在缓存架构中,"缓存穿透" 是最棘手的问题之一 ------ 恶意请求或不存在的数据会绕过缓存直接穿透到数据库,导致数据库连接耗尽、响应延迟,甚至宕机。上一篇我们提到的 Cache Aside 等策略,无法从根本上解决缓存穿透,而 布隆过滤器(Bloom Filter) 和 空值缓存(Null Cache) 是工业界最常用的两种解决方案。
本文将从「核心原理、实现逻辑、优缺点、适用场景」四个维度,详细拆解这两种方案,帮你理解它们的差异与最佳实践。
一、先搞懂:什么是缓存穿透?
在讲解决方案前,先明确缓存穿透的定义:当用户请求的数据 在缓存中不存在,且在数据库中也不存在 时,每次请求都会 "穿透" 缓存,直接查询数据库(因为缓存无法回写 "不存在的数据")。
比如:
- 恶意攻击者批量请求
user:999999(不存在的用户 ID); - 业务误操作查询不存在的商品 ID
product:-1; - 数据已被删除,但缓存未及时清理(极端场景)。
这类请求的特点是 高频、无缓存命中、数据库无结果,如果并发量较大,会直接压垮数据库。
二、空值缓存(Null Cache):最简单的 "兜底" 方案
核心原理
空值缓存的思路非常直接:对于数据库中不存在的数据,在缓存中存储一个 "空值"(如 null、""、-1),并设置合理的过期时间(TTL)。后续再收到相同请求时,直接返回缓存中的空值,避免穿透到数据库。
本质是 "用缓存记录'不存在的数据'",让缓存成为数据库的 "第一道屏障",即使数据不存在,也能命中缓存。
实现逻辑(结合 Cache Aside 策略)
空值缓存的核心是在 "缓存未命中 + 数据库无结果" 时,主动回写空值到缓存。完整流程如下:
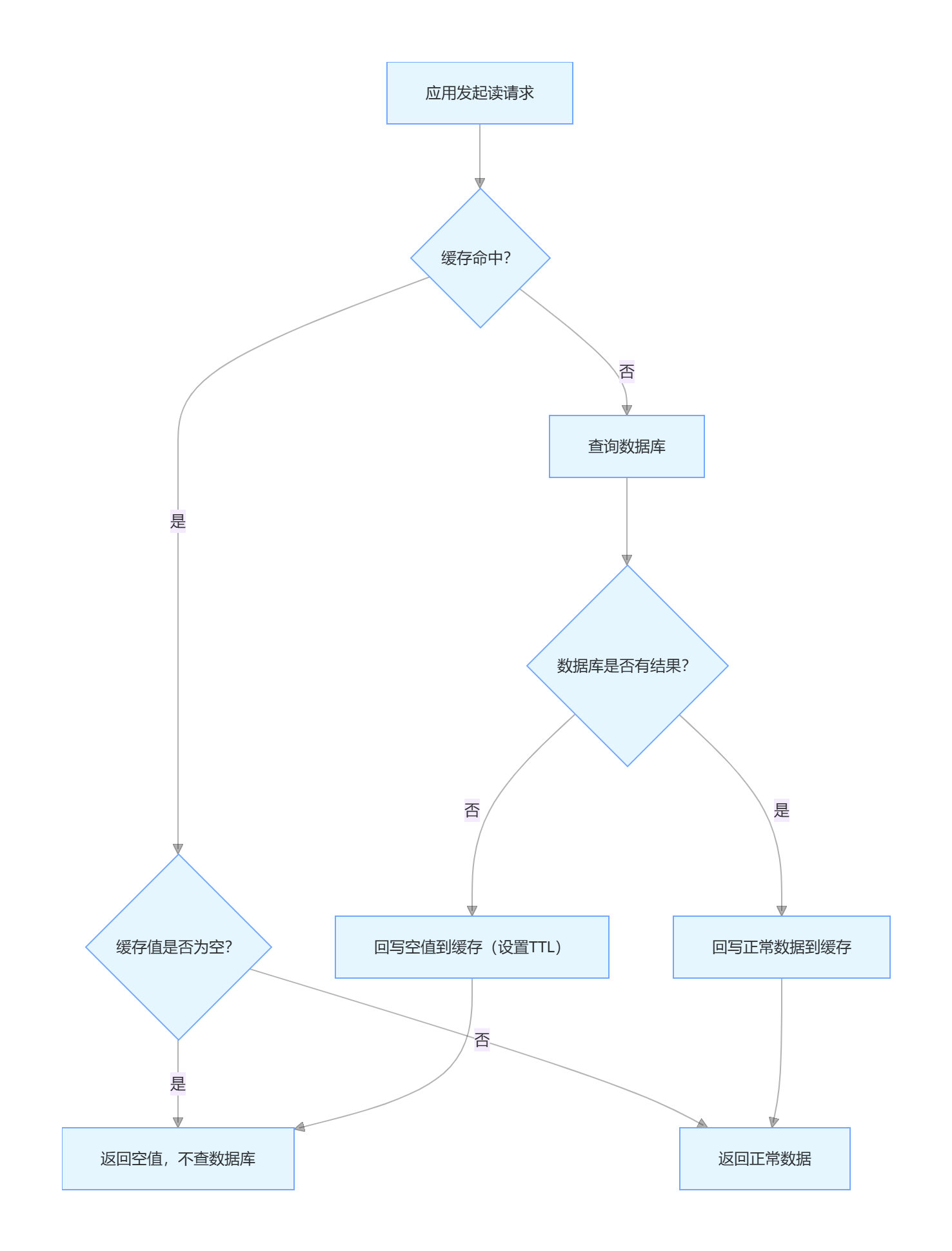
代码示例(Redis 实现)
java
String cacheKey = "user:999999"; // 不存在的用户ID
String userData = redis.get(cacheKey);
if (userData != null) {
if ("NULL".equals(userData)) { // 命中空值缓存
return null; // 直接返回空,不查库
}
return userData; // 命中正常缓存,返回数据
}
// 缓存未命中,查询数据库
userData = db.query("SELECT * FROM users WHERE id=999999");
if (userData == null) {
// 数据库无结果,回写空值缓存,设置10分钟过期
redis.setex(cacheKey, 600, "NULL");
return null;
} else {
// 数据库有结果,回写正常缓存
redis.setex(cacheKey, 3600, userData);
return userData;
}关键细节
- 空值标识 :需定义明确的空值标记(如
NULL字符串、-1数字),避免与真实数据冲突(比如不能用""作为空值,若真实数据可能是空字符串)。 - 过期时间(TTL) :空值缓存必须设置过期时间(如 5-10 分钟),原因是:
- 避免恶意攻击者批量请求不存在的 Key,导致缓存中积累大量空值,占用内存;
- 防止后续数据库中新增了该数据(如用户
999999被创建),但缓存仍返回空值(数据一致性问题)。
- 过期时间选择:根据业务数据新增频率调整 ------ 数据新增频繁的场景(如电商新品上架),TTL 可设短(5 分钟);新增少的场景(如用户 ID),TTL 可设长(30 分钟)。
优缺点分析
优点:
- 实现简单:无需引入额外组件,仅需在原有缓存逻辑上增加 "空值回写" 分支,开发成本极低;
- 理解成本低:逻辑直观,团队协作时无需额外沟通成本;
- 无误判风险:空值缓存记录的是 "确定不存在的数据",不会出现 "误判为不存在" 的情况(相比布隆过滤器);
- 适配所有场景:无论数据是否有规律(如随机不存在的 Key),都能生效。
缺点:
- 内存浪费:如果存在大量 "随机不存在的 Key"(如恶意攻击的
user:100000、user:100001...),空值缓存会占用大量缓存空间(虽然有 TTL,但高频攻击下仍会浪费); - 短暂不一致窗口:空值缓存过期前,若数据库中新增了该数据,会导致缓存返回空值(不一致),窗口长度 = TTL;
- 无法防御 "海量随机 Key 攻击":比如攻击者生成 100 万个随机不存在的 Key,空值缓存会存储 100 万个空值,既占用内存,又可能触发缓存淘汰(挤出正常缓存数据)。
适用场景
- 业务中 "不存在的数据" 数量较少(如正常用户查询错误 ID,而非恶意攻击);
- 开发资源有限,不想引入复杂组件;
- 数据新增频率较低,可接受短暂不一致窗口;
- 非高频随机 Key 攻击场景。
三、布隆过滤器(Bloom Filter):高效的 "存在性校验" 方案
核心原理
布隆过滤器是一种 空间效率极高的概率型数据结构,核心作用是 "快速判断一个元素是否存在于一个集合中"------ 它只能回答 "可能存在" 或 "一定不存在",无法回答 "一定存在"。
底层逻辑:
- 初始化一个长度为
m的二进制数组(bit 数组),所有位初始化为 0; - 定义
k个独立的哈希函数(如 MD5、SHA1 的片段); - 当插入一个元素(如存在的用户 ID
1001)时:- 用
k个哈希函数分别计算元素的哈希值,再对m取模,得到k个数组索引; - 将这
k个索引对应的二进制位设为 1;
- 用
- 当查询一个元素(如
999999)时:- 用同样的
k个哈希函数计算索引,检查对应的二进制位是否全为 1; - 若有任意一位为 0 → 元素 "一定不存在"(直接返回,避免查库);
- 若全为 1 → 元素 "可能存在"(需进一步查缓存和数据库,因为可能存在哈希碰撞)。
- 用同样的
直观示例:
假设 m=10,k=2,插入元素 1001:
- 哈希函数 1 计算
1001→ 索引 3 → 位 3 设为 1; - 哈希函数 2 计算
1001→ 索引 7 → 位 7 设为 1;查询元素999999: - 哈希函数 1 计算 → 索引 2(位 2 为 0)→ 判定 "一定不存在";查询元素
1002(哈希碰撞): - 哈希函数 1 计算 → 索引 3(位 3 为 1);
- 哈希函数 2 计算 → 索引 7(位 7 为 1)→ 判定 "可能存在"(实际不存在,属于误判)。
实现逻辑(缓存架构中的位置)
布隆过滤器的核心是 "在查缓存之前,先做存在性校验",过滤掉 "一定不存在" 的请求,流程如下:
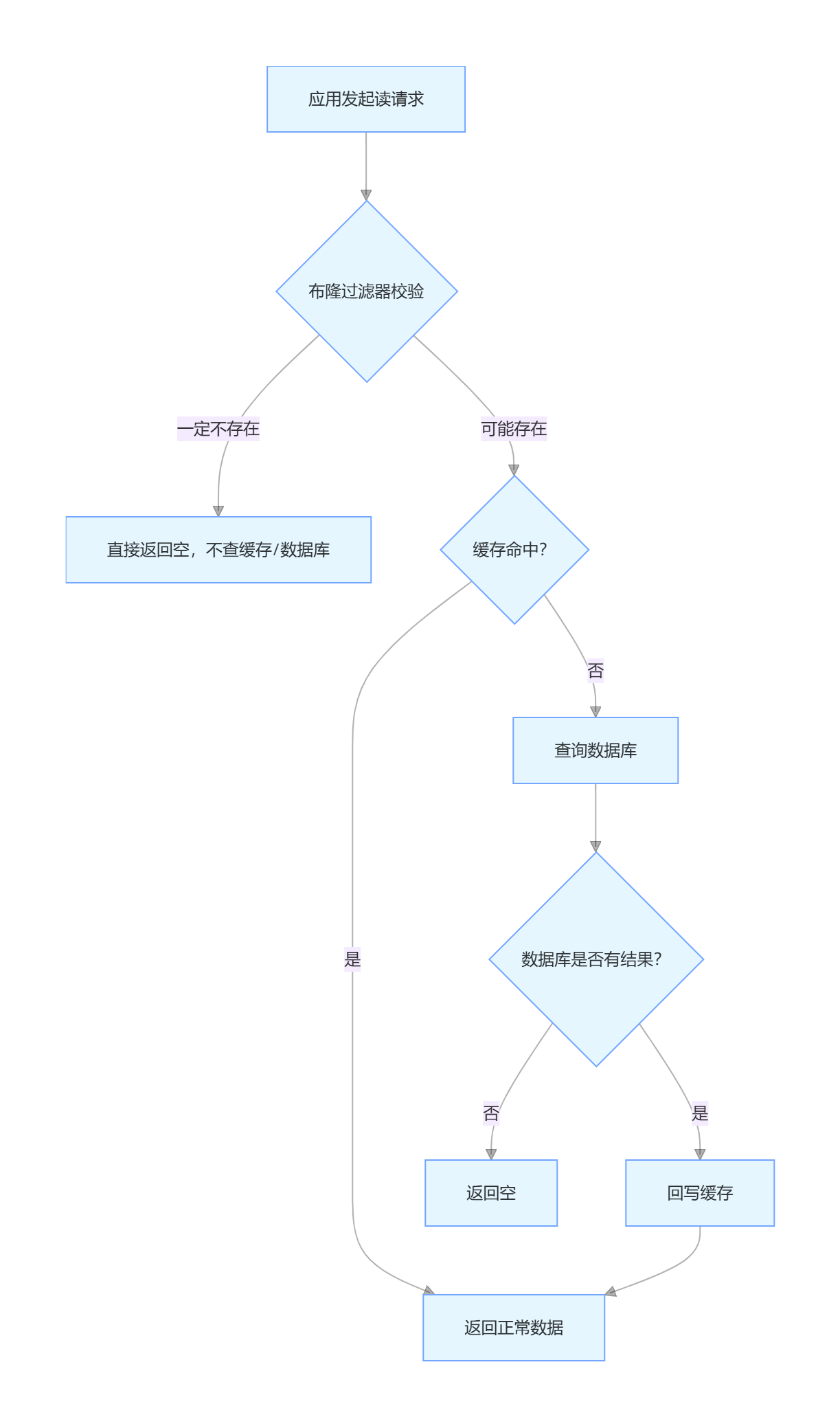
代码示例(Redis 布隆过滤器实现)
Redis 本身不直接支持布隆过滤器,但可通过 bitfield 命令手动实现,或使用 Redis 4.0+ 提供的 bf 模块(推荐,原生支持)。
1. 初始化布隆过滤器(插入所有存在的用户 ID)
java
// 假设数据库中所有存在的用户ID列表
List<Long> existUserIds = db.queryAll("SELECT id FROM users");
// 初始化布隆过滤器(m=1000000,k=3,误判率约0.1%)
String filterKey = "bloom:user:exist";
for (Long userId : existUserIds) {
// 用3个哈希函数计算索引(简化示例,实际需用独立哈希函数)
long hash1 = Math.abs(userId.hashCode()) % 1000000;
long hash2 = Math.abs((userId + "salt1").hashCode()) % 1000000;
long hash3 = Math.abs((userId + "salt2").hashCode()) % 1000000;
// 设定位为1
redis.bitOp(BitOp.SET, filterKey, hash1, 1);
redis.bitOp(BitOp.SET, filterKey, hash2, 1);
redis.bitOp(BitOp.SET, filterKey, hash3, 1);
}2. 查询时校验布隆过滤器
java
String cacheKey = "user:999999";
String filterKey = "bloom:user:exist";
// 布隆过滤器校验
long hash1 = Math.abs(999999L.hashCode()) % 1000000;
long hash2 = Math.abs((999999L + "salt1").hashCode()) % 1000000;
long hash3 = Math.abs((999999L + "salt2").hashCode()) % 1000000;
boolean bit1 = redis.getBit(filterKey, hash1) == 1;
boolean bit2 = redis.getBit(filterKey, hash2) == 1;
boolean bit3 = redis.getBit(filterKey, hash3) == 1;
if (!bit1 || !bit2 || !bit3) {
// 一定不存在,直接返回空
return null;
}
// 可能存在,继续查缓存和数据库
String userData = redis.get(cacheKey);
if (userData != null) {
return userData;
}
userData = db.query("SELECT * FROM users WHERE id=999999");
if (userData != null) {
redis.setex(cacheKey, 3600, userData);
}
return userData;关键参数与误判率
布隆过滤器的核心是平衡 空间占用 、查询效率 和 误判率,由两个参数决定:
m:bit 数组长度(越大,误判率越低,空间占用越高);k:哈希函数个数(越多,误判率越低,但查询 / 插入效率越低)。
误判率计算公式(简化):
p ≈ (1 - e^(-kn/m))^k其中 n 是插入的元素个数。
常见配置(参考):
| 元素个数 n | bit 数组长度 m | 哈希函数个数 k | 误判率 p |
|---|---|---|---|
| 100 万 | 1000 万 | 7 | 0.01% |
| 100 万 | 800 万 | 5 | 0.1% |
| 1000 万 | 1 亿 | 7 | 0.01% |
优缺点分析
优点:
- 空间效率极高:用 bit 数组存储,100 万元素 + 0.1% 误判率仅需约 1MB 空间(相比空值缓存节省几个数量级);
- 查询 / 插入效率高:时间复杂度为 O (k)(k 是哈希函数个数,通常为 3-10),毫秒级响应;
- 防御海量随机 Key 攻击:无论攻击者生成多少随机 Key,布隆过滤器都能快速过滤,不会占用大量缓存空间;
- 无内存溢出风险:bit 数组长度固定,不会因不存在的 Key 增多而膨胀。
缺点:
- 存在误判率:无法 100% 准确判断 "存在",只能判断 "一定不存在"------ 误判时会穿透到缓存和数据库(但误判率可通过参数优化到极低,如 0.1%);
- 不支持删除操作:bit 数组的位是 "多元素共享" 的,删除一个元素会把其他元素的位也置为 0,导致误判率飙升(解决方案:使用 "计数布隆过滤器",但空间占用会增加);
- 初始化成本高:需要提前将所有 "存在的数据" 插入布隆过滤器(适合静态数据或变更不频繁的数据);
- 数据变更维护复杂:如果数据库中数据频繁新增 / 删除(如实时商品上架 / 下架),需要同步更新布隆过滤器(如新增时插入,删除时需用计数布隆过滤器),增加维护成本。
适用场景
- 存在海量 "不存在的数据" 请求(如恶意攻击、高频无效查询);
- 缓存空间有限,无法承受大量空值缓存;
- 数据变更不频繁(如用户 ID、商品 ID,新增 / 删除频率低);
- 可接受极低误判率(如 0.1% 以下)的场景。
四、空值缓存 vs 布隆过滤器:核心对比与选型建议
核心对比表
| 对比维度 | 空值缓存(Null Cache) | 布隆过滤器(Bloom Filter) |
|---|---|---|
| 核心作用 | 缓存 "不存在的数据",直接命中 | 快速校验 "是否一定不存在",过滤请求 |
| 空间占用 | 高(每个不存在的 Key 占一个缓存项) | 极低(bit 数组,按位存储) |
| 误判风险 | 无(确定不存在) | 有(可优化到极低) |
| 支持删除 | 支持(过期自动删除) | 原生不支持(需计数布隆过滤器) |
| 初始化成本 | 无(按需回写空值) | 高(需提前插入所有存在数据) |
| 维护成本 | 低(无需额外维护) | 中高(数据变更需同步更新) |
| 适配数据类型 | 任意数据(动态 / 静态) | 静态数据或变更不频繁数据 |
| 防御海量攻击 | 弱(会占用大量缓存) | 强(无缓存占用) |
| 一致性窗口 | 有(TTL 期间) | 无(数据同步后即时生效) |
选型建议
-
优先选 空值缓存:
- 开发资源有限,不想引入复杂组件;
- 不存在的数据请求量少,或数据变更频繁;
- 无法接受任何误判(如金融、支付场景);
- 缓存空间充足,无需担心空值占用内存。
-
优先选 布隆过滤器:
- 存在海量不存在的数据请求(如恶意攻击、高频无效查询);
- 缓存空间有限,无法承受大量空值缓存;
- 数据变更不频繁(如用户 ID、商品 ID);
- 可接受极低误判率(如 0.1% 以下)。
-
组合使用(推荐!工业界常用方案):
- 用 布隆过滤器 过滤 "一定不存在" 的请求,减少空值缓存的写入;
- 用 空值缓存 处理布隆过滤器的 "误判请求"(即布隆过滤器判定 "可能存在",但数据库实际不存在的数据),避免二次穿透。
组合流程:
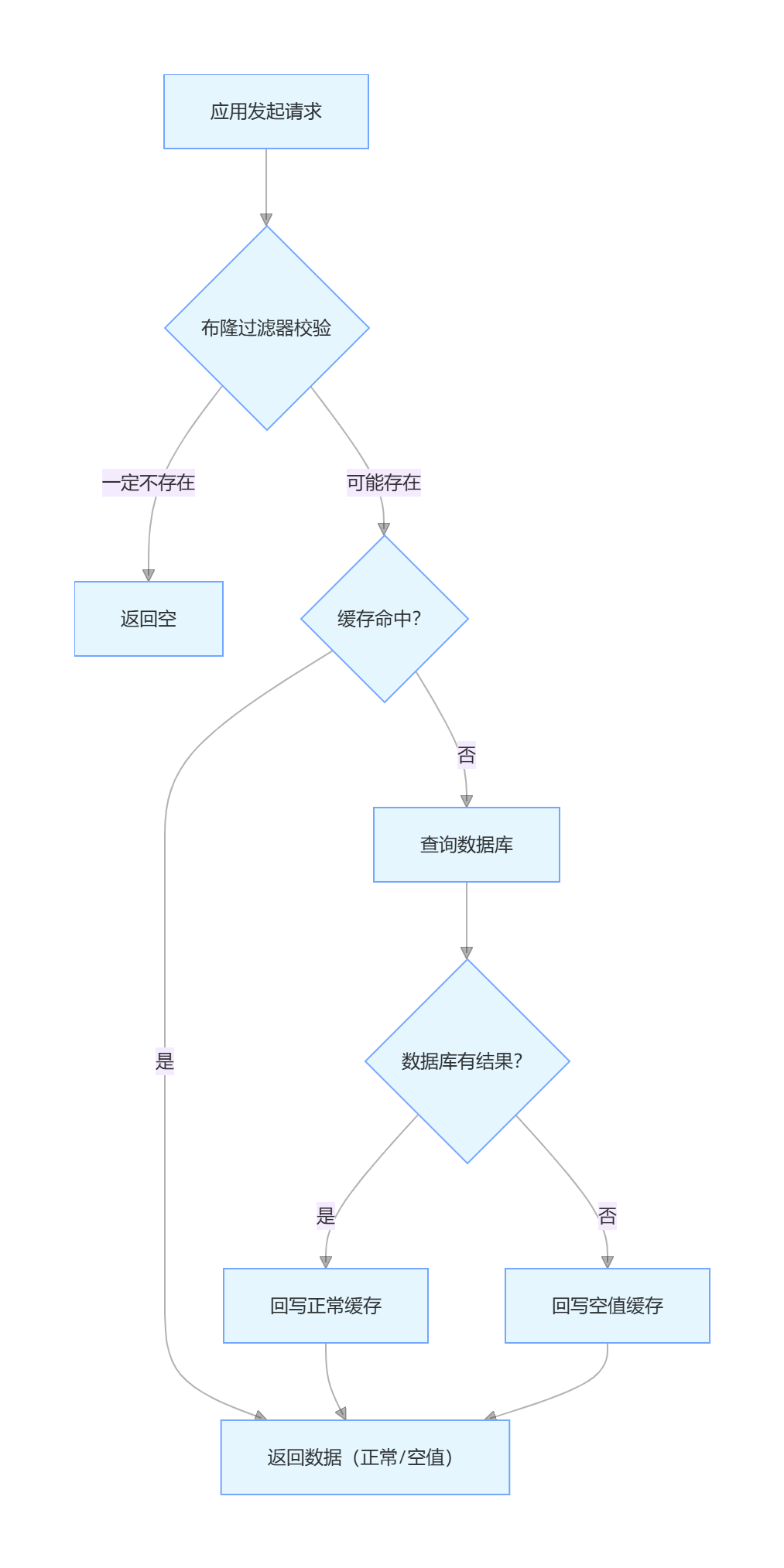
- 优势:兼顾布隆过滤器的 "高效过滤" 和空值缓存的 "零误判",完美解决缓存穿透,且内存占用低、维护成本可控。
总结
缓存穿透的本质是 "不存在的数据无法被缓存",而布隆过滤器和空值缓存从不同角度解决了这个问题:
- 空值缓存是 "兜底方案",简单直接,无误判,但占用内存;
- 布隆过滤器是 "前置过滤方案",高效省内存,但有轻微误判。
在实际架构中,组合使用两者 是最优解 ------ 用布隆过滤器挡掉绝大多数无效请求,用空值缓存处理少量误判请求,既保证了性能,又避免了缓存穿透,同时控制了内存占用和维护成本。
核心选型原则:根据 "不存在的数据请求量" 和 "数据变更频率" 决策------ 请求量小、变更频繁用空值缓存;请求量大、变更少用布隆过滤器;两者结合则覆盖绝大多数场景。