文章目录
- [一. Redis中的常用数据结构与编码方式](#一. Redis中的常用数据结构与编码方式)
- [二. Redis的单线程模型](#二. Redis的单线程模型)
-
- [1. 工作原理](#1. 工作原理)
- [2. Redis是单线程模型为什么还这么快?](#2. Redis是单线程模型为什么还这么快?)
- [三. string类型](#三. string类型)
-
- [1. get和set](#1. get和set)
- [2. flushall](#2. flushall)
- [3. mset和mget](#3. mset和mget)
- [4. setNX, setEX, psetEX](#4. setNX, setEX, psetEX)
- [5. incr, incrby](#5. incr, incrby)
- [6. decr, decrby, incrbyfloat](#6. decr, decrby, incrbyfloat)
- [7. append](#7. append)
- [8. getrange](#8. getrange)
- [9. setrange](#9. setrange)
- [10. strlen](#10. strlen)
- [11. string编码方式](#11. string编码方式)
- [12. string类型的应用场景](#12. string类型的应用场景)
一. Redis中的常用数据结构与编码方式
这里我们再次强调, 这里对于value的不同数据结构的讨论, 而对于key来说, 只有string类型, 同时Redis在实现这些数据结构的时候, 在底层源码上会有特殊的优化, 来达到节省时间/空间的效果, 意味着数据类型只是Redis承诺给你的, 但内部的编码方式却不一定是和那些常见数据结构一样, 外表还是你眼熟的外表, 内部却可能早已不是你熟知的模样
1. string -> 类似于Java中的string
2. hash -> 类似于Java中的hashMap, 只是在Redis中value的类型又是一对键值对结构的数据, 这里value中的key叫做field
3. list -> 类似于Java中的List
4. set -> 类似于Java中的set
5.zset -> 有序集合, 相当于里面除了存储成员member之外, 还需要存储一个权重score, 底层又经过一系列优化达到权重越大的优先级越高
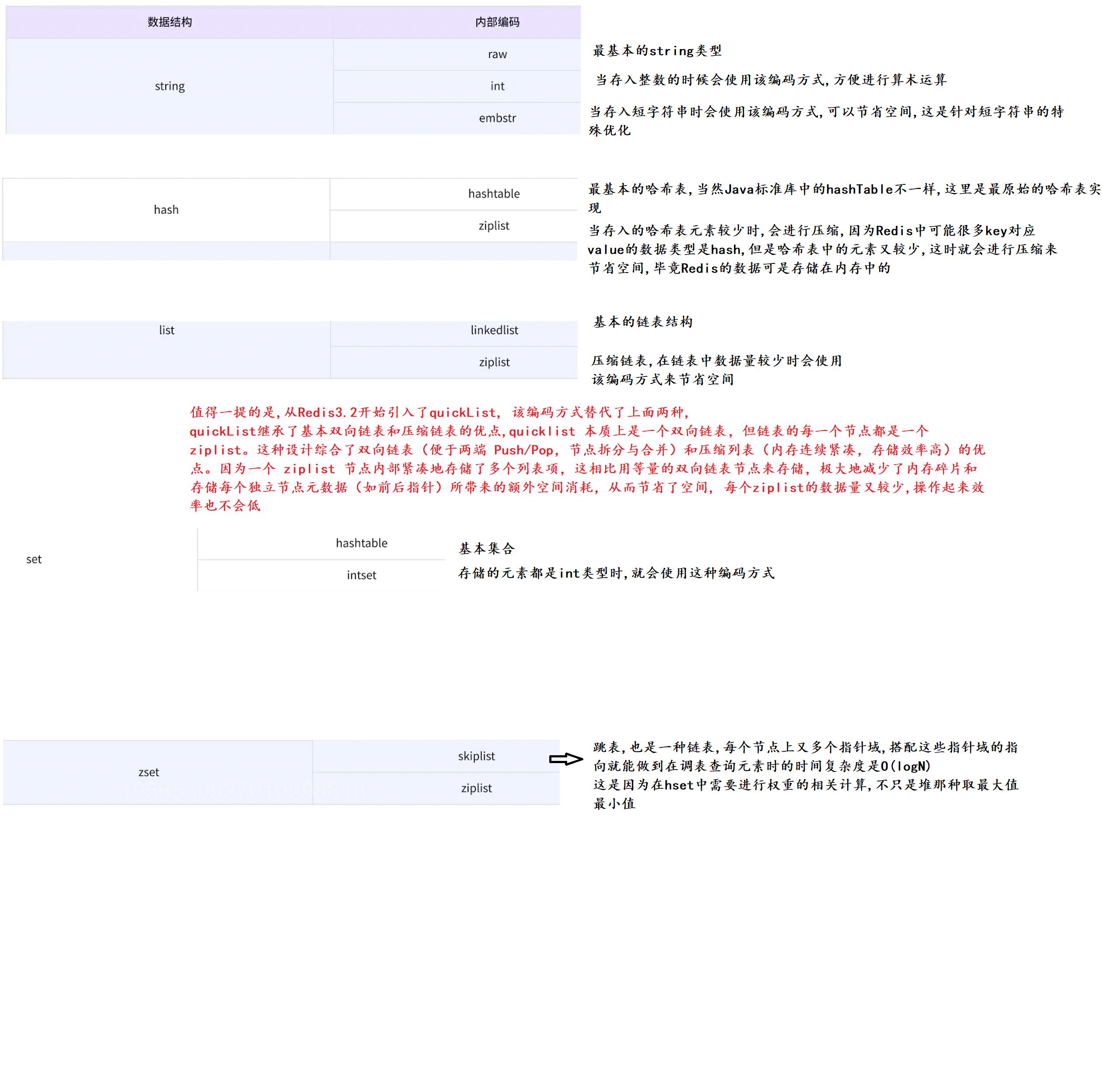
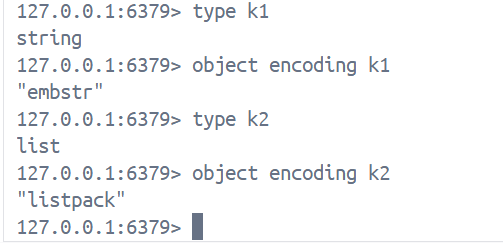
object encoding key用来查询当前key所用的编码方式
二. Redis的单线程模型
1. 工作原理
这里我们说的单线程模型指的是Redis中的核心业务逻辑, 处理所有的指令与请求时是单线程的, 但是在Redis服务器内部处理网络IO还是用的多线程, 也正因为Redis核心业务逻辑耗时比较短, 效率比较高, 不太吃CPU资源, 因此一个线程也能应付, 这就很好的避免了多线程引起的线程安全问题, 当多个客户端发送请求时, 会先将请求加入队列, 服务器再从队列中去取出任务来进行, 整个过程相当于串行执行
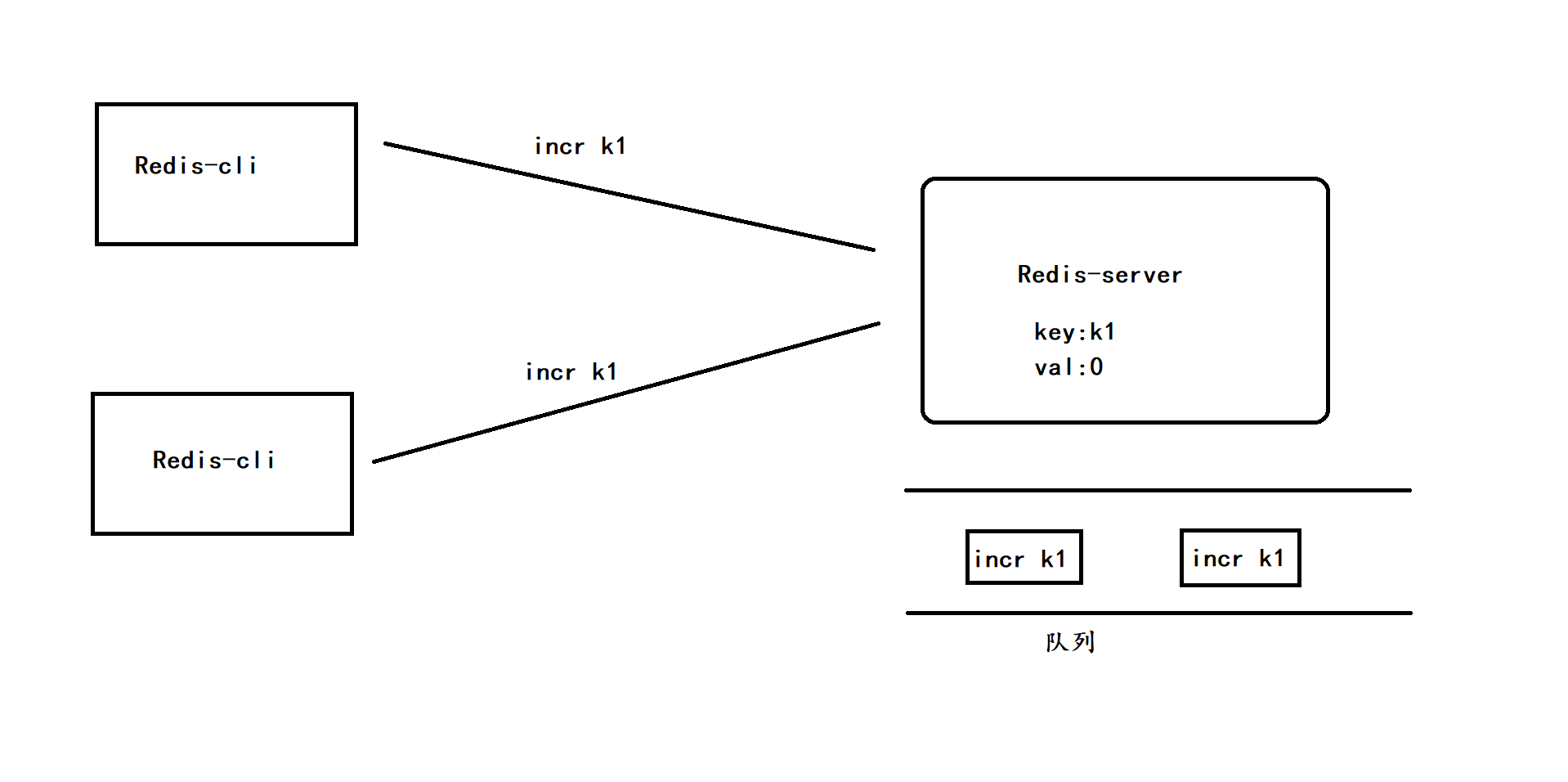
incr key这里我们又学到了一个新命令, incr表示自增的意思
2. Redis是单线程模型为什么还这么快?
关于Redis快的特性, 前面我们已经叙述过, 这里我们再次具体讲解一下, 因为这个还是太重要了, 当然这里的快是跟MySQL/Oracle这样的关系型数据库相比的
1. Redis操作内存, 操作内存的读写比硬盘的读写快了好几个数量级, 这也是快的主要原因
2. Redis中的核心业务逻辑比较简单, 就是简单的操作内存, 相比之下关系型数据库的业务逻辑复杂了不少
3. Redis单线程模型避免了不必要的线程竞争开销, 且每个操作都是短平快的, 不太消耗CPU资源, 引入多线程对性能提升反而不大, 甚至会因为解决多线程之间的安全问题而造成不必要的开销
4. Redis在处理网络IO的时候, 使用了epoll这样的IO多路复用机制
下面简单介绍一下epoll, 在我们学习TCP时, 服务器每服务一个新客户端都要给这个客户端建立一个socket, 但在大部分时候, 这些socket数据传输不是很频繁, 甚至是静默状态, 如果采用传统的每个socket分配一个线程, 就会很占用系统资源, 因此IO多路复用就是一个线程通过epoll同时监视多个socket, 当某个socket有IO事件(如数据到达、可写等)发生时,应用程序调用 epoll_wait() 函数并阻塞等待,内核会在有事件发生时唤醒该函数并返回就绪的 socket 列表, 应用程序再进行处理,而不是让应用程序为每个socket都维护一个阻塞等待的线程
三. string类型
Redis的字符串是直接按照二进制格式存储的, 也就不涉及到编码转换, 意味着啥都能存! 但Redis字符串类型存储的最大空间是512M, 当然这也是它快的原因, 你要往Redis存的数据都是大数据, 那它想快也快不了~
1. get和set
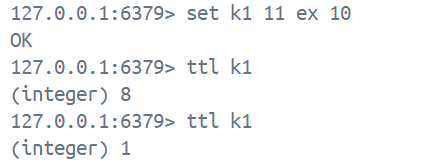
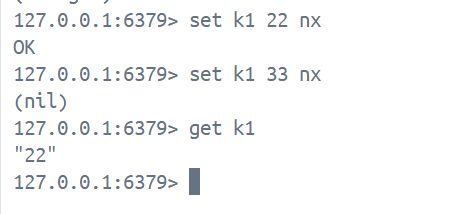
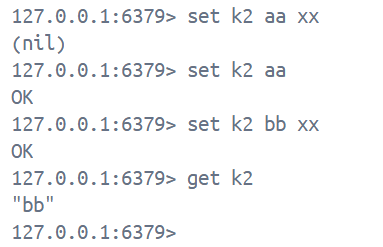
set key value [ex seconds | px milliseconds] [nx | xx]1. 上方命令的作用是既设置key和value又设置过期时间,同时设置更新条件, ex 表示秒级, px表示毫秒级, nx表示如果key不存在则可以设置, 创建新的键值对, 并设置过期时间(如果设置了过期时间的话), key存在则不可设置, 返回nil, xx表示如果key存在则不可以设置, 返回nil, key存在则可以设置, 并更新key中的value和过期时间(如果设置了过期时间的话)
2. \[\] 表示可有可无, 加不加都行
3. | 表示'或者'的意思, 多选一
4. \[\] 和 \[\] 之间可以同时存在
2. flushall
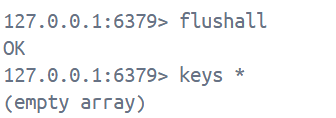
flushall清除Redis中所有的键值对, 简称'删库', 这是个极其危险的操作, 因此只在学习阶段用用就好了, 工作中可以忘了
3. mset和mget
mset key value [key value...]
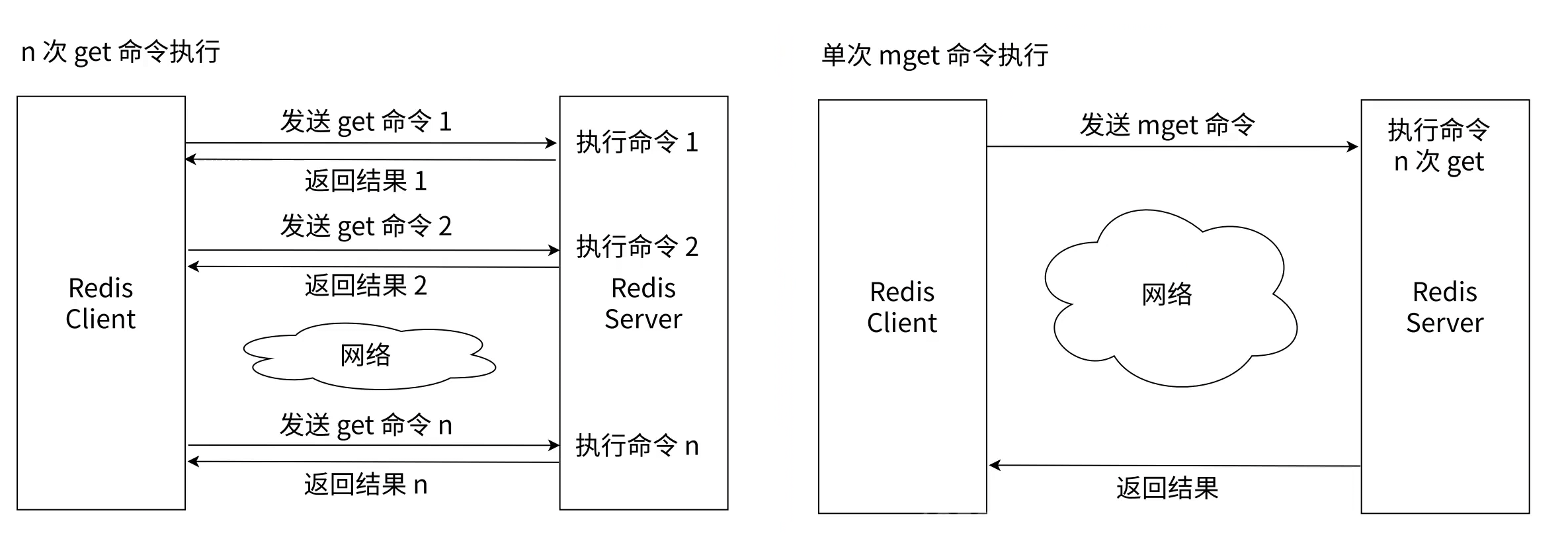
mget key [key...]批量设置键值对和读取value, 时间复杂度是O(N), 这里的N指的是键值对的数量, 每个操作是O(1)的, N个数据就是O(N)
mset和mget 命令极大的节省了需要插入/读取多个键值对时的网络IO开销, 毕竟网络开销比操作内存的开销大了好几个数量级

4. setNX, setEX, psetEX
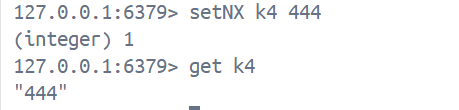
setNX key val
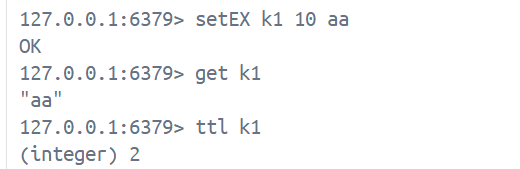
setEX key seconds value
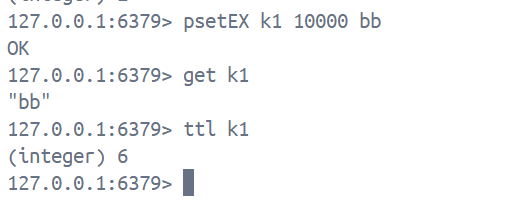
setPX key seconds value分别是set命令的另一种变形, 可以分别在key不存在的时候使用, 设置key的时候直接设置过期时间
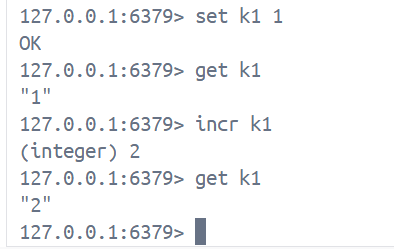
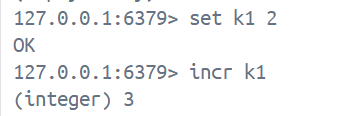
5. incr, incrby
incr key
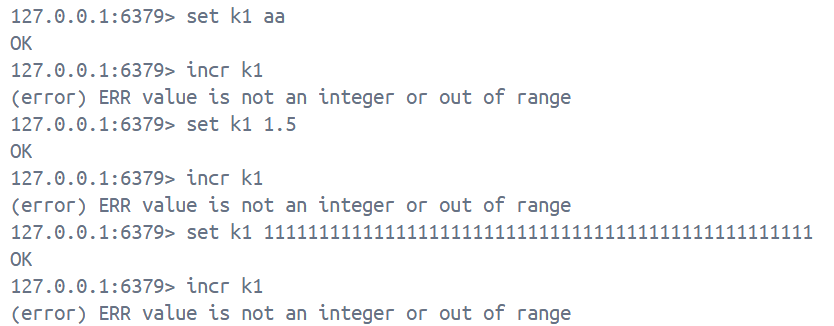
incrby key num1. incr key是让key对应的value值自增1, 返回值是自增后的值, 这里需要注意value值必须是整数类型, 且不能超过64个比特位, 否则就会报错
2. incrby key increment 让key对应的value值 + n, 设置多少就加多少, 返回值是相加后的值, 注意事项与上方一样
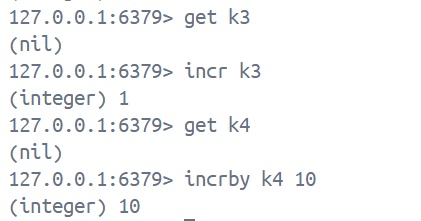
3. 这里我们需要注意的一个点: 当使用incr/incrby命令时, 如果key不存在, 则key默认的value是0
4. incrby 可以用来相加负数, 来实现减法的效果, 当然Redis为了设计更符合人类直觉, 更人性化, 还是提供了相应的自减命令


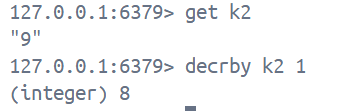
6. decr, decrby, incrbyfloat
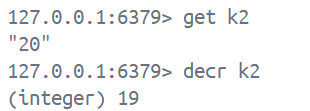
decr key
decyby key num
incrbyfloat key num1. decr 为给key对应的value进行 -1 操作, 返回值是自减后的值, 注意事项与特性与上方incr一致
2. decyby 为给key对应的value进行 -n 操作, 返回值是相减后的值, 注意事项与特性与上方incrby一致
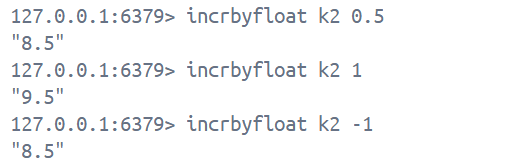
3. incrbyfloat 用来操作小数, 可进行小数之间的相加与相减, 具体值自己设定, 返回值是相加/相减后的值, 注意事项和特性与上面一致
7. append
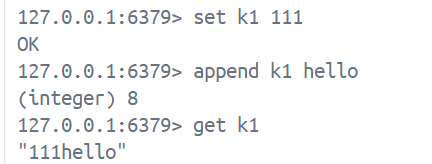
append key value1. 如果key已经存在, 并且value是一个string类型, 那么在key的value后面进行字符串拼接, 时间复杂度是O(1), 如果key不存在, 效果和set一致, 返回值是拼接后的字符串长度
2. 当然redis也可以拼接汉字, 只不过存储的是字节
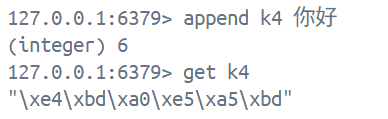
redis-cli --raw我们可以在启动Redis客户端的时候后面加上--raw, Redis在读取value的时候就会尝试翻译我们所存储的汉字
8. getrange
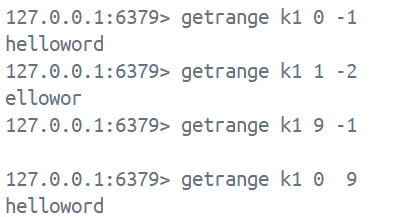
getrange key start end按照指定范围截取字符串, 类似于Java中的substring, 不同的是在Redis中支持负数下标, 即用负数表示倒数, -1表示len-1, 倒数第一个, 超过范围的偏移量还会根据string长度去调整, 同时需要特别注意的是, Redis中的范围是前闭后闭的, 单位是字节
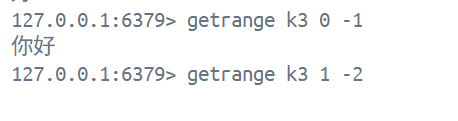
但如果字符串中存储的是汉字, 就需要按照具体的编码方式来整个截取, 如果截取范围不对, 可能会导致截取出来的结果不尽人意
9. setrange
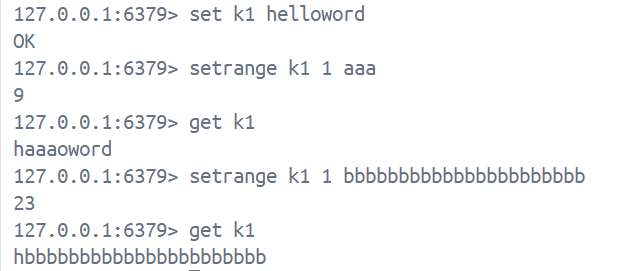
setrange key offset valueoffset 是偏移量, 表示要从第几个字节开始进行替换, 其中替换的范围是value的长度, 返回值是修改后字符串的长度, 当key对应的value不存在的时候, Redis会自动补充一个字节的字符串用'\x00'表示
10. strlen
strlen key获取当前key所对应的字符串的长度, 单位是字节, value必须是string类型, 否则会报错

11. string编码方式
1. raw 一般的编码方式, 底部持有一个字节数组, 字符串长度较大时, 用该编码
2. embstr 压缩字符串, 字符串长度较短时, 用该编码, 同时当存储的数据是小数时, 也是用改编码方式, 这就意味着进行小数的算术运算的时候, 要先转化为小数完成运算后再转化为压缩字符串
3. int 当value值全是整数时, 用该编码, 方便进行算术运算, 改int类型是8个字节, 相当于Java中的long

12. string类型的应用场景
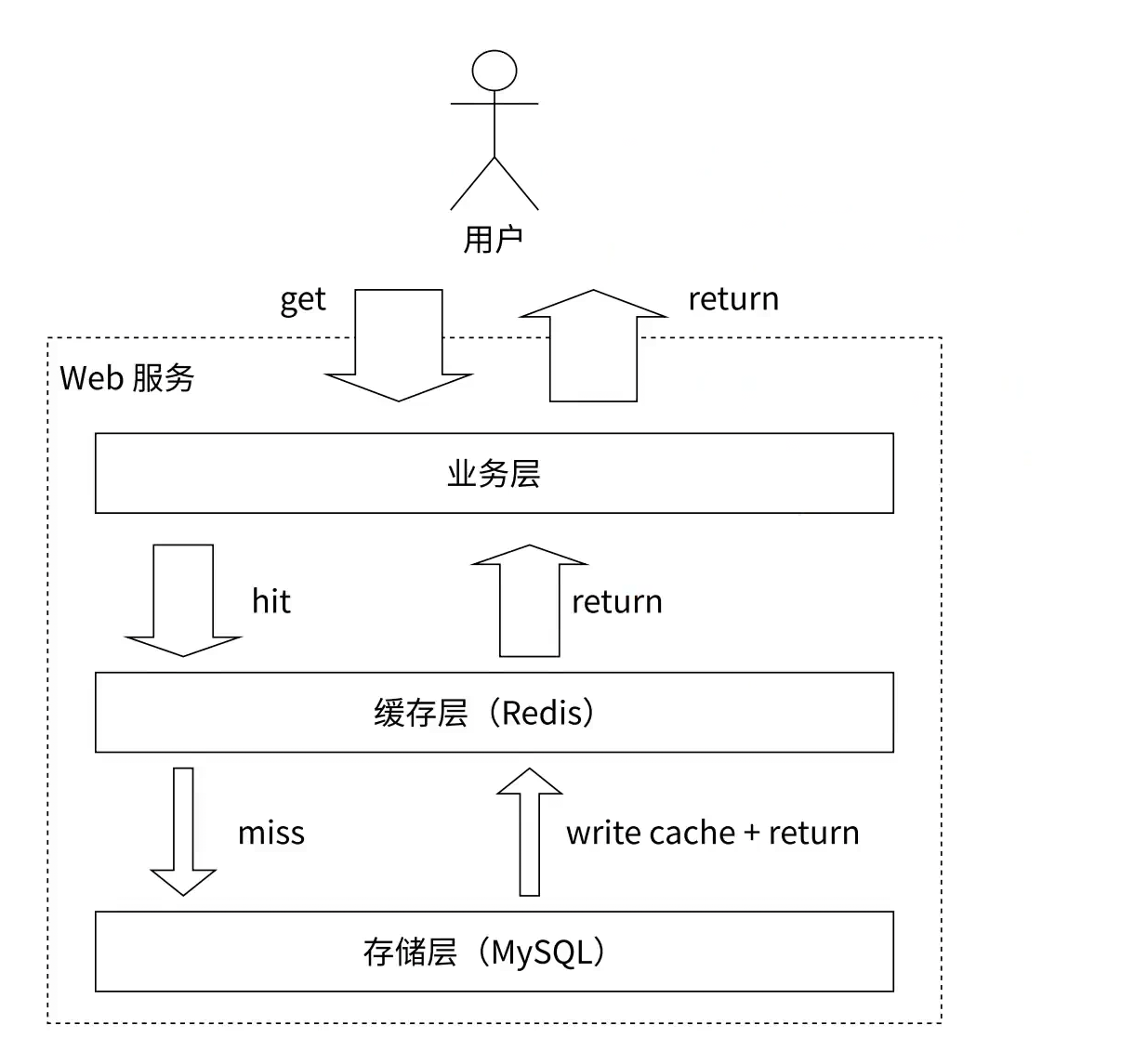
1. Redis再业务场景中常用于作为缓存, 当请求达到服务器上时, 会先从Redis中查询, 如果Redis中存在那么直接返回数据, 如果不存在再去MySQL中查询, 然后同步缓存中的数据
缓存中存储什么呢?
我们知道Redis操作的内存, 空间较小, 所以Redis中存储的一般是热点数据, 关于热点数据有两种解释: ①查询十分频繁且重复的数据 ②最近一段时间查询的数据当然为了防止Redis中的数据随着时间推移越积越多, 所以第一种方法是在存储数据的时候会设置过期时间, 到过期时间自动清除数据, 第二种方法是Redis在内存不足的时候也提供了内存淘汰机制 会把一部分键值对清除(根据具体业务来设置不同的淘汰策略)
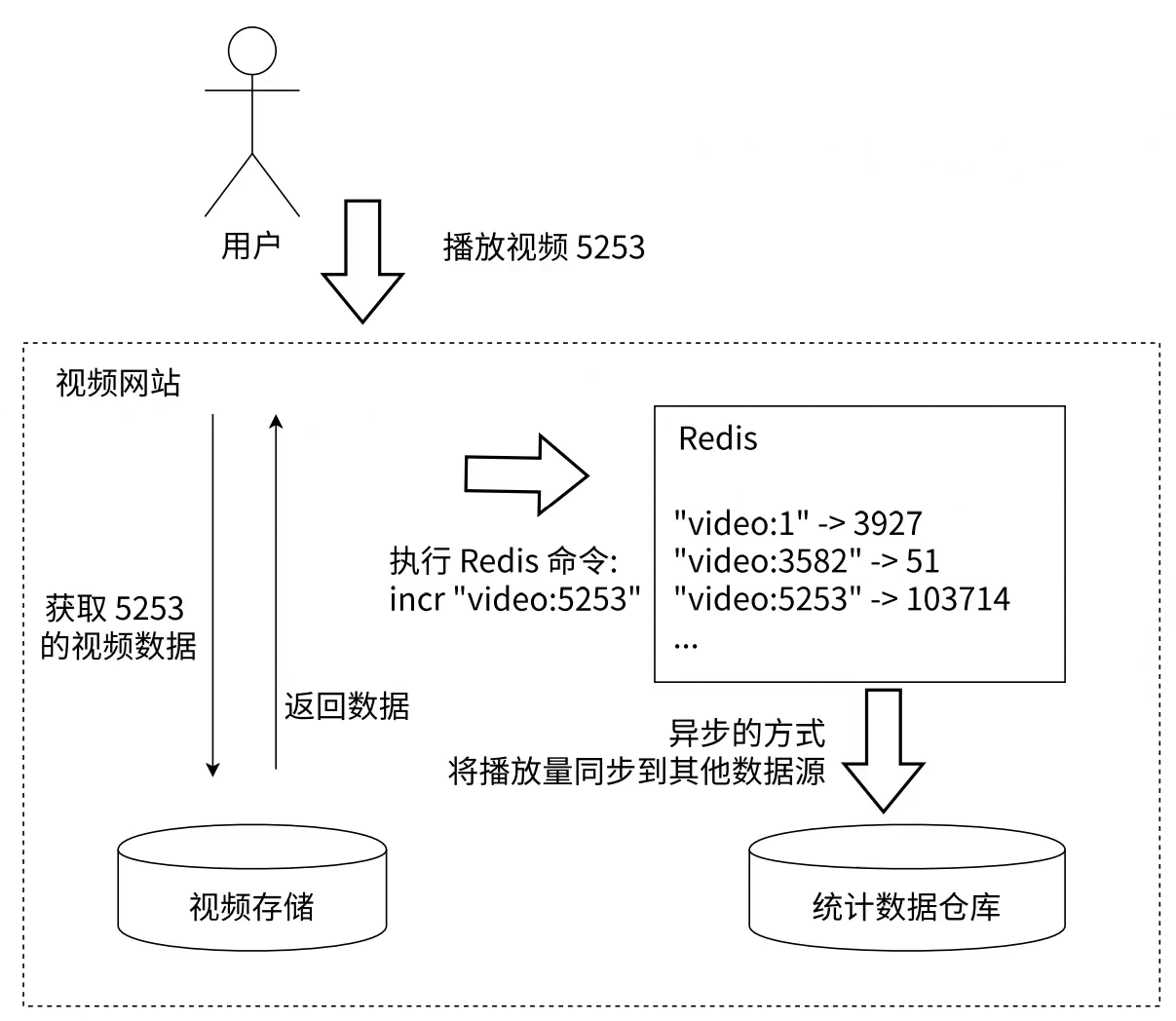
2. 计数场景
在一些视频网站上会有统计点赞数/播放量等等频繁计数的功能, 而是用MySQL这种关系型数据库进行算术运算加减的时候太慢, 性能较低, 因此Redis会在上层优先进行计数, 然后再通过异步操作慢慢的将数据存储给底层关系型数据库, 异步过程不要求速度, 只要求全部存储完整
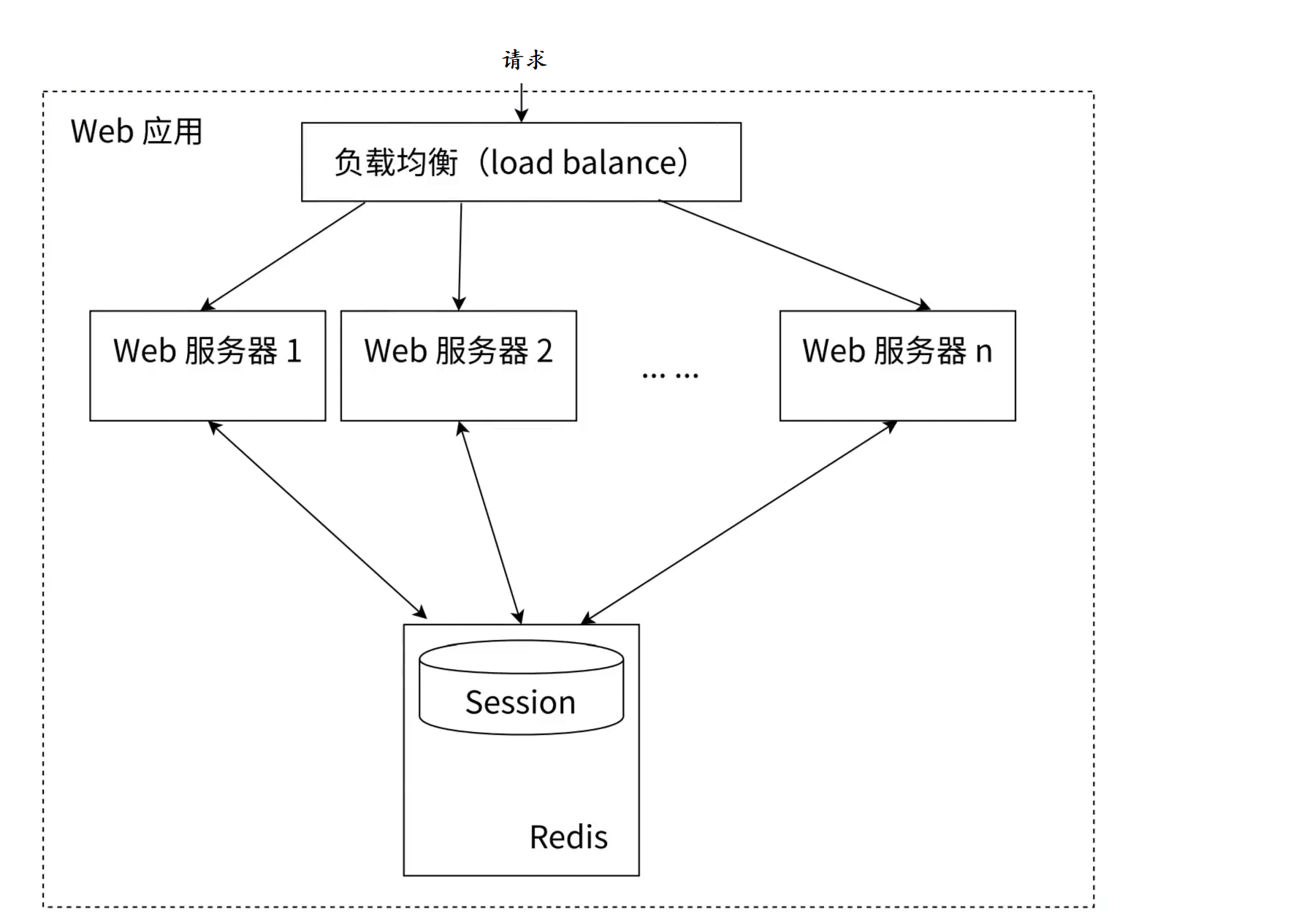
3. 用于存储Session会话
已知在客户端与服务器第一次交互中, 服务器会生成特定的独属于每个用户的SessionID, 是用来标记和区分每个用户的, 而Session一般又是具有时效性, 且会频繁且重复的使用, 在分布式架构中网关是通过负载均衡将请求打在不同的服务器上的, 因此用Redis来存储Session可以将不同服务器之间关联起来且查询性能高效
4. 验证码
验证码在我们生活中很常见, 手机验证码/邮箱验证码等等, 这些验证码的存储一般都是有时效性的和次数的, 例如一分钟最多发送一次, 一次验证码5分钟有效期等等, 而这在Redis中很容易实现通过expire实现, 根据业务来实现具体逻辑