本文分享如何规划使用LangGraph构建智能体(Agents)。
使用 LangGraph 构建智能体时,你首先需要将其拆解为多个独立的步骤,这些步骤被称为 "节点"(nodes)。接着,你要定义每个节点对应的不同决策逻辑,以及节点之间的过渡规则。最后,通过一个共享状态(shared state)将所有节点连接起来,每个节点都能从该共享状态中读取数据,也能向其中写入数据。本文将结合构建客户支持邮件智能体这一实际案例,展示如何逐步梳理使用LangGraph规划和实现智能体的思考过程。
一、从业务流程入手
假设你需要构建一个处理客户支持邮件的AI智能体,你的产品团队已向你提出以下需求:
text
智能体应具备以下功能:
- 读取收到的客户邮件
- 按紧急程度和主题对邮件进行分类
- 检索相关文档以解答问题
- 起草恰当的回复内容
- 将复杂问题升级转交给人工客服
- 在需要时安排后续跟进
智能体需处理的示例场景:
- 简单产品问题:"如何重置我的密码?"
- 漏洞反馈:"当我选择 PDF 格式时,导出功能会崩溃"
- 紧急账单问题:"我的订阅被重复扣费了!"
- 功能需求:"你们能给移动应用添加深色模式吗?"
- 复杂技术问题:"我们的 API 集成会间歇性失败,并出现 504 错误"二、构建智能体的基本流程
利用LangGraph实现智能体(agent),通常需遵循以下五个步骤。
步骤 1:将工作流程拆解为独立步骤(节点)
首先明确流程中的各个独立步骤,每个步骤将转化为一个节点(即执行特定任务的函数)。随后,梳理这些步骤之间的连接关系并进行简要规划。
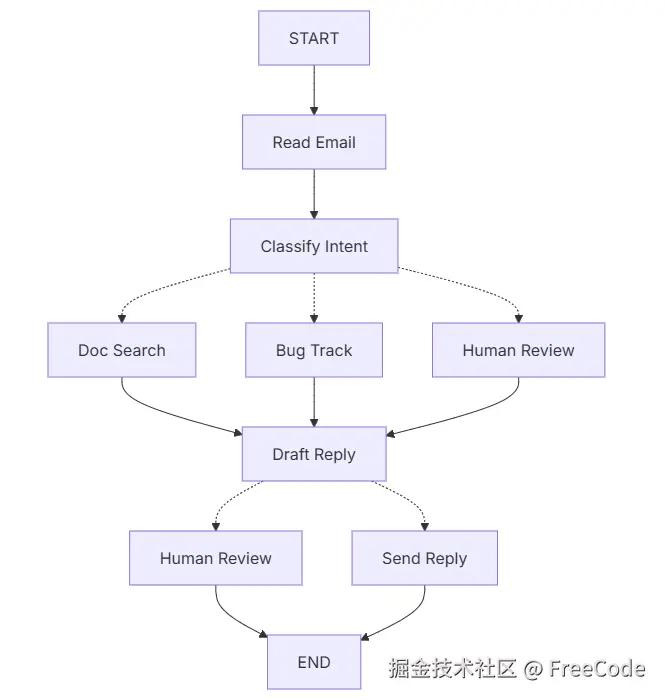
图中的箭头代表可能的路径,但具体选择哪条路径的决策过程会在每个节点内部完成。 接下来我们明确每个节点需要完成的任务:
- 读取邮件(Read Email):提取并解析邮件内容
- 意图分类(Classify Intent):使用大语言模型(LLM)对邮件的紧急程度和主题进行分类,随后将其导向对应的处理操作
- 文档检索(Doc Search):在知识库中查询相关信息
- 漏洞跟踪(Bug Track):在跟踪系统中创建或更新问题记录
- 起草回复(Draft Reply):生成恰当的回复内容
- 人工审核(Human Review):将问题升级至人工客服,由其进行审批或处理
- 发送回复(Send Reply):发送邮件回复
步骤 2:确定每个节点的节点类型及操作逻辑
针对图中的每个节点,确定其代表的操作类型,以及确保该节点正常运行所需的操作逻辑。
2.1 节点类型
- 大模型步骤(LLM steps) 当你需要理解、分析、生成文本或做出推理决策时,可使用此步骤。
- 数据步骤(Data steps) 当你需要从外部来源检索信息时,可使用此步骤。
- 操作步骤(Action steps) 当你需要执行外部操作时,可使用此步骤。
- 用户输入步骤(User input steps) 当你需要人工干预时,可使用此步骤。
本案例中的节点类型如下:
- 读取邮件(Read Email):数据步骤
- 意图分类(Classify Intent):大模型步骤
- 文档检索(Doc Search):数据步骤
- 漏洞跟踪(Bug Track):操作步骤
- 起草回复(Draft Reply):大模型步骤
- 人工审核(Human Review):用户输入步骤
- 发送回复(Send Reply):操作步骤
2.2 节点操作逻辑
LLM steps:
- 意图分类(Classify Intent)
- 静态上下文(提示词):分类类别、紧急程度定义、响应格式
- 动态上下文(来自状态):邮件内容、发送方信息
- 预期结果:用于确定路由方向的结构化分类结果
- 起草回复(Draft Reply)
- 静态上下文(提示词):语气指南、公司政策、回复模板
- 动态上下文(来自状态):分类结果、检索结果、客户历史记录
- 预期结果:可提交审核的专业邮件回复
Data steps:
- 文档检索(Document Search)
- 参数(Parameters):根据意图和主题构建的查询语句
- 重试策略(Retry strategy):支持重试;针对暂时性故障,采用指数退避算法(即重试间隔逐渐延长)
- 缓存(Caching):可对常见查询结果进行缓存,以减少 API 调用次数
- 客户历史记录查询(Customer History Lookup)
- 参数(Parameters):从状态(state)中获取的客户邮箱或客户 ID
- 重试策略(Retry strategy):支持重试;若无法获取完整历史记录,将降级返回基础客户信息
- 缓存(Caching):支持缓存;通过设置 "存活时间"(time-to-live,TTL)平衡数据新鲜度与查询性能
Action steps:
- 发送回复(Send Reply)
- 节点执行时机:审批通过后(人工审批或自动审批均可触发)
- 重试策略:支持重试;针对网络问题,采用指数退避算法(即重试间隔逐渐延长)
- 缓存设置:不应缓存;每一次发送操作均为独立且唯一的行为,无法通过缓存复用结果
- 漏洞跟踪(Bug Track)
- 节点执行时机:当意图分类结果为 "漏洞(bug)" 时,该节点必执行
- 重试策略:支持重试;漏洞报告不可丢失,因此重试机制对该节点至关重要
- 返回结果:生成工单编号(Ticket ID),需将该编号包含在回复内容中
User input steps:
- 人工审核(Human Review)
- 决策依据(Context for decision):原始邮件、回复草稿、紧急程度、分类结果
- 预期输入格式(Expected input format):审批结果(布尔值,即 "通过" 或 "不通过"),以及可选的修改后回复内容
- 触发时机(When triggered):邮件属于高紧急程度、涉及复杂问题,或存在回复质量争议时
步骤 3:设计状态(State)
状态是智能体中所有节点均可访问的共享内存。可以将其理解为智能体的 "笔记本",用于记录智能体在处理流程中获取的所有信息及做出的所有决策。
3.1 哪些内容应纳入状态?
针对每一项数据,可通过以下问题判断是否需要纳入状态:
- 纳入状态的情况:该数据是否需要在多个步骤间保留?若需要,则应纳入状态。
- 无需存储的情况:该数据是否可从其他数据中推导得出?若可以,则无需存储在状态中,只需在需要时计算获取即可。
对于我们的邮件智能体,需跟踪记录以下内容:
- 原始邮件及发送方信息(后续无法重新获取)
- 分类结果(供后续多个下游节点使用)
- 检索结果与客户数据(重新获取成本较高)
- 回复草稿(需保留至审核环节)
- 执行元数据(用于调试与故障恢复)
3.2 保持状态原始性,按需格式化提示词
核心原则:状态应存储原始数据,而非格式化文本。仅在节点内部需要时,再对提示词进行格式化处理。 这种分离方式具有以下优势:
- 不同节点可根据自身需求,对相同数据进行差异化格式化。
- 无需修改状态结构,即可直接调整提示词模板。
- 调试过程更清晰 ------ 能准确查看每个节点接收的原始数据。
- 智能体可灵活迭代升级,且不会破坏已有的状态数据。
下面我们来定义状态的具体内容:
python
from typing import TypedDict, Literal
# Define the structure for email classification
class EmailClassification(TypedDict):
intent: Literal["question", "bug", "billing", "feature", "complex"]
urgency: Literal["low", "medium", "high", "critical"]
topic: str
summary: str
class EmailAgentState(TypedDict):
# Raw email data
email_content: str
sender_email: str
email_id: str
# Classification result
classification: EmailClassification | None
# Raw search/API results
search_results: list[str] | None # List of raw document chunks
customer_history: dict | None # Raw customer data from CRM
# Generated content
draft_response: str | None
messages: list[str] | None需注意,状态中仅包含原始数据 ------ 不含提示词模板、格式化字符串及指令。分类结果直接来自大语言模型(LLM),并以单个字典的形式存储。
步骤 4:构建节点(Nodes)
现在我们将每个步骤实现为一个函数。LangGraph中的节点本质上是一个Python函数,它接收当前的状态(state),并返回对该状态的更新结果。
4.1 妥善处理错误
不同类型的错误需要采用不同的处理策略:
| 错误类型 | 处理责任人 | 处理策略 | 适用场景 |
|---|---|---|---|
| 暂时性错误(网络问题、速率限制) | 系统(自动处理) | 重试策略 RetryPolicy(max_attempts=3, initial_interval=1.0) | 通常重试后可解决的临时性故障 |
| 大模型(LLM)可恢复错误(工具故障、解析问题) | 大语言模型(LLM) | 将错误存储到状态中并返回重试 | 大语言模型能识别错误并调整处理方式的情况 |
| 用户可修复错误(信息缺失、指令模糊) | 人工 | 调用 interrupt () 函数暂停流程 | 需要用户补充输入才能继续推进的情况 |
| 意外错误 | 开发人员 | 允许错误向上传递(不拦截) | 需调试排查的未知问题 |
4.2 实现邮件智能体节点
我们将每个节点实现为一个简单函数。需谨记:节点接收状态(state)、执行任务,并返回状态更新结果。
4.2.1 读取和分类节点:
python
from typing import Literal
from langgraph.graph import StateGraph, START, END
from langgraph.types import interrupt, Command, RetryPolicy
from langchain_openai import ChatOpenAI
from langchain.messages import HumanMessage
llm = ChatOpenAI(model="gpt-4")
def read_email(state: EmailAgentState) -> dict:
"""Extract and parse email content"""
# In production, this would connect to your email service
return {
"messages": [HumanMessage(content=f"Processing email: {state['email_content']}")]
}
def classify_intent(state: EmailAgentState) -> Command[Literal["search_documentation", "human_review", "draft_response", "bug_tracking"]]:
"""Use LLM to classify email intent and urgency, then route accordingly"""
# Create structured LLM that returns EmailClassification dict
structured_llm = llm.with_structured_output(EmailClassification)
# Format the prompt on-demand, not stored in state
classification_prompt = f"""
Analyze this customer email and classify it:
Email: {state['email_content']}
From: {state['sender_email']}
Provide classification including intent, urgency, topic, and summary.
"""
# Get structured response directly as dict
classification = structured_llm.invoke(classification_prompt)
# Determine next node based on classification
if classification['intent'] == 'billing' or classification['urgency'] == 'critical':
goto = "human_review"
elif classification['intent'] in ['question', 'feature']:
goto = "search_documentation"
elif classification['intent'] == 'bug':
goto = "bug_tracking"
else:
goto = "draft_response"
# Store classification as a single dict in state
return Command(
update={"classification": classification},
goto=goto
)4.2.2 搜索和跟踪节点:
python
def search_documentation(state: EmailAgentState) -> Command[Literal["draft_response"]]:
"""Search knowledge base for relevant information"""
# Build search query from classification
classification = state.get('classification', {})
query = f"{classification.get('intent', '')} {classification.get('topic', '')}"
try:
# Implement your search logic here
# Store raw search results, not formatted text
search_results = [
"Reset password via Settings > Security > Change Password",
"Password must be at least 12 characters",
"Include uppercase, lowercase, numbers, and symbols"
]
except SearchAPIError as e:
# For recoverable search errors, store error and continue
search_results = [f"Search temporarily unavailable: {str(e)}"]
return Command(
update={"search_results": search_results}, # Store raw results or error
goto="draft_response"
)
def bug_tracking(state: EmailAgentState) -> Command[Literal["draft_response"]]:
"""Create or update bug tracking ticket"""
# Create ticket in your bug tracking system
ticket_id = "BUG-12345" # Would be created via API
return Command(
update={
"search_results": [f"Bug ticket {ticket_id} created"],
"current_step": "bug_tracked"
},
goto="draft_response"
)4.2.3 响应节点:
python
def draft_response(state: EmailAgentState) -> Command[Literal["human_review", "send_reply"]]:
"""Generate response using context and route based on quality"""
classification = state.get('classification', {})
# Format context from raw state data on-demand
context_sections = []
if state.get('search_results'):
# Format search results for the prompt
formatted_docs = "\n".join([f"- {doc}" for doc in state['search_results']])
context_sections.append(f"Relevant documentation:\n{formatted_docs}")
if state.get('customer_history'):
# Format customer data for the prompt
context_sections.append(f"Customer tier: {state['customer_history'].get('tier', 'standard')}")
# Build the prompt with formatted context
draft_prompt = f"""
Draft a response to this customer email:
{state['email_content']}
Email intent: {classification.get('intent', 'unknown')}
Urgency level: {classification.get('urgency', 'medium')}
{chr(10).join(context_sections)}
Guidelines:
- Be professional and helpful
- Address their specific concern
- Use the provided documentation when relevant
"""
response = llm.invoke(draft_prompt)
# Determine if human review needed based on urgency and intent
needs_review = (
classification.get('urgency') in ['high', 'critical'] or
classification.get('intent') == 'complex'
)
# Route to appropriate next node
goto = "human_review" if needs_review else "send_reply"
return Command(
update={"draft_response": response.content}, # Store only the raw response
goto=goto
)
def human_review(state: EmailAgentState) -> Command[Literal["send_reply", END]]:
"""Pause for human review using interrupt and route based on decision"""
classification = state.get('classification', {})
# interrupt() must come first - any code before it will re-run on resume
human_decision = interrupt({
"email_id": state.get('email_id',''),
"original_email": state.get('email_content',''),
"draft_response": state.get('draft_response',''),
"urgency": classification.get('urgency'),
"intent": classification.get('intent'),
"action": "Please review and approve/edit this response"
})
# Now process the human's decision
if human_decision.get("approved"):
return Command(
update={"draft_response": human_decision.get("edited_response", state.get('draft_response',''))},
goto="send_reply"
)
else:
# Rejection means human will handle directly
return Command(update={}, goto=END)
def send_reply(state: EmailAgentState) -> dict:
"""Send the email response"""
# Integrate with email service
print(f"Sending reply: {state['draft_response'][:100]}...")
return {}步骤 5:将各部分连接起来
现在我们要把所有节点连接成一个可运行的图(graph)。由于我们的节点会自行处理路由决策,因此只需设置几条关键的边(edge,即节点间的连接关系)即可。
若要通过interrupt()函数实现 "人机协作"(human-in-the-loop)功能,我们需要结合检查点程序(checkpointer)进行编译,以在两次运行之间保存状态。
5.1 代码实现
python
from langgraph.checkpoint.memory import MemorySaver
from langgraph.types import RetryPolicy
# Create the graph
workflow = StateGraph(EmailAgentState)
# Add nodes with appropriate error handling
workflow.add_node("read_email", read_email)
workflow.add_node("classify_intent", classify_intent)
# Add retry policy for nodes that might have transient failures
workflow.add_node(
"search_documentation",
search_documentation,
retry_policy=RetryPolicy(max_attempts=3)
)
workflow.add_node("bug_tracking", bug_tracking)
workflow.add_node("draft_response", draft_response)
workflow.add_node("human_review", human_review)
workflow.add_node("send_reply", send_reply)
# Add only the essential edges
workflow.add_edge(START, "read_email")
workflow.add_edge("read_email", "classify_intent")
workflow.add_edge("send_reply", END)
# Compile with checkpointer for persistence, in case run graph with Local_Server --> Please compile without checkpointer
memory = MemorySaver()
app = workflow.compile(checkpointer=memory)这个图的结构十分简洁,因为路由功能是通过Command对象在节点内部实现的。每个节点会借助类型提示(如CommandLiteral\["节点1", "节点2"])声明其可跳转至的节点,这让整个流程既清晰明确,又便于追踪。
5.2 运行测试
我们用一个需要人工审核的紧急账单问题来运行这个智能体:
python
# Test with an urgent billing issue
initial_state = {
"email_content": "I was charged twice for my subscription! This is urgent!",
"sender_email": "customer@example.com",
"email_id": "email_123",
"messages": []
}
# Run with a thread_id for persistence
config = {"configurable": {"thread_id": "customer_123"}}
result = app.invoke(initial_state, config)
# The graph will pause at human_review
print(f"Draft ready for review: {result['draft_response'][:100]}...")
# When ready, provide human input to resume
from langgraph.types import Command
human_response = Command(
resume={
"approved": True,
"edited_response": "We sincerely apologize for the double charge. I've initiated an immediate refund..."
}
)
# Resume execution
final_result = app.invoke(human_response, config)
print(f"Email sent successfully!")当图执行到interrupt()函数时会暂停,将所有数据保存到检查点程序(checkpointer)中并等待。它可以在数天后恢复运行,且能精准从暂停处继续执行。thread_id(线程 ID)可确保该对话相关的所有状态数据被统一保存。
三、总结
3.1 核心洞见
构建这个邮件智能体的过程,让我们理解了 LangGraph 的核心思路:
- 拆解为独立步骤:每个节点专注做好一件事。这种拆解支持流式进度更新、可暂停可恢复的稳定执行,且便于调试 ------ 因为能在步骤间查看状态数据。
- 状态即共享内存:仅存储原始数据,不存储格式化文本。这样不同节点可根据需求,以不同方式使用同一信息。
- 节点即函数:节点接收状态、执行任务并返回更新后的状态。当需要做路由决策时,节点会同时指定状态更新内容与下一个目标节点。
- 错误是流程的一部分:暂时性故障通过重试解决,大语言模型(LLM)可恢复错误会携带上下文返回重试,用户可修复问题会暂停等待输入,意外错误则向上传递以便调试。
- 人工输入是核心功能:interrupt()函数会无限期暂停执行、保存所有状态,且在提供输入后能从暂停处精准恢复。若在节点中与其他操作结合使用,该函数必须优先执行。
- 图结构自然形成:只需定义关键连接,节点会自行处理路由逻辑。这让控制流程清晰明确且可追踪 ------ 查看当前节点,就能始终了解智能体下一步的操作。
3.2 节点拆分考量
你可能会疑惑:为何不将 "读取邮件(Read Email)" 与 "意图分类(Classify Intent)" 合并为一个节点?又为何要将 "文档检索(Doc Search)" 与 "起草回复(Draft Reply)" 拆分开来?答案涉及韧性(resilience)和可观测性(observability)的考量。
3.2.1 韧性和可观测性考量:
LangGraph 的稳定执行会在节点边界处创建检查点。当工作流因中断或故障恢复时,会从执行停止的节点起点重新开始。节点越小,检查点频率越高,若出现问题,需要重复执行的工作量就越少。若将多个操作合并为一个大型节点,一旦在节点执行后期出现故障,就需从该节点起点重新执行所有操作。
我们为邮件智能体选择这种拆分方式的原因如下:
- 外部服务隔离:"文档检索" 与 "漏洞跟踪(Bug Track)" 是独立节点,因为它们需调用外部 API。若检索服务响应缓慢或出现故障,我们可将其与大语言模型(LLM)调用隔离开来,仅为这些特定节点添加重试策略,而不影响其他节点。
- 中间过程可见性:将 "意图分类" 设为独立节点,能让我们在执行后续操作前,先查看大语言模型的决策结果。这对调试和监控至关重要 ------ 你能准确了解智能体何时、为何会将任务路由至人工审核。
- 不同故障模式适配:大语言模型调用、数据库查询、邮件发送的重试策略各不相同。独立节点允许你为它们单独配置策略。
- 可复用性与可测试性:小型节点更易单独测试,也能在其他工作流中复用。
你也可以将 "读取邮件" 与 "意图分类" 合并为单个节点。但这样做会失去分类前查看原始邮件的能力,且该节点若出现故障,需重复执行这两项操作。对大多数应用而言,独立节点带来的可观测性与调试优势,值得为此付出权衡代价。
3.2.2 应用层考量:
步骤2中关于缓存的讨论(是否缓存检索结果)属于应用层决策,而非LangGraph框架的固有功能。你需根据具体需求在节点函数内部实现缓存逻辑 ------LangGraph不对此做强制规定。
3.2.3 性能考量:
节点数量多并不意味着执行速度慢。LangGraph默认在后台写入检查点(异步稳定模式,async durability mode),因此你的图(graph)会持续运行,无需等待检查点写入完成。这意味着你能以极小的性能损耗,获得高频次检查点。若有需要,你也可调整此行为:使用 "退出模式(exit mode)" 仅在执行完成时创建检查点,或使用 "同步模式(sync mode)" 阻塞执行,直至每个检查点写入完成。