大模型推理速度慢、跨设备扩展难,一直是边缘-云异构环境下的老问题。最近,来自兰克林与马歇尔学院以及纽约大学的研究团队拿出了一套新方案------DSD(分布式推测解码)框架。实测数据显示,相比现有方法,这套框架实现了 1.1 倍加速和 9.7%的吞吐量提升。
从单机到分布式,推测解码跨出关键一步
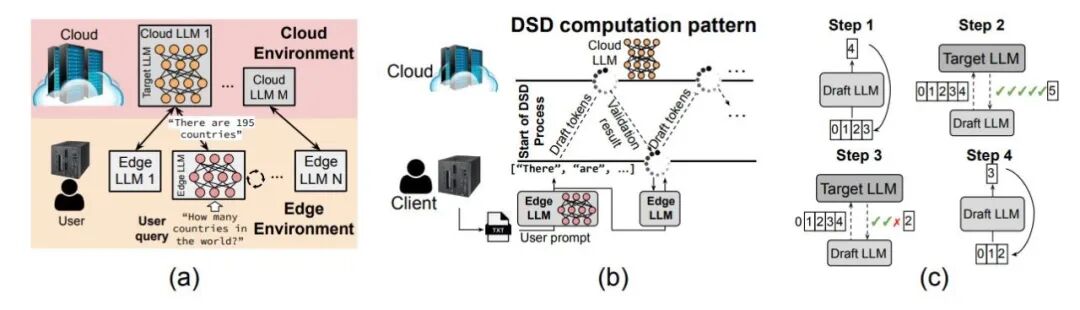
推测解码(Speculative Decoding)本身不算新技术。它的逻辑很直接:用一个轻量级的"草稿模型"先快速生成几个候选 token,再让大模型并行验证。这样能省下不少时间。
但问题在于,传统推测解码局限在单节点运行。一旦涉及边缘设备和云端的协同,网络延迟、批处理调度、设备异构性就都成了拦路虎。
DSD 的思路是把草稿模型放在边缘,目标模型放在云端,通过协调执行来实现跨设备的推测解码。听起来简单,实际操作起来涉及大量的系统级优化。
仿真先行,再做策略调优
团队没有直接上手搭系统,而是先做了一个离散事件仿真器 DSD-Sim。它能精确模拟网络传输、批处理、调度等环节的性能表现。这个工具本身就填补了分布式推测解码仿真的空白。
基于仿真结果,研究者进一步设计了 AWC(自适应窗口控制)策略。它能根据实时系统状态动态调整"推测窗口"大小,在吞吐量和稳定性之间找到平衡点。
实验覆盖了多种工作负载场景。结果显示,DSD 在加速比和吞吐量上都优于现有的单节点推测解码基线。这意味着边缘-云协同推理不再是"理论上可行",而是有了可落地的技术路径。
对产业意味着什么?
大模型落地,算力是一道门槛,延迟是另一道。尤其在边缘场景,用户对响应速度的容忍度更低。
DSD 的价值在于,它把推测解码从单机环境扩展到了分布式场景。这为边缘 AI 应用打开了新的可能性:手机、IoT 设备可以跑轻量模型做初筛,云端大模型负责精校,两者配合把推理速度拉上来。
从技术架构看,DSD 属于"端-边-云协同计算"的一个典型案例。它不是简单地把计算任务切分,而是通过推测机制把网络延迟转化为计算增益。这种思路对 6G 时代的算力网络也有借鉴意义。
值得注意的是,这项研究还配套了一个仿真工具。这对工业界来说很实用。企业在部署分布式推理系统之前,可以先用仿真器跑一遍,评估不同配置下的性能表现,避免盲目试错。
实验数据与技术细节
研究团队在 DSD-Sim 中引入了基于 VIDUR 的硬件性能建模引擎,能够准确预测不同 GPU 架构下的推理延迟。测试涵盖了 NVIDIA A40 等边缘导向硬件,以及 Qwen-7B 等轻量化模型。
在吞吐量测试中,DSD 相比传统方法提升了 9.7%。加速比达到 1.1 倍。这个数字看起来不算惊艳,但考虑到分布式环境下的通信开销和调度复杂度,这已经是不小的进步。
AWC 策略的设计也值得一提。它采用深度学习方法,根据实时的系统状态和算法条件动态调整推测窗口大小。在不同网络环境和工作负载下,系统都能保持较优性能。
行业趋势:边缘 AI 进入协同计算时代
从技术演进看,边缘 AI 正在经历从"独立推理"到"协同推理"的转变。
早期的边缘 AI 强调"端侧自主",模型要足够小,能在设备上独立运行。但随着应用复杂度提升,单纯的轻量化模型已经难以满足精度要求。
现在的方向是"能力协同"。边缘设备保留必要的感知和初筛能力,复杂决策交给云端。关键是如何优化中间的协同机制,让数据传输、任务调度、模型协作更高效。
DSD 正是在这个方向上的一次尝试。它没有去改模型结构,而是在系统层面做文章。通过推测解码机制,把本该浪费在等待上的时间用来做预判,进而提升整体效率。
类似的思路也出现在其他研究中。比如有团队提出用"不确定性感知"机制减少上行传输,有团队探索"Top-K 压缩"降低通信开销。这些工作共同指向一个目标:让边缘-云协同更流畅。
往前看,随着 6G 网络的推进和边缘算力的提升,分布式推理会成为常态。但技术挑战依然不少:如何处理更复杂的网络拓扑? 如何应对设备的动态加入和退出? 如何在保证精度的同时进一步降低延迟?
这些问题,都需要更多像 DSD 这样的系统级创新来回答。
参考材料:
-
DSD 论文原文:https://arxiv.org/abs/2511.21669
-
去中心化推测解码研究:https://arxiv.org/abs/2511.11733
2025-12-01

2025-11-24

谷歌正式跟进苹果PCC,华为OPPO同步入局:边缘AI隐私战打响
2025-11-22
