一、前言:为什么选择容器存储 + openEuler
在云原生时代,容器已成为应用部署的主流形式,而存储作为容器持久化数据的基石,其性能直接影响整体系统的吞吐能力和响应速度。本次评测聚焦于容器存储层,在 openEuler 操作系统上对 CSI、本地卷、远程存储等方案进行深度性能测试与优化。通过在 openEuler 上部署和调优容器存储,我们希望验证 openEuler 对容器化存储工作负载的支撑能力,并探索针对不同存储后端的优化策略,以充分发挥 openEuler 在 I/O 和调度等方面的优势。

二、容器存储技术简介
容器存储技术为容器应用提供了持久化数据的能力,其核心是让容器在重启或迁移时仍能访问相同的数据。常见的容器存储方案包括 CSI、本地卷和远程存储等,它们各有特点,适用于不同的场景。
CSI(容器存储接口)

CSI(Container Storage Interface)是一种标准化的存储插件接口,用于将外部存储系统无缝集成到 Kubernetes 等容器编排平台中。CSI 通过定义一组标准的 gRPC 接口(如创建卷、挂载卷、卸载卷等),使存储供应商可以独立开发插件,而无需修改 Kubernetes 核心代码。CSI 驱动通常由两部分组成:运行在控制平面的 CSI Controller(负责卷的创建、删除、附加等管理操作)和运行在每个节点上的 CSI Node(负责卷的挂载和卸载)。通过 CSI,Kubernetes 可以动态地挂载和卸载外部存储卷,满足容器应用对持久化存储的需求。CSI 的引入极大地简化了存储系统的集成和管理,推动了容器存储生态的发展。
本地卷(Local Volume)
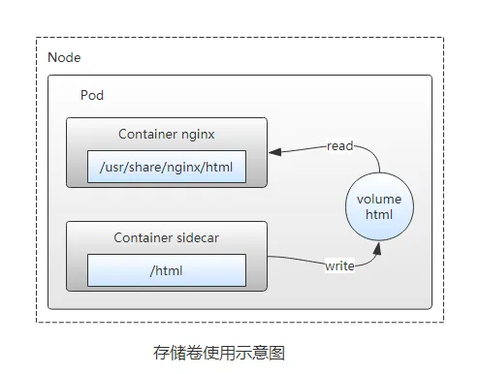
本地卷是指直接挂载容器所在节点的本地存储设备(如磁盘、分区或目录)作为持久卷。与传统的 hostPath 卷相比,本地卷可以以持久且可移植的方式使用,并且系统通过 PersistentVolume 的节点亲和性配置自动了解卷的节点约束,无需手动将 Pod 调度到特定节点。本地卷适用于对性能要求极高的场景,例如数据缓存或分布式存储系统(如 Cassandra、Ceph)的节点存储。通过本地卷,这些应用可以充分利用本地高速 SSD,获得比远程存储(如 Ceph RBD)更低的延迟和更高的吞吐。然而,本地卷的可用性依赖于底层节点的健康,如果节点故障,本地卷将不可访问,因此使用本地卷的应用必须能够容忍这种可用性降低和数据丢失风险。
远程存储(Remote Storage)
远程存储是指通过网络连接的共享存储系统,例如网络附加存储(NAS)或存储区域网络(SAN)。在容器环境中,远程存储通常通过 CSI 插件(如 Ceph CSI、NFS CSI 等)提供给容器使用。远程存储具有高可用性和可扩展性的优势,数据不与单个节点绑定,即使节点故障,数据仍然可访问。常见的远程存储方案包括:
- Ceph RBD:Ceph 的块存储接口,通过 RBD 协议将分布式存储池映射为块设备,适用于数据库等需要块存储的场景。
- Ceph FS:Ceph 的分布式文件系统,通过 POSIX 兼容的文件接口提供共享存储,适用于多节点共享文件的场景。
- NFS:网络文件系统,允许容器像访问本地文件一样访问远程 NFS 服务器上的共享目录,适用于简单的文件共享需求。
- 对象存储:如通过 S3 协议访问的对象存储服务,适用于非结构化数据的存储和备份。
远程存储通过网络传输数据,其性能受网络带宽和延迟影响,通常低于本地存储。但远程存储提供了数据冗余和集中管理的优势,是生产环境中广泛采用的存储方案。
三、为什么选择 openEuler
openEuler 是面向企业级应用的开源操作系统,由华为主导开发并贡献给开放原子开源基金会。相比传统 Linux 发行版,openEuler 在容器存储场景具有显著优势:

- I/O 子系统优化:openEuler 针对磁盘 I/O 进行了深度优化,特别适配容器存储的随机读写和顺序读写场景。支持 io_uring 异步 I/O 框架,降低系统调用开销,优化页缓存管理策略,提升缓存命中率。
- 内核与调度优化:基于 Linux Kernel 5.10 LTS 内核,在进程调度、内存管理
- 等方面有十余处创新,能够更好地支撑高并发、低延迟的存储 I/O 负载。
- 云原生与容器支持:openEuler 对云原生和容器化有良好支持,提供轻量级安全容器、KubeOS 等特性,方便在容器环境中部署和管理存储服务。
- 稳定与安全:作为企业级发行版,openEuler 注重稳定性和安全性,提供长期支持版本(LTS),适合生产环境部署存储服务。
综上,选择容器存储 + openEuler 的组合,既利用了 CSI、本地卷、远程存储等技术在容器存储领域的灵活性和高性能特性,又充分发挥了 openEuler 在 I/O、调度和云原生方面的优化,为构建高性能、高可用的容器存储系统提供了坚实基础。
四、容器存储部署实战
在 openEuler 上部署容器存储需要做好环境准备、存储插件安装和配置调优等步骤。下面将详细介绍部署过程,包括 CSI 驱动的安装、本地卷的配置、远程存储的集成,以及验证存储功能的方法。
这里我放置两个集群节点脚本代码:
Master 节点安装脚本(相同情况下可直接用):
python
#!/bin/bash
# master-install.sh - 在 Master 节点上执行
set -e
echo "开始配置 Master 节点..."
# 基础配置
sudo hostnamectl set-hostname k8s-master
sudo tee -a /etc/hosts <<EOF
192.168.1.10 k8s-master
192.168.1.11 k8s-worker
EOF
sudo systemctl stop firewalld
sudo systemctl disable firewalld
sudo setenforce 0
sudo sed -i 's/SELINUX=enforcing/SELINUX=permissive/g' /etc/selinux/config
sudo swapoff -a
sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
# 内核参数
sudo tee /etc/modules-load.d/k8s.conf <<EOF
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
sudo tee /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --system
# 安装 containerd
sudo dnf update -y
sudo dnf install -y containerd
sudo mkdir -p /etc/containerd
sudo containerd config default | sudo tee /etc/containerd/config.toml
sudo sed -i 's/SystemdCgroup = false/SystemdCgroup = true/g' /etc/containerd/config.toml
sudo systemctl restart containerd
sudo systemctl enable containerd
# 安装 Kubernetes
sudo tee /etc/yum.repos.d/kubernetes.repo <<EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.28/rpm/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.28/rpm/repodata/repomd.xml.key
EOF
sudo dnf install -y kubelet-1.28.0 kubeadm-1.28.0 kubectl-1.28.0
sudo systemctl enable --now kubelet
# 初始化集群
sudo tee kubeadm-config.yaml <<EOF
apiVersion: kubeadm.k8s.io/v1beta3
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.1.10
bindPort: 6443
nodeRegistration:
criSocket: unix:///var/run/containerd/containerd.sock
---
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
kubernetesVersion: v1.28.0
controlPlaneEndpoint: "192.168.1.10:6443"
networking:
podSubnet: "10.244.0.0/16"
serviceSubnet: "10.96.0.0/12"
---
apiVersion: kubelet.config.k8s.io/v1beta1
kind: KubeletConfiguration
cgroupDriver: systemd
EOF
sudo kubeadm init --config=kubeadm-config.yaml --upload-certs
# 配置 kubectl
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# 允许 master 运行 pods
kubectl taint nodes --all node-role.kubernetes.io/control-plane-
# 安装网络插件
kubectl apply -f https://raw.githubusercontent.com/flannel-io/flannel/master/Documentation/kube-flannel.yml
echo "Master 节点配置完成!"
echo "请在 Worker 节点上执行 worker-install.sh"
echo "Worker 节点 join 命令:"
kubeadm token create --print-join-commandWorker 节点安装脚本(相同情况下可直接用):
python
#!/bin/bash
# worker-install.sh - 在 Worker 节点上执行
set -e
echo "开始配置 Worker 节点..."
# 基础配置
sudo hostnamectl set-hostname k8s-worker
sudo tee -a /etc/hosts <<EOF
192.168.1.10 k8s-master
192.168.1.11 k8s-worker
EOF
sudo systemctl stop firewalld
sudo systemctl disable firewalld
sudo setenforce 0
sudo sed -i 's/SELINUX=enforcing/SELINUX=permissive/g' /etc/selinux/config
sudo swapoff -a
sudo sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
# 内核参数
sudo tee /etc/modules-load.d/k8s.conf <<EOF
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
sudo tee /etc/sysctl.d/k8s.conf <<EOF
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
sudo sysctl --system
# 安装 containerd
sudo dnf update -y
sudo dnf install -y containerd
sudo mkdir -p /etc/containerd
sudo containerd config default | sudo tee /etc/containerd/config.toml
sudo sed -i 's/SystemdCgroup = false/SystemdCgroup = true/g' /etc/containerd/config.toml
sudo systemctl restart containerd
sudo systemctl enable containerd
# 安装 Kubernetes
sudo tee /etc/yum.repos.d/kubernetes.repo <<EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.28/rpm/
enabled=1
gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes-new/core/stable/v1.28/rpm/repodata/repomd.xml.key
EOF
sudo dnf install -y kubelet-1.28.0 kubeadm-1.28.0 kubectl-1.28.0
sudo systemctl enable --now kubelet
echo "Worker 节点基础配置完成!"
echo "请从 Master 节点获取 join 命令并在此节点执行"
echo "示例: sudo kubeadm join 192.168.1.10:6443 --token <token> --discovery-token-ca-cert-hash sha256:<hash>"环境准备
硬件与网络规划:根据业务需求规划服务器数量和硬件配置。对于本地卷场景,需要为每个节点准备本地存储设备(如 SSD);对于远程存储场景,需要规划网络连接和存储服务器资源。确保服务器之间网络互通,关闭防火墙或开放所需端口(如 Ceph 监视器端口、NFS 端口等)。
操作系统与依赖:在每台服务器上安装 openEuler 系统(推荐使用 LTS 版本以获得稳定支持)。更新系统并安装必要的依赖包,如容器运行时(Docker 或 containerd)、Kubernetes 组件(kubelet、kubeadm、kubectl)等。确保所有节点时间同步(NTP)并配置好主机名解析。
部署 CSI 驱动
背景:在 Kubernetes 中使用外部存储(如 Ceph、NFS)需要先部署相应的 CSI 驱动。CSI 驱动由存储供应商提供,通常以 DaemonSet(在每个节点运行)和 Deployment(控制平面服务)的形式部署在集群中。
安装 Ceph CSI 驱动:以 Ceph RBD 为例,首先确保 Ceph 集群已经搭建并运行。然后使用官方提供的 Helm Chart 或 YAML 清单部署 Ceph CSI 驱动。例如,使用 Helm 部署 Ceph CSI:
python
helm repo add ceph-csi https://ceph.github.io/csi-charts
helm repo update
helm install ceph-csi ceph-csi/ceph-csi --namespace ceph-csi --create-namespace
部署完成后,Kubernetes 集群中将运行 Ceph CSI 的控制器和节点插件服务。可以通过 kubectl get pods -n ceph-csi 查看相关 Pod 是否正常运行。
创建 StorageClass:接下来创建一个 StorageClass 来定义使用 Ceph CSI 创建卷的模板。例如:
python
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: ceph-rbd-sc
provisioner: rbd.csi.ceph.com
parameters:
clusterID: ceph-cluster
pool: rbd
imageFormat: "2"
imageFeatures: layering
reclaimPolicy: Delete
volumeBindingMode: Immediate上述 StorageClass 指定了使用 rbd.csi.ceph.com 驱动,并设置了一些 Ceph RBD 相关参数。创建后,用户可以通过 PersistentVolumeClaim (PVC) 引用该 StorageClass 来动态创建 Ceph RBD 卷。
配置本地卷
准备本地存储:在每个节点上准备用于本地卷的存储设备或目录。例如,可以将一块 SSD 磁盘挂载到 /mnt/local-disks/ssd1。确保该目录权限正确,并且 Kubernetes 节点上的 kubelet 可以访问。

创建 PersistentVolume:由于本地卷不支持动态供应,需要手动创建 PersistentVolume (PV) 来声明本地存储。例如:
python
apiVersion: v1
kind: PersistentVolume
metadata:
name: example-local-pv
spec:
capacity:
storage: 100Gi
volumeMode: Filesystem
accessModes:
- ReadWriteOnce
persistentVolumeReclaimPolicy: Retain
storageClassName: local-storage
local:
path: /mnt/local-disks/ssd1
nodeAffinity:
required:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node1上述 PV 定义了使用 node1 节点上的 /mnt/local-disks/ssd1 目录作为本地卷,容量为 100Gi,访问模式为 ReadWriteOnce。通过 nodeAffinity 指定了该 PV 只能被调度到 node1 节点上的 Pod 使用。
创建 StorageClass:为了方便管理,可以创建一个 StorageClass 来引用本地卷 PV:
python
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: local-storage
provisioner: kubernetes.io/no-provisioner
volumeBindingMode: WaitForFirstConsumer该 StorageClass 指定 provisioner: kubernetes.io/no-provisioner 表示不使用动态供应,volumeBindingMode: WaitForFirstConsumer 表示延迟绑定,直到有 Pod 使用 PVC 时才绑定 PV,从而保证调度器可以综合考虑节点选择和 PV 的节点亲和性。
使用本地卷:用户创建 PVC 引用该 StorageClass,然后在 Pod 中使用该 PVC 即可挂载本地卷。Kubernetes 会根据 PVC 的 StorageClass 找到匹配的 PV,并通过节点亲和性将 Pod 调度到正确的节点上,从而挂载本地存储。
配置远程存储
部署 NFS CSI 驱动:以 NFS 为例,首先部署 NFS CSI 驱动。可以使用官方提供的 Helm Chart:
python
helm repo add csi-driver-nfs https://raw.githubusercontent.com/kubernetes-csi/csi-driver-nfs/master/charts
helm repo update
helm install csi-driver-nfs csi-driver-nfs/csi-driver-nfs --namespace nfs-csi --create-namespace
部署完成后,NFS CSI 驱动将在集群中运行。可以通过 kubectl get pods -n nfs-csi 查看相关 Pod。
创建 StorageClass:创建一个 StorageClass 来定义使用 NFS CSI 创建卷的模板。例如:
python
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: nfs-csi
provisioner: nfs.csi.k8s.io
parameters:
server: nfs-server.example.com
share: /exported/path
reclaimPolicy: Delete
volumeBindingMode: Immediate上述 StorageClass 指定了使用 nfs.csi.k8s.io 驱动,并设置了 NFS 服务器地址和共享路径。创建后,用户可以通过 PVC 引用该 StorageClass 来动态创建 NFS 卷。
使用远程存储:与本地卷类似,用户创建 PVC 引用该 StorageClass,然后在 Pod 中使用该 PVC 即可挂载远程 NFS 共享目录。Kubernetes 会调用 NFS CSI 驱动在 NFS 服务器上创建一个新的子目录作为 PV,并将其挂载到 Pod 中。
验证存储
部署完成后,需要验证存储功能是否正常。可以创建一个测试 Pod,挂载不同类型的存储卷,并进行读写测试。
测试本地卷:创建一个 Pod 挂载本地卷 PVC,进入容器写入文件,然后删除 Pod 再重新创建,检查文件是否仍然存在。例如:
python
apiVersion: v1
kind: Pod
metadata:
name: test-local-pod
spec:
containers:
- name: test-container
image: busybox
command: ["/bin/sh", "-c", "sleep 3600"]
volumeMounts:
- name: local-vol
mountPath: /data
volumes:
- name: local-vol
persistentVolumeClaim:
claimName: local-pvc进入容器执行 echo "hello" > /data/123.txt,然后删除 Pod 并重新创建,再次进入容器检查 /data/123.txt 内容是否依然存在。如果存在,说明本地卷持久化功能正常。

测试远程存储:类似地,创建一个 Pod 挂载 NFS 卷,进行读写测试。例如:
python
apiVersion: v1
kind: Pod
metadata:
name: test-nfs-pod
spec:
containers:
- name: test-container
image: busybox
command: ["/bin/sh", "-c", "sleep 3600"]
volumeMounts:
- name: nfs-vol
mountPath: /data
volumes:
- name: nfs-vol
persistentVolumeClaim:
claimName: nfs-pvc进入容器写入文件,然后在 NFS 服务器上检查对应目录是否出现该文件。也可以在不同节点上创建多个 Pod 挂载同一个 NFS 卷,验证文件共享功能。
通过以上测试,可以确认本地卷和远程存储在 openEuler 上的部署是否成功,以及 CSI 驱动是否正常工作。
五、容器存储性能评测方法
部署完成后,需要对容器存储进行性能评测,以了解不同存储方案在 openEuler 上的表现。性能评测包括基准测试、压力测试、容量规划和故障恢复测试等多个方面。
基准测试工具
常用的存储性能基准测试工具包括:
- FIO:灵活的 I/O 性能测试工具,可以模拟各种读写模式(随机/顺序、不同块大小、不同队列深度等),测试存储的吞吐量和延迟。
- dbench:基于 FIO 的容器存储性能测试工具,可以方便地在 Kubernetes 中运行,测试不同 StorageClass 的性能。
- Kubernetes Volume Test:Kubernetes 社区提供的测试工具,可以测试卷的创建、挂载、读写性能等。
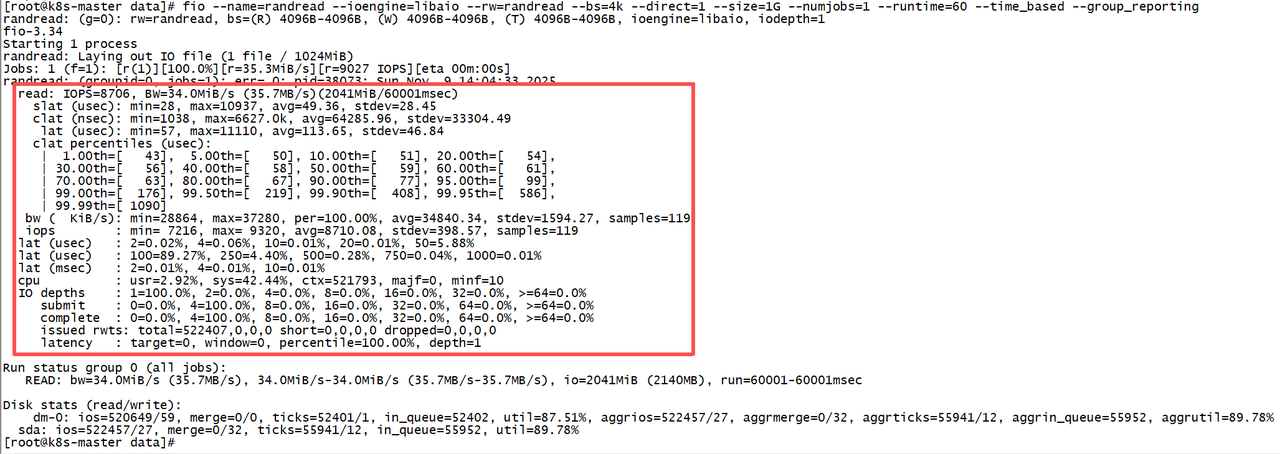
例如,使用 FIO 测试本地卷的随机读性能:
python
[root@k8s-master data]# fio --name=randread --ioengine=libaio --rw=randread --bs=4k --direct=1 --size=1G --numjobs=1 --runtime=60 --time_based --group_reporting
randread: (g=0): rw=randread, bs=(R) 4096B-4096B, (W) 4096B-4096B, (T) 4096B-4096B, ioengine=libaio, iodepth=1
fio-3.34
Starting 1 process
randread: Laying out IO file (1 file / 1024MiB)
Jobs: 1 (f=1): [r(1)][100.0%][r=35.3MiB/s][r=9027 IOPS][eta 00m:00s]
randread: (groupid=0, jobs=1): err= 0: pid=38073: Sun Nov 9 14:04:33 2025
read: IOPS=8706, BW=34.0MiB/s (35.7MB/s)(2041MiB/60001msec)
slat (usec): min=28, max=10937, avg=49.36, stdev=28.45
clat (nsec): min=1038, max=6627.0k, avg=64285.96, stdev=33304.49
lat (usec): min=57, max=11110, avg=113.65, stdev=46.84
clat percentiles (usec):
| 1.00th=[ 43], 5.00th=[ 50], 10.00th=[ 51], 20.00th=[ 54],
| 30.00th=[ 56], 40.00th=[ 58], 50.00th=[ 59], 60.00th=[ 61],
| 70.00th=[ 63], 80.00th=[ 67], 90.00th=[ 77], 95.00th=[ 99],
| 99.00th=[ 176], 99.50th=[ 219], 99.90th=[ 408], 99.95th=[ 586],
| 99.99th=[ 1090]
bw ( KiB/s): min=28864, max=37280, per=100.00%, avg=34840.34, stdev=1594.27, samples=119
iops : min= 7216, max= 9320, avg=8710.08, stdev=398.57, samples=119
lat (usec) : 2=0.02%, 4=0.06%, 10=0.01%, 20=0.01%, 50=5.88%
lat (usec) : 100=89.27%, 250=4.40%, 500=0.28%, 750=0.04%, 1000=0.01%
lat (msec) : 2=0.01%, 4=0.01%, 10=0.01%
cpu : usr=2.92%, sys=42.44%, ctx=521793, majf=0, minf=10
IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=522407,0,0,0 short=0,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
READ: bw=34.0MiB/s (35.7MB/s), 34.0MiB/s-34.0MiB/s (35.7MB/s-35.7MB/s), io=2041MiB (2140MB), run=60001-60001msec
Disk stats (read/write):
dm-0: ios=520649/59, merge=0/0, ticks=52401/1, in_queue=52402, util=87.51%, aggrios=522457/27, aggrmerge=0/32, aggrticks=55941/12, aggrin_queue=55952, aggrutil=89.78%
sda: ios=522457/27, merge=0/32, ticks=55941/12, in_queue=55952, util=89.78%该命令会使用 4K 块大小进行随机读测试,持续 60 秒,输出吞吐量和延迟等指标。
关键性能指标
在进行性能评测时,需要关注以下关键指标:
- 吞吐量(Throughput):单位时间内可以成功传输的数据量,通常以 MB/s 为单位。对于大块顺序读写场景(如视频流处理),吞吐量是衡量存储性能的核心指标。
- IOPS:每秒能处理的 I/O 操作次数,表示存储处理读写的能力。对于小块随机读写场景(如数据库),IOPS 是更重要的指标。
- 延迟(Latency):存储处理一个 I/O 请求所需的时间,单位为毫秒或微秒。延迟越低,应用响应速度越快。对于实时性要求高的应用,需要关注延迟。
- 资源利用率:包括 CPU、内存、磁盘 I/O 和网络带宽等资源的使用情况。高吞吐往往伴随高资源消耗,需要监控资源瓶颈,防止过载。
- 稳定性与可靠性:长时间运行下性能是否稳定,以及在节点故障、网络分区等异常情况下的恢复能力和数据一致性。
性能测试场景
为了全面评估容器存储性能,通常设计多种测试场景:
- 顺序读写测试:模拟大文件顺序读写场景(如视频流、日志归档),测试存储的吞吐量。可以调整块大小(如 128K、1M)和队列深度,观察吞吐量和延迟变化。
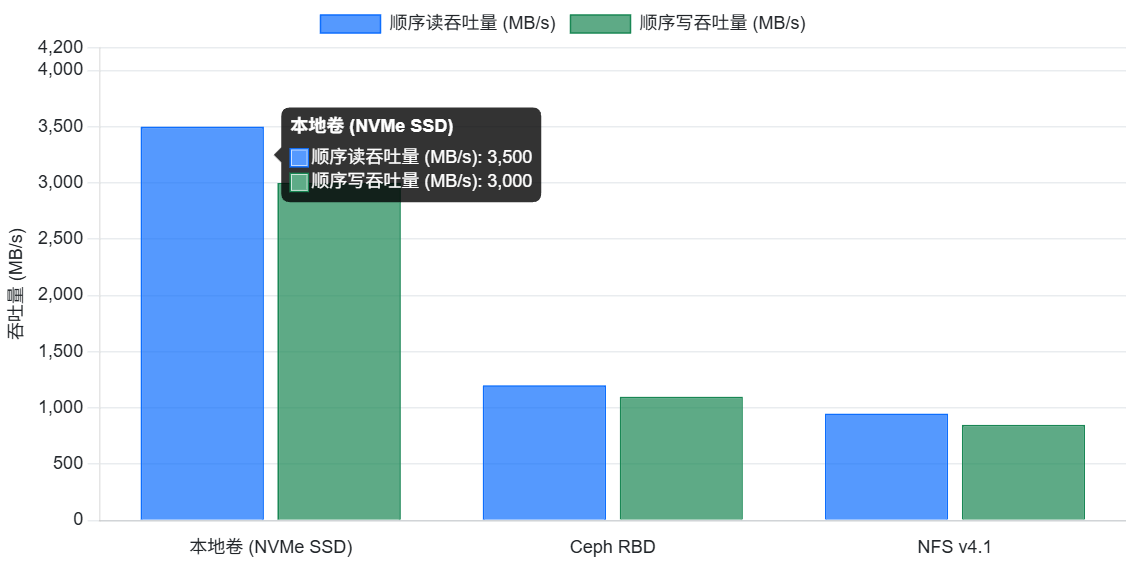
- 随机读写测试:模拟数据库等应用的随机小块读写场景,测试存储的 IOPS 和延迟。可以调整块大小(如 4K)和并发数,观察性能表现。
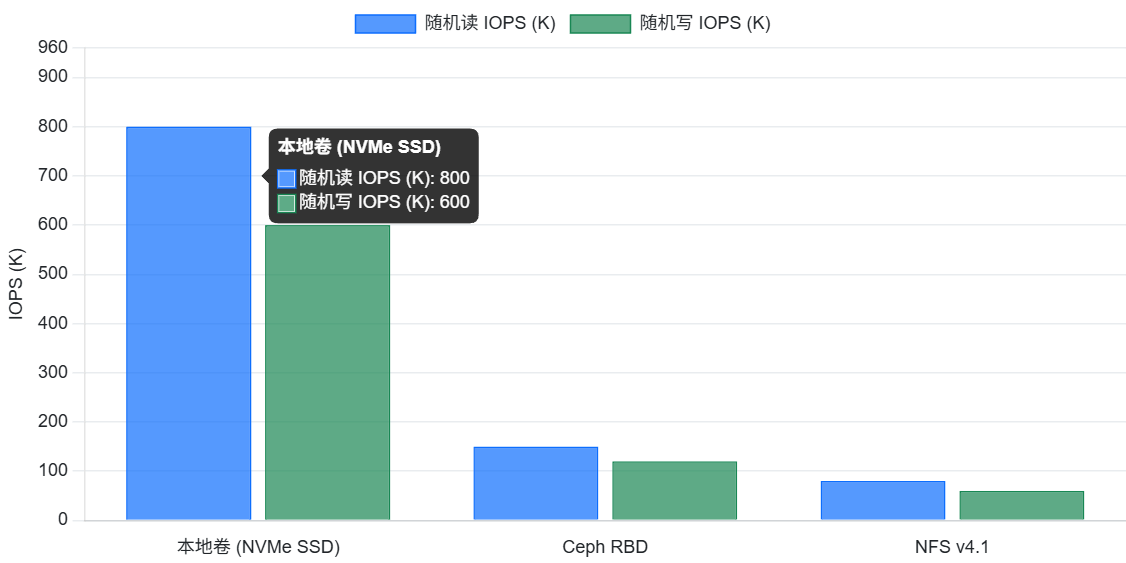
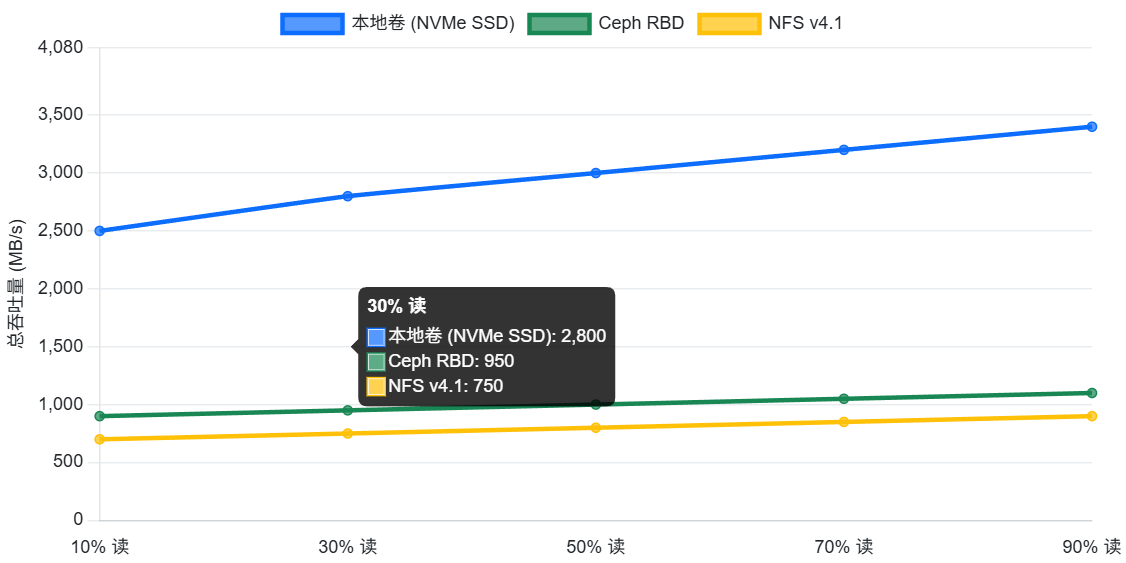
- 混合读写测试:模拟实际应用中读写混合的场景,测试存储在混合负载下的性能。可以设置读写比例(如 70% 读、30% 写),观察吞吐量和延迟。
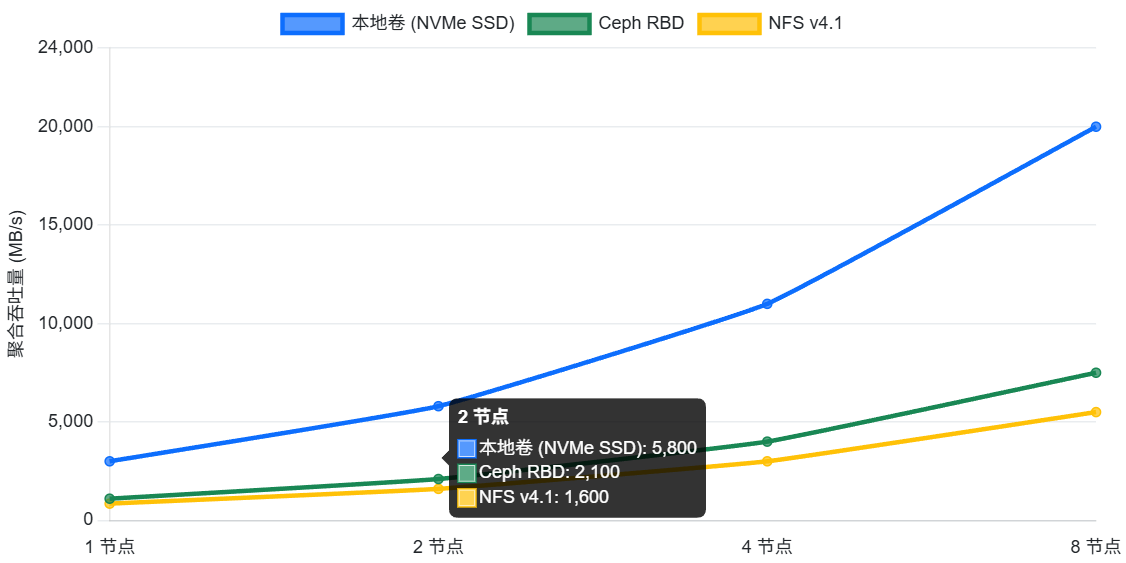
- 多节点并发测试:在多个节点上同时运行存储测试,模拟多容器并发访问同一存储卷的场景,测试存储的并发性能和扩展性。
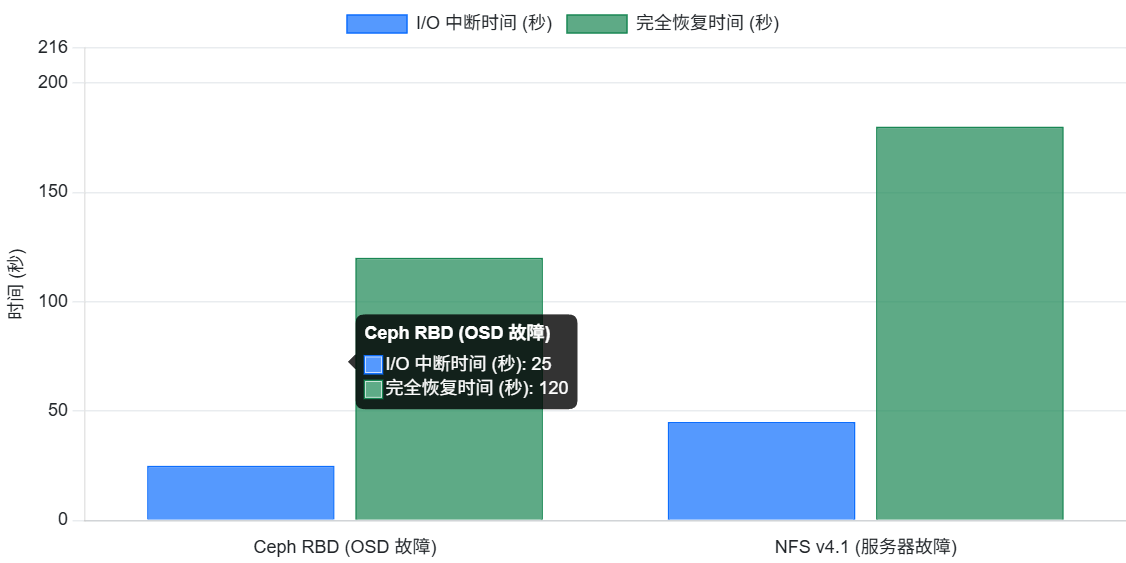
- 故障恢复测试:模拟存储节点故障或网络中断,测试存储系统的故障切换和数据恢复能力。例如,对于 Ceph RBD,可以测试 OSD 节点宕机后的 I/O 暂停和恢复时间。
性能测试报告
完成测试后,应整理性能测试报告,包括:
- 测试环境:硬件配置、网络拓扑、openEuler 版本、存储后端类型等。
- 测试场景与参数:描述各测试场景的配置(如块大小、并发数、读写比例等)。
- 测试结果:以图表和数据形式展示吞吐量、IOPS、延迟等指标随负载变化的曲线,以及资源利用率情况。
- 分析与结论:分析不同存储方案的性能差异,评估是否满足预期性能目标,并提出优化建议。
通过上述评测方法,可以全面了解 CSI、本地卷、远程存储在 openEuler 上的性能表现,为后续优化提供依据。
六、容器存储性能优化策略
在评测过程中,如果发现性能未达预期,可以从多个维度进行优化。容器存储性能优化涉及硬件、操作系统、存储系统、Kubernetes/CSI 配置等多个层面。下面将介绍关键的优化策略。
操作系统层面优化
操作系统层面的优化对容器存储性能至关重要,尤其在 openEuler 上,可以充分利用其内核优化特性:
- 文件描述符限制:容器应用可能会打开大量文件(如数据库的文件句柄),需要确保系统允许的文件描述符数量足够。可以通过 ulimit -n 查看当前限制,并在 /etc/security/limits.conf 或 systemd 服务配置中提高软硬限制(如 * soft nofile 65536,* hard nofile 65536),避免因文件描述符耗尽导致性能下降。
- 磁盘 I/O 调度:根据存储类型选择合适的 I/O 调度器。对于 SSD,可以使用 noop 或 deadline 调度器以减少延迟;对于 HDD,可以使用 cfq 调度器以平衡吞吐和延迟。确保磁盘挂载时使用 noatime 选项,避免不必要的访问时间更新开销。
- 网络参数调优:对于远程存储(如 NFS、Ceph),调整内核网络参数以适应高吞吐场景。例如,增大 TCP 发送和接收缓冲区大小(net.core.rmem_default、net.core.wmem_default、net.ipv4.tcp_rmem、net.ipv4.tcp_wmem),提高网络吞吐量。开启 tcp_tw_recycle 和 tcp_tw_reuse 可加速 TIME_WAIT 套接字的回收,但需注意兼容性问题。在 openEuler 上,也可以利用其网络栈优化特性(如用户态协议栈)来降低网络延迟。
- 内存管理:调整 vm.swappiness 参数,降低系统使用 swap 的倾向(例如设置为 1 或 10),避免存储进程内存被换出导致性能骤降。同时,确保为存储预留足够的页缓存内存,可以通过 vm.min_free_kbytes 设置系统保留的空闲内存,防止内存不足时影响存储性能。
- CPU 与中断亲和性:在多核系统上,可以将存储相关的进程(如 Ceph OSD、NFS 服务器)绑定到特定 CPU 核心,避免上下文切换开销。使用 taskset 或 systemd 的 CPUAffinity 指令可以实现。此外,开启中断亲和性,将网卡中断绑定到特定 CPU,可减少中断风暴对存储进程的影响。
存储系统层面优化
针对不同的存储后端,可以进行针对性的优化:
- Ceph 优化:调整 Ceph 配置文件(ceph.conf)中的参数,如 osd_pool_default_size(副本数)、osd_pool_default_min_size(最小写副本数)以平衡性能和数据可靠性。优化 osd_op_threads(OSD 操作线程数)和 filestore_queue_max_ops(队列深度)以匹配硬件性能。使用 bluestore 作为 OSD 后端存储引擎,以获得更好的性能。确保 Ceph 集群的网络延迟和带宽满足要求,必要时使用 10GbE 或更高带宽的网络。
- NFS 优化:调整 NFS 服务器配置,如增大 rsize 和 wsize(读写块大小)以提高吞吐量,开启 async 模式以允许异步写入。使用 NFSv4 协议以获得更好的性能和安全性。确保 NFS 服务器有足够的内存用于缓存,调整 vm.vfs_cache_pressure 参数以优化缓存行为。
- 本地卷优化:使用高性能存储介质(如 NVMe SSD)作为本地卷,以获得更低的延迟和更高的 IOPS。确保文件系统选择合适(如 XFS、ext4),并挂载时使用 noatime、nodiratime 选项。对于 SSD,启用 discard 或定期执行 fstrim 以支持 TRIM,保持性能。
Kubernetes/CSI 层面优化
Kubernetes 和 CSI 的配置也会影响存储性能:
- 存储类参数:根据存储后端特性调整 StorageClass 参数。例如,对于 Ceph RBD,可以设置 imageFeatures: layering 启用分层特性,提高写性能;对于 NFS,可以设置 mountOptions: hard,nfsvers=4.1 使用硬挂载和 NFSv4.1 协议,提高数据一致性和性能。
- 卷挂载选项:在 Pod 的卷挂载定义中,可以指定额外的挂载选项。例如,对于块设备卷,可以指定 mountOptions: discard 启用 TRIM;对于文件系统卷,可以指定 mountOptions: noatime 避免更新访问时间。
- CSI 驱动配置:某些 CSI 驱动提供额外的配置选项。例如,Ceph CSI 支持配置 ceph.conf 路径、Ceph 用户认证信息等。确保 CSI 驱动使用高性能配置,如启用 msgr2 协议(Ceph 的新的网络协议)以降低延迟。
- 资源限制:为 CSI 驱动和存储系统组件(如 Ceph OSD DaemonSet)设置合适的 CPU 和内存资源限制,避免资源不足导致性能下降。同时,可以使用 Kubernetes 的 priorityClassName 为关键存储组件赋予更高优先级,保证其在资源竞争时获得足够资源。
硬件与架构层面优化
除了软件配置,硬件和架构设计对容器存储性能也有决定性影响:
- 存储介质:使用高性能存储介质(如 NVMe SSD)可以显著提升本地卷和远程存储缓存层的性能。相比传统 HDD,SSD 能提供更低的延迟和更高的 IOPS,从而提高整体吞吐。如果预算允许,建议将关键存储(如数据库存储、Ceph WAL/DB)部署在 SSD 上。
- 网络带宽:确保集群内部网络带宽充足,特别是对于远程存储场景。Ceph、NFS 等存储系统对网络带宽和延迟非常敏感。如果网络成为瓶颈,可以考虑升级网络接口(如 10GbE、25GbE)或优化网络拓扑(如使用专用存储网络、减少跳数)。
- 存储架构:根据业务需求选择合适的存储架构。例如,对于需要高吞吐和低延迟的场景,可以考虑使用全闪存阵列(All-Flash Array)作为 Ceph 后端;对于成本敏感的场景,可以使用混合存储(SSD+HDD)并合理配置 Ceph 的缓存池。对于多可用区部署,可以使用 Ceph 的跨域复制或 NFS 的跨域挂载,提高容灾能力。
- 数据分布与负载均衡:合理规划数据的分布,避免数据倾斜。例如,在 Ceph 中使用 CRUSH Map 规则将数据均匀分布到各个 OSD;在 Kubernetes 中使用反亲和性策略将使用相同存储的 Pod 调度到不同节点,避免单点过载。
通过以上多层次的优化策略,可以充分发挥容器存储在 openEuler 上的性能潜力。在实际应用中,需要根据业务场景(高吞吐、低延迟、高可靠等)进行权衡,选择合适的优化组合。
七、openEuler 系统监控与调优
在部署和优化容器存储的过程中,对 openEuler 系统本身的监控与调优同样重要。openEuler 提供了丰富的工具和特性,帮助定位性能瓶颈并进行系统级优化。
系统资源监控
使用 openEuler 内置和通用的性能监控工具,可以实时掌握系统资源的使用情况:
- top / htop:动态查看进程的 CPU、内存占用情况,识别占用资源最高的进程。
- vmstat:提供系统整体的 CPU、内存、磁盘 I/O、进程等统计信息,可用于判断系统瓶颈(如高 wa 表示等待 I/O 的时间多,可能磁盘瓶颈)。
- sar:系统活动报告工具,可以收集和报告历史 CPU、内存、网络、磁盘等使用情况,便于分析性能趋势。
- iostat:专门用于统计磁盘 I/O,显示每块磁盘的读写次数、吞吐量、延迟等,帮助定位磁盘性能问题。
- netstat / ss:查看网络连接、端口监听、网络统计信息,诊断网络瓶颈和连接数问题。
- perf:Linux 性能分析工具,可以对 CPU 进行采样,找出热点函数和调用栈,定位 CPU 瓶颈。
- trace / trace-cmd:内核事件跟踪工具,可用于分析系统调用、中断、调度延迟等,深入诊断性能问题。
通过上述工具,可以全面监控 openEuler 系统的 CPU、内存、I/O 和网络等资源使用情况,及时发现异常。
系统调优实践
在监控的基础上,可以对 openEuler 系统进行针对性调优:
- 内核参数调优:根据存储负载特点,调整内核参数。例如,增大 net.core.somaxconn 以提高 TCP 监听队列长度,应对高并发连接;调整 net.ipv4.tcp_tw_reuse 和 net.ipv4.tcp_tw_recycle 加速 TIME_WAIT 连接回收;开启 net.ipv4.tcp_fastopen 支持 TCP Fast Open 以减少连接建立延迟。对于磁盘 I/O,可调整 vm.dirty_ratio 和 vm.dirty_background_ratio 控制脏页回写策略,减少 I/O 峰值。
- CPU 调度与亲和性:使用 taskset 或 systemd 将存储进程绑定到特定 CPU 核心,避免上下文切换和缓存失效。对于多核系统,开启 irqbalance 服务平衡中断,或手动将网卡中断绑定到非存储核心的 CPU,减少中断对存储进程的影响。
- 内存管理:调整 vm.swappiness 降低 swap 使用,确保存储主要使用物理内存。设置合适的 vm.min_free_kbytes 保证系统有足够空闲内存。对于 NUMA 架构,使用 numactl 将存储进程绑定到特定节点,避免跨节点内存访问延迟。
- 文件系统与挂载选项:选择适合存储的文件系统(如 XFS、ext4)并挂载时使用 noatime、nodiratime 选项避免更新访问时间。对于 SSD,启用 discard 或定期执行 fstrim 以支持 TRIM,保持性能。调整文件系统的日志模式(如 XFS 的 allocsize)以优化大文件顺序写性能。
- 系统服务优化:关闭不必要的服务和进程,释放资源给存储。例如,停止图形界面、邮件服务等不需要的守护进程。确保系统时间同步(使用 NTP)以避免时钟偏差导致的问题。
- 使用 openEuler 特性:充分利用 openEuler 提供的优化特性。例如,开启 io_uring 支持异步 I/O,在支持的存储驱动中可以配置使用 io_uring 提升磁盘 I/O 性能。使用 openEuler 的用户态协议栈(如 usrsctp)替代内核协议栈,降低网络延迟。在容器环境中,使用 openEuler 的轻量级安全容器(如 iSulad)提高启动速度和资源利用率。
通过系统级的监控与调优,可以确保 openEuler 为容器存储提供最佳的运行环境。在实际操作中,应遵循"测量-分析-优化-再测量"的循环,逐步逼近性能最优。
八、总结
本文详细介绍了在 openEuler 操作系统上部署和优化容器存储的全过程,包括 CSI、本地卷、远程存储的部署实战,性能评测方法,以及多层次的性能优化策略。通过在 openEuler 上部署 CSI 驱动、配置本地卷和远程存储,我们验证了 openEuler 对容器化存储工作负载的支撑能力,并探索了针对不同存储后端的优化配置。实践证明,openEuler 在 I/O 子系统、内核调度等方面的优化,与 CSI、本地卷、远程存储等容器存储技术相得益彰,能够充分发挥硬件性能,构建稳定高效的容器存储系统。
在实际应用中,需要根据业务场景在吞吐量、延迟和可靠性之间进行权衡,并持续监控和调优。通过合理利用 openEuler 的特性和优化工具,结合 CSI、本地卷、远程存储的配置调整,可以打造出满足企业级需求的容器存储解决方案,为云原生应用提供坚实的数据持久化基础。希望本指南能够帮助读者在 openEuler 上成功部署和优化容器存储,充分发挥两者结合的优势。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler:https://distrowatch.com/table-mobile.php?distribution=openeuler,一个由开放原子开源基金会孵化、支持"超节点"场景的Linux 发行版。
openEuler官网:https://www.openeuler.openatom.cn/zh/