概述
蚂蚁百灵研发助手,官网,
Awesome-Code-LLM
论文,开源(GitHub,1.3K Star,132 Fork)。
蚂蚁集团联合上海交通大学发布110页代码大模型综述,覆盖超过50个模型、30个下游任务、800篇参考文献,全方位总结LLM在代码相关应用中的最新进展与挑战。
ChatBot
开源(GitHub,1.3K Star,132 Fork)AI智能助手,致力于简化和优化软件开发生命周期中的各个环节。结合Multi-Agent的协同调度机制,并集成丰富的工具库、代码库、知识库和沙盒环境,使得LLM模型能够在DevOps领域内有效执行和处理复杂任务。
核心功能点:
- 智能调度核心:构建体系链路完善的调度核心,支持多模式一键配置,简化操作流程;
- 代码整库分析:实现仓库级的代码深入理解,以及项目文件级的代码编写与生成,提升开发效率;
- 文档分析增强:融合文档知识库与知识图谱,通过检索和推理增强,为文档分析提供深层次支持;
- 垂类专属知识:为DevOps领域定制的专属知识库,支持垂类知识库的自助一键构建,便捷实用;
- 垂类模型兼容:针对DevOps领域的小型模型,保证与DevOps相关平台的兼容性,促进技术生态整合。
ModelCache
开源(GitHub,961 Star,59 Fork)大模型语义缓存系统,通过缓存已生成的模型结果,降低类似请求的响应时间,提升用户体验。从服务优化角度出发,引入缓存机制,在资源有限和对实时性要求较高的场景下,帮助企业和研究机构降低推理部署成本、提升模型性能和效率、提供规模化大模型服务。
架构
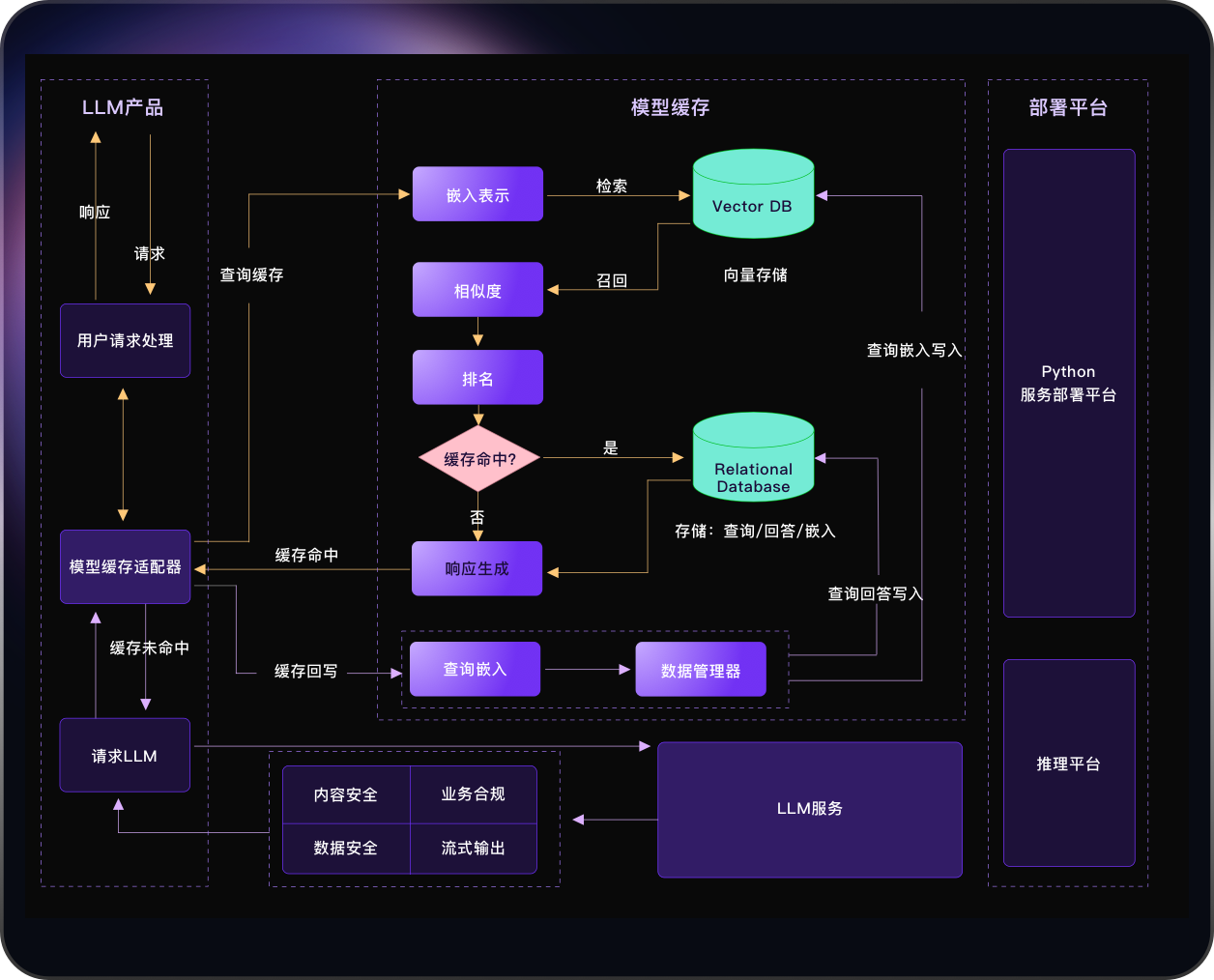
核心模块:
- adapter:其主要功能是处理各种任务的业务逻辑,并且能够将embedding、rank、data_manager等模块串联起来;
- embedding:主要负责将文本转换为语义向量表示,它将用户的查询转换为向量形式,并用于后续的召回或存储操作;
- rank:用于对召回的向量进行相似度排序和评估,可根据L2距离、余弦相似度或者评估模型,对两个向量进行相似度评分,并进行排序;
- data_manager:主要用于管理数据库,包括向量数据库和关系型数据库,负责数据的存储、查询、更新和删除等操作。
- 向量数据库:如Milvus作为一个高性能、可扩展、多功能的向量数据库,适用于多种需要向量检索的应用场景。
- 关系型数据库:采用蚂蚁的OceanBase数据库,存储用户Query、LLM相应、模型版本等信息。
ModelCache与GPTCache
| 模块 | 功能 | ModelCache | GPTCache |
|---|---|---|---|
| 基础接口 | 数据查询接口 | ✅ | ✅ |
| 数据写入接口 | ✅ | ✅ | |
| Embedding | Embedding模型配置 | ✅ | ✅ |
| 大模型Embedding层 | ✅ | ||
| bert模型长文本处理 | ✅ | ||
| 大模型调用 | 是否与大模型解耦 | ✅ | |
| Embedding模型本地加载 | ✅ | ||
| 数据隔离 | 模型数据隔离 | ✅ | ✅ |
| 超参数隔离 | ✅ | ||
| 数据库 | MySQL | ✅ | ✅ |
| Milvus | ✅ | ✅ | |
| OceanBase | ✅ | ||
| 会话管理 | 单轮会话 | ✅ | ✅ |
| System指令 | ✅ | ||
| 多轮会话 | ✅ | ||
| 数据管理 | 数据持久化 | ✅ | ✅ |
| 一键清空缓存 | ✅ | ||
| 租户管理 | 支持多租户(多模型) | ✅ | |
| Milvus多表能力 | ✅ | ||
| 其他 | 长短对话区分能力 | ✅ |
核心功能
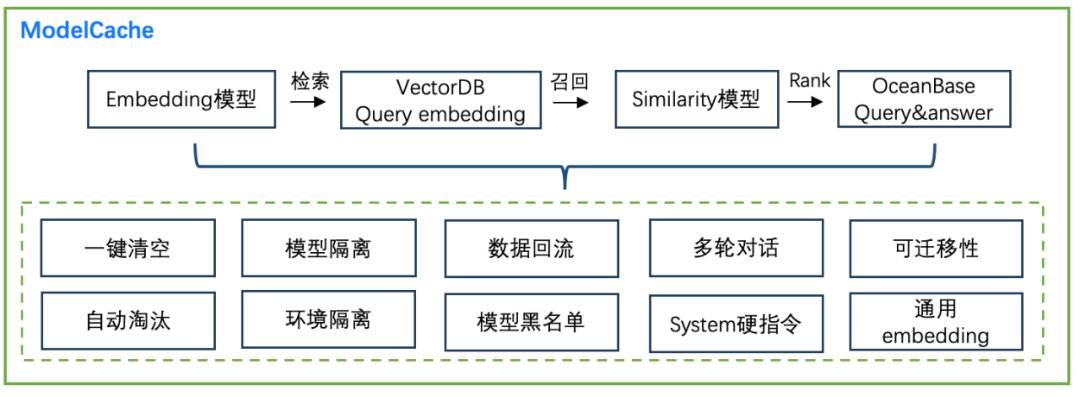
解读:
- 数据管理:Cache需要确保过时或不必要的数据不会在缓存中累积,缓存管理是Cache中关键的一环,提供两个重要功能:
- 一键清空能力:提供数据移除接口,使用户能够一键清空其缓存。这项功能确保当模型版本或者参数发生变更时,前期版本的数据不会对线上的回答造成干扰。
- 缓存淘汰策略:ModelCache支持可定制化的缓存淘汰策略,使用户能够根据自身需求来定制缓存。
- 数据隔离:在实际应用中,数据隔离是一个重要的功能,为了满足不同场景的需求,ModelCache实现了多种数据隔离功能,包括:
- 环境隔离: 支持在不同环境中进行数据隔离,包括DEV、预发和线上环境。这些环境可能存在模型版本和参数上的差异,确保数据在不同环境中的独立性。
- 模型隔离: 支持模型级别的隔离,使用向量数据库表和OB表字段实现独立存储。通过这种方式,不同模型之间的数据可以得到有效的隔离,确保数据的安全性和完整性。
- 数据回流:具有知识持久化的能力,能够确保系统重要数据得到有效地保存和持续使用,从而支持系统的长期发展。为此,Cache中提供了数据回流功能,使得系统中的数据能够得到有效的持久化,这项功能采用异步方式进行,尽可能减少对系统性能的影响。
- system指令及多轮对话支持:在ModelCache中,提供了system指令和多轮对话支持,以满足用户的需求。具体如下:
- system指令支持: 支持system指令,尤其是后续用户可以自定义system指令的情况下,会区分不同system指令下对话的语义相似性,保持Cache的稳定性,未来还计划将system指令与会话进行分离,以进一步提升系统的灵活性和可扩展性。
- 多轮对话能力: ModelCache还支持多轮对话,即能够匹配连续对话的语义相似性。
- 可迁移性:ModelCache具有出色的可迁移性,能够适应不同的场景,OceanBase可以无缝迁移至MySQL等产品,Milvus也是一种可快速部署的数据库服务,所以无论是专有云还是公有云都能够快速应对,并提供高质量的服务。ModelCache可以为用户提供更加灵活和可扩展的部署方案,以满足不同的需求和场景。
- Embedding能力:在当前的cache中,用户可使用中文通用embedding模型(text2vec-base-chinese)。也支持大模型embedding层的嵌入能力,这使得embedding能够更好地适应模型本身的语义,但仅使用大模型的embedding层,演变成词袋模型,无法获取各个token的权重。为此,在训练SGPT(GPT Sentence Embeddings for Semantic Search),以更好的支持ModelCache。
muAgent
开源(GitHub,771 Star,82 Fork)的MAS,宗旨在于简化Agents的标准操作程序(SOP)编排流程。
多Agents的核心,即Agent的交互链路,也即实现SOP的关键。如何把上一个Agent的输出给到下一个Agent的输入,其中涉及到LLM输出、具体Action执行、信息解析处理。
muAgent整合一系列工具库、代码库、知识库、沙盒环境,可支撑用户在任何领域场景,都能迅速搭建复杂的处理多层次多维度任务的多Agent交互应用。
架构图
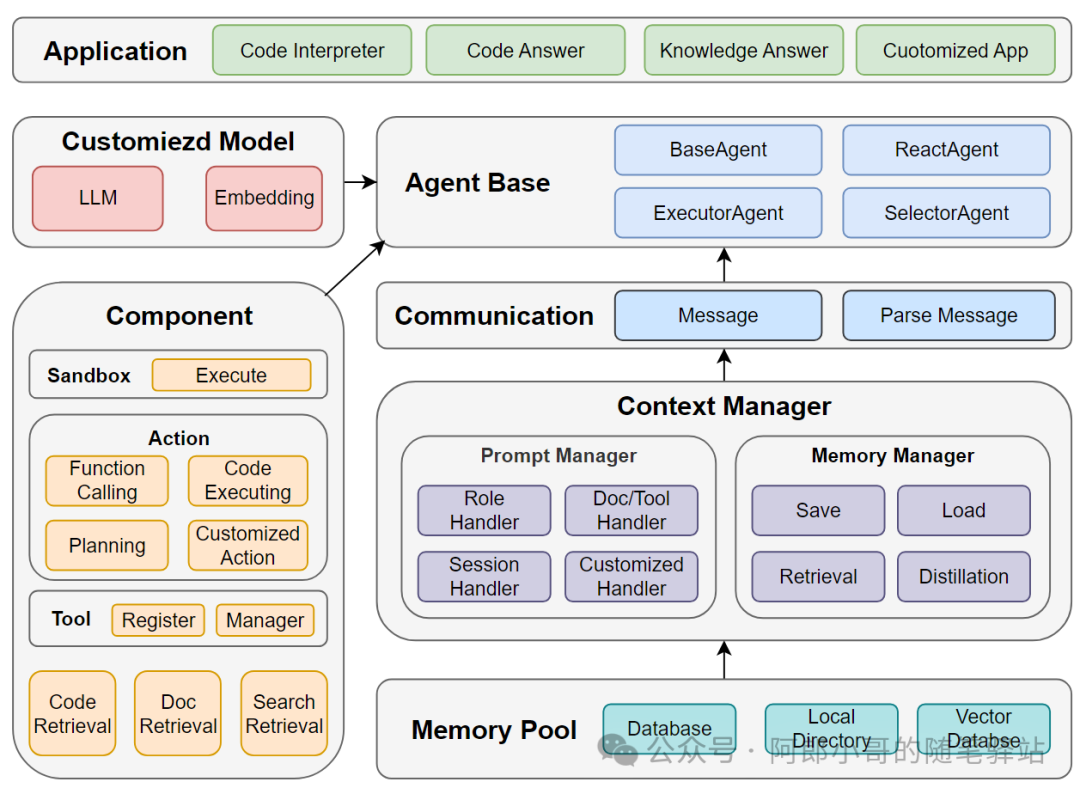
解读:
- Agent Base:构建四种基本的Agent类型BaseAgent、ReactAgent、ExecutorAgent、SelectorAgent,支撑各种场景的基础活动;
- Communication:通过Message和Parse Message实体完成Agent间的信息传递,并与Memory Manager交互再Memory Pool完成记忆管理;
- Prompt Manager:通过Role Handler、Doc/Tool Handler、Session Handler、Customized Handler,来自动化组装Customized的Agent Prompt;
- Memory Manager:用于支撑Chat History的存储管理、信息压缩、记忆检索等管理,最后通过Memory Pool在数据库、本地、向量数据库中完成存储;
- Component:用于构建Agent的辅助生态组件,包括Retrieval、Tool、Action、Sandbox等;
- Customized Model:支持私有化的LLM和Embedding的接入;
官方文档。
安装:pip install codefuse-muagent
MFTCoder
论文,首个开源(GitHub,704 Star,70 Fork)高精度、高效率、多任务、多模型支持、多训练算法LLM代码能力微调框架,包含代码大模型的模型、数据、训练等。
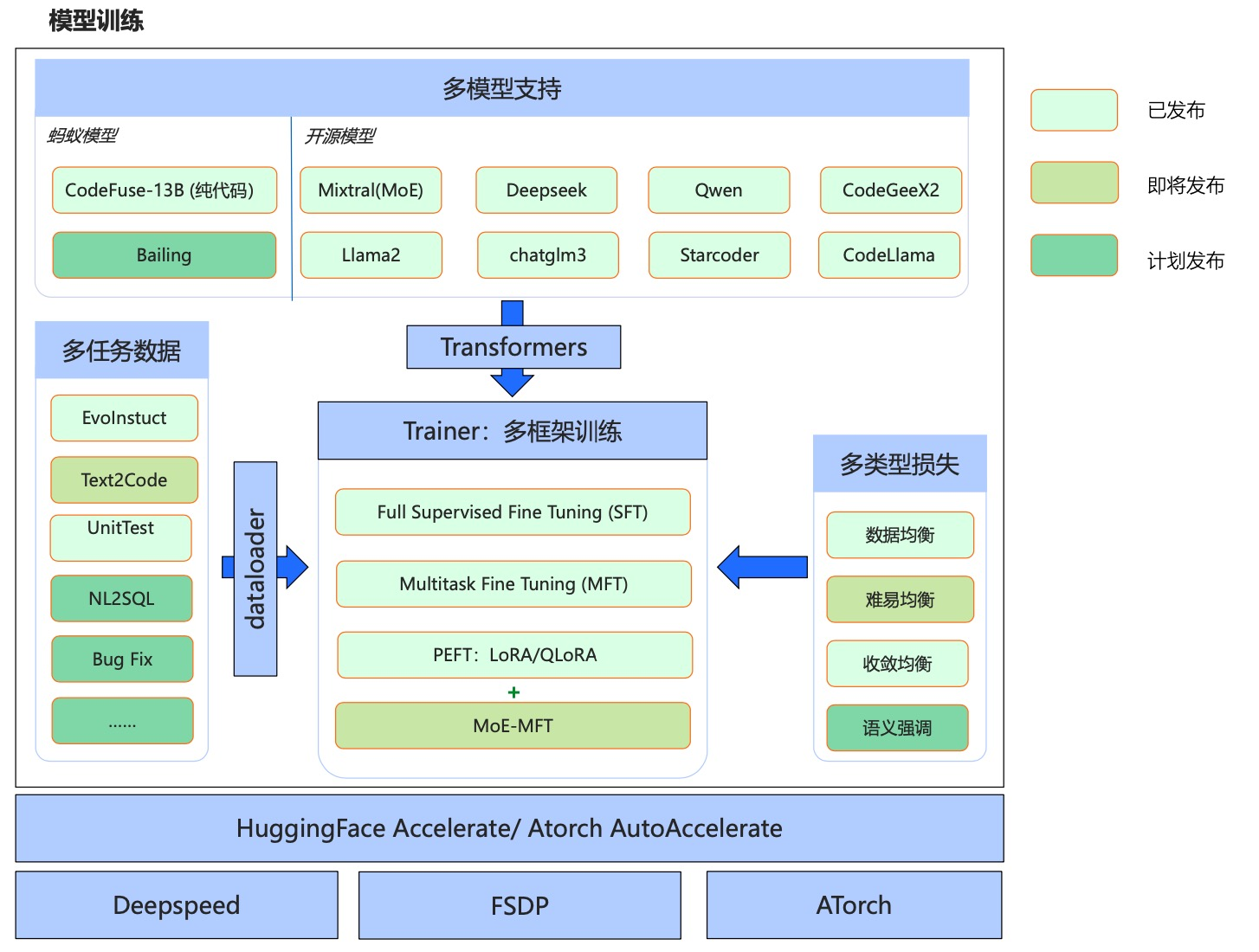
优势
- 多任务:一个模型同时支持多个任务,会保证多个任务之间的平衡,甚至可以泛化到新的没有见过的任务上去;
- 多模型:支持最新的多个开源模型,包括gpt-neox,llama,llama-2,baichuan,Qwen,chatglm2等;
- 多框架:支持主流开源的Accelerate、DeepSpeed、FSDP、ATorch框架;
- 高效微调:支持QLoRA低成本高效指令微调、LoRA高效指令微调、全量参数高精度微调,可用很少资源去微调大模型,且训练速度能满足几乎所有微调场景。
框架
开源模型
| 模型 | HuggingFace链接 | 魔搭链接 | 基座模型 | 训练数据 | BatchSize | SeqLength |
|---|---|---|---|---|---|---|
| CodeFuse-DeepSeek-33B | HF | MS | DeepSeek-coder-33B | 60万 | 80 | 4096 |
| CodeFuse-Mixtral-8x7B | HF | MS | Mixtral-8x7B | 60万 | 80 | 4096 |
| CodeFuse-CodeLlama-34B | HF | MS | CodeLlama-34b-Python | 60万 | 80 | 4096 |
| CodeFuse-CodeLlama-34B-4bits | HF | MS | CodeLlama-34b-Python | 4096 | ||
| CodeFuse-StarCoder-15B | HF | MS | StarCoder-15B | 60万 | 80 | 4096 |
| CodeFuse-QWen-14B | HF | MS | Qwen-14b | 110万 | 256 | 4096 |
| CodeFuse-CodeGeex2-6B | HF | MS | CodeGeex2-6B | 110万 | 256 | 4096 |
| CodeFuse-StarCoder2-15B | HF | MS | Starcoder2-15B | 70万 | 128 | 4096 |
开源代码任务指令微调数据集
| 名称 | 介绍 |
|---|---|
| Evol-instruction-66k | 基于开源open-evol-instruction-80k过滤低质量,重复和human eval相似的数据后得到的高质量代码类微调数据 |
| CodeExercise-Python-27k | 高质量Python练习题数据 |
DevOps-Eval
开源(GitHub,645 Star,46 Fork)专门为DevOps领域大模型设计的综合评估数据集。

Test-Agent
国内首个开源(GitHub,642 Star,74 Fork)测试行业大模型,包含性能最强的7B测试领域大模型,以及配套的本地模型快速发布和体验工程化框架。旨在构建测试领域的智能体,融合大模型和质量领域工程化技术,促进质量技术代系升级。
架构
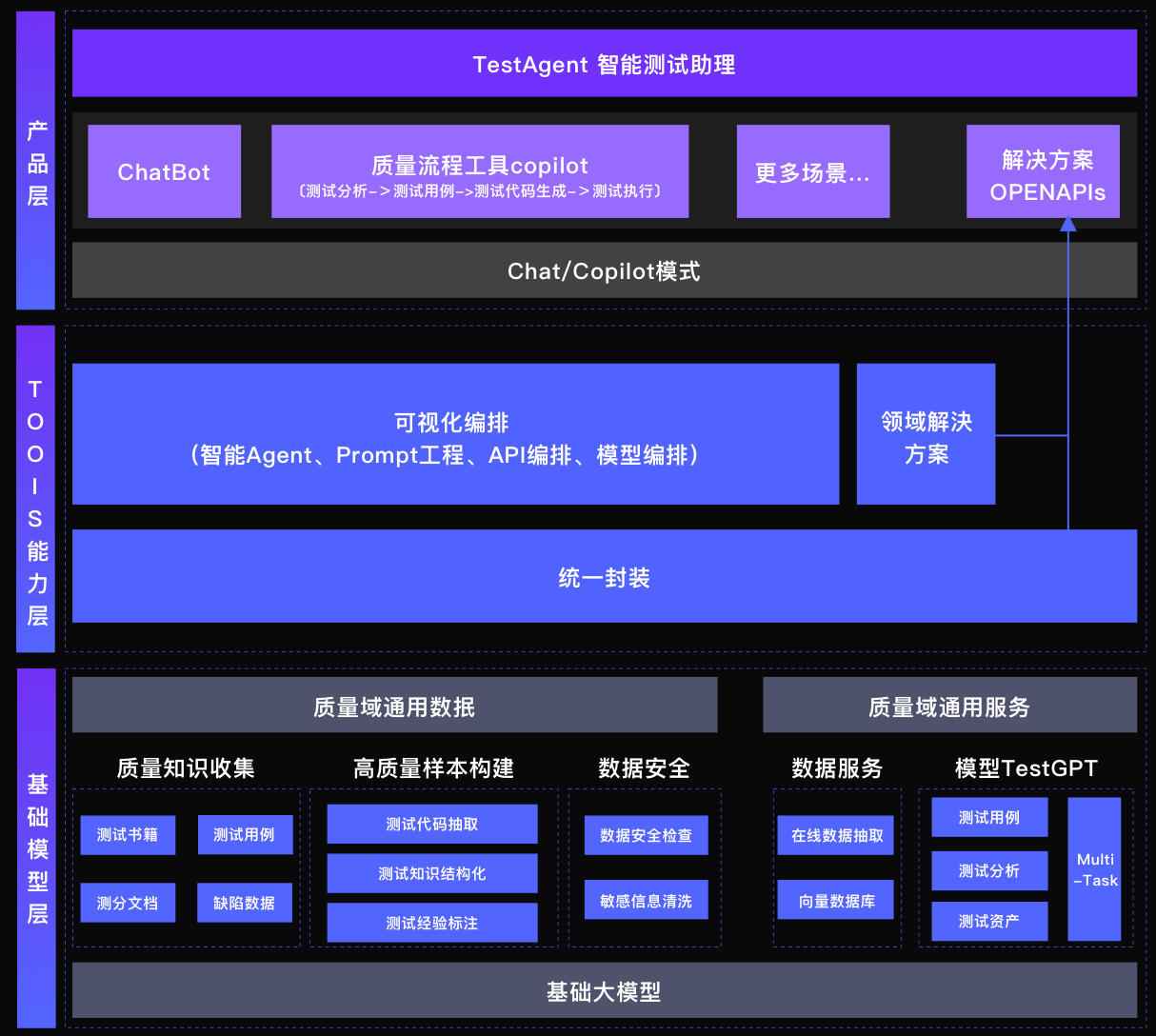
以CodeLlama-7B为基座,进行相关下游任务的微调:
- 多语言测试用例生成(Java/Python/JS)一直以来都是学术界和工业界非常关注的领域,近年来不断有新产品或工具孵化出来,如EvoSuite、Randoop、SmartUnit等。然而传统的用例生成存在其难以解决的痛点问题,基于大模型的测试用例生成在测试用例可读性、测试场景完整度、多语言支持方面都优于传统用例生成工具。在本次开源的版本中首先包含Java、Python、JS测试用例生成能力,下一版本中逐步开放Go、C++等语言。
- 测试用例Assert补全:对当前测试用例现状的分析与探查时,发现代码仓库中存在一定比例的存量测试用例中未包含Assert。没有Assert的测试用例虽然能够在回归过程中执行通过,却无法发现问题。因此拓展测试用例Assert自动补全这一场景。通过该模型能力,结合一定的工程化配套,可实现对全库测试用例的批量自动补全,智能提升项目质量水位。
开源模型:
提供网页端快速搭建UI的能力能够更直观的展示模型交互和效果,使用几个简单命令把前端页面唤醒并实时调用模型能力。在项目目录下,依次启动以下服务:
- 启动Controller:
python3 -m chat.server.controller - 启动模型Worker:
python3 -m chat.server.model_worker --model-path models/TestGPT-7B --device mps --num-gpus 2,其中--device参数支持:--device mps:Mac电脑上开启GPU加速(Apple Silicon或AMD GPUs);--device xpu:Intel XPU上开启加速(Intel Data Center and Arc A-Series GPUs);- 需安装Intel Extension for PyTorch
- 设置OneAPI环境变量:
source /opt/intel/oneapi/setvars.sh
--device npu:华为AI处理器- 需安装Ascend PyTorch Adapter
- 设置CANN环境变量:
source /usr/local/Ascend/ascend-toolkit/set_env.sh
--device cpu:使用CPU,不需要GPU;
- 启动Web服务:
python3 -m chat.server.gradio_testgpt
浏览器打开http://0.0.0.0:7860,
DevOps-Model
开源(GitHub,508 Star,42 Fork)
开源模型
| 参数 | 基座模型HF链接 | 基座模型MS链接 | 对齐模型HF链接 | 对齐模型MS链接 |
|---|---|---|---|---|
| DevOps-Model-7B | HF-Base | MS-Base | HF-Chat | MS-Chat |
| DevOps-Model-14B | - | MS-Base | - | MS-Chat |
示例:
py
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
model_name = "codefuse-ai/CodeFuse-DevOps-Model-14B-Chat"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto", trust_remote_code=True, bf16=True).eval()
model.generation_config = GenerationConfig.from_pretrained(model_name, trust_remote_code=True)
resp, hist = model.chat(query='Java中HashMap和Hashtable的区别', tokenizer=tokenizer, history=None)
print(resp)
resp2, hist2 = model.chat(query='线程安全什么意思', tokenizer=tokenizer, history=hist)
print(resp2)CGM
论文,开源(GitHub,493 Star,46 Fork)。CGM是Code Graph Model缩写,
CodeFuse-Query
开源(GitHub,304 Star,37 Fork)强大的静态代码分析平台,适合大规模、复杂的代码库分析场景。以数据为中心的方法和高度的可扩展性使得它在现代软件开发环境中具有独特的优势。
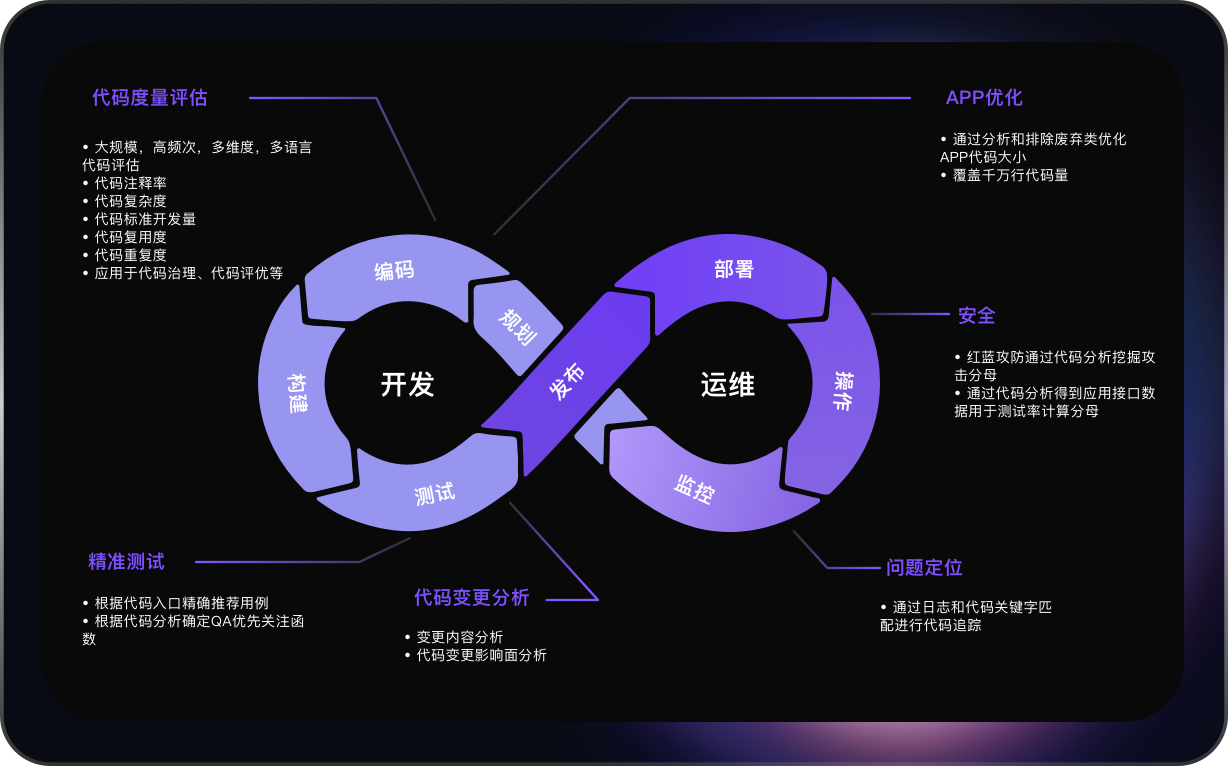
分为三大部分:
- 代码数据模型:COREF=AST(抽象语法树)+ASG(抽象语义图)+CFG(控制流图)+PDG(程序依赖图)+Call Graph(函数调用图)+Class Hierarchy(类继承关系)+Documentation(文档/注释信息)
- 代码查询DSL:
- 平台产品化服务:
支持分析的编程语言
| 语言 | 状态 | COREF模型节点数 |
|---|---|---|
| Java | 成熟 | 162 |
| XML | 成熟 | 12 |
| TS/JS | 成熟 | 392 |
| Go | 成熟 | 40 |
| OC/C++ | beta | 53/397 |
| Python3 | beta | 93 |
| Swift | beta | 248 |
| SQL | beta | 750 |
| Properties | beta | 9 |
IDE
开源(GitHub,268 Star,40 Fork)基于CodeFuse和OpenSumi的AI原生IDE。
启动:
bash
yarn
yarn run electron-rebuild
yarn run startOpenSumi
官网,一款开源(GitHub,3.6K Star,444 Fork)可用于快速搭建本地和云端IDE的框架。
CodeFuseEval
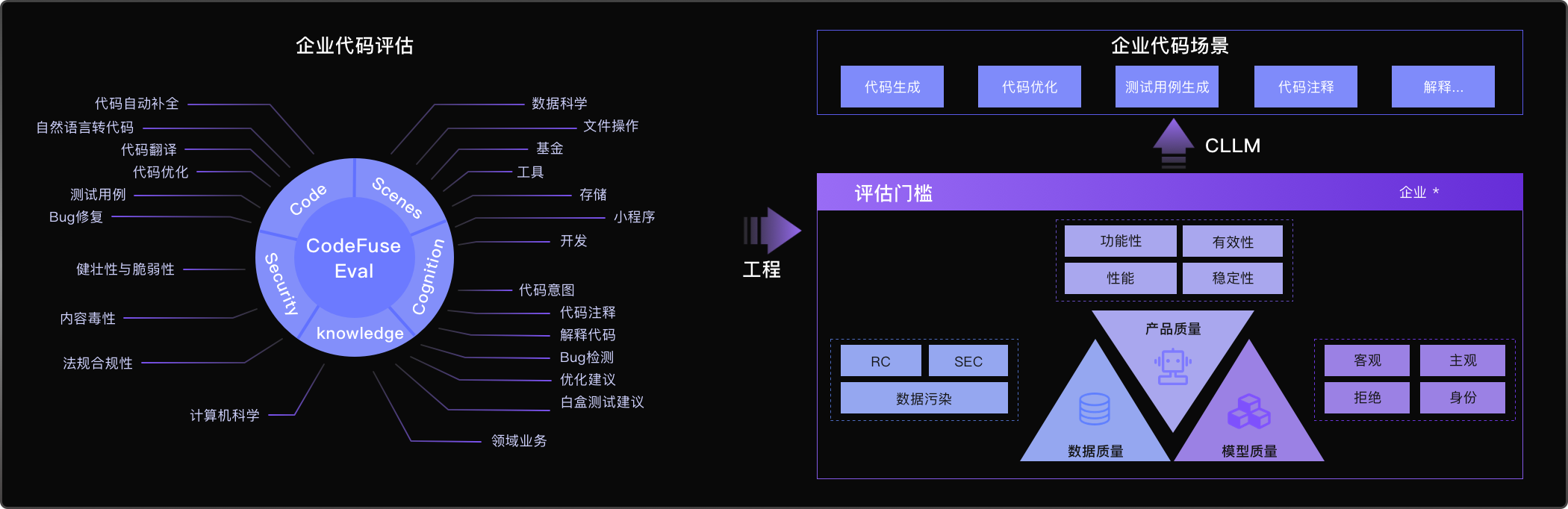
开源(GitHub,103 Star,16 Fork)结合Codefuse大模型多任务场景,在开源的HumanEval-x、MBPP、DS1000评测基准基础上,开发的面向大模型代码垂类领域的企业级多类型编程任务评估基准。可用于评估大模型在代码补全、自然语言生成代码、测试用例生成、跨语言代码翻译、中文指令生成代码、代码注解释、Bug检测/修复、代码优化等不同任务的能力表现。旨在贴近企业实际应用场景,构建而成的衡量大模型代码生成相关能力的「多维」、「多样」和「可信」的评测基准。
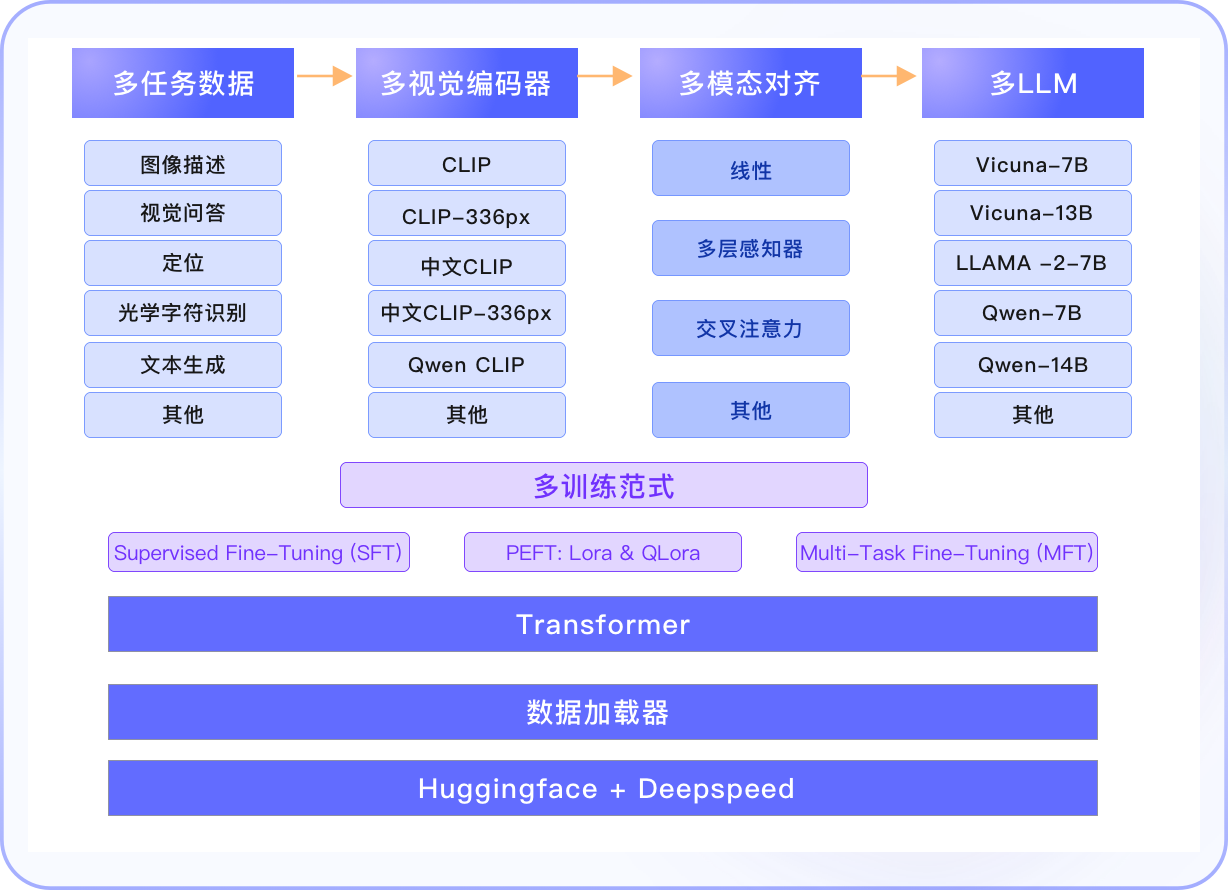
MFT-VLM
开源(GitHub,40 Star,9 Fork)为多模态LLM设计的框架,旨在兼容和适应多种视觉和语言模型以支持不同类型的任务。集成众多视觉编码器如CLIP系列,LM如Vicuna和LLAMA系列,提供灵活的配置选项,允许用户通过VL-MFTCoder自由组合不同的模型,从而简化多模态任务的开发和应用过程。
参考
- 官网和GitHub