Transcript-Cut-Tool 技术总结文档
一、工具技术介绍
1.1 开发语言
- Python 3.10
选择 Python 3.10 的原因:
faster-whisperctranslate2ffmpeg-pythontkinter
均对 Python 3.10 支持稳定,而 Python 3.13 暂未被 PyTorch / Whisper 生态完整支持。
1.2 核心技术组件
| 组件 | 作用 |
|---|---|
| Tkinter | GUI 图形界面 |
| faster-whisper | 高性能 Whisper 推理 |
| CTranslate2 | Whisper GPU 推理引擎 |
| FFmpeg | 视频剪辑 / 音频处理 |
| silencedetect | 静音检测 |
| Python subprocess / multiprocessing | 子进程隔离 GPU 推理 |
| CUDA | GPU 加速 |
| NVIDIA RTX 4050 | GPU 推理设备 |
1.3 推理框架说明
Whisper 推理架构
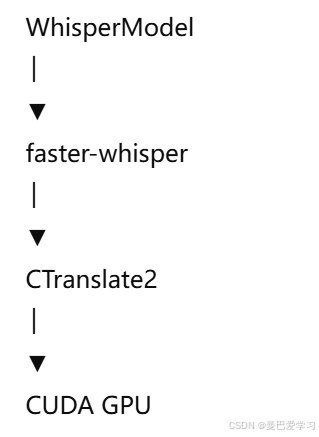
说明:
-
faster-whisper
- Whisper 推理实现
- 基于 CTranslate2
- 推理速度比 OpenAI Whisper 快 4~10 倍
-
CTranslate2
- 推理框架
- 类似 TensorRT
- 专门用于 Transformer 推理
- 支持:
- GPU
- CPU
- INT8 / FP16
1.4 CUDA 环境
硬件:
GPU: NVIDIA GeForce RTX 4050 Laptop GPU
Driver Version: 566.24
CUDA Version: 12.7
安装组件:
CUDA Toolkit 12.x
cuBLAS
cuDNN
环境变量:(安装时自动添加)
CUDA_PATH
PATH += CUDA/bin
PATH += CUDA/libnvvp
二、工具能力介绍
2.1 自动字幕识别
支持:
- MP4
- MOV
- MKV
- 音频文件
通过 Whisper 模型识别字幕:
Whisper large-v3 / medium / small
输出:
start_time end_time text
示例:
12.35 14.22 人体有五脏六腑
14.22 16.10 心肝脾肺肾
2.2 GPU 加速识别
支持:
device="cuda"
compute_type="int8_float16"
核心代码:
model = WhisperModel(model_size, device=device, compute_type=compute_type)
segments, info = model.transcribe(
input_path,
language=language,
beam_size=5, # 提高准确率
best_of=5,
vad_filter=True, # 开启语音分段,将有声音的部分喂给模型
vad_parameters=dict(
min_silence_duration_ms=700, # 多少毫秒连续静音,才被认为"真的静音"
speech_pad_ms=200 # 在检测到有声音时,前后多保留多少毫秒,防止字头字尾被截断,出现断裂感觉
),
word_timestamps=is_word, # 开启字级时间戳,解决精细删除某句话中的单个字
condition_on_previous_text=False,
temperature=0.2, # 改为 0.2
no_repeat_ngram_size=3 # 防重复
)性能:
| 模型 | CPU | GPU |
|---|---|---|
| medium | 10-15 min | 1 min |
| large-v3 | 20 min | 2 min |
2.3 静音检测
使用:ffmpeg silencedetect
作用:
-
自动识别静音区间
-
合并讲话段落
cmd = [
ffmpeg_exe,
"-i", input_media,
"-af", f"silencedetect=noise={noise_db}:d={min_duration}",
"-f", "null", "-"
]
2.4 视频自动剪辑
剪辑逻辑:

核心代码:
# 2. FFmpeg 命令
cmd = [
ffmpeg_exe,
"-y",
"-i", input_media,
"-filter_complex_script", script_path,
"-map", "[outv]",
"-map", "[outa]",
"-c:v", "libx264",
"-preset", "medium",
"-crf", "18",
"-pix_fmt", "yuv420p",
"-c:a", "aac",
"-movflags", "+faststart",
out_path
]
else:
cmd = [
ffmpeg_exe,
"-y",
"-i", input_media,
"-filter_complex", filter_complex,
"-map", "[outv]",
"-map", "[outa]",
"-c:v", "libx264",
"-preset", "medium",
"-crf", "18",
"-pix_fmt", "yuv420p",
"-c:a", "aac",
"-movflags", "+faststart",
out_path
]最终生成final.mp4
2.5 精细化字幕编辑
用户可以:
- 删除字幕
- 修改字幕
- 调整时间
再执行:重新裁剪视频
2.6 防止视频卡顿
改进裁剪方式:
-filter_complex
concat
避免:
-copyts
-seek
新增参数:
-pix_fmt yuv420p
-c:a aac
-movflags +faststart
作用:
| 参数 | 作用 |
|---|---|
| yuv420p | 兼容播放器 |
| aac | 音频重新编码 |
| faststart | 视频流优化 |
三、工具使用方式
3.1 启动 GUI
运行:
bash
#!/usr/bin/env bash
# 示例:一键运行 GUI(需要已安装 Python 及依赖)
python3 gui.pywindows一键启动:
run.bat
界面包含:
- 选择视频
- 转录字幕
- 过滤字幕
- 裁剪导出
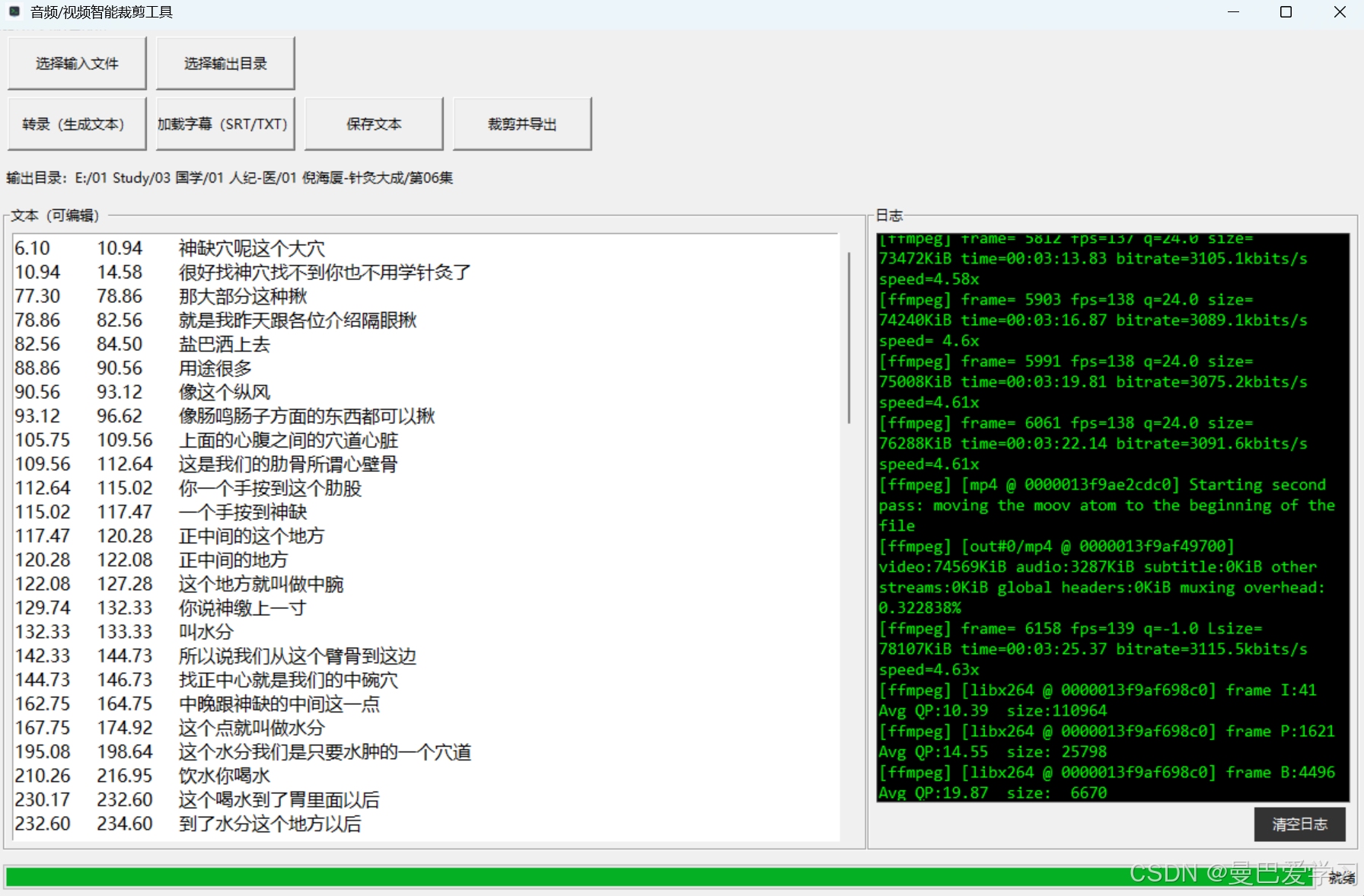
3.2 转录字幕
点击:转录(生成文本)
流程:

3.3 编辑字幕
格式:
start end text
用户可以:
- 删除错误字幕
- 调整时间
3.4 静音过滤
执行:过滤静音
逻辑:
- 识别静音
- 删除无效片段
3.5 导出视频
点击: 裁剪并导出
执行:FFmpeg
输出:final.mp4
四、开发过程中遇到的问题及解决方案
4.1 Python 3.13 不支持 PyTorch
问题:
pip install torch
No matching distribution
原因:
PyTorch 未支持 Python 3.13
解决:
使用 Python 3.10
4.2 CUDA 不可用
问题:
torch.cuda.is_available() = False
原因:
安装 CPU 版 torch
解决:
pip install torch --index-url https://download.pytorch.org/whl/cu121
4.3 Tkinter init.tcl 错误
错误:
Can't find init.tcl
原因:
Python 环境冲突
解决:
重新配置环境变量:
PYTHONUNBUFFERED=1;
TCL_LIBRARY=D:\Python31011\tcl\tcl8.6;
TK_LIBRARY=D:\Python31011\tcl\tk8.6
4.4 Whisper GPU 推理崩溃
错误:
Process finished with exit code -1073740791
原因:
CUDA + CTranslate2 在 Windows 存在 native crash
解决:
使用子进程隔离 GPU 推理
4.5 缺少 cublas64_12.dll
错误:
Library cublas64_12.dll not found
原因:
CUDA 未加入 PATH
解决:
PATH += CUDA/bin
4.6 缺少 cudnn
错误:
cudnn_ops_infer64_8.dll
解决:
安装: cuDNN
4.7 Windows 命令过长
错误:
WinError 206 文件名太长
原因:
ffmpeg filter_complex 太长
解决:
使用:
-filter_complex_script
4.8 GBK 编码错误
错误:
gbk codec can't decode byte
原因:
Windows 默认 GBK
Python 输出 UTF8
解决:
subprocess encoding="utf-8"
4.9 Whisper 识别重复文本
问题:
肌肉肌肉肌肉肌肉...
原因:
temperature + beam search
解决:
aiignore
temperature=0.2
no_repeat_ngram_size=3
condition_on_previous_text=False4.10 字幕时间跨度过大
原因:
Whisper segment 过长
解决:
word_timestamps=True
特别说明
该实现需要系统安装并能在 PATH 中调用 ffmpeg。如果 Windows 上无法直接调用,请把 ffmpeg 可执行路径写入系统 PATH 或把 ffmpeg 改为完整路径(我在注释中标明位置)