作为一名长期与 Elasticsearch 打交道的引擎研发,我见过太多集群因为一个看似无害的 wildcard 模糊查询而瞬间崩溃。
许多开发者继承了 SQL LIKE %...% 的思维习惯,直接把它搬到 ES 中------在小数据量时没什么大碍,但当文档量上亿时,它会变成拖垮集群的性能黑洞:
-
轻则:错用字段类型,查不准结果,浪费存储
-
重则:暴力扫描,CPU 瞬间打满,集群直接假死
为什么会这样?又该怎么避免?
接下来,我们将深入解析这些问题原因和其解决方案。我们特意在 5000 万级数据量 下做了高压测试,用真实数据复刻事故现场,让你一眼看懂问题的根源与规避方案。
对 ES 用户及技术开发爱好者而言,这是一份不可错过的技术文章。
不同查询场景的最佳选型建议
针对不同场景,我们给出以下实战建议:

特别提醒:选型还要看量级
-
数据量 < 10 万: 默认 keyword 即可,无需过度优化也能实现毫秒级响应。
-
数据量 > 1000 万: 必须慎重选择,否则分分钟线上故障。
一、痛点解析:从"查不到"到"搞挂集群"的三重陷阱
wildcard 的问题不只是"慢",它首先是一个逻辑陷阱。
陷阱一:分词误用 → 查询结果静默丢失
text 分词导致的"查不到" (The Logic Tra)
-
**现象:**文档里明明有 "agent 007 bond",但搜 *agent 007* 返回空。
-
原理: text 字段经过分词器(Analyzer)处理,变成了 "agent", "007", "bond" 三个独立的词元。wildcard 是去匹配每一个单独的词元,显然没有一个词元长得像 *agent 007*(跨词了)。
Tips:如果怀疑分词存在问题,可使用
_termvectorsAPI 查看磁盘中数据的实际存储情况。你可能会发现,它的存储形式与原文早已大相径庭。
陷阱二:Keyword 模糊查询 → 线性性能雪崩
为了解决"陷阱一",开发者通常会决定:"改用 keyword 字段吧,它不分词,保留完整字符串。" 这时候,业务逻辑通了,但性能噩梦开始了。
-
事故现场: 当你执行 *login* 时,ES 被迫对数百万个长字符串执行逐一扫描。
-
**实测验证:**在 5000W 数据下,单次查询耗时 13秒 ,CPU 瞬间打满,集群直接假死。(详见 6.2)
陷阱三:Rewrite 机制限制 → 报错或数据丢失
即使你忍受了 Keyword 的慢,你可能还会遇到更底层的问题。ES 底层的 Rewrite(重写)机制 让你面临两个选择:
-
要么"报错"(Scoring Boolean): 如果业务需要算分,ES 必须把匹配词展开为布尔查询。一旦匹配词超过 1024 个(默认限制),查询直接熔断报错:too_many_clauses。
-
要么"丢数据"(Top N): 为了不报错,你被迫配置 top_terms_N 。这告诉 ES:"只计算频次最高的 N 个词,剩下的扔掉。"后果就是数据静默消失。
二、实战方案详解(Ngram / Search_as_you_type / Wildcard 配置与查询 DSL)
既然"直接查"是死路,我们必须"将计算压力从查询时转移到索引时"**。**以下是 3 种方案的完整配置代码。
方案 1:Ngram 索引器(极致性能,代价昂贵)
这是最经典的"空间换时间"方案,通过自定义 Analyzer,在索引时将字符串切分成碎片(如 te,ex,xt...)。
1)索引配置 (Settings & Mapping):
json
PUT /bench_ngram
{
"settings": {
"analysis": {
"tokenizer": {
"my_ngram_tokenizer": {
"type": "ngram",
"min_gram": 2, // 支持搜短词 (如 ID)
"max_gram": 3 // 过大会造成存储膨胀严重,2-3 为性价比首选,除非超高 qps,否则不建议更大
}
},
"analyzer": {
"my_ngram_analyzer": { "tokenizer": "my_ngram_tokenizer" }
}
}
},
"mappings": {
"properties": {
"sku": { "type": "text", "analyzer": "my_ngram_analyzer" }
}
}
}2)查询改造 (Query DSL):
注意必须修改查询代码,推荐使用 constant_score 包裹 match (operator: and),这是兼顾准确性与极致性能的最佳实践。但是会有一定假阳,若一定要求准确,则需使用 match_phrase。
json
GET /bench_ngram/_search
{
"track_total_hits": false, // 生产环境建议关闭,利用提前终止优化,否则大基数下会非常慢
"query": {
"constant_score": {
"filter": {
"match": {
"sku": { "query": "BATCH888", "operator": "and" }
}
}
}
}
}Tips: constant_score 换成 bool filter 效果也一样
评价: 速度快到离谱,唯二的缺点是费空间 和废代码(需重写 DSL)。
方案 2:search_as_you_type 字段(面向前缀提示的专用类型)
这是 Elasticsearch 官方专为 下拉提示 场景打造的字段类型,它会在索引阶段自动生成多种前缀和短语组合,确保用户在输入的同时即可获得精准、快速的搜索建议。
1)索引配置(Mapping):
bash
PUT /bench_sayt
{
"mappings": {
"properties": { "sku": { "type": "search_as_you_type" } }
}
}2)查询方式:
使用 multi_match + bool_prefix 类型。
评价: 它是为"前缀"而生的。虽然也能勉强做中间匹配(通过 stored shingle),但空间占用巨大,且在非前缀场景下性能并不突出。
方案 3:wildcard 字段类型(官方推荐的通用型方案)
wildcard 是 Elasticsearch 7.9+ 专为非结构化文本检索设计的字段类型,本质上是一个自带索引加速器的 keyword 字段。它在底层采用"双重结构"架构,以在通配符查询中兼顾性能与准确性:
-
**加速层(Approximation):**写入时会自动将字符串切分为 3-gram 片段,存入 倒排索引。查询时,利用倒排链求交能力快速过滤出"可能匹配"的候选文档,将扫描范围从 全量数据 缩小到 极小集合。
-
**验证层(Verification):**通过 Binary Doc Values 存储完整的原始字符串,对筛选出的候选文档使用 Automaton(有限自动机)进行逐字节精确比对,确保检索结果 100% 准确。
1)索引配置(Mapping):
配置过程非常简单,无需自定义 Analyzer,即可直接在 Mapping 中声明字段类型为 wildcard。
bash
PUT /bench_wildcard
{
"mappings": {
"properties": { "sku": { "type": "wildcard" } }
}
}2) 查询方式:
零改造! 继续使用 DSL: wildcard: { "sku": "*BATCH888*" } 。
评价: 唯一推荐的通用解。它是最安全的默认选项。它也许在某些特定 case(如超短前缀)下不如 Ngram 暴力,但它能处理所有情况(包括正则、复杂通配)。查得准、用得爽(零侵入)、存得省。
三、5000W 数据压测对比(性能、存储全维度)
数据胜于空谈。我们在 Serverless 8.17 环境中,写入了 5000 万条高基数 且无重复的 UUID 数据,用实测结果向你展示------在架构选型中,你在存储上付出了多少,又在性能上收获了什么。
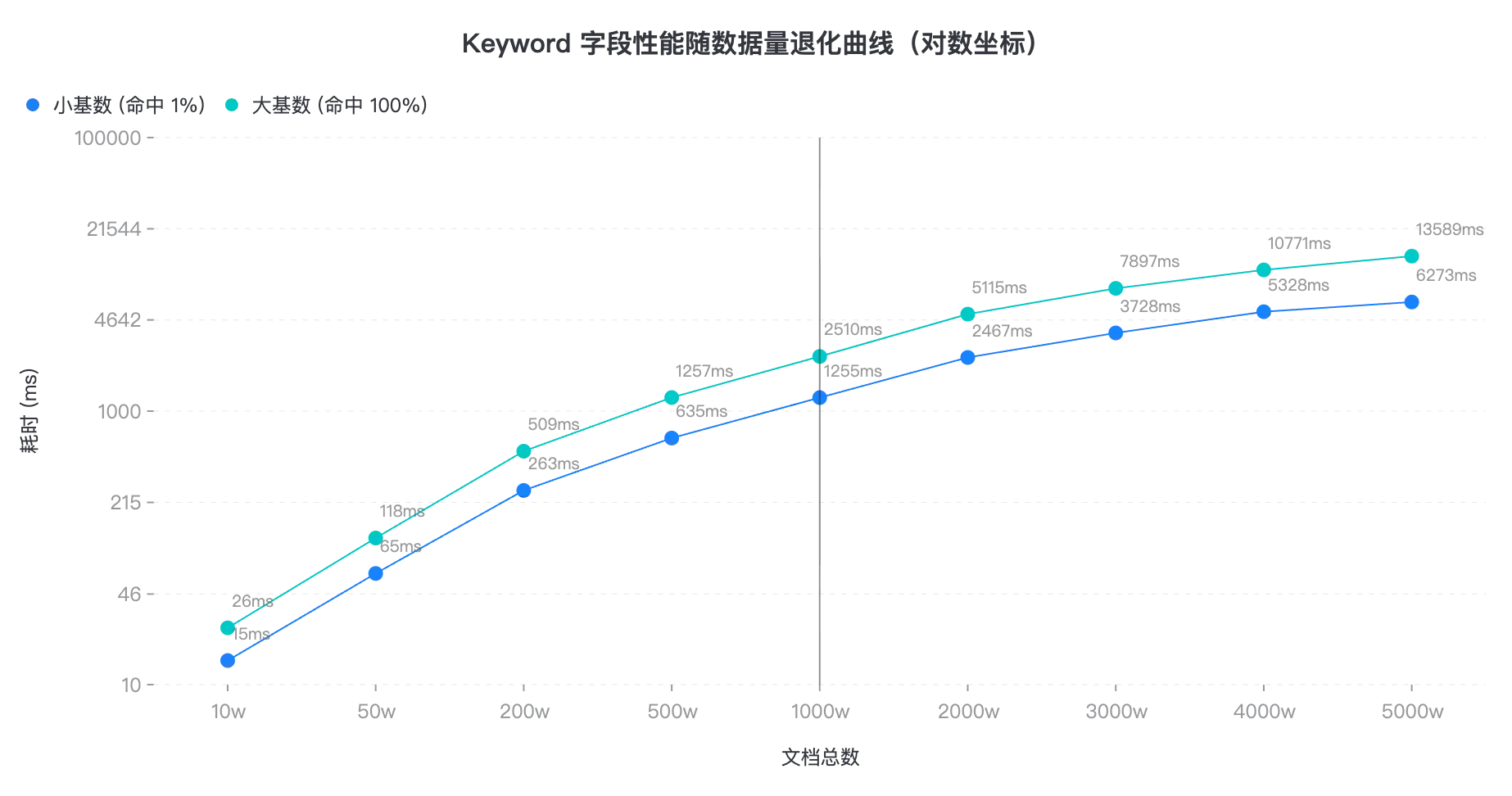
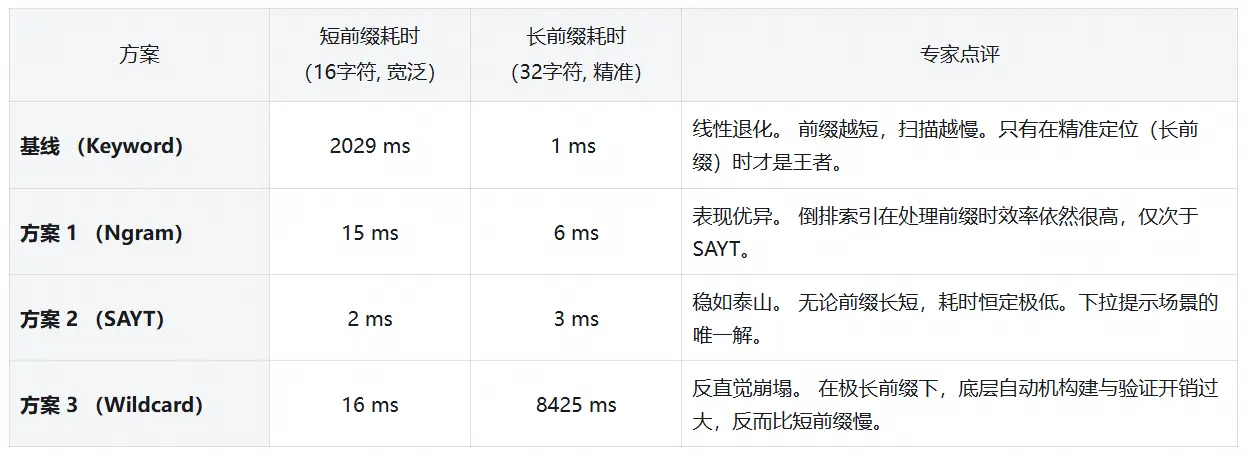
3.1 keyword 性能退化曲线
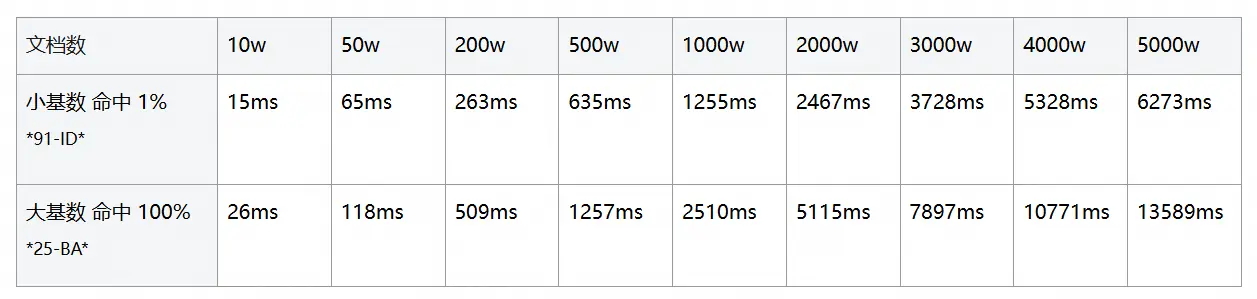
为了让大家直观感受都 keyword 的表现,我们测试了不同数据量下的查询耗时。可见,超过 1000w,即使是小基数,也要 1s+,业务已无法使用。
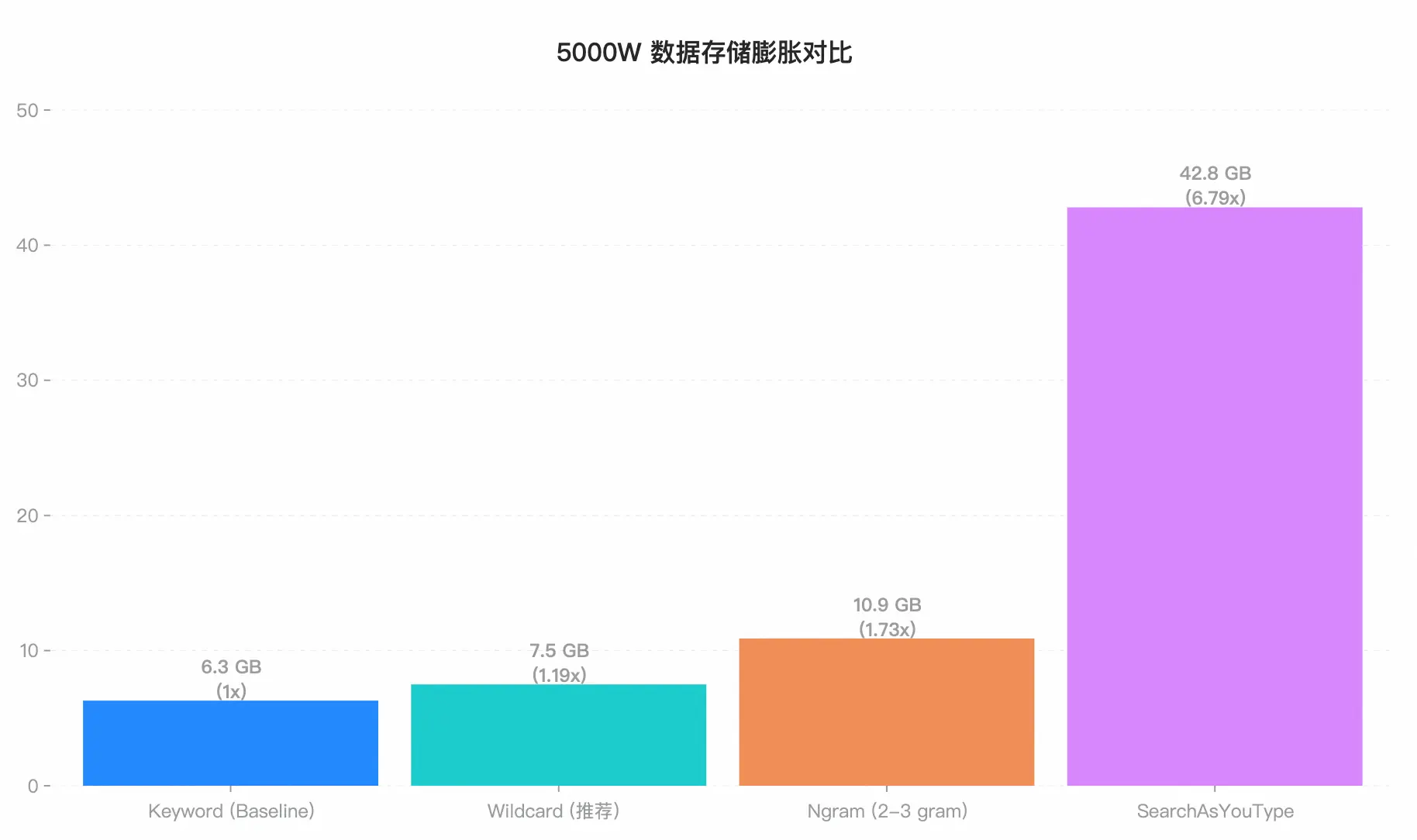
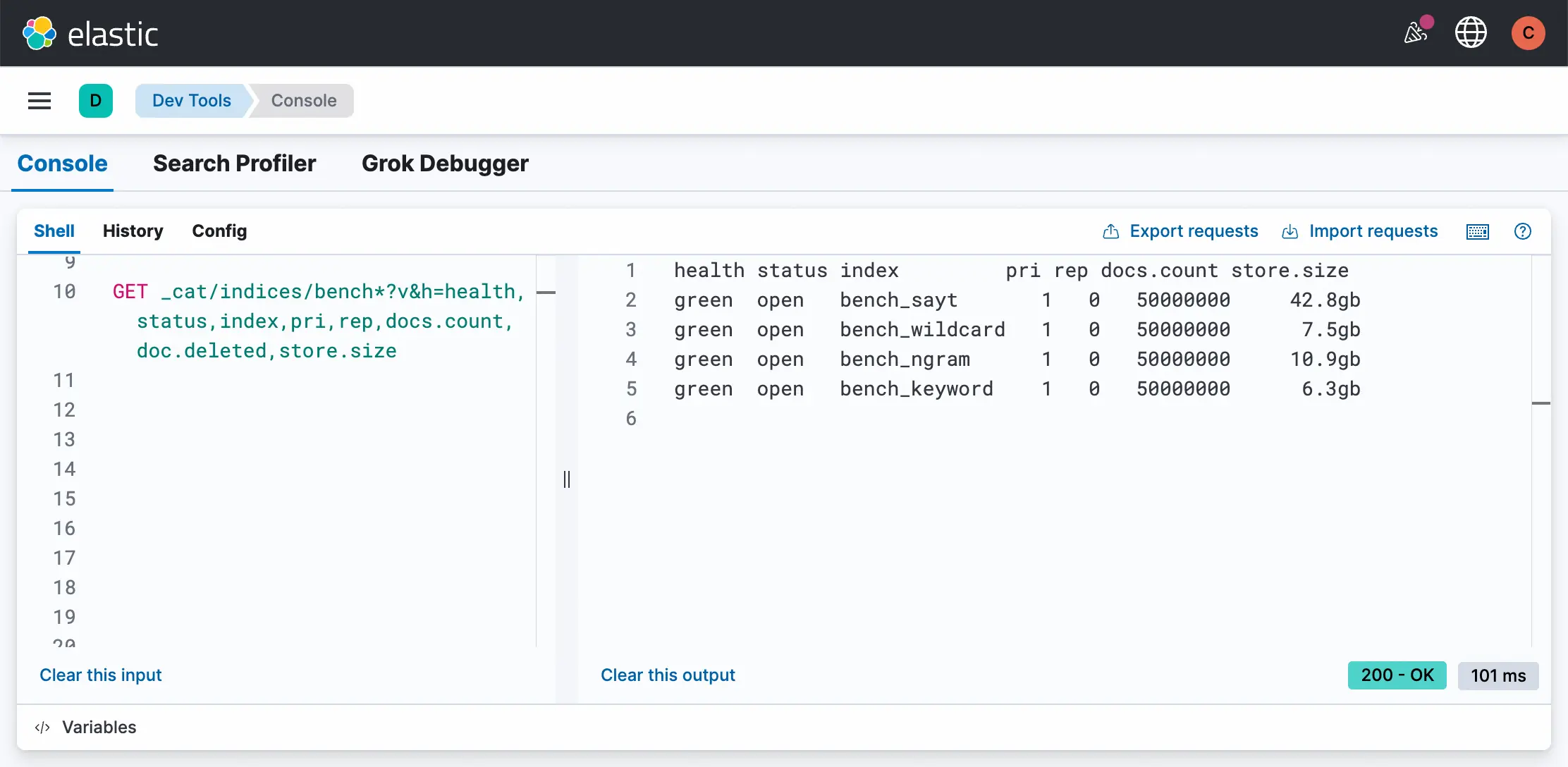
3.2 存储膨胀对比:空间换时间,代价有多大?
我们先观察磁盘占用情况。forcemerge 完成后,不同方案的存储规模差异十分明显。
-
Wildcard 效果惊艳: 在支持任意模糊匹配的同时,仅比纯文本 FST 多了 1.2GB 的开销,架构设计极其优秀。
-
Ngram 的空间陷阱: 我们在测试中使用了
min:2, max:3的 ngram 配置。但其存储依然膨胀了73% ,达到了 10.9 GB。但这造成了无法搜索单字,若需要搜索单字,需要min:1, 这会造成海量高频词,性能崩塌。便又要max_gram: 10,来进行提速。此时空间直接爆炸。 -
SAYT 的空间代价: 42.8 GB 的占用量证明了它就是为"前缀"这一件事不惜血本的设计,绝不适合通用场景。
3.3 中缀查询谁是王者?Wildcard 稳健,Ngram 极致
接下来,我们在 5 QPS 负载下随机执行中缀查询(如 *BATCH888*),对比记录集群在该场景下的 CU 消耗与响应时间,直观体现不同方案的性能差异。
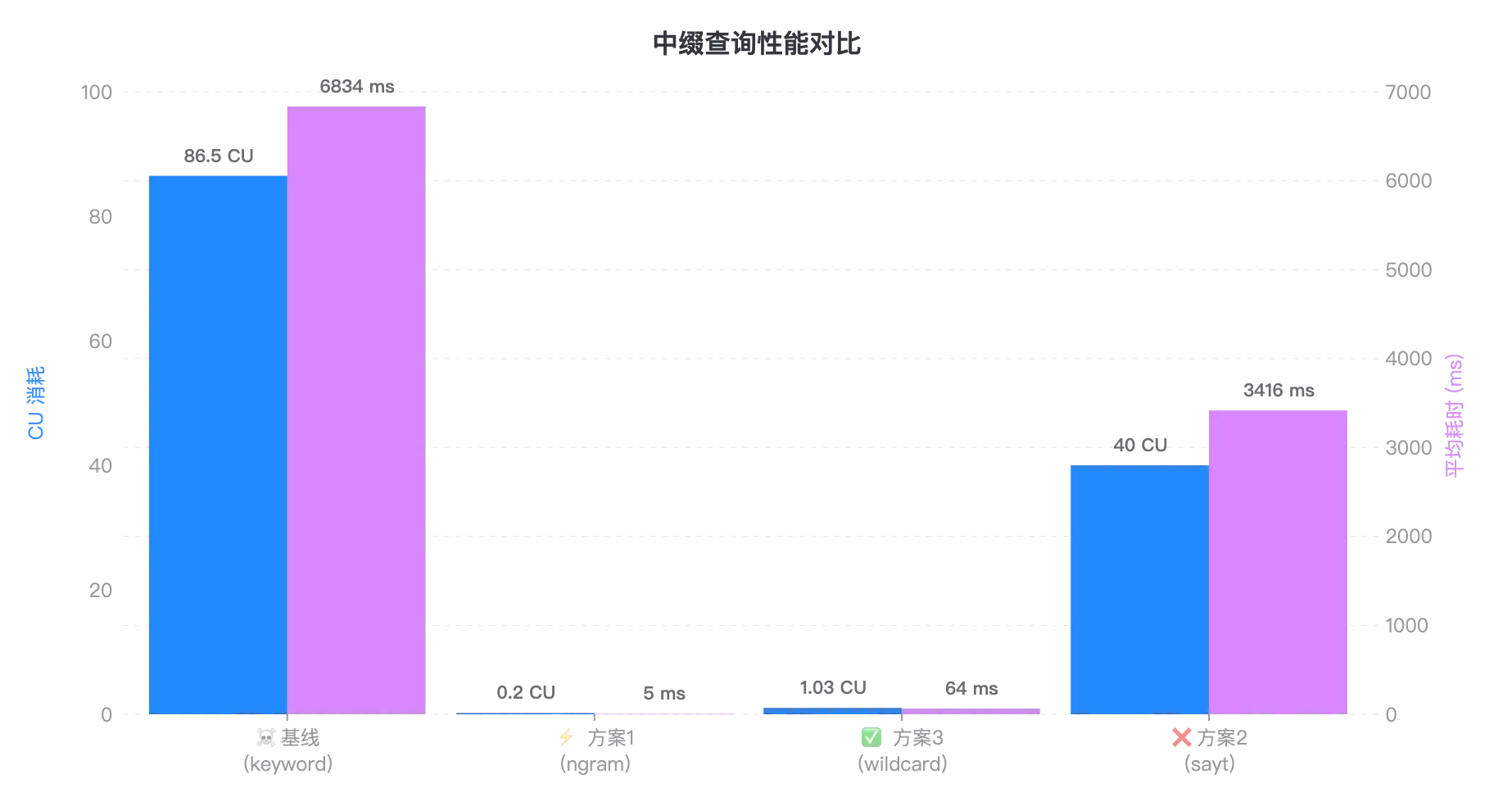
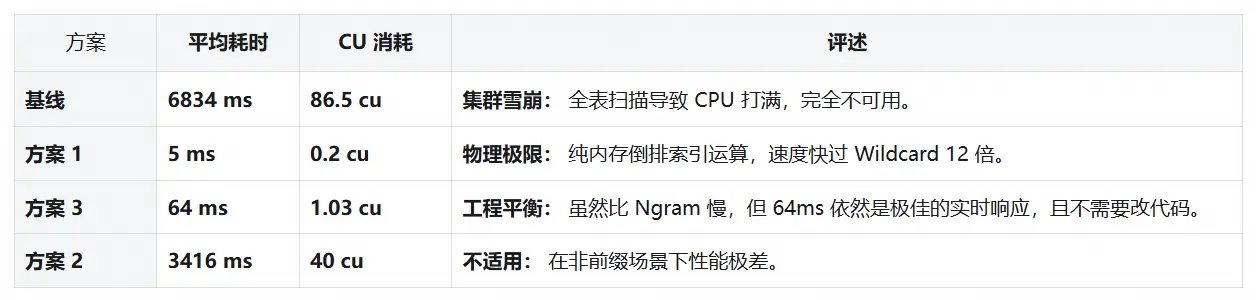
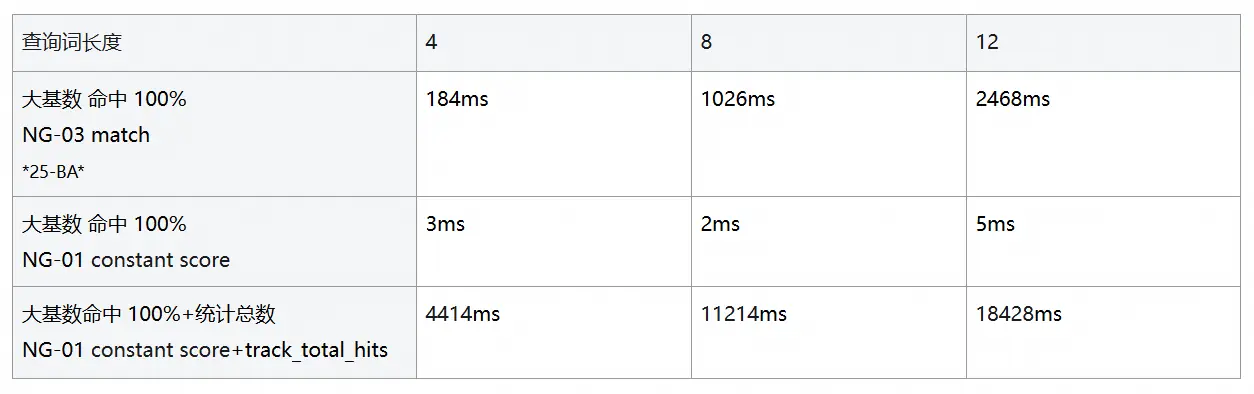
Tips:为什么 Ngram 只要 5ms?
在测试中,我们采用了
constant_score与track_total_hits: false的组合策略,跳过了相关性算分和全量命中统计,直接利用倒排索引的位图交集(BitSet Intersection)以及提前终止(Early Termination)机制,将查询过程压缩到了极限。不过,这种极致性能的实现是有代价的:
1)功能受限: 搜不到单字的短词, 且严禁开启总数统计(否则耗时飙升 1000 倍至 4.4s,见附录 6. 3);
2)代码侵入: 对代码有一定侵入性,需要重写查询 DSL,对于 a*b 这类中间模糊的查询处理复杂。
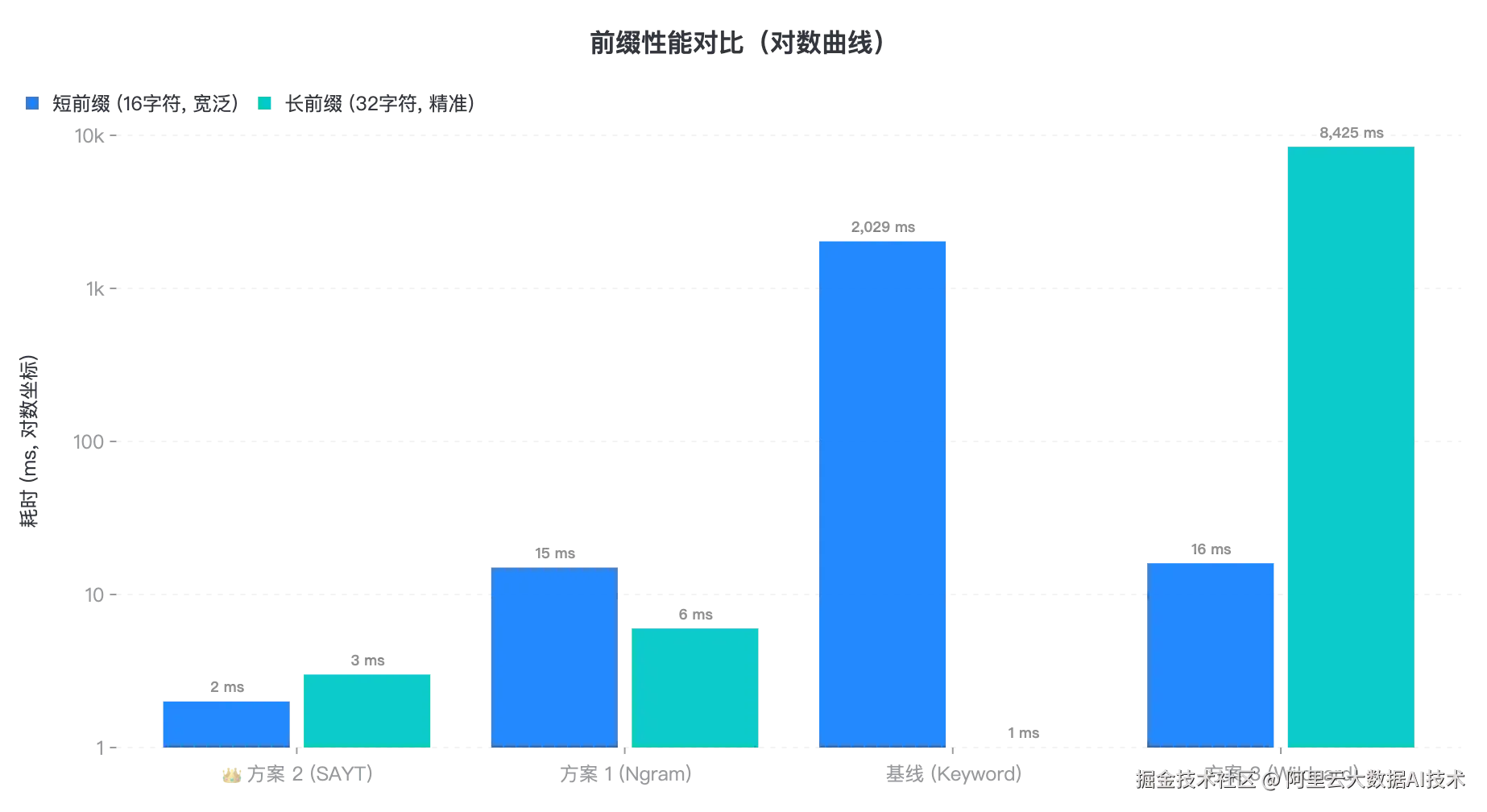
3.4 前缀查询验证:谁是"前缀之王"?
在测试中,我们分别对比了各方案在 宽泛前缀 (匹配大量文档)和 精准前缀(匹配少量文档)两种场景下的表现。
结果显示,SearchAsYouType 不愧为前缀匹配的专业选手,无论前缀长度如何,都能保持稳定的低延迟;而 Wildcard 在处理超长前缀时,由于底层自动机验证过程的开销显著增加,性能会出现明显下滑。
四、残酷现实:选对了方案,就能高枕无忧吗?
根据上述实测结果,很多开发者的第一反应可能是:"只要将所有字段替换为 Wildcard 类型,就可以彻底解决问题。"
但长周期的生产运行告诉我们,即使在实现层面选择了最优方案,也仍存在两类无法回避的潜在风险------堪称生产环境中的"隐形炸弹":
4.1 防不住的"手滑"(Human Error):
"你无法保证每一位新入职的同事都熟读开发规范。也许只是一次无心的手滑,在普通的 Keyword 字段上写了一个 *...* 查询------这一行不起眼的代码,足以让你的自建集群在业务高峰期瞬间雪崩,甚至拖垮正常的写入和核心查询。"
4.2 跟不上的"内核"(Technical Debt):
Elasticsearch 社区的演进日新月异。像 Wildcard 这样优秀的底层优化往往依赖最新的内核版本。而自建集群因为担心升级风险,往往只能"锁死"在老版本,眼睁睁看着数倍的性能红利白白流失。
五、阿里云 ES Serverless : 稳定性与先进性的"双重保障"
改变每一位开发者的查询习惯几乎不可能,而我们选择了另一条路:
直接让你的集群拥有"防弹护甲",自动抵御那些足以击穿性能的高危查询。与自建相比,阿里云 ES Serverless 的架构更健壮、更安全,也更省心。
5.1 内置"智能护栏",终结单点雪崩
我们不会在后台"魔法般地"自动修改你的业务代码,但可以在风险发生前,阻止高风险查询拖垮整个集群。
阿里云 ES Serverless 内置了企业级的 智能查询限流与熔断机制,能够精准识别那些资源消耗巨大的 "杀手级查询"(Cluster Killers),并进行针对性的限流或熔断处理。
这样,你的集群将始终保持业务连续性------不会因为一条异常 SQL 而全面宕机。高风险查询被隔离控制,正常查询依然可以平稳、流畅地执行。
5.2 内核无感进化,坐享性能红利
基于云原生 Serverless 架构,阿里云实现了内核的 静默无感升级。
无论是 Wildcard 字段底层的实现优化,还是查询执行器的性能改进,你都无需进行任何迁移或重启,即可自动、透明地获得这些优化成果。
这意味着,你可以在 零额外运维成本 的情况下,始终运行在更快、更安全、更强大的版本上,让技术红利直接转化为业务竞争力。
六、压测实录节选(进群获取完整 pdf)
6.1 存储膨胀对比 (5000万数据)
6.2 Keyword 中缀查询耗时随文档数的变化
6.3 Ngram 中缀查询耗时变化
七、参考资料
官方文档 (User Guides)
深入博客(Blog Deep Dives)
八、结尾
模糊查询并非洪水猛兽,真正的风险在于 使用场景不匹配 和 字段类型 、索引策略选错。在超大数据量的实际业务环境中:
Wildcard → 最稳健的通用方案;
Ngram → 高 QPS 中缀场景下的性能极限选手;
Search_as_you_type → 前缀提示的专业方案。
无论选择哪种方案,最终都取决于你的数据规模、查询模式和运维能力。
获取压测数据 & 加入技术讨论
欢迎加入钉钉群 72335013004,回复"报告",即可获得本次 5000 万数据压测的完整数据报告。
入群还可获取更多深度避坑指南、内核源码解读及高并发压测报告,与一线研发共同探讨最佳实践。
告别"运维深渊",把时间还给业务创新
如果你不想因为一次无心的模糊查询而雪崩,可以考虑阿里云 ES Serverless:
-
智能限流与熔断:坏查询关进笼子,好查询按需放行
-
内核无感升级:无需手动迁移享受最新性能优化
这样,你能把时间和精力放在业务创新上,而不是追着故障跑。
立即启用 阿里云 ES Serverless,持续迭代内核与智能性能护栏,让集群始终稳定高效。