概述
在语音转文本ASR工具合集介绍ASR基础概念,汇总几款语音识别模型和项目,其中就包括OpenAI开源的Whisper。OpenAI Whisper则是技术原理和实战。
围绕Whisper有着非常庞大的生态,本文试图介绍几个,不够深入。
whisper.cpp
Whisper模型的开源(GitHub,44.5K Star,4.9K Fork)C++实现版本,核心优势:
- 几乎无依赖:最大亮点,不同于其他需通过
pip安装一大堆Python库的项目,whisper.cpp几乎没有依赖; - 性能卓越:C++原生性能优势,转录速度非常快,资源占用也相对较低;
- 跨平台与硬件支持:支持多种硬件加速,从主流的NVIDIA(CUDA)、AMD(OpenCL)显卡,到苹果的Metal框架,甚至是专用NPU,都能利用起来进一步提速;
- 部署简单:可以直接下载官方编译好的可执行文件,解压即用,整个程序包非常小巧。
实战
| 模型名称 | 文件大小 | 推荐场景 |
|---|---|---|
ggml-small.bin |
~488MB | 电脑配置较低,对速度要求高,能接受少量错误 |
ggml-medium.bin |
~1.5GB | 平衡之选 |
ggml-large-v2.bin |
~3.0GB | 追求高准确率,电脑配置较好 |
ggml-large-v3.bin |
~3.1GB | 最高准确率,目前效果最好的模型,推荐给追求极致效果的用户 |
ggml-large-v3-turbo.bin |
~1.6GB | large-v3的优化版本,速度比v2/v3更快,准确率相差不大,适合大多数用户 |
whisper.cpp本身只处理标准格式.wav`文件,对于mp3、m4a、mp4、mkv等格式,直接处理可能会报错或得到空白结果。可使用FFmpeg预先转换
Faster-Whisper
开源(GitHub,19.3K Star,1.6K Fork),使用CTranslate2技术。
没有提供图形用户界面GUI,也没提供命令行接口,只能作为一个Python库被调用。
模型:
- tiny.en
- tiny
- base.en
- base
- small.en
- small
- medium.en
- medium
- large-v1
- large-v2
- large-v3
- distil-large-v2
- distil-medium.en
- distil-small.en
- distil-large-v3
- large-v3-turbo
- turbo
实战
安装:pip install faster-whisper
实例:
py
from faster_whisper import WhisperModel
# GPU + FP16
model = WhisperModel("medium", device="cuda", compute_type="float16")
# GPU + INT8
model = WhisperModel("large-v2", device="cuda", compute_type="int8_float16")
model = WhisperModel("large-v3", device="cpu", compute_type="int8")
segments, info = model.transcribe("audio.mp3", beam_size=5, language="en", condition_on_previous_text=False)
print("Detected language '%s' with probability %f" % (info.language, info.language_probability))
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))以及:
py
from faster_whisper import WhisperModel, BatchedInferencePipeline
model = WhisperModel("turbo", device="cuda", compute_type="float16")
batched_model = BatchedInferencePipeline(model=model)
segments, info = batched_model.transcribe("audio.mp3", batch_size=16)
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))WhisperX
论文,开源(GitHub,19K Star,2K Fork)支持词级时间戳(及分词)的说话人分离的ASR工具。
后端基于:Faster-Whisper和CTranslate2。
只有命令行工具,没提供API。
py
实战
安装:pip install whisperx或基于nv安装:uvx whisperx
Whisper
开源(GitHub,9.9K Star,895 Fork)whisper.cpp的Windows实现版,基于C++/C后端,C#界面。
WhisperLiveKit
开源(GitHub,8.9K Star,866 Fork)。
架构
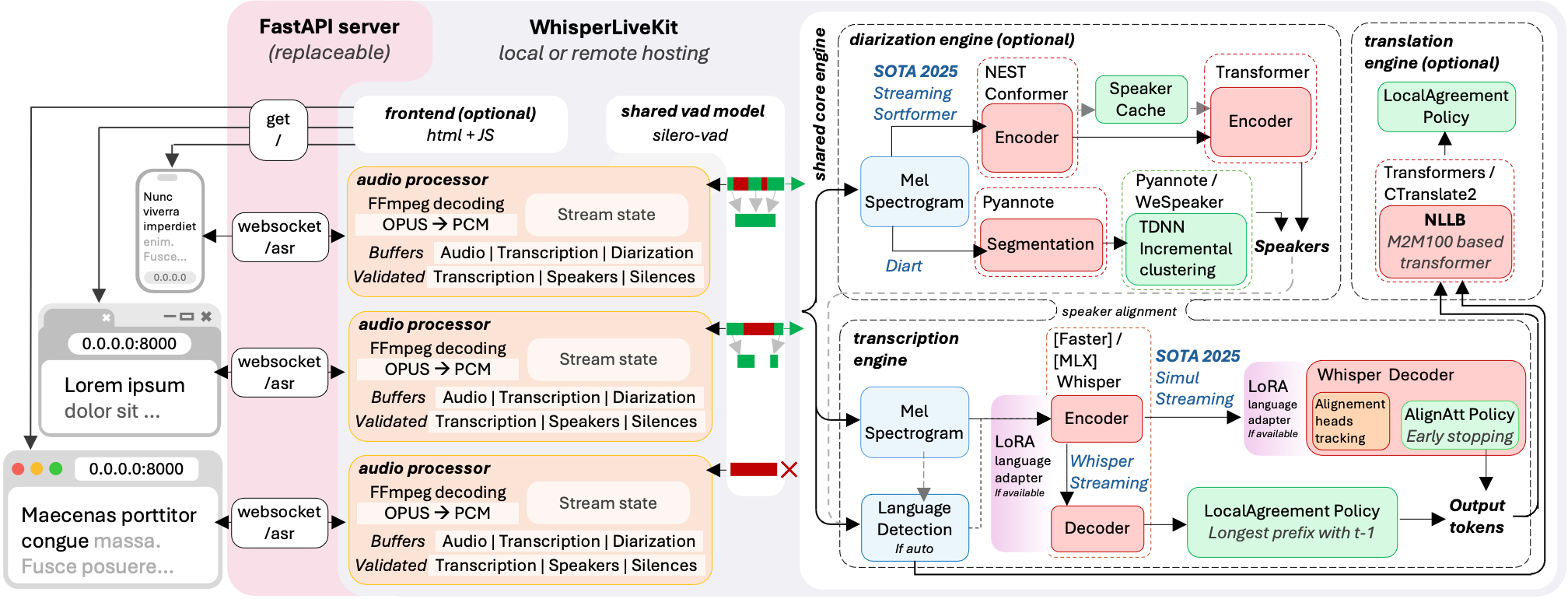
安装:pip install whisperlivekit
Python SDK集成:
py
import asyncio
from contextlib import asynccontextmanager
from fastapi import FastAPI, WebSocket, WebSocketDisconnect
from fastapi.responses import HTMLResponse
from whisperlivekit import AudioProcessor, TranscriptionEngine, parse_args
transcription_engine = None
@asynccontextmanager
async def lifespan(app: FastAPI):
global transcription_engine
transcription_engine = TranscriptionEngine(model="medium", diarization=True, lan="en")
yield
app = FastAPI(lifespan=lifespan)
async def handle_websocket_results(websocket: WebSocket, results_generator):
async for response in results_generator:
await websocket.send_json(response)
await websocket.send_json({"type": "ready_to_stop"})
@app.websocket("/asr")
async def websocket_endpoint(websocket: WebSocket):
global transcription_engine
# Create a new AudioProcessor for each connection, passing the shared engine
audio_processor = AudioProcessor(transcription_engine=transcription_engine)
results_generator = await audio_processor.create_tasks()
results_task = asyncio.create_task(handle_websocket_results(websocket, results_generator))
await websocket.accept()
while True:
message = await websocket.receive_bytes()
await audio_processor.process_audio(message) Whisper-Diarization
开源(GitHub,3.6K Star,496 Fork)
WhisperLive
开源(GitHub,3.6K Star,496 Fork)
Faster-Whisper-GUI
开源(GitHub,2.8K Star,164 Fork)。
适用于Faster-Whisper、WhisperX的GUI程序。
参数:
- 转写参数
audio:输入文件的路径,或类似文件的对象,或音频波形;language:音频语言,如en。如果未设置,则在音频前30秒内检测语言;task:要执行的任务,转录或翻译;beam_size:用于解码的beam大小;best_of:采样时使用非零温度的候选数;patience:Beam搜索耐心因子;length_penalty:指数长度惩罚常数;temperature:采样温度,可以是温度元组,如果根据compression_ratio_threshold或log_prob_threshold失败,则会依次使用;compression_ratio_threshold:如果gzip压缩比高于此值,则视为失败;log_prob_threshold:如果对采样标记的平均对数概率低于此值,则视为失败;no_speech_threshold:如果无话音概率高于此值,并且对采样标记的平均对数概率低于log_prob_threshold,则将该段视为静音;condition_on_previous_text:如果为True,则将模型的前一个输出作为下一个窗口的提示提供;禁用可能会导致文本在窗口之间不一致,但模型不太容易陷入失败循环,比如重复循环或时间戳失去同步;initial_prompt:为第一个窗口提供的可选文本字符串或词元id可迭代项;prefix:为第一个窗口提供的可选文本前缀;suppress_blank:在采样开始时抑制空白输出;suppress_tokens:要抑制的标记ID列表。-1将抑制配置文件config.json中定义的默认符号集;without_timestamps:仅对文本标记进行采样;max_initial_timestamp:初始时间戳不能晚于此时间;word_timestamps:使用交叉注意力模式和动态时间规整提取单词级时间戳,并在每个段的每个单词中包含时间戳;prepend_punctuations:如果word_timestamps为True,则将这些标点符号与下一个单词合并;append_punctuations:如果word_timestamps为True,则将这些标点符号与前一个单词合并;vad_filter:启用语音活动检测(VAD)以过滤掉没有语音的音频部分,使用Silero VAD模型;vad_parameters:Silero VAD参数字典或VadOptions类;max_new_tokens:每个区块生成的新令牌的最大数量。未设置,最大值将通过默认max_size设置;chunk_length:音频段的长度。如果不是None,将覆盖FeatureExtractor的默认chunk_size;clip_timestamps:逗号分隔的要处理的剪辑的时间戳列表(以秒为单位)开始,结束,开始,结束......。最后一个结束时间戳默认为文件的结束。如果使用clip_timestamps,将忽略VAD设置;hallucination_silence_threshold:当word_timestamps为True时,当检测到可能的幻觉时,跳过长于此阈值(以秒为单位)的静默期;hotwords:为模型提供的热词/提示短语。如果prefix不是None,则无效;language_detection_threshold:如果语言标记的最大概率高于此值,则会检测为该语言;language_detection_segments:语言检测需要考虑的分段数量。
- VAD参数
threshold:语音阈值。Silero VAD为每个音频块输出语音概率,概率高于此值的认为是语音。最好对每个数据集单独调整此参数,0.5对大多数数据集来说都非常好;min_speech_duration_ms:短于min_speech_duration_ms的最终语音块会被抛弃;max_speech_duration_s:语音块的最大持续时间(秒)。比max_speech_duration_s更长的块将在最后一个持续时间超过100ms的静音时间戳拆分(如果有的话),以防止过度切割。否则,它们将在max_speech_duration_s之前强制拆分;min_silence_duration_ms:在每个语音块结束时等待min_silence_duration_ms再拆分它;window_size_samples:window_size_samples大小的音频块被馈送到Silero VAD模型。Silero VAD模型使用16000采样率训练得到512,1024、1536样本,其他值可能会影响模型性能;speech_pad_ms:最终的语音块每边都由speech_pad_ms填充。
- 模型参数
model_size_or_path:使用的模型大小(tiny,tiny.en,base,base.en,small,small.en,medium, medium.en,large-v1或large-v2),转换后的模型目录路径,或来自HuggingFace的CTranslate2转换的Whisper模型ID。当配置了大小或模型ID时,转换后的模型将从HuggingFace下载。device:转写设备("cpu","cuda","auto")。device_index:要使用的设备ID。也可以通过传递ID列表(如[0,1,2])在多GPU上加载模型。在这种情况下,当从多个Python线程调用transcribe()时,可以并行运行多个转录;compute_type:计算类型。请参阅https://opennmt.net/CTranslate2/quantization.html。cpu_threads:在CPU上运行时使用的线程数(默认为4)。非零值会覆盖OMP_NUM_THREADS环境变量。num_workers:当从多个Python线程调用transcribe()时,具有多个工作线程可以在运行模型时实现真正的并行性(对self.model.generate()的并发调用将并行运行)。可以以增加内存使用为代价提高整体吞吐量。download_root:模型应该保存的目录。如果未设置,则模型将保存在标准HuggingFace缓存目录中。local_files_only:如果为True,避免下载文件,并在本地缓存的文件存在时返回其路径。
whisper-timestamped
开源(GitHub,2.7K Star,201 Fork)
whisper-ctranslate2
开源(GitHub,1.2K Star,116 Fork)基于CTranslate2兼容OpenAI的命令行客户端。
stable-ts
开源(GitHub,2.1K Star,223 Fork)基于Whisper进行转录、强制对齐和音频索引。
echogarden
开源(GitHub,420 Star,43 Fork)
CarelessWhisper
哈哈哈:George Michael有同名歌曲。
这些年,ASR模型依托于Transformer架构发展特别快,主要分三类:只用编码器的、只用解码器的、编码器-解码器全用,Whisper属于第三种。
问题:Whisper编码器是非因果的,得输入全部语音才能输出表示,没法实时转录。试图实现流式Whisper的实践举例:
- Simul-Whisper:不微调,靠对齐头判断啥时候输出Token,但每次都要把输入补到30秒,计算效率差;
- UfalWhisper:不微调,靠音频缓冲区和局部一致算法,但同样要补全输入,效率低;
- U2-Whisper:微调编码器加个CTC头,推理要走两趟(先CTC预测,再解码器排序),麻烦;
- WhisperFlow:让Whisper检测每个分块末尾的静音词,但要改架构。
流式ASR的几种方向:
- RNN-T:循环神经网络转换器,最经典的流式架构,用LSTM或双向RNN,天生因果(只能看过去的语音),适合实时。比如有人用知识蒸馏把离线模型的知识传给RNN-T,还有人优化它适配移动端,但RNN的并行性差,大模型效率不高。
- Transformer Transducer:把RNN-T里的循环组件换成Transformer编码器,兼顾并行和流式。比如混合编码器(一个因果掩码,一个没有),或基于分块注意力,但这些方法要么架构复杂,要么适配预训练模型麻烦。
- 直接用Transformer做流式:如Emformer(增强版内存Transformer)、SpeechLLM(把音频和文本嵌入喂给LLM解码器),还有微调自监督语音模型(S3M)改流式,但这些大多不是针对Whisper设计,适配起来要大改。
- 改Whisper做流式的前人方法:就是引言里提到的那几个,要么不微调但效率低(补全输入),要么要加额外参数、改架构(比如加CTC头),总之都有短板。
Whisper的基本工作方式:
- 输入是log-mel谱,先过几层CNN压缩时间维度,得到序列 X T = ( x 1 , ... , x T ) XT=(x_1,...,x_T) XT=(x1,...,xT),其中 T T T是帧数;
- 编码器把 X T X_T XT转换成表示序列 Z T = ( z 1 , ... , z T ) Z_T=(z_1,...,z_T) ZT=(z1,...,zT),其中 z t z_t zt是 d d d维向量;
- 解码器自回归预测:给定之前的 t o k e n ( y ^ ) token(ŷ) token(y^)和 Z T ZT ZT,输出下一个 t o k e n ( y ^ i ) token(ŷi) token(y^i)的概率 P ( y ^ i ∣ y ^ , Z T ) P(ŷ_i|ŷ,Z_T) P(y^i∣y^,ZT),贪心解码就是选概率最大Token。
流式场景的关键区别是分块处理:不是等全部语音来,而是每次处理一个分块chunk。比如第 k k k个分块是 X ( ( k − 1 ) τ + 1 ) k τ X((k-1)τ+1)^{kτ} X((k−1)τ+1)kτ,其中 τ τ τ是分块大小,单位是帧数,对应几十毫秒的语音)。流式编码器处理这个分块,输出的表示是 Z ^ ( ( k − 1 ) τ + 1 ) k τ Ẑ((k-1)τ+1)^{kτ} Z^((k−1)τ+1)kτ,这个 Z ^ Ẑ Z^和离线编码器处理全序列得到的 Z Z Z的对应部分不一样。
核心目标:微调后的流式编码器+解码器,使词错误率(WER)尽可能接近离线Whisper的WER,同时延迟低(分块小)、计算快。
核心创新集中在:流式编码器、流式解码器、推理机制、词级时间戳
流式编码器:加个因果掩码,让模型只看过去
普通Whisper编码器是非因果的,每个帧都能看到所有帧(包括未来的),这在流式里肯定不行。解决办法是给编码器的自注意力加一个因果掩码矩阵M,让每个帧只能看自己和之前的帧。
- 元素是0:不屏蔽,能看;
- 元素是 − ∞ -∞ −∞:屏蔽,看不到;
- 分初始分块 τ 0 τ_0 τ0和后续分块 τ τ τ:初始分块(比如600毫秒)内所有帧可以互看(要先攒点语音保证准确性),后续分块(比如300毫秒)里,第 i i i帧只能看和它同属一个分块或更早分块的帧。
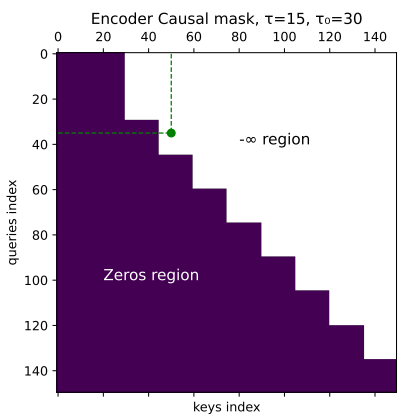
举个例子(图1):τ=15帧(对应300毫秒,因为每帧20毫秒),τ₀=30帧(600毫秒),处理第10个分块时,帧35只能看帧23(同属第3个分块),但看不到帧50(第4个分块,未来的)。
证明关键定理:加掩码后,分块处理到第 k k k个分块得到的前 k τ kτ kτ帧表示,和一次性处理全序列得到的前 k τ kτ kτ帧表示完全一样。保证流式处理的准确性不会因为分块而下降,而且不用每次都重算所有历史帧,只算新分块就行,效率大大提高。
流式解码器:带缓存的注意力,处理动态输入
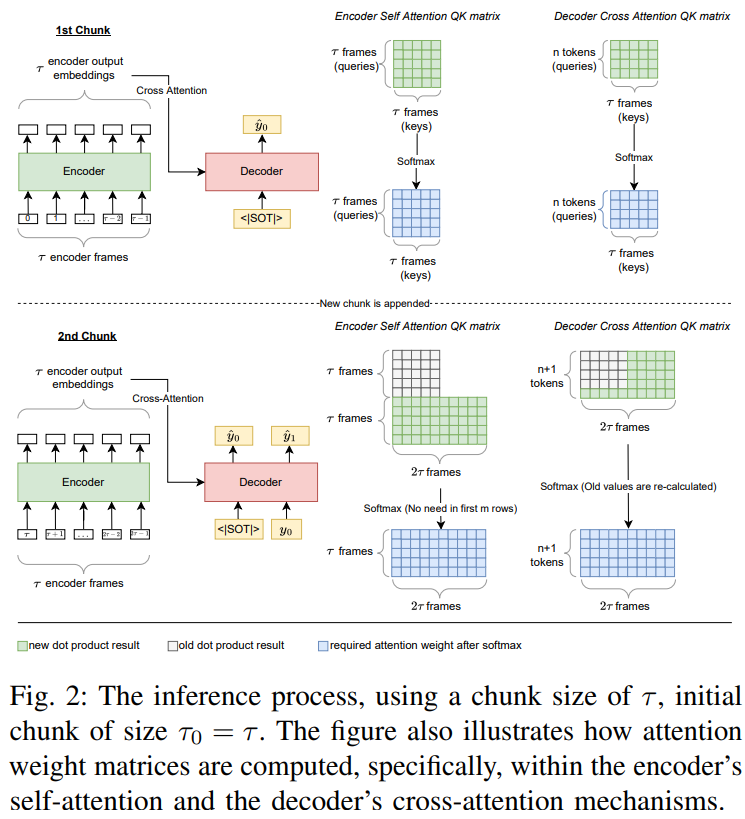
解码器要做两件事:一是记住之前的语音表示(缓存),二是自回归预测Token。
关键是注意力机制的缓存策略:
- 交叉注意力(看编码器输出):新分块的K和V算出来后缓存,下次用的时候直接和新的Q算,不用重算历史K/V;
- 自注意力(看之前Token):没法直接缓存,因为新语音会改变解码器的上下文,导致Token的嵌入变化,之前的自注意力结果就不准。作者的分析:很多Whisper的交叉注意力头不是时间对齐的,新语音会让交叉注意力输出变,进而影响自注意力,所以自注意力缓存暂时不可行。
推理机制:判断稳定Token,避免反复改结果
流式转录的痛点是分块可能切在词中间,比如apple的ap在这个分块,ple在下个分块,直接输出ap肯定错。解决办法是定义稳定Token,只输出稳定Token,不稳定的就等下一个分块再确认。
贪心解码的稳定Token
满足以下任一条件,Token在第 k k k个分块可以被认为是稳定的:
- 在第 k k k个分块的概率≥第 k − 1 k-1 k−1个分块的概率(概率上升,说明更确定);
- 还是第 k k k个分块里概率最大的Token(即使概率降了,但还是最可能的)。
解码时,如果发现最后 n n n个Token里有不稳定的,就回到第一个不稳定的位置重新算,把后面Token删掉。可以证明这个贪心解码是局部最优,比普通贪心解码的概率路径更高。
BeamSearch解码的稳定Token
BeamSearch会同时保留top-b个候选序列( b b b是束大小),稳定Token:这个Token在当前分块的top-b候选里。
停止准则:如果某个候选序列出现结束符(EOT),不马上输出,等下一个分块再确认------避免因为分块切在词中间导致提前结束,减少幻觉(比如重复词)。
词级时间戳:微调的意外收获
因为微调时使用弱对齐数据集(靠强制对齐把语音和文本对应起来),模型的Token和声学特征对齐得更好,顺带解决实时词级时间戳的问题。

具体方法:只要模型预测出一个新的非EOT Token,就把当前分块的时间戳记给这个词;下一个词的开始时间,就是上一个词的结束时间。这个方法只在小分块(40毫秒或100毫秒)下有效,大分块可能包含多个词,边界就不准确。
KV缓存和因果掩码带来的复杂度降低:
- 编码器KV缓存:普通非因果编码器每次处理新分块,都要重算所有历史帧的自注意力,复杂度 O ( T 2 d ) O(T²d) O(T2d);加因果掩码后,历史帧的K和V可以缓存,新分块只算自己的K/V,再和历史缓存结合,复杂度从二次降到线性 O ( T d ) O(Td) O(Td);
- 复杂度定理:作者的方法处理全长为T的序列,计算量是 O ( T 2 d + T d 2 ) O(T^2d + Td^2) O(T2d+Td2);之前方法(如Simul-Whisper)因为要补全输入,计算量是 O ( T 3 d / τ + T 2 d 2 / τ ) O(T^3d/τ + T^2d^2/τ) O(T3d/τ+T2d2/τ),分块越小 τ τ τ越小,差距越大,比如 τ τ τ=40毫秒时,比Simul-Whisper快好几个量级。
- 解码器效率:交叉注意力用缓存,不用重算历史;自注意力虽然不能缓存,但因为分块小,计算量也不大。
微调目标:
- 让编码器学会因果表示;
- 让解码器知道什么时候输出Token。
具体步骤如下:
- LoRA层插入:只在关键地方加LoRA(不训整个模型,轻量)------编码器的自注意力层、解码器的自注意力层、解码器的交叉注意力层。LoRA的秩(rank)根据模型大小调:base/small模型用32,large-v2用4(避免过拟合)。
- 数据集处理:用弱对齐数据集,先通过强制对齐把语音和文本对应起来(知道每个Token的开始/结束时间),然后采样一部分时间点来训(不用每个时间点都训,效率高)。比如每个分块大小τ对应一组时间点,采样其中的f%(f是采样率,比如0.02~0.25)来计算交叉熵损失。
- 训练参数:优化器用AdamW,学习率1e-5,权重衰减0.01,学习率调度用ReduceLROnPlateau(效果不好就降半,耐心2个epoch)。batch size根据模型大小调:base用32,small用16,large-v2用4(显存限制)。
贡献
- 首次用LoRA微调把Whisper改成纯流式模型,不用加额外头(如CTC),不用多阶段解码,轻量高效;
- 提出因果掩码和稳定Token推理机制,保证低延迟(分块≥40毫秒),WER接近离线Whisper;
- 顺带解决词级时间戳问题,小分块下精度比Canary高;
- 复杂度分析和实验证明,效率比现有流式Whisper方法高3~4倍。
局限
- 每个分块大小要单独训一个模型,不能动态调整分块;
- 解码器自注意力还没法用KV缓存,大模型推理时还有优化空间;
- 多语言泛化性不如Ufal-Whisper,因为微调数据不够。
未来方向
- 随机掩码,让一个模型支持多种分块大小;
- 优化解码器自注意力缓存,比如让交叉注意力头更时间对齐,减少动态嵌入的影响;
- 用更多多语言数据微调,提升多语言泛化性。