就在本周,DeepSeek V3.2 正式上线。当天我写了一篇分析,提到了这次技术上可能被忽视的突破:
一个是 DSA 稀疏注意力,另一个是思考模式的工具调用的突破。
显然评论区的小伙伴对第二个讨论更激烈。
没错,是 DeepSeek 的首次,但不是行业的首次。评论区有人直接不服点名 minimax、gemini、claude、o3 就已经支持了。
DeepSeek 把它叫「Thinking in Tool-Use」(思考 + 工具调用),Anthropic 最早称为「Extended Thinking」(延展思考),MiniMax 叫法是「Interleaved Thinking」(交错思维链),kimi 叫「边思考、边使用工具」,各家有各家的叫法,但是本质上是同一个技术能力------让模型在调用工具的过程中持续思考,而不是想完就干,干完就停。
这么一争论,我发现了一个有意思的现象:做 Agent 底座模型的这些大模型公司们,都在做同一件事儿,但还没有一个统一的认知。
先就近看最新的 DeepSeek V3.2 的图:
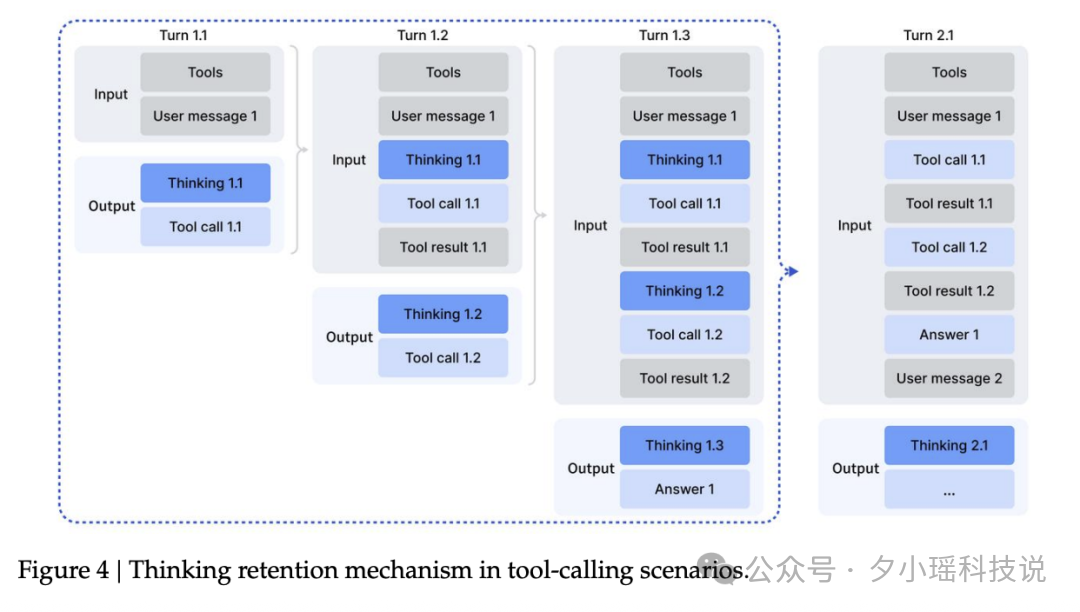
模型先进行初步推理(Thinking 1.1),然后发起第一次工具调用(Tool call 1.1),拿到返回结果(Tool result 1.1)之后,继续往下思考(Thinking 1.2),并再次调用工具(Tool call 1.2)......
等等,我总觉得这个路径好像在哪见过。。
我翻了一下资料,原来两周前在 AIE 大会上,MiniMax 也重点讲了这个。

他们的叫法是------Interleaved Thinking(交错思维链)。
甚至这俩的图都好像。。。这可就有意思了。
两大国产之光,同时盯上了同一项新技术------Interleaved Thinking。
Interleaved thinking 是什么?
简单说,它让模型学会"边想边干"。
过去,大多数模型的工作方式很"直男":接到任务,想一遍,立刻去做。做完就交差,中间不再思考。
你可能觉得够用了,但其实这种方式有很多隐藏的毛病。比如工具查回来的结果模型理解错了,但它已经开始输出了。或者它原本想好了三步计划,查完工具结果后一拍脑袋直接跳到第四步,前后不连贯。
更常见的,是它根本没能基于新信息重新组织思路,只是机械地堆出一段回应。
这,就是旧式 AI 推理的通病------逻辑中断。
而 Interleaved Thinking 的出现,就是为了解决这个问题。
它允许模型在每次工具调用之后立刻再进行一次思考,评估新信息是否推翻了旧计划,是否需要重新规划下一步。也就是说 Interleaved Thinking 让模型像人一样,一边干活一边思考、实时修正。
你可以看这张图:
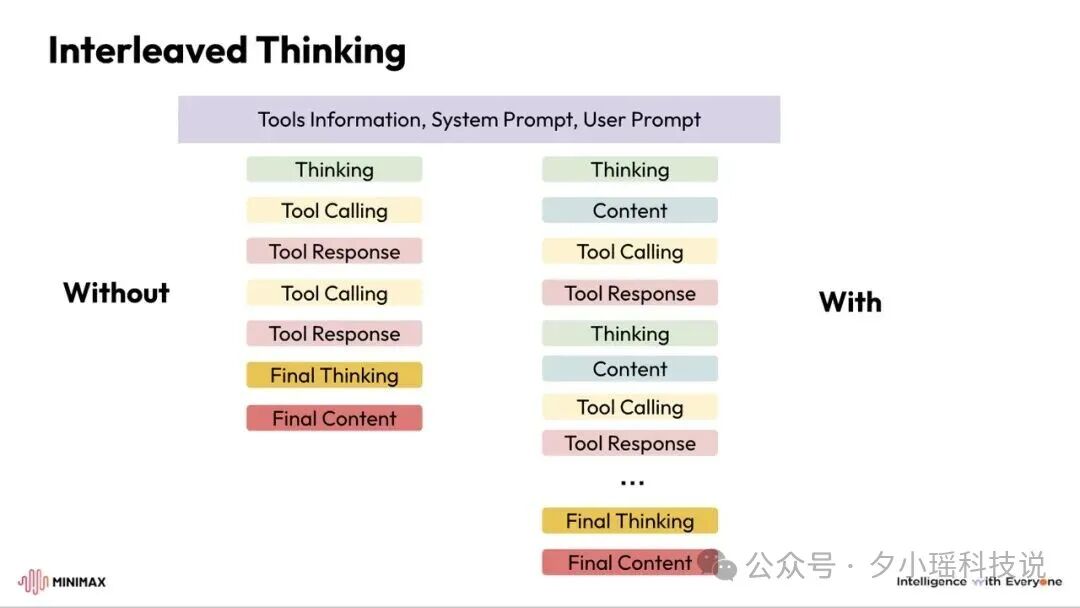
左边是传统的模式,整个过程思考只发生在开头和结尾。右边是**Interleaved Thinking 模式,**思考过程和工具使用交替进行,而不是一次从完成所有思考。
在这种模式下:
-
工具调用前思考 :模型先分析当前情况,决定调用什么工具。
-
执行工具 :调用工具获取结果。
-
基于结果再思考 :根据工具返回的信息进行新一轮思考。
-
决策下一步 :决定是继续调用工具还是给出最终答案。
-
循环往复 :这个过程可以多次迭代。
这就像一个人做复杂任务:旧方式是闷头按计划执行,新方式是每完成一步都停下来想想刚才的结果符合预期吗?要不要调整下一步?
整个过程中,模型并没有忘记前面做过什么。
那为什么大家都开始卷这个?
因为,这种"边思考边执行"的能力,几乎决定了模型能不能成为一个真正的 Agent。
Agent 的核心挑战是什么?是长任务。
长任务就意味着:
-
规划下一步;
-
根据工具返回结果调整策略;
-
记住尝试过什么;
-
避免重复错误;
-
在多轮交互中保持一致目标。
这些都依赖一个核心能力:你得能记住自己刚刚是怎么想的。
如果每次都从零开始思考,系统会陷入状态漂移(State Drift),计划难以延续,甚至频繁"自我打断"。
而 Interleaved Thinking 正是为解决这个痛点而生。
这项机制最早由 Anthropic 在 Claude 4 系列中提出,产品术语叫 Extended Thinking,Extended Thinking + Tool Use 组合能力起的正式名称叫 Interleaved Thinking,这种叫法在学术界、开发者社区也被广泛采用,像 MiniMax、vLLM 等工具平台都开始用这个名字来指代「一边思考、一边调用工具」的机制。

虽然 OpenAI 的 GPT-oss 版本和部分研究框架也尝试支持,但并未形成统一标准。
直到 MiniMax 发布 M2,这种状况才迎来根本性转变。
M2 不只是支持 Interleaved Thinking,而是首次将其作为 Agent 核心工作流进行结构性构建。
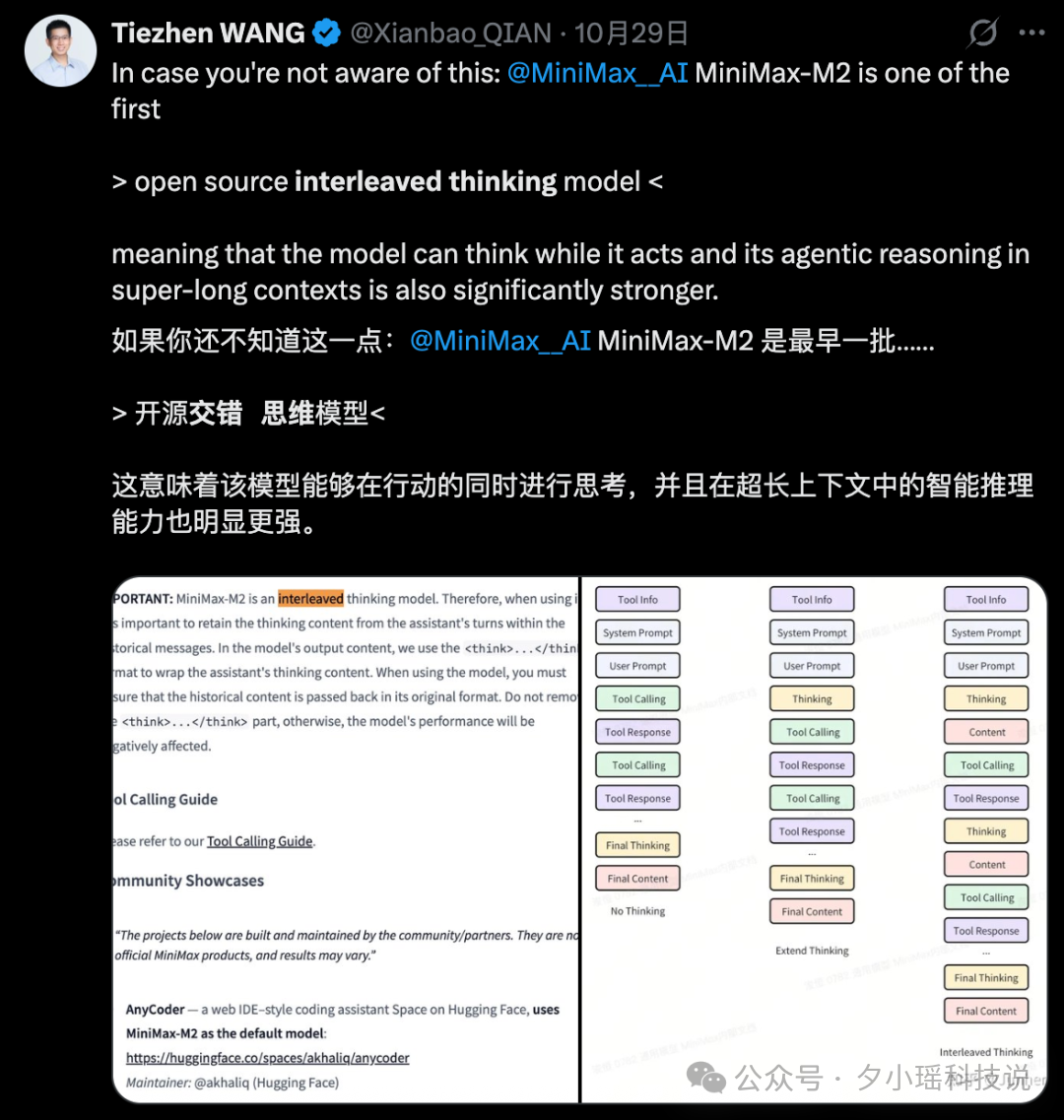
具体来说,M2 会在每一次工具调用前后都进行明确的推理步骤,而这些推理的内容不会丢失,而是被结构化保存在一个字段里,并自动带入下一轮。
这样的设计直接改变了以前常见的问题:模型查完工具结果后,不再能"续上"之前的思路,导致逻辑断裂、计划跳步、甚至重复犯错。
而在 M2 里,推理过程被完整保留下来,模型可以随时回看、更新和修正自己的判断,使得长流程任务的执行更加稳定、连贯。
这种设计,彻底打破了"每次调用都是一次重启"的传统范式,把推理链条首次变成了系统级结构。
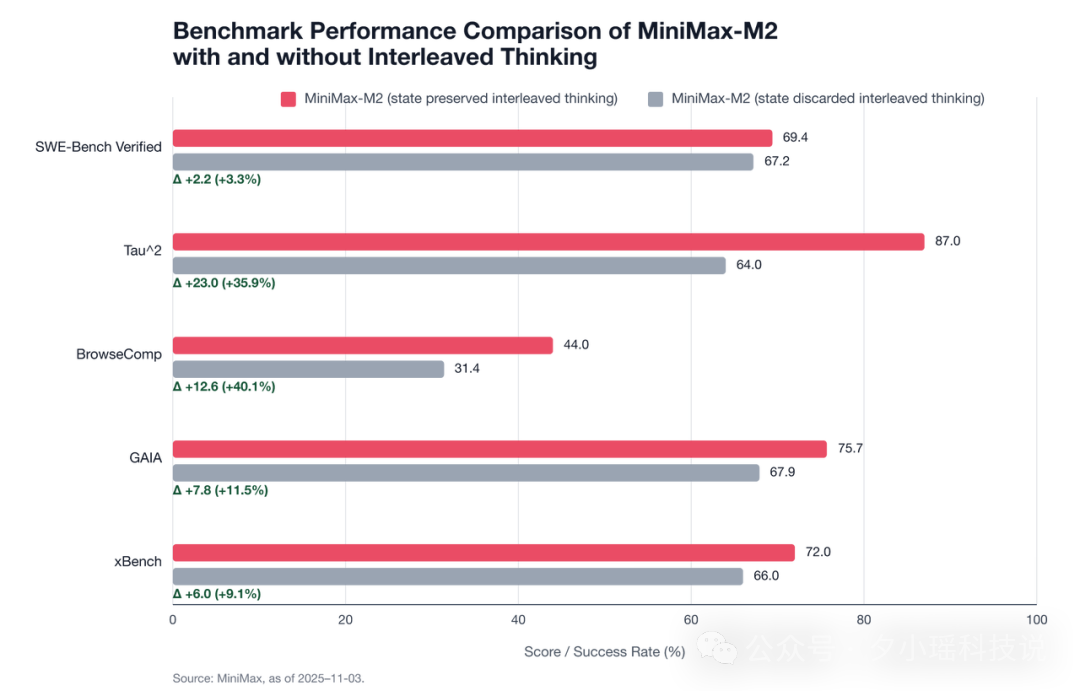
从 MiniMax 的实测结果看,这种"是否保留思维链"的差异,可不只是略有影响,而是直接决定了模型能不能用、稳不稳定:
-
在长流程逻辑任务 Tau² 中,开启 Interleaved Thinking 后,成功率从 64% 飙升至 87%,提升 +35.9%
-
在依赖网页信息处理与工具结合的 BrowseComp 任务中,提升 +40.1%
-
在多轮计划和状态传递要求较高的 GAIA、xBench 上,稳定提升分别为 +11.5% 和 +9.1%
-
哪怕在相对静态的代码修复任务 SWE‑Bench Verified 上,也有 +3.3% 的增长
这些任务覆盖了当前主流 Agent 应用的几乎所有核心方向:信息查找、多轮执行、工具控制、错误修复、推理链验证。一个共通点是:只要任务链长、工具多、状态复杂,Interleaved Thinking 就是硬门槛。
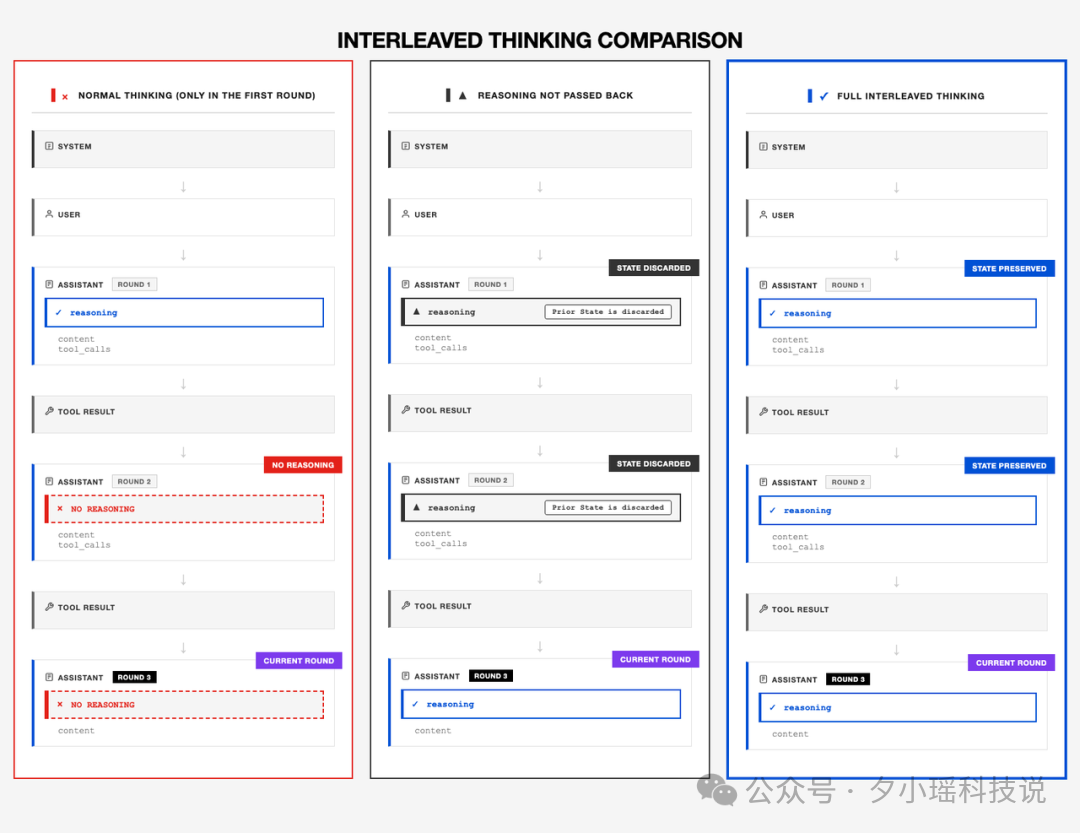
图示中你可以直观看到这个结构差异:
-
普通模型(左图)只在第一轮思考,后续工具调用中推理内容断档,状态丢失;
-
未正确实现回传机制的模型(中图)哪怕模型能生成推理块,也无法从接口层传入下一轮,依然断链;
-
而 M2 所构建的(右图),是从 API 到模型都支持完整链路的结构:思考-行动-回传-再思考,每一段状态都保留并持续演进。
这一步,看似只是多了一条回传路径,实则改变了模型的工作逻辑。
它让模型第一次具备了真正的连续意识**。**
MiniMax 怎么让它成为行业共识?
当 MiniMax 发布 M2 时,社区对 Interleaved Thinking 的支持几乎为零。
OpenAI 的 Chat API 不支持 reasoning 回传,Anthropic 的格式虽然有,但生态没人用。
MiniMax 团队为此干了三件关键的事:
-
开源 Mini-Agent,作为开发者实践标准参考实现(700+Star);
这是第一个完全实现 Interleaved Thinking 的开源 Agent 框架。
它用最小代码展示了完整的"思考-行动-反思"循环,让开发者一目了然。
-
推动生态联动
与 Kilo Code、Cline、RooCode、OpenRouter、Ollama 等平台联合,提交多项 PR,让这些第三方平台原生支持 Interleaved Thinking + Native Tool Call,并通过跨平台实测确保一致性。
-
建立标准语义与测试机制
在 API 层面定义了 reasoning_details、thinking_block 等字段格式。并以内部 Benchmark 验证不同实现的正确性,为行业提供了"可复现的标准"。
这一套动作下来,Interleaved Thinking 从一个理念变成了工程标准。
这套机制的意义,不止在技术层面。
就在本周的 AWS re:Invent 2025 大会上,MiniMax M2 被正式纳入 Amazon Bedrock 模型库,与 Google Gemma、NVIDIA Nemotron 等模型一同登场,成为登陆 AWS Bedrock 的中国模型之一(CEO直接开麦点名,排面拉满)。

在 MiniMax 的评论区,我看到这样一条留言:
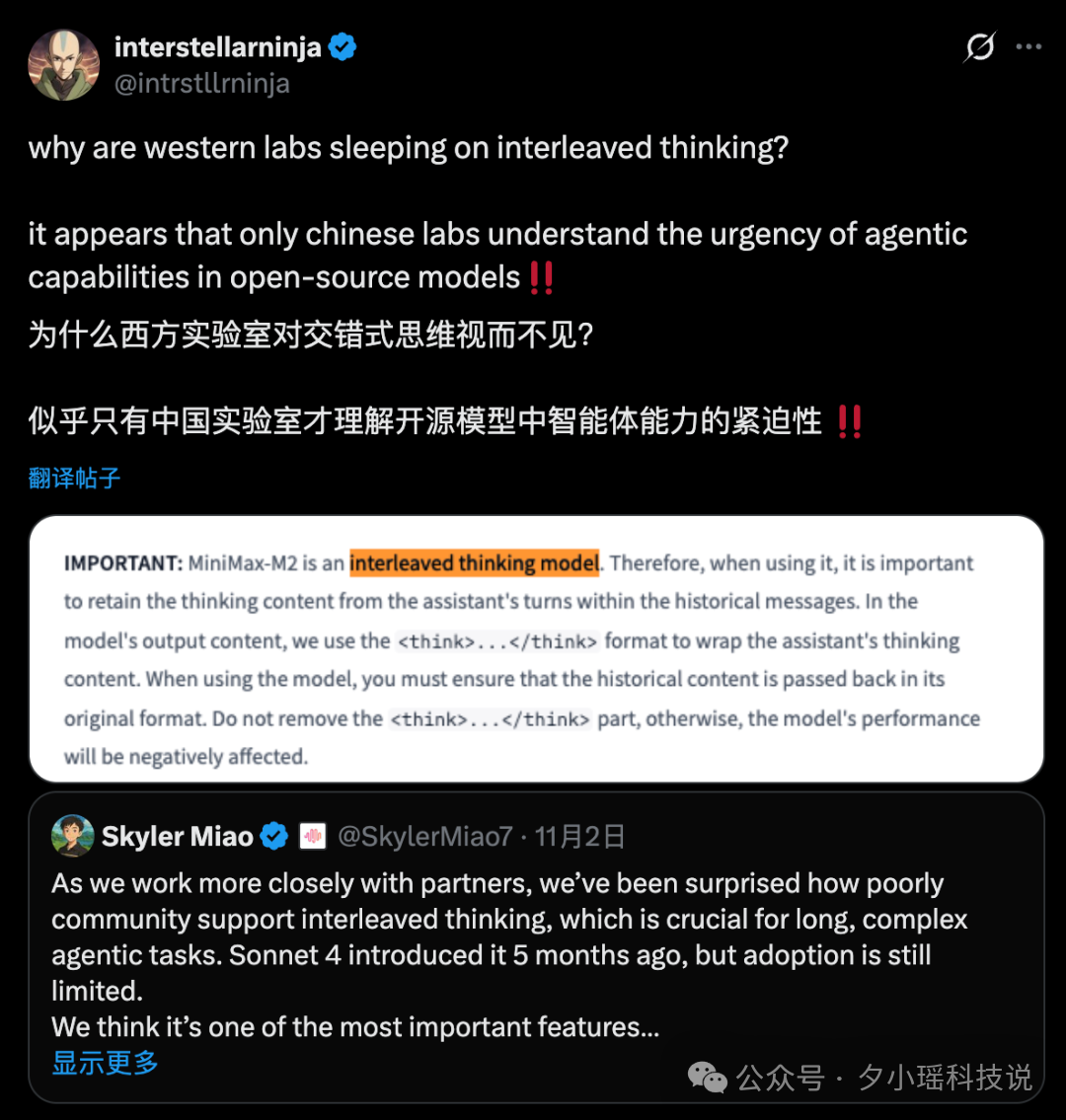
那一刻,我突然有点出神。
这个概念,最早是西方团队提出来的,但真正把它跑通、落地、做成体系的,却是中国的团队。
有点魔幻,也有点象征意味。
算力让 AI 更快,思维链让 AI 更稳。
而这一刻,国产 AI 已经率先想明白了。