目录
[1. 线程库](#1. 线程库)
[1.1 thread类的简单介绍](#1.1 thread类的简单介绍)
[1.2 线程函数参数](#1.2 线程函数参数)
[1.3 原子性操作库(atomic)](#1.3 原子性操作库(atomic))
[1.4 mutex](#1.4 mutex)
[2 异常](#2 异常)
[2.2 为什么需要处理错误???](#2.2 为什么需要处理错误???)
[2.3 c++异常概念](#2.3 c++异常概念)
[2.4 异常的使用](#2.4 异常的使用)
[2.5 异常安全](#2.5 异常安全)
[2.6 自定义异常体系](#2.6 自定义异常体系)
[2.7 c++标准库的异常体系](#2.7 c++标准库的异常体系)
[2.7 异常规范](#2.7 异常规范)
[2.8 异常的抛出和匹配规则](#2.8 异常的抛出和匹配规则)
[2.9 异常的优缺点](#2.9 异常的优缺点)
1. 线程库
声明:对于线程库的学习,是有关Linux系统编程的很多概念,建议先学我的Linux系统编程章节
1.1 thread类的简单介绍
没有线程库之前,我们如果想要编写一套多线程且可移植的代码,在不同平台下都能跑,就需要用到条件编译,因为在不同的平台,创建多线程的系统接口是不一样的
比如windows:CreateThread Linux:pthread_create
这时候需要用到条件编译,来区别不同的平台
c++11的线程库相当于帮我们封装好了条件编译,这使得我们在使用的时候摒弃掉底层原理,直接上手即可,代码可移植,跨平台
在C++11之前,涉及到多线程问题,都是和平台相关的,比如windows和linux下各有自己的接口,这使得代码的可移植性比较差。C++11中最重要的特性就是对线程进行支持了,使得C++在并行编程时不需要依赖第三方库,而且在原子操作中还引入了原子类的概念。要使用标准库中的线程,必须包含< thread >头文件。C++11中线程类

thread():这个是构造一个线程对象,但是没有关联任何线程函数,即没有启动任何线程
thread():构造一个线程对象,并关联线程函数fn,args为线程函数的参数
对于拷贝构造是删掉的,允许move移动构造
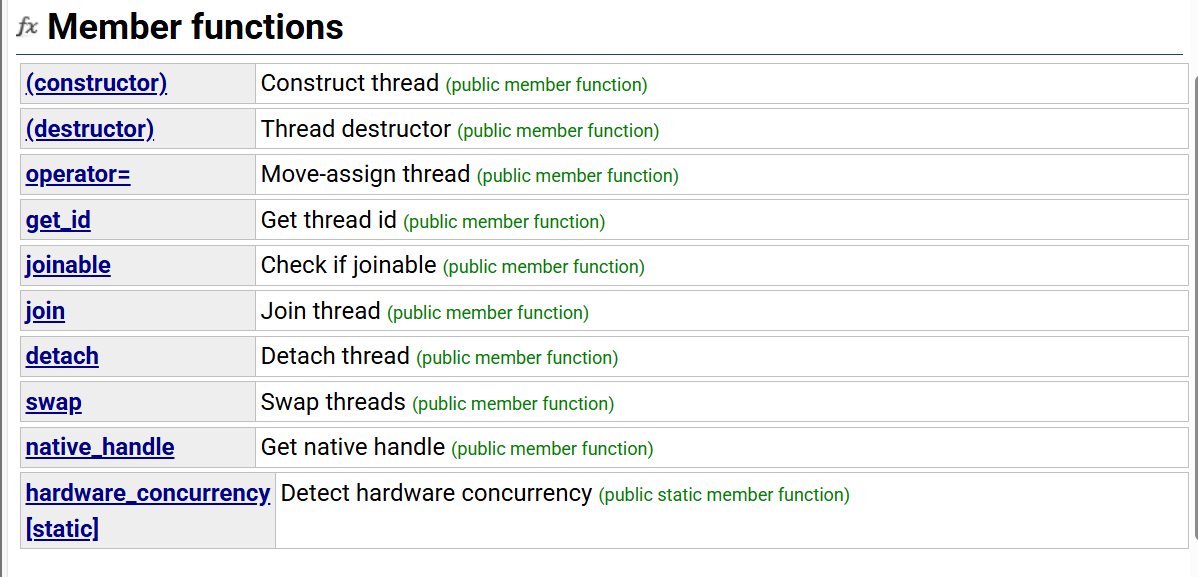
get_id():获取线程id,线程id是一个
joinable():线程是否还在执行,joinable代表的是一个正在执行中的线程
join():该函数调用后会阻塞主线程,当该线程结束后,主线程继续执行(注意多线程要join,否则主线程跑完了,子线程还在执行就会出错)
detach():在创建线程对象后马上调用,用于把被创建线程与线程对象分离开,分离的线程变为后台线程,创建的线程的死活就与主线程无关
注意:
1.线程是操作系统的一个概念,线程对象可以关联一个线程,用来控制线程以及获取线程的状态,这就相当于c++的封装,创建了一个类,用类对象来管理这个线程
2.当创建一个线程对象后,没有提供线程函数,该对象实际没有对应任何线程
get_id() 的返回值类型为 id 类型, id 类型实际为 std::thread 命名空间下封装的一个类,该类中包含了一个结构体
cpp
// vs下查看
typedef struct
{ /* thread identifier for Win32 */
void *_Hnd; /* Win32 HANDLE */
unsigned int _Id;
} _Thrd_imp_t;
主线程可以通过this_thread这个类对象来控制
3.当创建一个线程对象后,并且给线程关联线程函数,该线程就会被启动,与主线程一起运行,线程函数一般情况下可按照以下三种方式提供:
函数
防函数对象
lambda表达式
函数指针
(这些本质上都是具有函数的特性)
cpp
#include <iostream>
using namespace std;
#include <thread>
void ThreadFunc(int a)
{
cout << "Thread1" << a << endl;
}
class TF
{
public:
void operator()()
{
cout << "Thread3" << endl;
}
};
int main()
{
// 线程函数为函数指针
thread t1(ThreadFunc, 10);
// 线程函数为lambda表达式
thread t2([]{cout << "Thread2" << endl; });
// 线程函数为函数对象
TF tf;
thread t3(tf);
t1.join();
t2.join();
t3.join();
cout << "Main thread!" << endl;
return 0;
}-
thread类是防拷贝的,不允许拷贝构造以及赋值,但是可以移动构造和移动赋值,即将一个线程对象关联线程的状态转移给其他线程对象,转移期间不意向线程的执行。
-
可以通过joinable()函数判断线程是否是有效的,如果是以下任意情况,则线程无效
采用无参构造函数构造线程对象
线程对象的状态已经转移给其他线程对象
线程已经调用join或者detach结束
面试题:并发与并行的区别???
1.2 线程函数参数
线程函数的参数是以值拷贝的方式拷贝到线程栈空间中的 ,因此:即使线程参数为引用类型,在线程中修改后也不能修改外部实参,因为其实际引用的是线程栈中的拷贝,而不是外部实参
cpp
#include <thread>
void ThreadFunc1(int& x)
{
x += 10;
}
void ThreadFunc2(int* x)
{
*x += 10;
}
int main()
{
int a = 10;
// 在线程函数中对a修改,不会影响外部实参,因为:线程函数参数虽然是引用方式,但其实际引用的
//是线程栈中的拷贝
thread t1(ThreadFunc1, a);//注意这句是会报错的,因为你多线程拷贝是临时对象,也就是把a的临时对象 //给t1,t1接受的时候没有使用const,就会出错
t1.join();
cout << a << endl;
// 如果想要通过形参改变外部实参时,必须借助std::ref()函数
thread t2(ThreadFunc1, std::ref(a);
t2.join();
cout << a << endl;
// 地址的拷贝
thread t3(ThreadFunc2, &a);
t3.join();
cout << a << endl;
return 0
}对于t1:默认情况下传是会拷贝实参到线程栈,是拷贝之后的临时对象,不是原对象
对于t2:std::ref(a) 的作用是将 a 包装成 "引用包装器(std::reference_wrapper<int>)" ,告诉 std::thread:"不要拷贝 a,直接传递 a 的引用"。
对于t3:就是传递它的地址
注意:如果是类成员函数作为线程参数时,必须将 this 作为线程函数参数。
1.3 原子性操作库(atomic)
多线程最主要的问题是共享数据带来的问题**(即线程安全)**。如果共享数据都是只读的,那么没问题,因为只读操作不会影响到数据,更不会涉及对数据的修改,所以所有线程都会获得同样的数据。但是,当一个或多****个线程要修改共享数据时,就会产生很多潜在的麻烦。(在Linux中已经系统谈过了,这就是临界资源)
cpp
#include <iostream>
using namespace std;
#include <thread>
unsigned long sum = 0L;
void fun(size_t num)
{
for (size_t i = 0; i < num; ++i)
sum++;
}
int main()
{
cout << "Before joining,sum = " << sum << std::endl;
thread t1(fun, 10000000);
thread t2(fun, 10000000);
t1.join();
t2.join();
cout << "After joining,sum = " << sum << std::endl;
return 0;
}对于sum来说是全局变量,临界资源,执行++有三条语句,如果是多线程就会导致别的++还没来得及放回内存,别的线程取的是旧值,就会导致sum最后不是理想的结果
传统的解决方法:加锁(后面我们会重点讲解)
在这里可以通过原子性操作:也就是要么执行完成,要么不执行,没有中间态
cpp
#include <iostream>
#include <thread>
#include <atomic>
using namespace std;
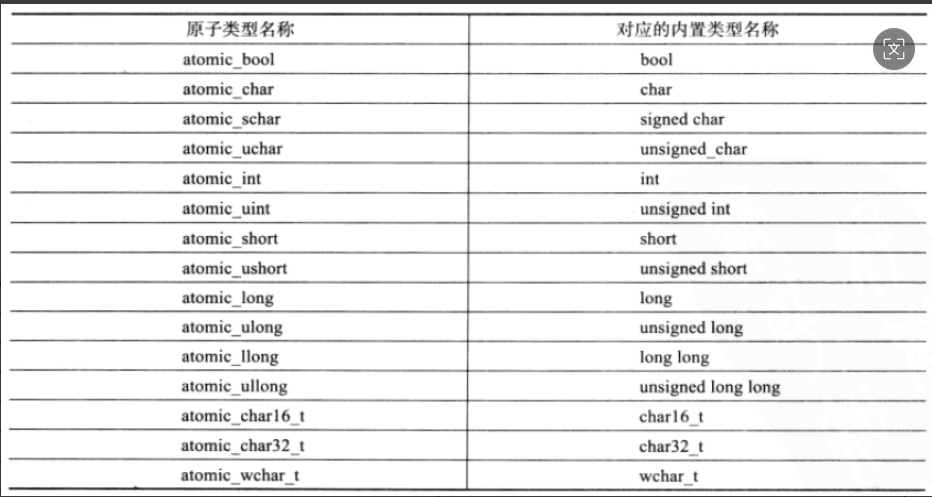
atomic_long sum{0};
//atomic<long> sum=0; 这个更好用,使用atomic<T>定义出需要的任意原子类型
void fun(size_t num)
{
for (size_t i = 0; i < num; ++i)
sum ++; // 原子操作
}
int main()
{
cout << "Before joining, sum = " << sum << std::endl;
thread t1(fun, 1000000);
thread t2(fun, 1000000);
t1.join();
t2.join();
cout << "After joining, sum = " << sum << std::endl;
return 0;
}这个原子操作能够执行:是因为硬件支持,CPU 提供了原子指令,保证单个操作的不可分割性;
还有语言层面c++进行了封装
扩展学习:CAS--->无锁编程
1.4 mutex
原子操作根本代替不了锁,因为原子操作仅仅针对单个变量或对象(c++20支持可平凡复制,自己了解),但对于语句块,复杂的多步操作/多个资源同步等情况原子操作根本无法保证多线程安全,只有加锁,对临界资源进行加锁才能保证多线程安全

不能拷贝构造,不能移动构造,拷贝显然不行怎么可以在拷贝出来一把锁,移动的话会导致原来持有锁的线程持个空锁,这些都是不允许的
所以为了保证锁实例与内核资源一一对应,维持锁的独占性和互斥语义,都是要禁掉拷贝和移动的
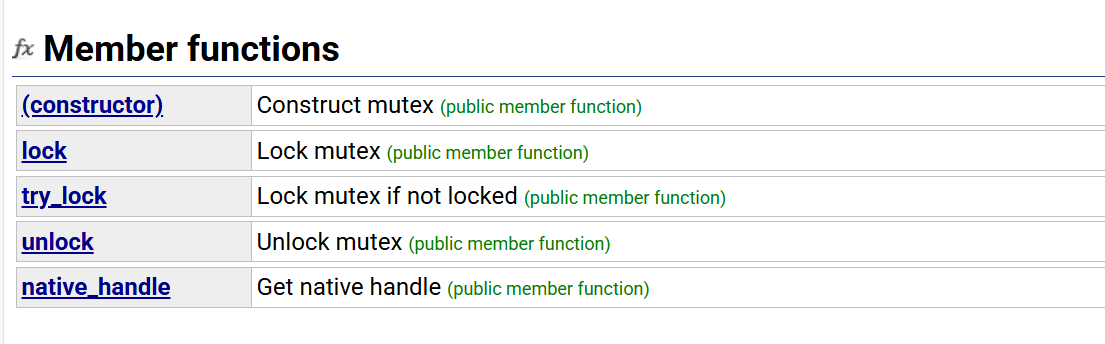
lock():上锁,锁住互斥量
unlock():解锁,释放对互斥量的所有权
try_lock():尝试锁住互斥量,如果互斥量被其他线程占有,则当前线程不会被阻塞
注意,线程函数调用lock()时,可能会发生以下三种情况:
--如果该互斥量当前没有被锁住,则调用线程将该互斥量锁住,直到调用 unlock之前,该线程一直
拥有该锁
--如果当前互斥量被其他线程锁住,则当前的调用线程被阻塞住
--如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock),因为会阻塞在再次lock那里,没有哪个线程能够释放
线程函数调用try_lock()时,可能会发生以下三种情况:
--如果当前互斥量没有被其他线程占有,则该线程锁住互斥量,直到该线程调用 unlock 释放互斥量
--如果当前互斥量被其他线程锁住,则当前调用线程返回 false,而并不会被阻塞掉
--如果当前互斥量被当前调用线程锁住,则会产生死锁(deadlock)
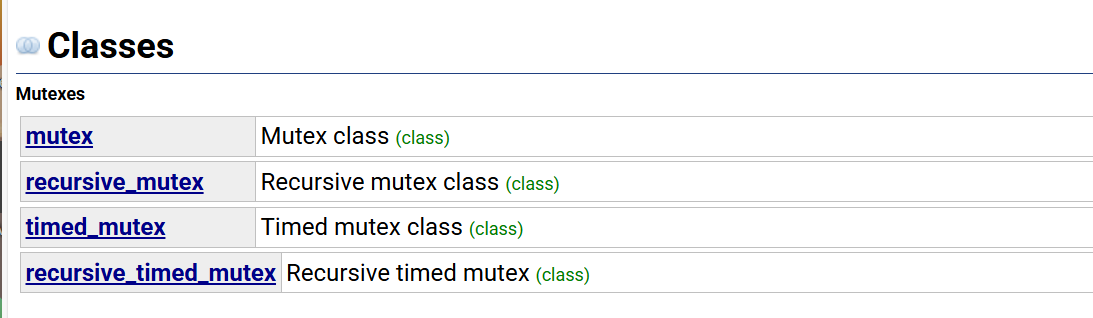
四种类型的锁,上面已经讲了mutex
recursive_mutex:这个是递归锁,也就是一个线程可以多次上锁,但释放的时候需要调用与该锁层次深度相同次数的unlock(),(mutex不行,刚刚已经讲过了,会发生死锁,因为同一个线程会一直阻塞在再次调用lock函数那里,导致所有的线程都无法unlock和lock),除此之外std::recusive_mutex的特性和std::mutex大致相同
timed_mutex:比mutex多了两个成员函数,try_lock_for(),try_lock_until()try_lock_for()
接受一个时间范围,表示在这一段时间范围之内线程如果没有获得锁则被阻塞住(与 std::mutex的 try_lock() 不同,try_lock 如果被调用时没有获得锁则直接返回 false),如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指定时间内还是没有获得锁),则返回 false。
try_lock_until()
接受一个时间点作为参数,在指定时间点未到来之前线程如果没有获得锁则被阻塞住,如果在此期间其他线程释放了锁,则该线程可以获得对互斥量的锁,如果超时(即在指定时间内还是没有获得锁),则返回false
recursive_timed_mutex:这个很明显就是递归加可等待一段时间的锁
1.5条件变量
C++11 的条件变量(std::condition_variable)是用来实现线程间的 "等待 - 通知" 同步机制------ 让一个线程等待某个条件满足,另一个线程在条件满足时通知等待的线程继续执行,常用于 "生产者 - 消费者""任务队列" 等场景。
核心作用:解决 "轮询浪费资源" 的问题
如果没有条件变量,线程要等待某个条件(比如队列非空),只能通过轮询(反复检查条件)实现,但轮询会持续占用 CPU 资源;而条件变量可以让线程主动阻塞(释放 CPU),直到条件满足时被唤醒,既实现了同步,又节省了资源。
基本用法(配合互斥锁)
条件变量必须和 ** 互斥锁(std::mutex)** 配合使用,核心接口是:
wait():线程阻塞,等待条件满足;notify_one():唤醒一个等待的线程;notify_all():唤醒所有等待的线程。
经典面试题,有两个线程,让其一个打印奇数,一个偶数,并且要求依次打印
如果不加以控制两个线程,一个打印奇数,一个打印偶数,就会出现竞争终端的情况,导致打印的乱
如果单单通过一个锁是否可以实现?没法实现谁先打印,一开始的打印可能是1也可能是0
可以通过两个锁和两个条件变量,一套管一个线程
cpp
#include <condition_variable>
#include <mutex>
#include <thread>
#include <iostream>
using namespace std;
int main() {
int n = 100;
mutex mtx1, mtx2;
condition_variable cv1, cv2;
thread t1([&]() {
for (int i = 0; i < n; i += 2) {
cout << this_thread::get_id() << ":" << i << endl;
cv2.notify_one();
unique_lock<mutex> lock1(mtx1);
cv1.wait(lock1); // 或配合条件谓词:cv1.wait(lock1, [&](){ ... });
}
// 最后一次通知,避免t2等待
cv2.notify_one();
});
thread t2([&]() {
for (int i = 1; i < n; i += 2) {
unique_lock<mutex> lock2(mtx2);
cv2.wait(lock2); // 或配合条件谓词:cv2.wait(lock2, [&](){ ... });
cout << this_thread::get_id() << ":" << i << endl;
cv1.notify_one();
}
});
t1.join();
t2.join();
return 0;
}这里的unique_lock看下一节
2 异常
异常是面向对象语言处理错误的一种方法
2.1.c语言传统的处理错误的方式及缺陷
-
终止程序,如****assert(),exit(),信号中断,缺陷:用户难以接受。如发生内存错误,除0错误时就会终止程序。
-
返回错误码,缺陷:需要程序员自己去查找对应的错误。如系统的很多库的接口函数都是通过把错误码放到errno中,表示错误
-
C 标准库中setjmp和longjmp组合。这个不是很常用,了解一下
实际中C语言基本都是使用返回错误码的方式处理错误,部分情况下使用终止程序处理非常严重的错误。
缺陷:
a. 拿到错误码,需要查找错误表,才知道是什么错误(比如http协议,404是啥错误等)
b. 如果一个函数是通过返回值拿数据,发生错误时就很难处理,比如一个函数所有的值都可能是数据,那你要返回什么表示错误???
c. 如果多层次的调用函数,当最底层的函数发生错误的时候,要层层返回错误码,整个处理很难受,要一层一层的接受错误然后再向上返回
d. errno是全局变量,对于多线程来说可能会覆盖
注意:
错误码是不会终止程序的,进程还是会继续进行下去
exit是正常退出,是你站在进程的角度,主动调用导致,主动控制让进程退出的
os发出的信号是异常退出,是被动的,os直接让进程结束的
(进程退出码是结束之后能够查看的,是标志进程是否正常执行完成的标志)
(错误码和退出码是两个概念)
面对以上的缺陷,c++提出了异常来解决
2.2 为什么需要处理错误???
cpp
namespace wcf {
int div(int m, int n) {
return m / n;
}
}
int main() {
cout << wcf::div(3, 0);
return 0;
}对于这种发生/0错误
一般来说编译期间是不会出错的
只有在运行期间会出错,不同的os有不同的处理方式
- 在 Windows(MSVC 编译器):会触发 "浮点异常"(但整数除以 0 属于整数异常),程序直接崩溃,错误提示为 "除以零";
- 在 Linux(GCC/Clang 编译器) :整数除以 0 会触发 **
SIGFPE信号 **(浮点异常信号,但实际是整数除零),操作系统会终止程序,输出类似Floating point exception (core dumped)。
但程序当中最好不要出现这种被动终止的,最好是程序主动
| 错误等级 | 定义(示例) | 处理策略 | 核心目标 |
|---|---|---|---|
| 致命错误 | 无法恢复的底层错误(如内存分配失败、数据库核心连接中断、除零、数组越界) | 主动调用 exit/assert/abort 终止程序 |
避免数据损坏、资源泄漏 |
| 严重错误 | 业务逻辑失败(如文件打开失败、参数非法、网络临时断开) | 返回错误码 / 抛异常,上层重试 / 降级处理 | 进程不终止,业务可降级 |
| 轻微错误 | 预期内的小问题(如用户输入格式错、请求超时) | 捕获错误,提示用户 / 重试,程序继续运行 | 进程稳定,不中断核心逻辑 |
最终目标是让程序可控,而不是失控崩溃
2.3 c++异常概念
异常是一种处理错误的方式,当一个函数发现自己无法处理的错误时就可以抛出异常,让函数的直接或间接****的调用者处理这个错误。
**throw:**当问题出现时,程序会抛出一个异常。这是通过使用 throw关键字来完成的。
**catch:**在您想要处理问题的地方,通过异常处理程序捕获异常.catch关键字用于捕获异常,可以有多个catch进行捕获。
try: try 块中的代码标识将被激活的特定异常,它后面通常跟着一个或多个 catch 块。
如果有一个块抛出一个异常,捕获异常的方法会使用 try和 catch关键字。try 块中放置可能抛出异常的代码,try 块中的代码被称为保护代码。使用 try/catch 语句的语法如下所示:
cpp
try
{
// 保护的标识代码
}catch( ExceptionName e1 )
{
// catch 块
}catch( ExceptionName e2 )
{
// catch 块
}catch( ExceptionName eN )
{
// catch 块
}这里有两个很好的例子,vector中的\[\]和at,两个的处理错误方式就不一样,一个是assert,一个是抛异常
cpp
#include <vector>
#include <iostream>
using namespace std;
int main() {
vector<int>v{ 1,2,3,4,5 };
for (int i = 0; i <=v.size(); i++) {//这里故意写<=,所以会越界访问
//cout << v[i] << " ";
cout<<v.at[i]<<" ";
}
cout << endl;
return 0;
}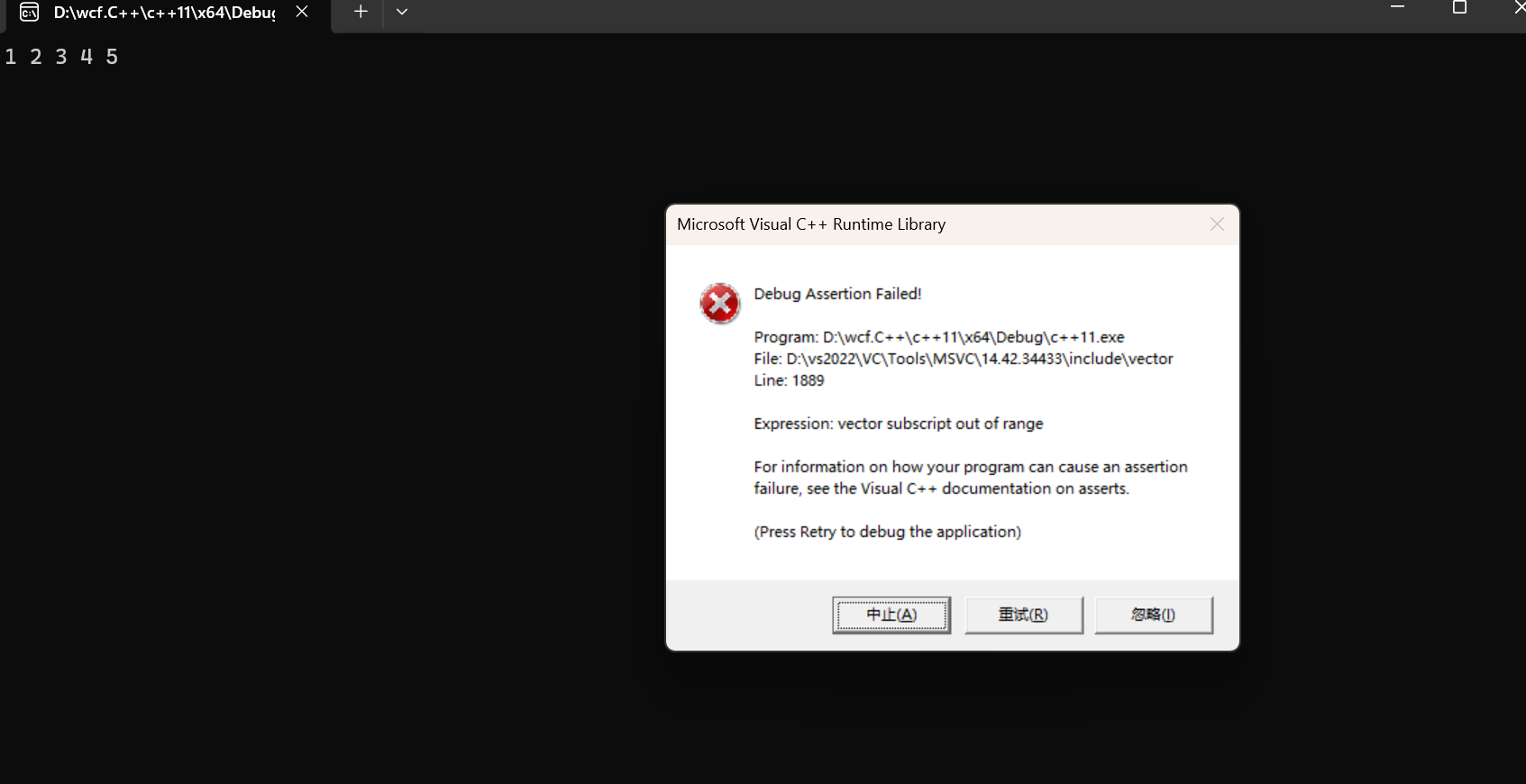
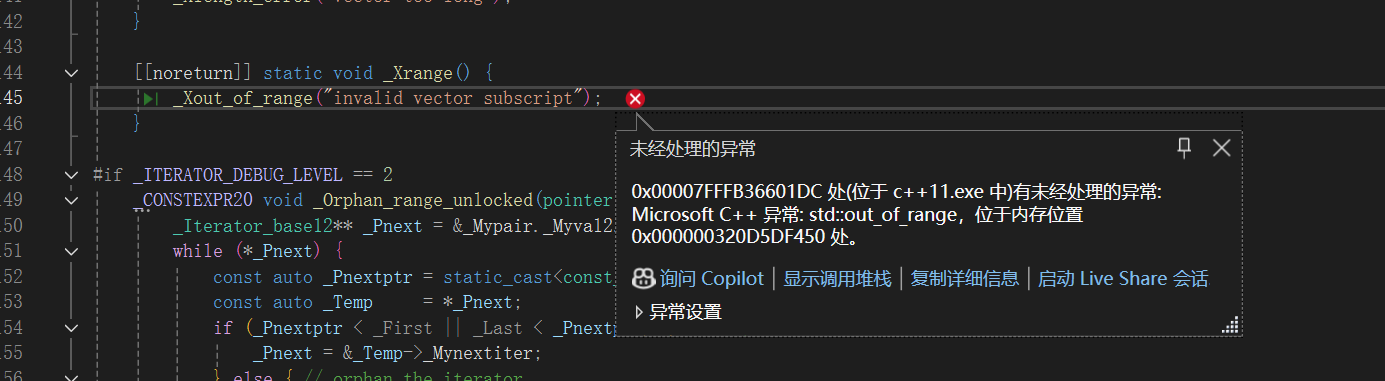
一个是直接assert,一个是抛异常(非法访问了某个子部分)
2.4 异常的使用
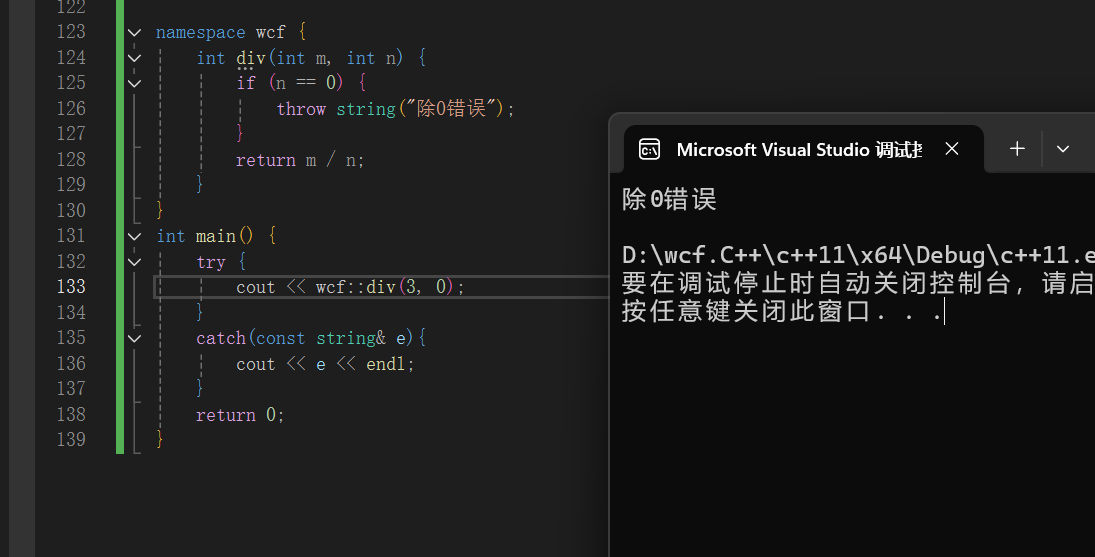
throw就是抛异常的意思,可以抛出任意类型,比如这里是string
try包含的是这一段代码可能会有抛异常,所以需要括起来
catch是捕捉异常,必须配合try出现,可以有多对,因为抛异常可能有多个,catch捕捉的类型要和throw抛出的类型一致,否则捕获异常失败,如果异常没有被捕获,进程就会异常终止
- 若回溯到
main函数仍无匹配的catch;- 系统会调用
std::terminate()函数(默认调用std::abort());std::abort()向进程发送SIGABRT信号(Linux 下信号号 6),操作系统强制终止进程 ------ 这属于异常退出 (而非exit的正常退出)。
以上的执行流是,执行try里面的语句,然后执行到div函数,div出现/0,就会进入if语句,然后throw,return m/n不会执行 ,然后出来之后因为有异常,所以进入catch,执行catch的内容
重点注意:这个throw跑出来的异常会拷贝的,就相当于一个函数传值返回一样,比如这个string对象,出了作用域会自动销毁,所以它会先拷贝,然后把这个拷贝的临时对象抛出去,所以这里采用了const才可以绑定临时对象(临时对象具有常性,属于右值),这个临时对象的生命周期延长跟catch语句块一样,如果不加const就会出错,当然你也可以选择string e,不使用引用,值接受,那就会多一层拷贝
结论:
1.throw可以抛出任意类型的对象,且是一个临时对象
2.接受的时候catch接受
3.异常会打乱外面的执行流
但是对于一些语句,如果没有捕捉到异常,就会异常终止
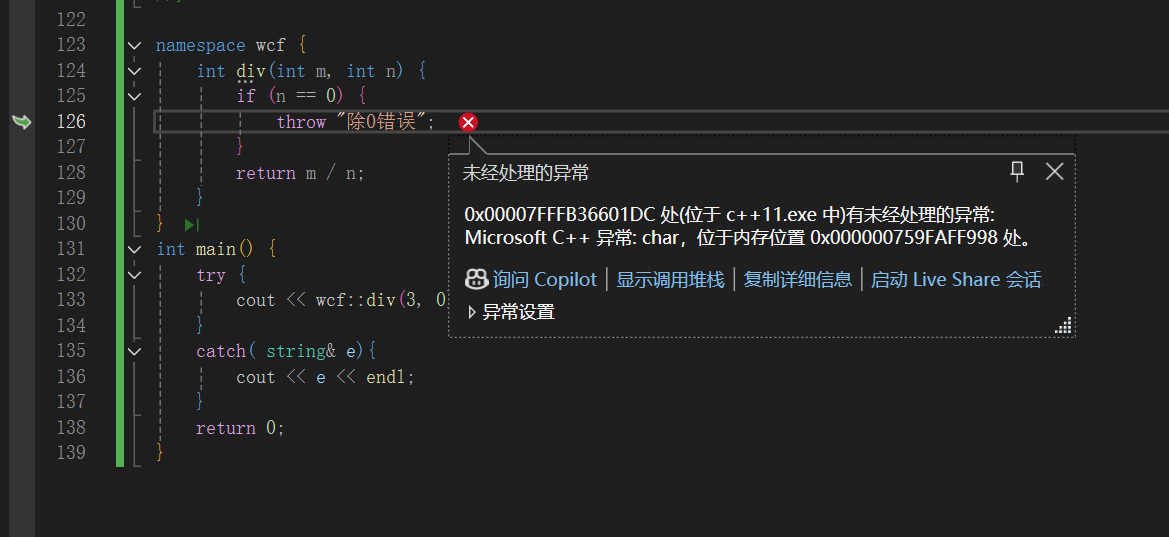
比如这里我抛出去的是const char*类型,但是没有一个catch能够捕捉这个异常,所以导致程序异常终止
catch(...){
//catch语句
}
//这个的意思是捕捉没有匹配的任意类型的异常,避免异常没捕获时程序终止了
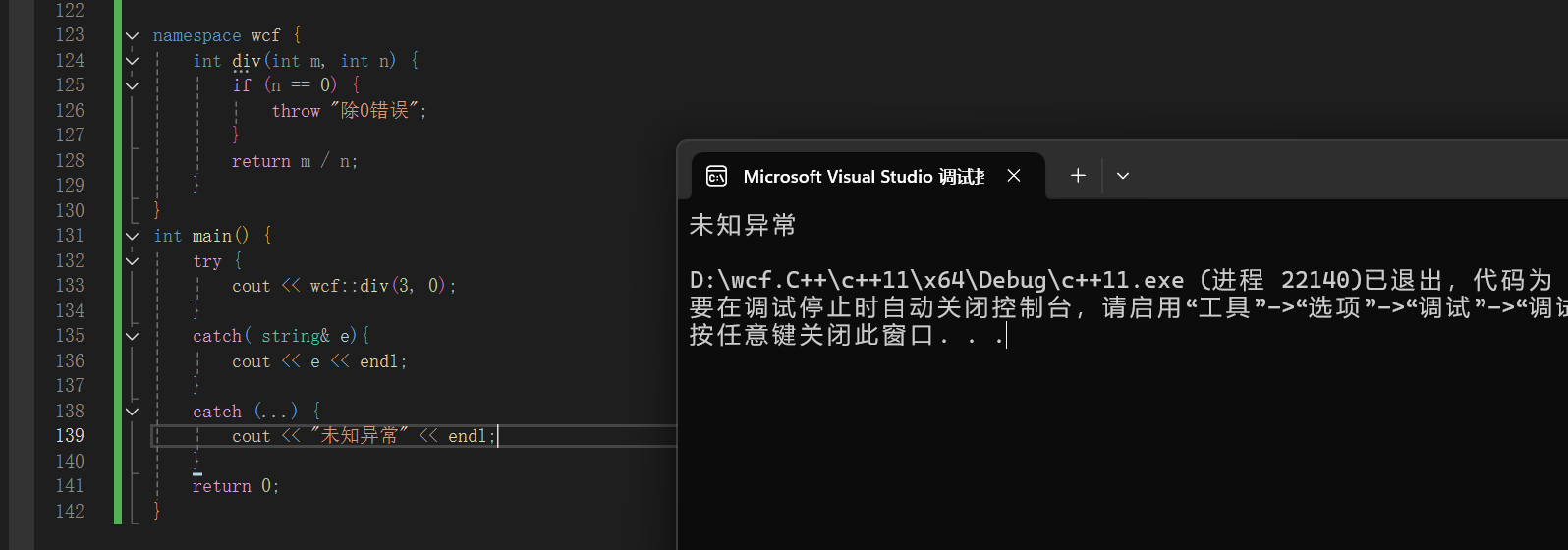
2.5 异常安全
由于异常会导致执行流改变
假设在new和delete之间发生异常,会导致delete没有执行,从而导致内存泄漏,这就是异常安全
cpp
double Division(int a, int b)
{
// 当b == 0时抛出异常
if (b == 0)
{
throw "Division by zero condition!";
}
return (double)a / (double)b;
}
void Func()
{
// 这里可以看到如果发生除0错误抛出异常,另外下面的array没有得到释放。
// 所以这里捕获异常后并不处理异常,异常还是交给外面处理,这里捕获了再
// 重新抛出去。
int* array = new int[10];
try {
int len, time;
cin >> len >> time;
cout << Division(len, time) << endl;
}
catch (...)
{
cout << "delete []" << array << endl;
delete[] array;
throw;
}
// ...
cout << "delete []" << array << endl;
delete[]array;
}
int main()
{
try
{
Func();
}
catch (const char* errmsg)
{
cout << errmsg << endl;
}
return 0;
}throw后面没有跟任何东西的意思是:捕捉这个异常后,先处理catch里面的内容,即delete释放资源,然后throw重新抛出这个异常(除0错误)
构造函数完成对象的构造和初始化 , 最好不要 在构造函数中抛出异常,否则 可能导致对象不完整或没有 完全初始化
析构函数主要完成资源的清理 , 最好不要 在析构函数内抛出异常,否则 可能导致资源泄漏 ( 内存泄漏、句柄未关闭等)
C++ 中异常经常会导致资源泄漏的问题,比如在 new 和 delete 中抛出了异常,导致内存泄漏,在 lock 和unlock之间抛出了异常导致死锁, C++ 经常使用 RAII 来解决以上问题,关于 RAII 我们智能指针这节进行讲解。
2.6 自定义异常体系
小dem不需要抛异常,大业务大公司绝对需要使用异常,那对于很多公司都会自定义自己的异常体系进行规范的异常管理,否则一个项目当中,我压根不知道对方抛什么类型的异常,对于捕获的人是个灾难,应该捕获什么样的数据,在哪捕获?,导致很乱很杂,所以实际中都会定义一套继承的规范体系,这样大家抛出的都是继承的派生类对象,捕获一个基类就可以(继承多态)
https://blog.csdn.net/Laydya/article/details/148145002
https://blog.csdn.net/Laydya/article/details/148176755
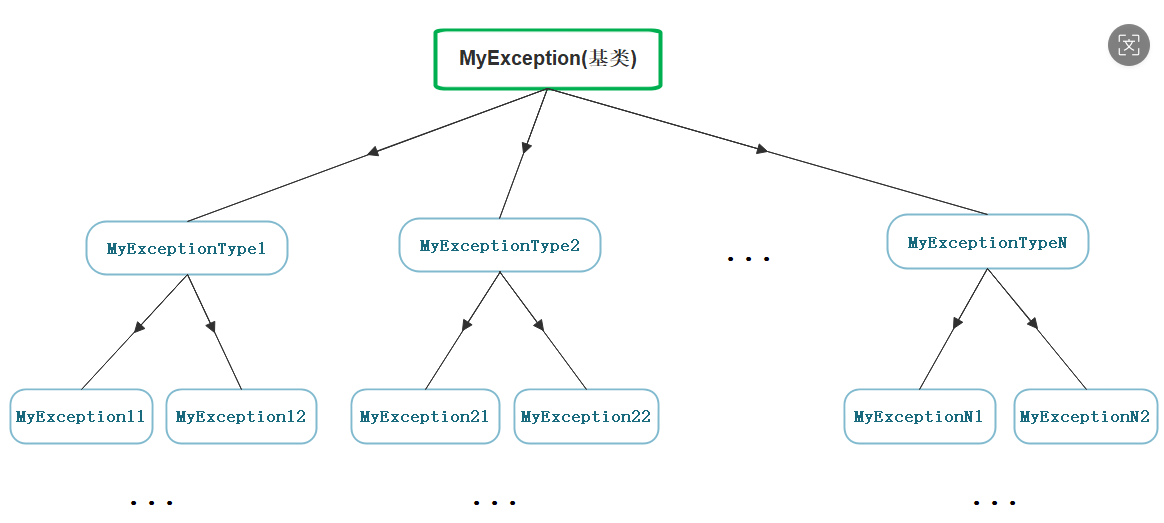
简单来说就是公司指定了一个基类:基类中包含错误id,错误描述(有时候还包含错误栈帧)
如果使用异常你必须去建一个派生类去继承基类,然后重写它的纯虚函数
捕捉异常的时候catch(基类&),这样抛的派生类就可以被捕获,此时实现了多态,传什么对象就调用它的函数即可
cpp
// 服务器开发中通常使用的异常继承体系
class Exception
{
public:
virtual void what()=0;//纯虚函数,用来描述_errmsg
protected:
string _errmsg;
int _id;
//list<StackInfo> _traceStack;
// ...
};
class SqlException : public Exception
{};
class CacheException : public Exception
{};
class HttpServerException : public Exception
{};
int main()
{
try{
// server.Start();
// 抛出对象都是派生类对象
}
catch (const Exception& e) // 这里捕获父类对象就可以
{ e.what();//直接调用描述函数就知道是啥错误了
}
catch (...)
{
cout << "Unkown Exception" << endl;
}
return 0;
}
这个是c++实现的异常,在头文件<exception中>,可以看到它的基类的what函数就是虚函数,所以后面的只要重写,然后实现多态即可
2.7 c++标准库的异常体系
C++ 提供了一系列标准的异常,定义在 中,我们可以在程序中使用这些标准的异常。它们是以父子类层次结构组织起来的,如下所示:
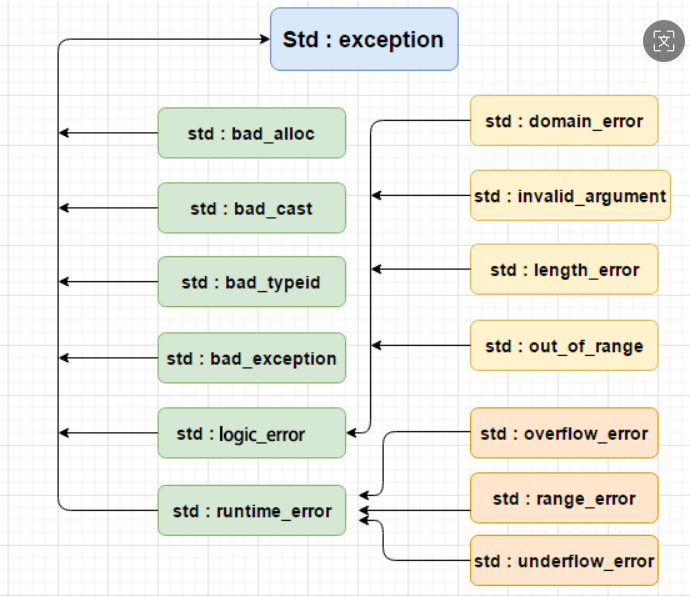
最常用的是bad_alloc、invalid_argument、out_of_range
C++的体系太乱了,实际上公司都是会自定义一套的
2.7 异常规范
-
异常规格说明的目的是为了让函数使用者知道该函数可能抛出的异常有哪些。 可以在函数的后面接throw(类型),列出这个函数可能抛掷的所有异常类型。
-
函数的后面接throw()或noexcept,表示函数不抛异常。
-
若无异常接口声明,则此函数可以抛任何类型的异常
cpp
// 这里表示这个函数会抛出A/B/C/D中的某种类型的异常
void fun() throw(A,B,C,D);
// 这里表示这个函数只会抛出bad_alloc的异常
void* operator new (std::size_t size) throw (std::bad_alloc);
// 这里表示这个函数不会抛出异常
void* operator new (std::size_t size, void* ptr) throw();
void* operator new (std::size_t size, void* ptr) noexcept;这个规范一般大家都不遵守,因为太麻烦了,c++11的语法也没有强制规定必须要加,因为要向前兼容前面的,否则直接导致c++98编的代码直接跑不过去
2.8 异常的抛出和匹配规则
-
异常是通过抛出对象而引发 的,该对象的类型决定了应该激活哪个catch的处理代码。
-
被选中的处理代码 是调用链中与该对象类型匹配且离抛出异常位置最近的那一个。
-
抛出异常对象后,会生成一个异常对象的拷贝,因为抛出的异常对象可能是一个临时对象,所以会生成一个拷贝对象,这个拷贝的临时对象会在被catch以后销毁。(这里的处理类似于函数的传值返回)
-
catch(...)可以捕获任意类型的异常,问题是不知道异常错误是什么。
-
实际中抛出和捕获的匹配原则有个例外,并不都是类型完全匹配,可以抛出的派生类对象,使用基类捕****获,这个在实际中非常实用
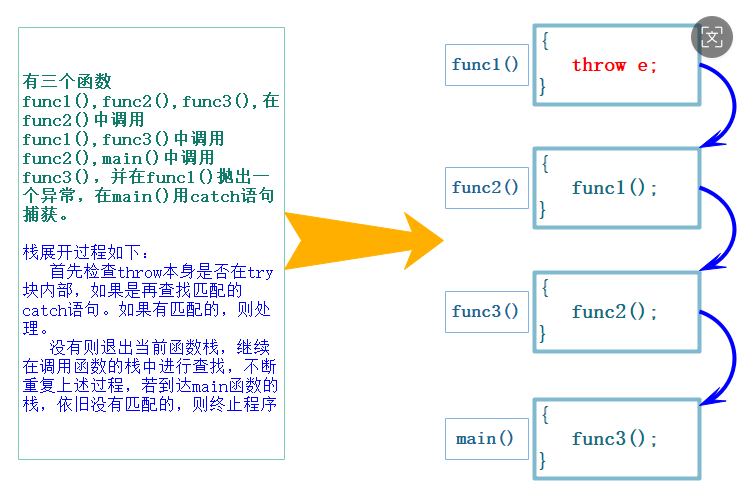
这里我们就没有谈过第二点,也就是它会调用离他最近的catch,之前c语言的痛点就是有很多的函数,在最底层的函数出错,返回错误码,就会一层一层向上返回,处理麻烦
这里的意思就是我们只要在最外层有一个catch即可,这里最底层的函数出错,他会自动寻找最近的catch,如果本层没有就一直返回,直到main,main里面还没有就会异常终止进程
在函数调用链中异常栈展开匹配原则
- 首先 检查 throw 本身是否在 try 块内部,如果是再查找匹配的 catch 语句 。如果有匹配的,则调到 catch的地方进行处理。
- 没有匹配的 catch 则退出当前函数栈,继续在调用函数的栈中进行查找匹配的 catch 。
- 如果到达 main 函数的栈,依旧没有匹配的,则终止程序 。上述这个沿着调用链查找匹配的 catch 子句的过程称为栈展开 。所以实际中我们最后都要加一个 catch(...) 捕获任意类型的异常,否则当有异常没捕获,程序就会直接终止。
- 找到匹配的 catch 子句并处理以后,会继续沿着 catch 子句后面继续执行。
2.9 异常的优缺点
优点
-
异常对象定义好了,相比错误码的方式可以清晰准确的展示出错误的各种信息 ,甚至可以包含堆栈调用的信息,这样可以帮助更好的定位程序的bug。(清晰的包含错误信息,这个是解决c语言的a缺陷的,因为你要查表,我直接what就行,并且封装成一个类,里面包含很详细的信息)
-
部分函数使用异常更好处理,不方便使用错误码方式处理。比如T& operator\[\]这样的函数,如果pos越界了只能使用异常或者终止程序处理,没办法通过返回值表示错误。(这个是解决c语言的b缺陷的,我可以通过抛异常而不是返回值进行错误处理)
-
返回错误码的传统方式有个很大的问题就是,在函数调用链中,深层的函数返回了错误,那么我们得层层返回错误,最外层才能拿到错误,使用异常仅仅需要在最外层捕获即可(这个是解决c语言的c缺陷的,可以通过最外层异常捕获即可)
-
很多的第三方库都包含异常,比如boost、gtest、gmock等等常用的库,那么我们使用它们也需要使用异常。
-
很多测试框架都使用异常,这样能更好的使用单元测试等进行白盒的测试。
缺点
-
异常会导致程序的执行流乱跳,并且非常的混乱,并且是运行时出错抛异常就会乱跳。这会导致我们跟踪调试时以及分析程序时,比较困难。
-
异常会有一些性能的开销。当然在现代硬件速度很快的情况下,这个影响基本忽略不计。
-
C++没有垃圾回收机制,资源需要自己管理。有了异常非常容易导致内存泄漏、死锁等异常安全问题。 这个需要使用RAII来处理资源的管理问题。学习成本较高。
-
C++标准库的异常体系定义得不好,导致大家各自定义各自的异常体系,非常的混乱。
-
异常尽量规范使用,否则后果不堪设想,随意抛异常,外层捕获的用户苦不堪言。所以异常规范有两点:一、抛出异常类型都继承自一个基类。二、函数是否抛异常、抛什么异常,都使用 func()throw();的方式规范化。
总结:异常总体而言,利大于弊,所以工程中我们还是鼓励使用异常的。另外OO的语言基本都是用异常处理错误,这也可以看出这是大势所趋