整体架构:
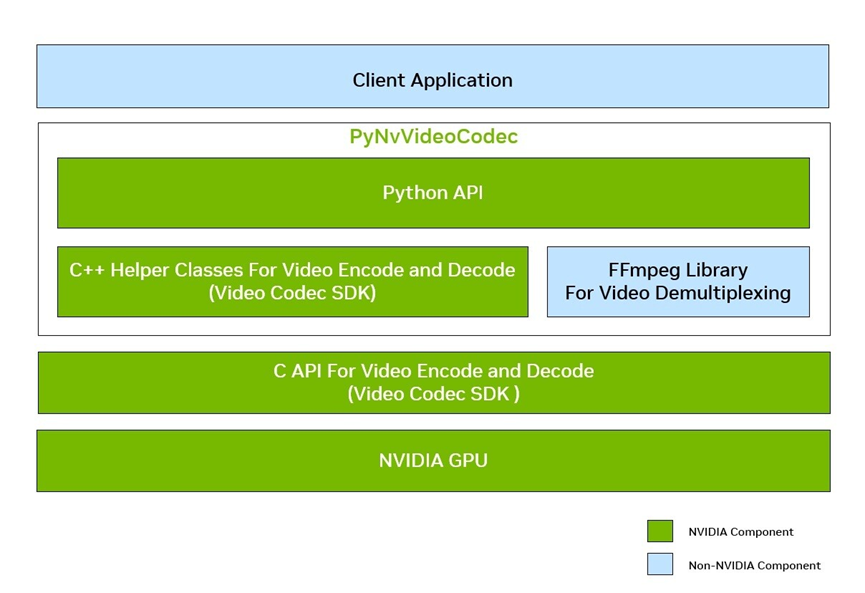
优点:
基于PyNvVideoCodec,视频解码、AI模型推理都在显存操作,减少了显存和cpu的数据拷贝。
缺点:
接口只支持本地视频,不支持实时视频流。
环境安装:
pip install PyNvVideoCodec
示例代码:
#!/usr/bin/env python3
"""
Decode + FasterRCNN 推理(单 GPU,零拷贝)
运行: python infer.py
"""
import os
import torch
import torchvision
from torchvision import transforms as T
import pycuda.driver as cuda
import pycuda.autoinit # 自动创建并激活 primary context
import PyNvVideoCodec as nvc
# --------------------------------------------------
# 1. 参数
# --------------------------------------------------
VIDEO_PATH = "input.mp4" # 上一步生成的文件
BATCH = 3 # 每次拿 3 帧
DEVICE_ID = 0 # 用 0 号 GPU
BUFFER_SIZE = 30 # 解码器缓冲帧数
# --------------------------------------------------
# 2. 创建 CUDA stream(必须与后面 torch 用同一个)
# --------------------------------------------------
cuda.init()
dev = cuda.Device(DEVICE_ID)
ctx = dev.retain_primary_context() # 与 pycuda.autoinit 同一个 context
ctx.push()
stream = cuda.Stream() # PyCUDA stream
ctx.pop()
# --------------------------------------------------
# 3. 初始化 ThreadedDecoder
# --------------------------------------------------
decoder = nvc.ThreadedDecoder(
enc_file_path = VIDEO_PATH,
buffer_size = BUFFER_SIZE,
start_frame = 0,
cuda_context = int(ctx.handle), # 裸指针
cuda_stream = int(stream.handle),# 裸指针
use_device_memory = True,
output_color_type = nvc.OutputColorType.RGBP # planar RGB
)
# 2. 立即取元数据
meta = decoder.get_stream_metadata()
if meta: # 防止空指针
print("width :", meta.width)
print("height:", meta.height)
print("average_fps:", meta.average_fps)
print("codec_name:", meta.codec_name)
# --------------------------------------------------
# 4. 加载模型
# --------------------------------------------------
device = torch.device(f'cuda:{DEVICE_ID}')
model = torchvision.models.detection.fasterrcnn_resnet50_fpn(pretrained=True)
model.to(device)
model.eval()
# --------------------------------------------------
# 5. 推理循环
# --------------------------------------------------
def main():
DESIRED_FPS = 5 # 想要的几帧/秒
stride = max(1, round(25 / DESIRED_FPS)) # 25 是源 fps,可 ffprobe 读出来
frame_idx = 0
while True:
frames = decoder.get_batch_frames(BATCH) # list[PyCapsule]
if len(frames) == 0:
break
batch_tensor = []
for frm in frames:
if frame_idx % stride == 0: #抽帧
# 5.1 dlpack 零拷贝 → torch
t = torch.from_dlpack(frm) # shape: (C, H, W) planar RGB
t = t.float() / 255.0
batch_tensor.append(t)
frame_idx = (frame_idx + 1)%100
# 5.4 组 batch
if len(batch_tensor)!=0:
batch = torch.stack(batch_tensor).to(device, non_blocking=True)
# 5.5 推理
with torch.no_grad():
outputs = model(batch) # List[Dict[str, Tensor]]
print(f"[INFO] decoded {len(frames)} frames, "
f"detected {[len(o['labels']) for o in outputs]} objects")
#del decoder
print("[INFO] done.")
if __name__ == "__main__":
main()参考链接:
https://developer.nvidia.com/pynvvideocodec
https://docs.nvidia.com/video-technologies/pynvvideocodec/pynvc-api-prog-guide/index.html#overview
https://catalog.ngc.nvidia.com/orgs/nvidia/resources/pynvvideocodec?version=2.0.2
https://gitee.com/mirrors/videoprocessingframework/tree/master