原文链接:www.gbase.cn/community/p...
更多精彩内容尽在南大通用GBase技术社区,南大通用致力于成为用户最信赖的数据库产品供应商。
集群在运行过程中偶尔会出现crash,当集群crash时,从哪里查看堆栈信息呢?system.log 中记录了宕机的堆栈信息,core 文件中记录了宕机的详细的堆栈信息,如果想要看到详细的堆栈信息,则需要在集群coor节点以及集群data节点的配置文件中,开启该功能,具体步骤如下:
1、修改集群coor节点配置文件:在每台集群coor节点机器的集群安装目录,如/opt/gcluster/config 路径下,找到配 置文件 gbase_8a_gcluster.cnf,将文件中的 core-file 参数去掉参数前的注释符号"#"。
2、修改集群data节点配置文件:在每台集群节点安装目录,如/opt/gnode/config 路径下,找到配置文件 gbase_8a_gbase.cnf,将文件中的 core-file 参数去掉参数前的注释符号"#"。
3、重启集群每个节点服务:86版本切换到 root 用户,运行 service gcware restart 命令,重新启动集群服务;95版本使用dbauser用户执行gcluster_services all restart重启服务,使上述配置文件的设置生效。
堆栈收集方式
根据进程名的收集方式
javascript
pstack `pidof gbased`|/opt/gcluster/server/bin/stack_uniq.py > gbased_ip_pstack.txt说明:打印去重后的gbased进程堆栈,输出到指定文件中去,其中:
gbased为进程名称,可以是gbased、gclusterd、gcware、gccli等8a的各种进程名称。
/opt/gcluster/server/bin/stack_uniq.py为去重脚本,位置在安装目录下对应gcluster、gnode目录下的server/bin目录中不同版本的路径略有不同。
gbased_ip_pstack.txt为输出路径。
86、95版本:

953多实例版本:

PS:也可以ps获取该进程的id号,直接pstack id获取堆栈,pstack就是gstack的一个软连接
sql卡住时的堆栈收集
在明确卡住sql的情况下,除了直接打印对应的gclusterd,gbased堆栈以外,还可以直接打印该sql的线程id信息:打印方法,先从gc或者gn层show full processlist,获得该sql的Tid,然后执行pstack 来获取卡住sql的现场信息。如下图:
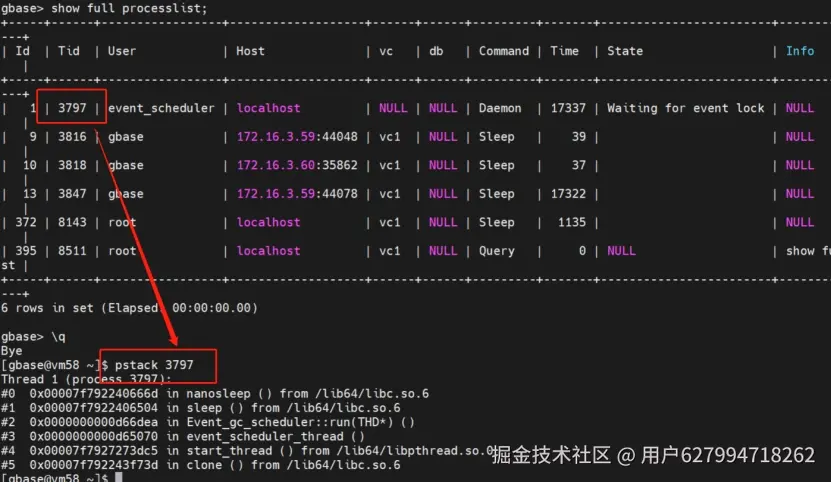
PS:建议卡住sql间隔多打印几次进程堆栈,其中多次存在同样堆栈的方法值得重点怀疑,有助于研发根据不同状态的堆栈分析。
宕机堆栈获取方式
- system.log中获取
宕机后一般会在system日志中获取到对应的堆栈信息,路径为安装路径下对应gcluster/log/glcuster/system.log,gnode/log/gbase/system.log,可以根据宕机发生的时间结合express日志和定时processlist收集的日志,梳理分析宕机时刻业务环境发生的变化。
- dump文件获取方式
解压dump文件 ./xxxx.dump,dump如果无法解压,可以给dump文件增加执行权限即可,展开目录,有如下文件列表。
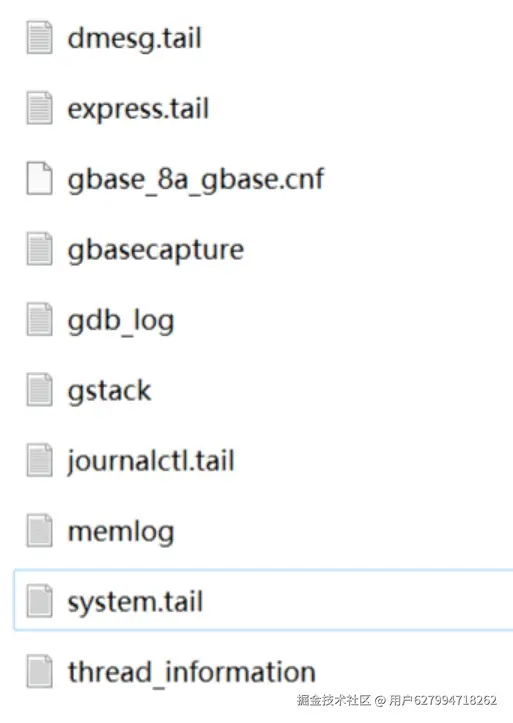
其中system保存有宕机堆栈信息,如果没有记录,可以观察gstack文件中的堆栈信息
- core文件获取堆栈方式
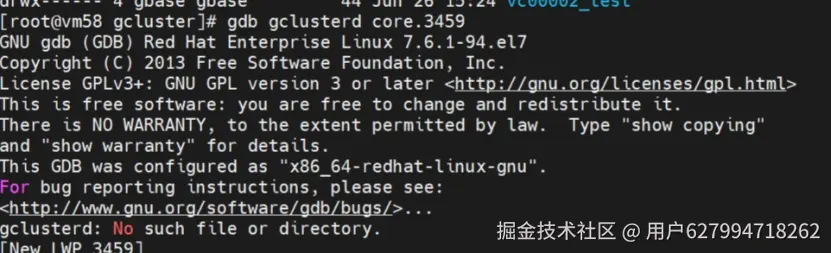
core文件位置在安装目录对应gcluster、gnode目录的userdata目录下

执行如下命令:
gdb gbased corefile执行结果如下:
执行如下命令输出堆栈信息:
shell
>set logging file stack.txt
>set logging on
>t a a bt(堆栈打印完为止)
>set logging off
>q 退出
打开stack.txt,查找segfault
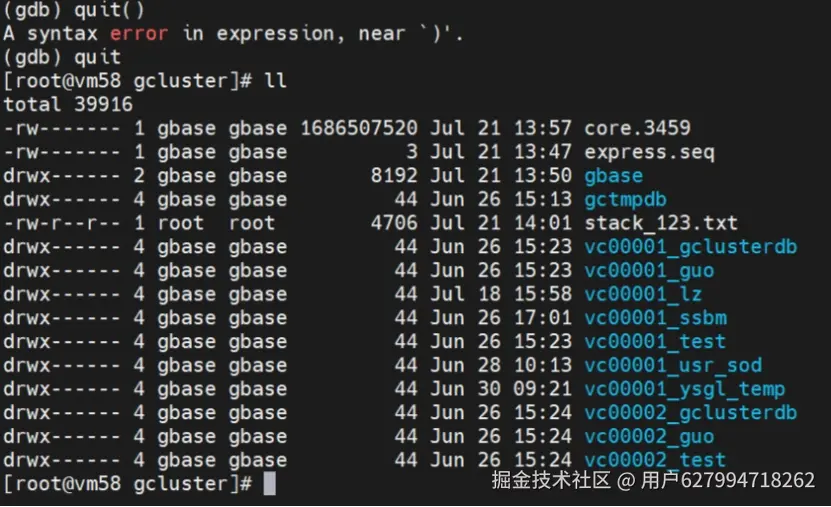
开启和关闭corefile的参数,在对应的gc和gn配置文件下增加 core_file字段就可以开启
PS:core文件较大,可能会增强客户感知,请现场斟酌使用
宕机堆栈信息去重判断
现场对宕机问题的堆栈要进行判断去重,不同的堆栈提交不同的问题反馈单。
判断堆栈是否重复,需要人为梳理堆栈信息中的,进程对应的前几条程序方法调用情况,一般认为不同的方法对应不同的宕机堆栈信息,以下为两个不同的宕机堆栈信息
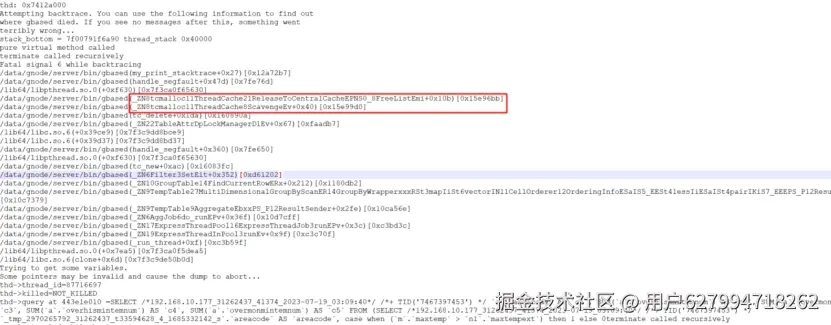
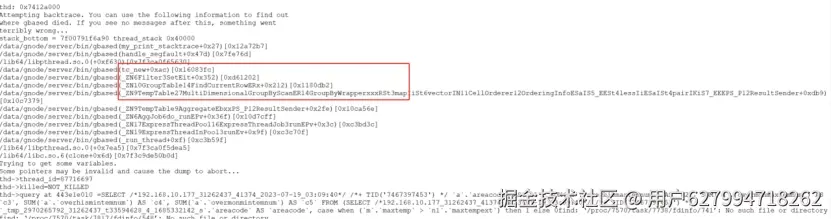
原文链接:www.gbase.cn/community/p...
更多精彩内容尽在南大通用GBase技术社区,南大通用致力于成为用户最信赖的数据库产品供应商。