Redis 4.0 升级至 5.0 实施手册
一、背景
为提升 Redis 服务的性能、稳定性及功能扩展性,计划将现有 Redis 4.0 版本升级至 5.0 版本。Redis 5.0 虽与 4.0 整体兼容性较好,但升级过程需兼顾客户端适配、数据兼容、集群高可用及业务无感知等核心要点,同时需解决配置分散、自动重连验证等实际问题,确保升级平稳落地。
二、解决方案
通过"定位业务服务→验证重连机制"的核心逻辑,保障升级后业务与 Redis 服务的适配性,具体步骤如下:
- 基于 Redis 实例查询已建立连接的客户端,定位客户端所属主机;
- 在该主机上排查运行中的 JVM 进程,根据进程 ID 核查是否占用 Redis 端口;
- 确定目标 JVM 服务的工作目录,以此锁定实际使用该 Redis 实例的业务服务;
- 检索对应项目代码中 Redis 实例的构造参数,验证其是否支持 Redis 服务升级过程中的中断重连机制。
三、前置处理
将 Redis 从 4.0 升级到 5.0 时,虽整体兼容性较好,但需重点关注以下关键事项,确保升级过程平稳且业务不受影响:
1. 版本兼容性检查
(1)客户端兼容性
- 客户端版本:确保业务使用的 Redis 客户端(如 Jedis、Lettuce 等)适配 Redis 5.0,具体版本要求:
-
- Jedis 需升级至 2.10.0+(推荐 3.x 及以上版本,更好适配 Redis 5.0 新特性);
- Lettuce 需升级至 5.0+ 版本,以支持 Redis 5.0 新增命令及协议优化。
- 命令兼容性 :Redis 5.0 新增
ZPOPMIN/ZPOPMAX、XADD(Stream 相关)等命令,旧客户端可能不支持,但SET、GET、INCR等基础命令完全兼容,不影响现有核心业务。
(2)数据格式兼容性
- Redis 5.0 对 String、Hash、List 等现有数据结构的存储格式无变更,升级后可直接读取 4.0 版本数据,无需数据迁移或转换;
- 持久化文件(RDB/AOF)格式兼容:Redis 5.0 可加载 4.0 生成的 RDB 和 AOF 文件,低版本(4.0)无法加载高版本(5.0)生成的持久化文件,需做好版本回滚的数据备份。
2. 新特性与行为变更
需评估 Redis 5.0 新特性的应用场景,及现有业务是否受行为变更影响:
(1)核心新特性(可选使用)
- Stream 数据结构:类 Kafka 的持久化消息队列,支持消费组、消息确认等机制,可替代 List 实现的简单队列,适用于需可靠消息队列的业务场景;
ZPOPMIN/ZPOPMAX命令:原子性弹出有序集合最小/最大元素,替代ZRANGE + ZREM组合操作,适配优先级队列场景;- 改进的主从复制:优化复制过程中网络中断恢复逻辑,降低全量同步概率,提升集群稳定性;
- Lua 脚本优化 :扩展
EVAL命令参数列表,执行效率略有提升,现有 Lua 脚本无需修改即可兼容。
(2)行为变更(需重点注意)
EXISTS命令扩展:支持同时检查多个 key(返回存在的数量),但单 key 检查行为不变(返回 1/0),对现有代码无影响;TYPE命令返回值细化:如对 Stream 类型返回stream、对过期键返回对应类型(4.0 可能返回none),常规业务极少依赖该返回值,无需调整;- 过期键删除策略:底层优化清理效率,对外行为(键过期后不可访问)不变,不影响业务逻辑。
3. 集群与高可用调整
(1)Redis Cluster
- 5.0 优化集群故障转移速度和槽位迁移效率,升级后稳定性提升;
- 升级策略:先升级从节点,再升级主节点(滚动升级),避免集群不可用。
(2)哨兵(Sentinel)
- 5.0 微调哨兵故障检测逻辑,提升主从切换准确性,无需修改哨兵配置即可兼容;
- 升级顺序:先升级哨兵集群,再升级 Redis 节点,确保哨兵能正确识别新版本节点。
4. 性能与资源考量
- 内存占用:对 Hash、Set 等数据结构的内存编码优化,相同数据量下内存占用略有降低,整体差异较小;
- CPU 与网络 :优化网络 IO 处理和命令执行效率,高并发场景吞吐量可提升 5%-10%;需避免使用
KEYS、FLUSHALL等阻塞命令,否则仍可能出现性能波动; - 持久化优化:AOF 重写和 RDB 生成效率提升,降低持久化对业务的影响。
5. 升级步骤与回滚预案
(1)环境准备
- 在测试环境部署 Redis 5.0,加载生产环境的 RDB/AOF 文件完成兼容性测试,验证所有依赖 Redis 的核心业务流程;
- 检查并升级客户端至兼容 5.0 的版本,在测试环境完成功能验证。
(2)滚动升级(推荐)
- 单机部署:停止 4.0 实例 → 替换为 5.0 二进制文件 → 加载原有 RDB/AOF 启动 → 验证功能后对外提供服务;
- 主从集群:先升级从节点(停止 → 升级 5.0 → 启动并同步主节点)→ 切换主节点(哨兵自动/手动切换)→ 升级原主节点为从节点;
- Redis Cluster :逐个升级从节点 → 通过
CLUSTER FAILOVER安全切换主从 → 升级原主节点。
(3)回滚预案
- 升级前全量备份 RDB/AOF 文件,若升级后出现异常,立即回滚至 4.0 版本,加载备份文件恢复数据;
- 实时监控升级后核心指标(内存、CPU、响应时间、错误率),异常时切换至备用集群。
6. 其他注意事项
- 模块兼容性:若使用 RedisJSON、RediSearch 等模块,需确保模块版本与 Redis 5.0 适配(模块通常绑定特定 Redis 版本);
- 配置参数 :Redis 5.0 新增
stream-node-max-bytes等配置,原有配置完全兼容,无需修改; - 日志与监控 :升级后关注 Redis 日志,及时处理
WARNING级别的兼容性提示(如旧命令废弃),调整相关业务代码。
四、问题分类
在 Redis 服务升级过程中,核心问题集中在以下两类:
- 项目重启环节:Redis 相关配置未集中管理,散落在配置文件、启动命令行参数、Maven 的 pom 文件等位置,导致重启前配置核对不全面,易引发配置遗漏或错误;
- 自动重连验证环节:需通过 Redis 后台管理界面/工具查询与实例建立连接的服务器列表,以此判断业务服务的 Redis 自动重连机制在升级中断场景下是否正常触发。
五、实操步骤
步骤1:定位 Redis 连接客户端及所属主机
-
登录 Redis 实例所在服务器,执行
redis-cli进入 Redis 客户端交互界面; -
执行
CLIENT LIST命令,获取所有已建立连接的客户端信息,提取关键字段:
-
addr:客户端 IP 与端口(格式为IP:Port),用于定位客户端所属主机;fd:文件描述符,辅助确认连接有效性;age:连接时长,筛选长期活跃的业务客户端;
- 整理客户端 IP 列表,与服务器资产信息匹配,确定每个客户端对应的业务主机。
步骤2:排查主机上运行的 JVM 进程并核查 Redis 端口占用
- 登录目标业务主机,执行以下命令列出所有运行中的 JVM 进程:
bash
jps -l # 显示进程 PID 及对应主类/ Jar 包路径- 针对每个 JVM 进程,核查是否占用 Redis 端口(默认 6379,需替换为实际端口):
perl
ss -tunp | grep <JVM进程PID> | grep <Redis端口>- 记录符合条件的进程信息:PID、进程名称、Jar 包路径/主类名,确认进程状态为
RUNNING。
步骤3:解析 JVM 启动参数,确定服务工作目录
- 执行以下命令查看目标 JVM 进程的完整启动参数:
xml
jinfo <JVM进程PID> # 或 jps -v | grep <JVM进程PID>
bash
# 如果是Tomcat项目,可使用jps -lvm和readlink -f获取对应PID和工程目录
jps -lvm
readlink -f /proc/<JVM进程PID>/cwd/- 从启动参数中提取关键信息:
-
user.dir:JVM 工作目录(核心);spring.config.location/--spring.config.name:配置文件路径,辅助确认服务归属;classpath:类路径,验证服务代码目录;
- 进入
user.dir目录,结合进程信息确认服务的部署路径与业务归属。
步骤4:锁定实际使用 Redis 的业务服务
- 基于 JVM 工作目录与进程信息,定位业务服务标识:
-
- 查看目录下的
application.yml/redis.properties等配置文件,确认 Redis 连接信息(地址、端口、密码)与目标实例匹配; - 核对 Jar 包名称/主类名,关联至具体业务服务(如订单服务、用户服务);
- 查看目录下的
- 记录业务服务信息:服务名称、部署路径、负责人、代码仓库地址。
步骤5:检索项目代码验证 Redis 中断重连机制
- 拉取目标业务服务的源代码,检索 Redis 实例构造相关代码:
-
- Jedis 客户端 :查找
JedisPoolConfig/JedisPool初始化代码,重点检查以下参数:
- Jedis 客户端 :查找
scss
// 重连相关核心参数
poolConfig.setMaxTotal(200); // 最大连接数
poolConfig.setMaxIdle(50); // 最大空闲连接
poolConfig.setTestOnBorrow(true); // 借用连接时测试有效性
JedisPool jedisPool = new JedisPool(poolConfig, host, port, Protocol.DEFAULT_TIMEOUT, password, ssl);
// 手动重连逻辑:是否捕获 JedisConnectionException 并触发重连-
- Lettuce 客户端 :查找
LettuceConnectionFactory初始化代码,重点检查:
- Lettuce 客户端 :查找
scss
LettuceClientConfiguration clientConfig = LettuceClientConfiguration.builder()
.commandTimeout(Duration.ofSeconds(5))
.reconnectAttempts(3) // 重连次数
.reconnectInterval(Duration.ofMillis(1000)) // 重连间隔
.build();- 验证重连机制有效性:
-
- 确认重连参数配置合理(如重连次数≥3、重连间隔 1-3 秒);
- 检查代码中是否捕获
RedisConnectionFailureException等连接异常,并实现自动重连逻辑; - 若存在自定义 Redis 连接池,核查池化策略是否支持连接失效后自动重建。
步骤6:处理 Redis 配置分散问题(前置/并行操作)
- 全量梳理目标服务的 Redis 配置存储位置:
| 配置位置 | 核查内容 |
|---|---|
| 配置文件(application.yml/redis.properties) | Redis 地址、端口、密码、连接池参数 |
| 启动命令(如 start.sh 中的 java -jar 参数) | 外部传入的 Redis 配置(如 --redis.host=xxx) |
| Maven POM 文件 | Redis 客户端依赖版本、自定义配置依赖 |
- 统一核对配置值,确保所有位置的 Redis 连接信息一致;
- 升级前修正配置错误/不一致项,建议后续将配置迁移至配置中心(Nacos/Apollo),避免分散管理。
步骤7:验证自动重连机制(测试/生产验证)
- 测试环境验证:
-
- 模拟 Redis 升级中断:停止 Redis 实例 10 秒后重启;
- 执行以下命令监控业务服务的 Redis 连接状态:
perl
# 实时查看业务服务日志中的连接异常
tail -f <业务服务日志文件> | grep "Redis|connection"
# 查看 Redis 客户端连接恢复情况
redis-cli CLIENT LIST | grep <业务主机IP>-
- 验证核心业务流程(如数据读写、缓存更新)无异常,连接中断后自动恢复。
- 生产环境验证(升级后) :
-
- 通过 Redis 后台管理工具(RedisInsight/运维平台)查看客户端连接列表,确认业务主机重新建联;
- 监控业务服务指标:Redis 调用成功率、响应时间、异常率,确保重连机制生效。
步骤8:升级后兜底验证
- 完成 Redis 4.0 → 5.0 升级后,执行以下命令确认版本:
perl
redis-cli INFO server | grep "redis_version"-
遍历所有关联业务服务,执行核心用例(如下单、支付、数据查询),验证 Redis 交互正常;
-
持续监控 24 小时,重点关注:
-
- Redis 侧:内存占用、CPU 使用率、持久化日志、集群槽位分布(集群版);
- 业务侧:Redis 调用异常日志、接口响应时间、服务可用性。
六、相关脚本
client list 解析
client listclient_list.cl
bash
id=43931324 addr=1xx.2xx.0.240:54695 fd=49 name= age=497974 idle=208 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r traffic-control=NULL cmd=exists type=vpc next_opid=-1 real_addr=
id=43931325 addr=1xx.2xx.0.240:54694 fd=58 name= age=497974 idle=151 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r traffic-control=NULL cmd=exists type=vpc next_opid=-1 real_addr=
id=43931326 addr=1xx.2xx.0.240:54705 fd=59 name= age=497974 idle=174 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r traffic-control=NULL cmd=eval type=vpc next_opid=-1 real_addr=
id=43931327 addr=1xx.2xx.0.240:54699 fd=60 name= age=497974 idle=651 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r traffic-control=NULL cmd=eval type=vpc next_opid=-1 real_addr=
id=43931328 addr=1xx.2xx.0.240:54703 fd=61 name= age=497974 idle=208 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r traffic-control=NULL cmd=eval type=vpc next_opid=-1 real_addr=
id=43931329 addr=1xx.2xx.0.240:54707 fd=62 name= age=497974 idle=651 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r traffic-control=NULL cmd=eval type=vpc next_opid=-1 real_addr=
id=43931330 addr=1xx.2xx.0.240:54709 fd=63 name= age=497974 idle=114 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r traffic-control=NULL cmd=hexists type=vpc next_opid=-1 real_addr=
id=43931331 addr=1xx.2xx.0.240:54719 fd=65 name= age=497974 idle=651 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r traffic-control=NULL cmd=hexists type=vpc next_opid=-1 real_addr=client_list.py
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Redis客户端列表响应解析器
用于解析redis client_list命令的输出结果
"""
import os
import socket
from typing import Dict, Set, Optional
class RedisClientInfo:
"""Redis客户端连接信息类
用于存储和操作Redis客户端连接的详细信息
每一行client_list数据对应一个实例
"""
def __init__(self, **kwargs):
"""初始化客户端信息对象
Args:
**kwargs: 客户端信息的各个字段
"""
# 基本连接信息
self.id: Optional[str] = kwargs.get('id')
self.addr: Optional[str] = kwargs.get('addr')
self.fd: Optional[str] = kwargs.get('fd')
self.name: Optional[str] = kwargs.get('name')
# 状态信息
self.age: Optional[str] = kwargs.get('age')
self.idle: Optional[str] = kwargs.get('idle')
self.flags: Optional[str] = kwargs.get('flags')
self.db: Optional[str] = kwargs.get('db')
# 订阅信息
self.sub: Optional[str] = kwargs.get('sub')
self.psub: Optional[str] = kwargs.get('psub')
# 事务信息
self.multi: Optional[str] = kwargs.get('multi')
# 缓冲区信息
self.qbuf: Optional[str] = kwargs.get('qbuf')
self.qbuf_free: Optional[str] = kwargs.get('qbuf-free')
self.obl: Optional[str] = kwargs.get('obl')
self.oll: Optional[str] = kwargs.get('oll')
self.omem: Optional[str] = kwargs.get('omem')
# 事件和命令信息
self.events: Optional[str] = kwargs.get('events')
self.traffic_control: Optional[str] = kwargs.get('traffic-control')
self.cmd: Optional[str] = kwargs.get('cmd')
# 额外信息
self.type: Optional[str] = kwargs.get('type')
self.next_opid: Optional[str] = kwargs.get('next_opid')
self.real_addr: Optional[str] = kwargs.get('real_addr')
def __str__(self) -> str:
"""返回客户端信息的字符串表示"""
return f"RedisClientInfo(id={self.id}, addr={self.addr}, cmd={self.cmd}, age={self.age}s)"
def __repr__(self) -> str:
"""返回客户端信息的官方字符串表示"""
return self.__str__()
def __eq__(self, other) -> bool:
"""比较两个客户端信息是否相等(基于id)"""
if not isinstance(other, RedisClientInfo):
return False
return self.id == other.id
def __hash__(self) -> int:
"""返回客户端信息的哈希值(基于id)"""
return hash(self.id)
def to_dict(self) -> Dict[str, Optional[str]]:
"""将客户端信息转换为字典"""
return {
'id': self.id,
'addr': self.addr,
'fd': self.fd,
'name': self.name,
'age': self.age,
'idle': self.idle,
'flags': self.flags,
'db': self.db,
'sub': self.sub,
'psub': self.psub,
'multi': self.multi,
'qbuf': self.qbuf,
'qbuf-free': self.qbuf_free,
'obl': self.obl,
'oll': self.oll,
'omem': self.omem,
'events': self.events,
'traffic-control': self.traffic_control,
'cmd': self.cmd,
'type': self.type,
'next_opid': self.next_opid,
'real_addr': self.real_addr
}
def parse_client_line(line: str) -> Optional[RedisClientInfo]:
"""解析单行客户端信息
Args:
line: 单行client_list输出
Returns:
RedisClientInfo实例,如果解析失败则返回None
"""
if not line or not line.strip():
return None
# 分割key=value对
parts = line.strip().split()
client_data = {}
for part in parts:
try:
key, value = part.split('=', 1)
client_data[key] = value
except ValueError:
# 忽略无效的格式
continue
# 确保有id字段才创建实例
if 'id' in client_data:
return RedisClientInfo(**client_data)
return None
def parse_client_list_file(file_path: str) -> Set[RedisClientInfo]:
"""解析client_list文件
Args:
file_path: client_list文件路径
Returns:
RedisClientInfo实例的集合
"""
clients_set = set()
try:
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
client_info = parse_client_line(line)
if client_info:
clients_set.add(client_info)
except FileNotFoundError:
print(f"错误:文件 {file_path} 不存在")
except Exception as e:
print(f"解析文件时出错:{e}")
return clients_set
def get_client_list_input_path() -> str:
"""获取client_list文件的默认路径"""
# 直接使用绝对路径,确保能找到文件
return '/Users/ayuan/Documents/src/PycharmProjects/python/src/main/resources/data/redis/client_list/client_list.cl'
def get_client_list_output_path() -> str:
"""获取client_list文件的默认路径"""
# 直接使用绝对路径,确保能找到文件
return '/Users/ayuan/Documents/src/PycharmProjects/python/output/redis/client_list'
def get_current_host_ip() -> str:
"""获取当前主机的IP地址
Returns:
str: 当前主机的IP地址
"""
try:
# 创建一个UDP socket连接到外部地址,这样可以获取本地出口IP
s = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)
s.connect(('8.8.8.8', 80))
ip = s.getsockname()[0]
s.close()
return ip
except Exception:
# 如果失败,返回127.0.0.1作为默认值
return '127.0.0.1'
def split_by_ip(clients: Set[RedisClientInfo], output_dir: str, exclude_local_ip: bool = True) -> None:
"""按IP地址分割客户端信息到不同的文件
Args:
clients: RedisClientInfo实例的集合
output_dir: 输出目录路径
exclude_local_ip: 是否排除当前主机的IP地址
"""
# 确保输出目录存在
os.makedirs(output_dir, exist_ok=True)
# 获取当前主机IP
local_ip = get_current_host_ip() if exclude_local_ip else None
if exclude_local_ip:
print(f"正在排除当前主机IP: {local_ip}")
# 按IP分组存储原始行数据
ip_data = {}
# 重新读取原始文件,以便保留完整的行数据
file_path = get_client_list_input_path()
try:
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
client_info = parse_client_line(line)
if client_info and client_info.addr:
ip = client_info.addr.split(':')[0] if ':' in client_info.addr else client_info.addr
# 如果需要排除本地IP且当前IP是本地IP,则跳过
if exclude_local_ip and ip == local_ip:
continue
if ip not in ip_data:
ip_data[ip] = []
ip_data[ip].append(line.strip())
except Exception as e:
print(f"读取原始文件时出错:{e}")
return
# 写入按IP分组的文件
for ip, lines in ip_data.items():
# 将IP地址中的点替换为下划线作为文件名
safe_ip = ip.replace('.', '_')
output_file = os.path.join(output_dir, f"client_list_{safe_ip}.cls")
try:
with open(output_file, 'w', encoding='utf-8') as f:
for line in lines:
f.write(line + '\n')
print(f"已写入 {len(lines)} 条记录到 {output_file}")
except Exception as e:
print(f"写入文件 {output_file} 时出错:{e}")
print(f"\n按IP分组完成,共生成 {len(ip_data)} 个文件")
def client_list():
"""主函数,用于演示解析功能"""
file_path = get_client_list_input_path()
print(f"正在解析文件:{file_path}")
clients = parse_client_list_file(file_path)
print(f"成功解析 {len(clients)} 个客户端连接信息")
# 获取当前主机IP
local_ip = get_current_host_ip()
print(f"当前主机IP: {local_ip}")
# 过滤掉本地IP的客户端
non_local_clients = {client for client in clients if client.addr and
(client.addr.split(':')[0] if ':' in client.addr else client.addr) != local_ip}
print(f"过滤后客户端数量: {len(non_local_clients)}")
# 显示前5个非本地客户端信息作为示例
print("\n前5个非本地客户端信息示例:")
for i, client in enumerate(list(non_local_clients)[:5], 1):
print(f"{i}. {client}")
# 统计一些基本信息(仅对非本地客户端)
print("\n基本统计信息(已排除本地IP):")
# 按数据库分组统计
db_count = {}
cmd_count = {}
ip_count = {}
for client in non_local_clients:
# 统计数据库使用情况
if client.db:
db_count[client.db] = db_count.get(client.db, 0) + 1
# 统计命令使用情况
if client.cmd:
cmd_count[client.cmd] = cmd_count.get(client.cmd, 0) + 1
# 统计IP地址使用情况(提取IP部分,忽略端口)
if client.addr:
ip = client.addr.split(':')[0] if ':' in client.addr else client.addr
ip_count[ip] = ip_count.get(ip, 0) + 1
print(f"数据库使用情况:{db_count}")
print(f"最常用的5个命令:{sorted(cmd_count.items(), key=lambda x: x[1], reverse=True)[:5]}")
# 显示按IP分组的统计信息
print("\n按IP地址分组统计(已排除本地IP):")
# 按连接数降序排序并显示
sorted_ips = sorted(ip_count.items(), key=lambda x: x[1], reverse=True)
print(f"共有 {len(sorted_ips)} 个不同的IP地址")
print("前10个IP地址及其连接数:")
for ip, count in sorted_ips[:10]:
print(f" {ip}: {count} 个连接")
# 按IP分割文件(排除本地IP)
print("\n开始按IP地址分割文件(已排除本地IP)...")
output_dir = get_client_list_output_path()
split_by_ip(non_local_clients, output_dir, exclude_local_ip=True)
if __name__ == '__main__':
client_list()client_list.cls
lua
-- 本机IP地址
id=38124222 addr=127.0.0.1:42355 fd=222 name= age=7053385 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=32768 obl=0 oll=0 omem=0 events=r traffic-control=NULL cmd=config type=localhost next_opid=-1 real_addr=
jps 解析
jps_lvm.input
javascript
11828 org.apache.catalina.startup.Bootstrap start -Djava.util.logging.config.file=/home/tomcat/easyhome_workbench/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djdk.tls.ephemeralDHKeySize=2048 -Djava.protocol.handler.pkgs=org.apache.catalina.webresources -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=9191 -javaagent:/home/skywalking-agent/skywalking-agent.jar -Dskywalking.agent.service_name=uat-workbench -Dskywalking.collector.backend_service=10.231.58.172:11800 -Dignore.endorsed.dirs= -Dcatalina.base=/home/tomcat/easyhome_workbench -Dcatalina.home=/home/tomcat/easyhome_workbench -Djava.io.tmpdir=/home/tomcat/easyhome_workbench/tempjps_lvm.py
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
读取jps_lvm.txt文件,将空格替换为换行,并输出到jps_lvm.out文件
Python 3.9 兼容版本
"""
import os
def jps_lvm():
# 源文件和目标文件路径
source_file = '/Users/ayuan/Documents/src/PycharmProjects/python/src/main/resources/data/redis/jps_lvm/jps_lvm.input'
target_file = '/Users/ayuan/Documents/src/PycharmProjects/python/output/redis/jps_lvm/jps_lvm.output'
print(f"读取文件: {source_file}")
try:
# 读取源文件内容
with open(source_file, 'r', encoding='utf-8') as f:
content = f.read().strip()
print("读取到内容长度: {} 字符".format(len(content)))
# 将空格替换为换行
processed_content = content.replace(' ', ' \n')
# 确保目标文件所在的目录存在
os.makedirs(os.path.dirname(target_file), exist_ok=True)
print(f"确保目录存在: {os.path.dirname(target_file)}")
# 写入目标文件
with open(target_file, 'w', encoding='utf-8') as f:
f.write(processed_content)
print("已将处理后的内容写入: {}".format(target_file))
print("处理后内容长度: {} 字符".format(len(processed_content)))
# 验证结果
with open(target_file, 'r', encoding='utf-8') as f:
final_content = f.read()
line_count = final_content.count('\n') + 1
print("验证写入成功,最终文件行数: {}".format(line_count))
except Exception as e:
print("处理出错: {}".format(str(e)))
if __name__ == '__main__':
jps_lvm()jps_lvm.output
ini
11828
org.apache.catalina.startup.Bootstrap
start
-Djava.util.logging.config.file=/home/tomcat/easyhome_workbench/conf/logging.properties
-Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager
-Djdk.tls.ephemeralDHKeySize=2048
-Djava.protocol.handler.pkgs=org.apache.catalina.webresources
-Xdebug
-Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=9191
-javaagent:/home/skywalking-agent/skywalking-agent.jar
-Dskywalking.agent.service_name=uat-workbench
-Dskywalking.collector.backend_service=1x.2xx.5x.1xx:11800
-Dignore.endorsed.dirs=
-Dcatalina.base=/home/tomcat/easyhome_workbench
-Dcatalina.home=/home/tomcat/easyhome_workbench
-Djava.io.tmpdir=/home/tomcat/easyhome_workbench/temp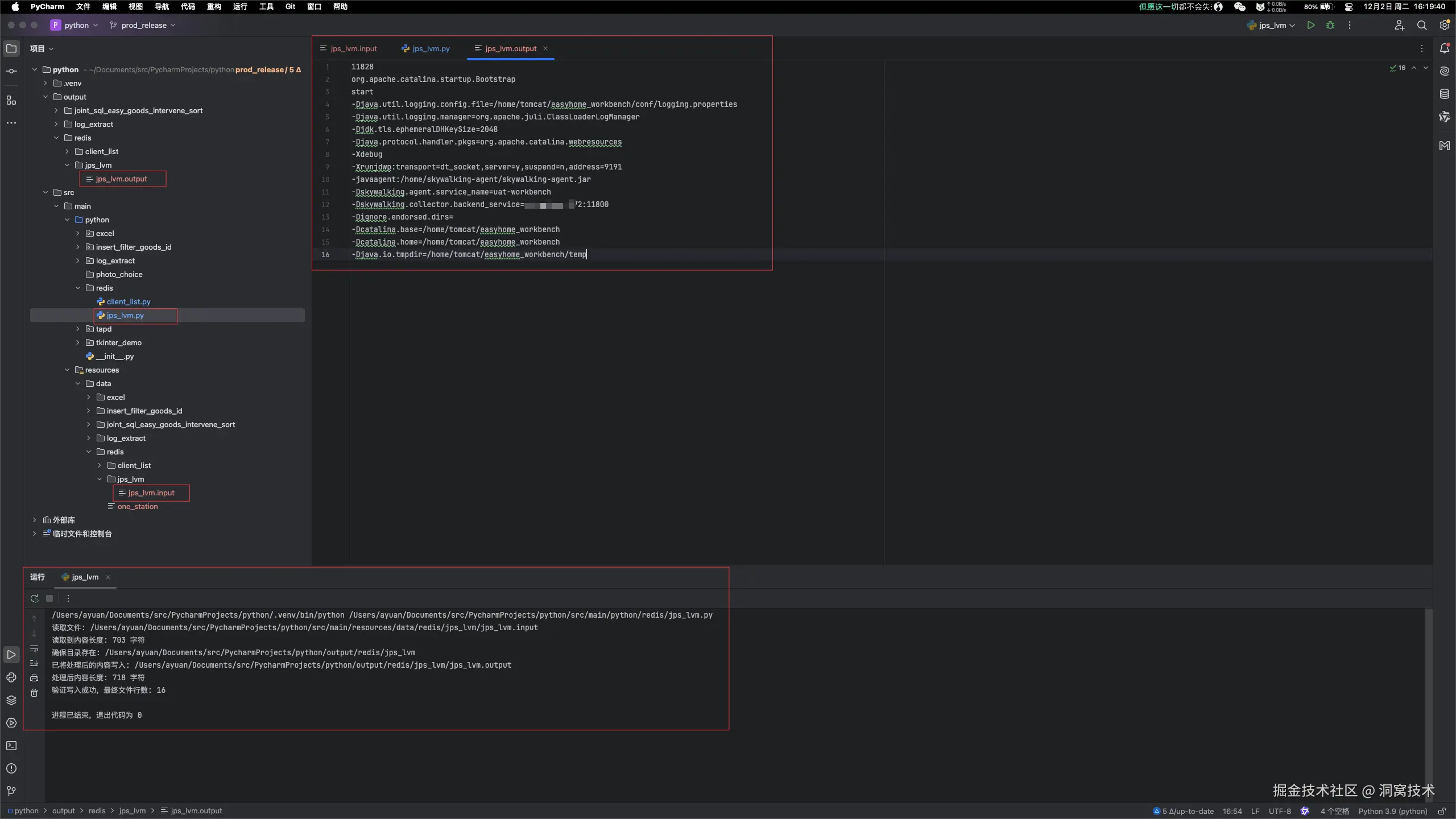
连接池参数
java
// 1. 配置连接池参数
JedisPoolConfig poolConfig = new JedisPoolConfig();
poolConfig.setMaxTotal(20); // 最大连接数(同时与 Redis 建立的连接数)
poolConfig.setMaxIdle(10); // 最大空闲连接数(空闲时保留的连接数)
poolConfig.setMinIdle(5); // 最小空闲连接数(空闲时至少保留的连接数)
poolConfig.setMaxWaitMillis(3000); // 从连接池获取连接的最大等待时间(超时抛异常)
java
public class JedisPoolConfig extends GenericObjectPoolConfig {
public JedisPoolConfig() {
this.setTestWhileIdle(true); // 空闲连接检测(定期检测空闲连接,销毁无效连接),结合 timeBetweenEvictionRunsMillis
this.setMinEvictableIdleTimeMillis(60000L); // 空闲连接最小存活时间:5分钟(空闲超过5分钟的连接会被销毁)
this.setTimeBetweenEvictionRunsMillis(30000L); // 空闲连接检测的间隔时间
this.setNumTestsPerEvictionRun(-1); // 设置每次空闲连接检测时,最多校验的空闲连接数量
}
}作者:洞窝-孟源