学习大纲
AI的基础概念
LLM服务调用方式
- 代理方式:国外大模型,如gpt大模型
- OneApi方式:支持一些国产大模型和国外模型。 输出统一的接口
- 厂商原生接口:阿里云的百炼大模型平台
- Ollama方式:开源的本地私有化部署大模型,如 DeepSeek 等。
Prompt指令工程
使用LangChain + LangSmith + FastApi主流框架进行搭建
流量包智能推荐客服
Prompt工程基础用例
将应用封装成API接口进行调用,支持历史对话记忆、流式输出和非流式输出,并在前端处理流式和非流式数据。使用Gradio完成WebUi页面的搭建,并完成整个前后端的交互。支持几多个厂商的大模型调用。
流量包智能推荐客服质量检测用例
Cot思维链
它展示了人工智能在解决复杂问题时能够模仿人类思维的方式,分解问题并逐步解决,从而提高答案的准确性。
Self-Consistency 自洽性
一种对抗"幻觉"的手段。就像做数学题,要多次验算一样。
RAG 知识增强生成
LangChain + LangSmith + FastApi + Chroma 框架
私有健康档案知识库用例
文本预处理后进行灌库
文档加载 -> 文档切片 -> 向量化 -> 灌入向量数据库
RAG在线检索
获取用户问题 -> 用户问题向量化 -> 检索向量数据库 -> 将检索结果和用户问题填入 Prompt 模版 -> 用最终的Prompt调用LLM -> 由LLM生成回复。
在RAG在线检索的基础上增加 re-rank 功能处理逻辑。re-rank是一种用于信息检索系统的技术,旨在对初步检索的结果进行进一步排序,以提高相关性和准确性
OpenSPG KAG开源框架测试用例
了解和使用OpenSPG框架。
KAG是蚂蚁集团OpenSPG发布0.5版本中出现的知识增强生成(KAG)的专业领域知识服务框架,旨在充分利用知识图谱和向量检索的优势,增强大型语音模型和知识图谱,以解决RAG挑战。
OpenSPG-Server部署、产品模式(Web端)测试、开发者模式测试(调整配置文件->初始化项目->提交schema->构建索引->在线检索->知识图谱可视化(图数据库neo4j) )
Agent多智能体协作
意图识别和分诊Agent用例
LangChain + LangSmith + LangGraph + PostgreSQL
基于LangChain、LangGraph框架和PostgreSQL数据库,结合工具调用和动态路由实现用户意图识别和分诊工作流用例。短期记忆、长期记忆 + 对话历史管理 + Function Calling + PostgreSQL持久化
营销战略协作智能体用例
CrewAI + FastApi + Celery
基于CrewAi框架实现Ai Agent复杂工作流程,支持工作流的并发异步调度和生命周期状态监测
Fine-Tuning 大模型微调
微酒店推荐垂直领域大模型并应用的完整闭环案例
本项目旨在提供一个微酒店推荐垂直领域大模型并应用的完整闭环案例作为参考案例,使用的基础大模型为Qwen2.5-7B-Instruct
构建业务数据库 -> 数据增强、制作数据集 -> 轻量化大模型微调 -> 大模型应用测试 -> 封装大模型推理应用接口并测试
及介绍什么是大模型微调,轻量化微调流程图
AGI的核心能力模型
懂业务: 懂用户、客户、需求、市场、运营、商业模式
- 懂用户:知道目标用户是谁,他们的习惯和痛点。
- 懂客户:明白付钱的人(可能是老板或公司)想要什么
- 懂需求:能分清什么是用户想要的
- 懂市场:了解行业趋势,比如AI客户现在火,未来可能是AI医疗
- 懂运营:知道AI上线后怎么推广、留住用户
- 懂商业模式:清楚怎么赚钱,比如按月收费、卖数据分析服务还是免费引流再卖广告。
懂AI:知道AI能做什么,不能做什么,怎么做更快、更好、更便宜
- 知道AI能做什么:明白AI擅长什么,比如画图、写文、预测销量,不玄乎也不吹牛
- 知道AI不能做什么:清楚AI的局限,比如没法完全代替人做创意设计或处理复杂感情
- 知道AI怎么做更快:懂得用现在的工具或模型,比如拿开源代码改改就能用,不用从头训练
- 知道AI怎么做更好:会调参数、选对数据,让AI结果更准,比如客服机器人别回答的鹿群不对马嘴
- 知道AI怎么做更便宜:能省资源,比如用小模型跑简单任务,不浪费算力。
懂编程:实现一个符合业务需求的产品
实现一个符合业务需求的产品,会写代码把想法落地。比如,客户要个销售预测工具,能用python写个程序,接上AI模型,吐出结果给老板看。还得简单好用,别让用户学半天。
AGI场景落地-建议
1、从最熟悉的领域入手
2、找"文本进、文本出"的场景
3、别求大而全。将任务拆解。先解决任务小场景
4、让AI学最厉害员工的能力,辅助其他员工,降本增效。
大模型 LLM
LLm是什么及如何生成结果
LLM(Large Language Model),大语音模型是人工智能领域的一种技术。
基于深度学习(特别是神经网络中的Transform架构),通过在海量文本数据上训练,能够理解和生成自然语音的AI系统。
那么LLM是如何生成结果的呢?
- 通俗原理:其实,它只是根据上下文,猜下一个词(的概率)
- 略深点的通俗原理:训练和推理是大模型工作的两个核心过程(用人类比,训练就是学,推理就是用。学以致用)
用不严格但通俗的语言描述训练和推理
训练
大模型阅读了人类说过的所有话。这就是机器学习。
训练过程会把说过的话中的不同Token同时出现的概率存入神经网络文件,保存的数据就是参数,也叫权重。
LLM通常有几十亿到上千亿个参数(Parameters),这些参数是通过训练调整的,决定了模型对语言的理解和生成能力。比如,像DeepSeek-R1有671B个参数。
推理
给推理程序若干 Token(Prompt),程序会加载大模型权重算出概率最高的下一个Token是什么。再用生成的Token加上上下文,技能继续生成下一个Token,
Token是什么?
在LLm中,Token是文本处理的基本单位,不是简单的"单词"或"字符",而是经过Tokenizer(分词器)处理后的一段文本片段。
Token的长度和内容取决于具体的分词策略和模型设计
Prompt单位
- 可能是一个英文单词,也可能是半个,三分之一个
- 可能是一个中文词或一个汉字、半个汉字、甚至三分之一汉字
- 大模型在开训前,需要先训练一个tokenizer模型,将所有文本切成token
LLM生成机制的内核
深度学习模型架构:Transform、RWKV、Mamba。 其中Transform架构,仍是主流,但已经不是最先进的了。
Transform
是由谷歌在 2017年提出的架构(论文《Attention is All You Need》),彻底改变了自然语言处理(NLP)领域。它放弃了传统的循环神经网络(RNN),转而使用**自注意力机制(Self-Attention)**来并行处理序列数据。
RWKV(Recurrent Weighted Key-Value)
是一种较新的架构,结合了RNN和Transform的优点,试图解决 Transform 的效率问题。它由社区驱动开发(非谷歌主导),近年来收到关注。
Mamba
是2023-2024年间提出的新型架构,旨在取代 Transform,尤其针对长序列和高效率需求。它基于结构化状态空间模型(Structured State Space Models,SSM)。
目前只有 Transform被证明了符合 scaling-law。RMKV和Mamba的 scaling-law 研究还在进行中,初步结果显示它们可能符合类似规律,但数据和实现规模还不足以媲美 Transform 的成熟验证。
什么是Scaling Law?
Scaling Law是深度学习领域的一种经验规律(由OpenAI 等研究提出),表明模型性能(比如语音理解能力)会随着三个因素的增加而提升。
- 模型参数量(更大的网络)
- 训练数据量(更多文本)
- 计算资源(更多算力)
LLM应用业务架构
- AI Embedded模式,人主导,中间某个环节AI参与,如人脸识别
- AI Copilot模式,AI和人主导,每个环节AI辅助参与
- AI Agent,人把事情丢给AI,AI自己规划自己去做
目前 Agent 还太超前,Copilot值得追求
LLM 应用技术架构
有4种主流的技术架构,应用技术特点:门槛低、天花板高
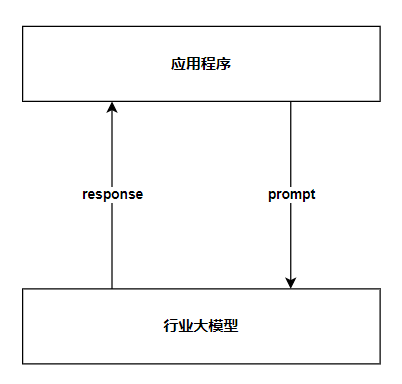
指令工程 Prompt Engineering
使用场景:知识问答、情报分析、写作、编程、文本加工等
核心思想:构造一个有效且正确的Prompt(指令具体、信息丰富、尽量少歧义)
技术架构图
给大模型新知识RAG
使用场景:智能知识库、智能诊断、数字分身、待例子的Prompt等
核心思想:人找知识,会查资料;LLM找知识,会查向量数据库(向向量检索即相似度检索)
技术架构图如下
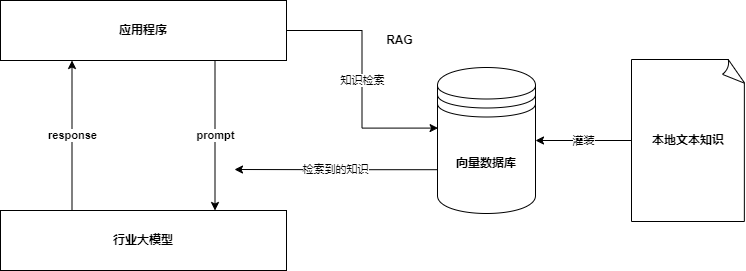
此时,Prompt会带着问题和知识交给大模型,大模型基于知识进行总结反馈给应用。
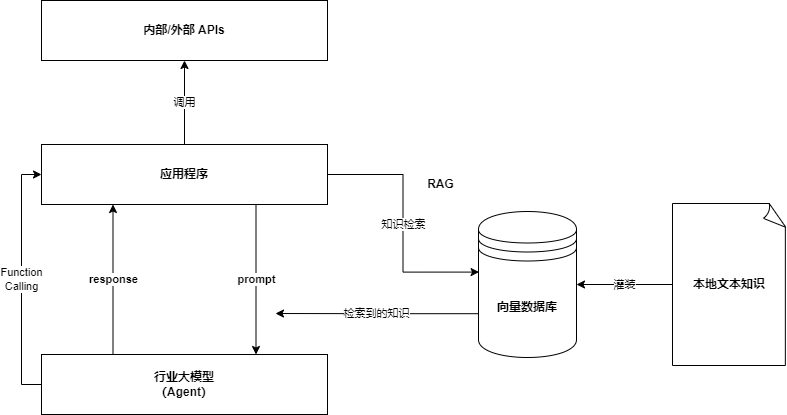
让大模型对接外界 Function Calling
使用场景:智能助手,下一代搜索引擎、机器人、Agent等
基本过程:大模型调用外部工具处理问题。
Agent使用 Json 格式方向提出要求,应用了大模型的规则性原理。
技术架构图如下
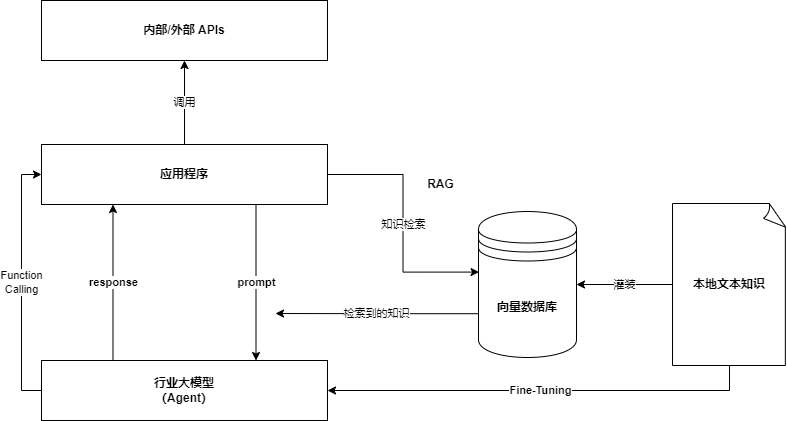
让大模型深度理解知识 Fine-tuning
使用场景:智能知识库、智能诊断、数字分身等
核心思想:人阅读背诵,理解资料;LLM进行增强学习训练。
基本过程:给基础大模型增加参数(补充垂直领域的新知识),基于大模型进行轻量化微调。Fine-tuning 过程全都在使用工具(不需要重新造轮子)。
技术架构图如下:
与RAG解决的场景类似,差别:
- RAG 查询完资料就会忘记,下次需要重新再查
- 微调后的垂直领域行业大模型(Fine-Tuning)是将知识记住,可立即给结果
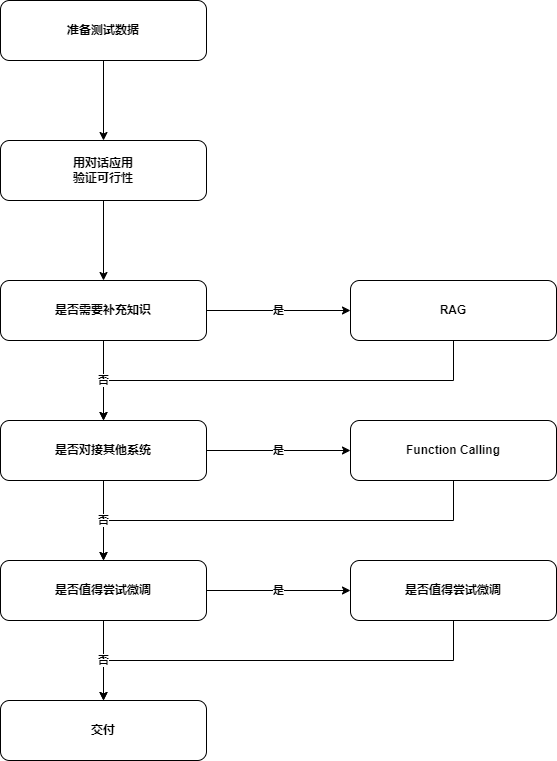
如何选择技术路线
面对一个需求如何开始,如何选择技术方案。
常用思路如下:
前两步是最重要的,耗时最高
值得尝试 Fine-Tuning的情况:
- 提供模型输出的稳定性
- 用户量大,降低推理成本的意义很大
- 提高大模型的生成速度
- 需要私有化部署
本地环境准备
需要使用到 Pycharm 和 Anaconda。
Pycharm是ide,用于开发代码。
https://www.jetbrains.com/pycharm/download/?section=windows
Anaconda用于独立的Python环境,可以做好Python 版本隔离,方便开发。
https://www.anaconda.com/download