whisper合入ffmpeg,8.0开始可能使用语音转文字的AI智能。
1. whisper简介
Whisper 是 OpenAI 开发的一款自动语音识别(ASR)模型,同时支持多语言语音转文字、语音翻译(如将其他语言语音直接转为英文文本)等功能。
适用于语音助手、会议记录、字幕生成、多语言沟通等场景,因其开源特性和易用性,被广泛用于开发者和企业的语音处理项目中。
准确的说,这次ffmpeg8.0合入的是whisper.cpp开源库:
https://github.com/ggml-org/whisper.cpp.gitWhisper.cpp 是一个基于 C/C++ 实现的开源项目,旨在将 OpenAI 的 Whisper 语音识别模型以轻量级、高性能的方式部署到各种平台,包括嵌入式设备、PC 和服务器等。
-
跨平台兼容:支持 Windows、Linux、macOS 等主流系统,甚至能在树莓派、iOS、Android 等嵌入式或移动设备上运行。
-
轻量高效:无需依赖 Python 环境或大型深度学习框架(如 PyTorch),通过纯 C/C++ 实现推理,内存占用低,运行速度快。
-
功能完整:保留了 Whisper 模型的核心能力,包括多语言语音识别、语音转文字、时间戳标记等,同时支持命令行调用和二次开发。
-
易于集成:提供简洁的 API 接口,方便开发者将语音识别功能嵌入到自己的 C/C++ 项目中,也支持通过其他语言(如 Python、Go 等)调用。
适合需要本地部署语音识别功能、对资源占用敏感,或需要在嵌入式设备上实现语音处理的场景,比如智能家居设备、离线语音助手、本地录音转文字工具等。
2. ffmpeg8.0的whisper
ffmpeg8.0是把whisper.cpp合入到ffmpeg的avfilter模块中,作为avfilter的一个子功能来使用。
2.1 如何编译
第一步,下载whisper.cpp并用cmake进行构造和编译:
cpp
git clone https://github.com/ggml-org/whisper.cpp.git
cd whisper.cpp
mkdir objs
cd objs
cmake ..
make -j 2
make install第二步,下载ffmpeg,当前采用的是master分支(后面肯定会生成release8.0):
cpp
git clone https://git.ffmpeg.org/ffmpeg.git
cd ffmpeg
git checkcout master第三步,编译ffmpeg,给大家参考的./configure命令行,主要加入使能whisper编译的部分,供参考:
cpp
./configure --enable-cross-compile \
--disable-avdevice \
--disable-doc \
--disable-devices \
--enable-filters \
--enable-libx264 \
--enable-nonfree \
--disable-asm \
--enable-gpl \
--enable-whisper \
--extra-ldflags="-Wl,-rpath,/usr/local/lib"
make -j 2
make install--enable-whisper就是使能whisper.cpp模块,该模块合入到avfilter模块中。
2.2 命令行如何使用
给个简单的例子,把一个视频中的音频进行语音转文字,并输出成.srt的字幕文件。
cpp
ffmpeg -i ./movie.mp4 \
-vn -af \
"whisper=model=/home/runner365/whisper.cpp/models/ggml-medium.bin\
:language=en\
:queue=3\
:destination=movie.srt\
:format=srt" -f null -如上,whisper作为avfiter的一个模块,需要设置"whisper=xx:xx"的属性,主要信息为:
- model:支持的大模型,这个可以自己去下载,可以去whisper.cpp的代码model目录下下载,有多种模型可以选择:
cpp
cd whisper.cpp/models
./download-ggml-model.sh
Usage: ./download-ggml-model.sh <model> [models_path]
Available models:
tiny tiny.en tiny-q5_1 tiny.en-q5_1 tiny-q8_0
base base.en base-q5_1 base.en-q5_1 base-q8_0
small small.en small.en-tdrz small-q5_1 small.en-q5_1 small-q8_0
medium medium.en medium-q5_0 medium.en-q5_0 medium-q8_0
large-v1 large-v2 large-v2-q5_0 large-v2-q8_0 large-v3 large-v3-q5_0 large-v3-turbo large-v3-turbo-q5_0 large-v3-turbo-q8_0上面的例子中model=ggml-medium.bin
-
language: 识别的语言,en为英语,如果不设置,模型会自己检测,不过稍微慢一点。
-
queue: 语音缓存队列
使用 whisper 处理音频之前,排队进入过滤器的最大大小。使用较小的值会更频繁地处理音频流,但转录质量会较低,所需的处理能力也会更高。使用较大的值(例如 10-20 秒)会使用更少的 CPU 获得更准确的结果(就像使用 whisper-cli 工具一样),但转录延迟会更高,因此不适用于处理实时流。默认值:@code{"3"}
-
format:格式,支持srt,json,text
-
destination:结果输出。其可以是文件,如xxx.srt; 也可以是http的一个地址,也就是一些实时流,可以一直post到http server中,http server就可以形成动态字幕给客户。
在生成srt的字幕文件后,可以再用ffmpeg合成srt到mp4中:
cpp
ffmpeg -i movie.mp4 -i movie.srt \
-c:v copy -c:a copy -c:s mov_text \
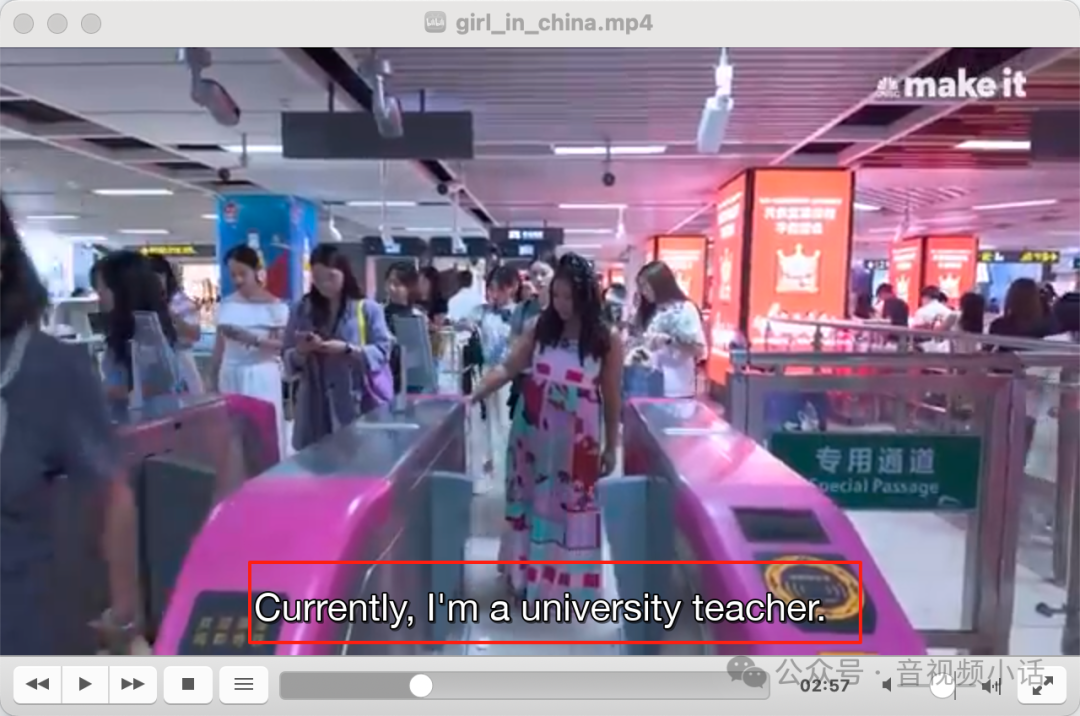
-f mp4 movie_with_srt.mp4用VLC播放,如下效果,英文视频有了英文字幕,领导再也不用担心我听不懂英文了。
3. 展望
ffmpeg8.0合入whisper之后,能使用语音识别的大模型,更多的应用会出现:
-
直播实时字幕的应用场景
-
实时会议的会议场景,后台会议结束后的实时会议纪要
-
英文电影的翻译会变得简单
-
语音识别在嵌入式设备,或移动设备上的应用会更加广泛:android/linux/ios等