存储 | R2 对外出网免费,存储按量计费;KV 便宜 | 静态托管含在计划内,存储/带宽有限 | S3 存储便宜但出网贵 | 对象存储/带宽按量计费,跨区出网高 |
| 数据库 | D1 便宜但预览期功能有限;DO 用量计费 | KV/Blob 存储为主,无托管关系型 | RDS 全量能力但成本较高,跨洲性能靠加速 | 自建或托管 DB,需备份/高可用方案 |
| 观测/日志 | Analytics 基础免费,Logpush 按量 | 内置监控,日志在高档位 | CloudWatch 按日志/指标计费 | 第三方或自建,需运维 |
| 总体小流量成本 | 极低,适合出海和读多写少 | 前端体验好,中小流量可控 | 分项收费,出网+WAF 成本显著 | 需要人力运维,月度固定成本高 |
基本没什么好想的,项目体量小的时候,打包不超过3M,能直接免费用Cloudflare,超过3M后的每月5$的套餐完全也能撑得起来业务。在体量起来后,成本的差别能达到几百倍。
开发速度
Next.js 现在已经是全栈框架,配合 Cloudflare 的一体化产品,可以把"前端 + 中间层 + 部署"合在一起,少踩很多坑。
而最佳实践无非是使用opennextjs/cloudflare,
什么是OpenNext?
OpenNext 是一个 让 Next.js 可以"脱离 Vercel,自托管"的开源适配层 / 打包工具链。
把 next build 的输出转换成可以在 AWS Lambda、Cloudflare Workers、Netlify 等 FaaS/边缘平台上直接部署的包。
为啥会有 OpenNext?Next.js 原生的"官方最佳形态"是跑在 Vercel 上,如果你想:用 AWS Lambda + API Gateway + CloudFront 之类的无服务器架构,或者用 Cloudflare Workers / Pages、Netlify 等。
别的平台又想尽量支持 App Router、SSR、ISR、Middleware、Image Optimization、Server Actions 这些新特性就会发现:
不同社区自己写了一堆"Next.js on AWS/Cloudflare/Netlify"的适配实现,但 Next.js 版本更新很快,各家实现很难长期维护,我其实理解 OpenNext 就是把这些努力"合并为一个标准方案"的社区项目。
真的很感谢OpenNext的开源工作者,这件事真的很有意义,特别是做适配Nextjs的缓存层,并整合各家。
如果有感兴趣的小伙伴可以看看我博客,有专门讲如何使用Cloudflare + OpenNext构建AI应用,具体的东西已经讲了很多遍了。
并且我博客本身也是用的这一套。
总结
更高一层看,这是"把互联网当作计算平台"的落地范式:网络、计算、存储前移到全球边缘,小团队不必重复造 VPC/K8s/多活,也能用低成本拿到接近"大厂基础设施"的体验。技术的本质是把复杂度藏在平台里,让业务更快试错、更快出海,Cloudflare + Next.js + OpenNext 正好是当下最具性价比的组合之一。