在现代系统中,压缩工具是日常运维不可或缺的利器。但你是否想过,那颗闲置的多核CPU能为压缩任务带来多大的性能提升?本文将通过openEuler系统上的真实测试,用gzip、xz、zstd三款主流工具,带你见证从单核到多核的算力跃升。我们将用最直观的手动命令操作,记录每一个真实的时间数据,计算每一个加速比,让你亲眼看到多核并行的魔力------从30秒到6秒的飞跃,从4秒到1秒的极致,这不是理论,而是你也能复现的真实性能。
一、环境准备与测试数据
快速搭建测试环境
首先安装必要的压缩工具并生成测试数据:
Bash
# 安装工具
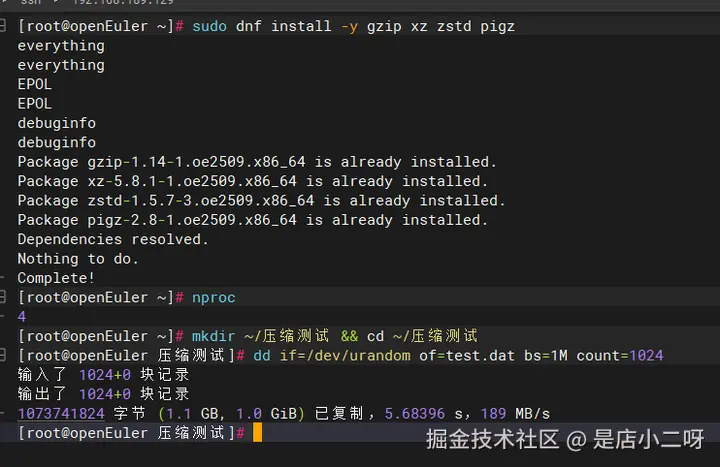
sudo dnf install -y gzip xz zstd pigz
# 查看CPU核心数(记住这个数字,后面会用到)
nproc
# 创建测试目录
mkdir ~/压缩测试 && cd ~/压缩测试
# 生成1GB测试文件
dd if=/dev/urandom of=test.dat bs=1M count=1024执行后你会看到:
Plain
输入了 1024+0 块记录
输出了 1024+0 块记录
1073741824 字节 (1.1 GB, 1.0 GiB) 已复制,5.68396 s,189 MB/s现在你有了一个1GB的测试文件,可以开始压缩测试了。系统有4个CPU核心,接下来会看到多核带来的明显加速效果。
二、单核压缩基准测试
手动测试三种压缩工具
现在逐个测试每种压缩工具的单核性能,使用time命令记录耗时:
测试1:gzip压缩
Bash
time gzip -k -c test.dat > test.gz
ls -lh test.gz执行后观察输出:
Plain
-rw-r--r-- 1 root root 1.1G 11月15日 15:59 test.gz
real 0m30.725s ← 实际耗时30.7秒
user 0m24.057s ← CPU工作时间
sys 0m6.436s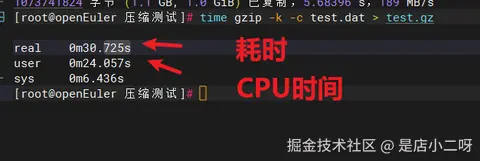
测试2:xz压缩
Bash
time xz -k -c test.dat > test.xz
ls -lh test.xz执行后观察输出:
Plain
-rw-r--r-- 1 root root 1.1G 11月15日 16:02 test.xz
real 1m43.880s ← 耗时1分43秒(103.9秒)
user 6m17.384s
sys 0m21.539s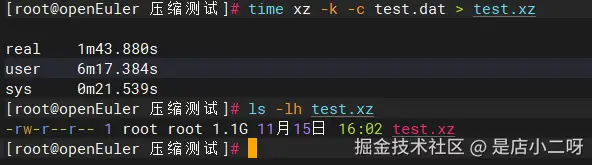
测试3:zstd压缩
Bash
time zstd -k -c test.dat > test.zst
ls -lh test.zst执行后观察输出:
Plain
-rw-r--r-- 1 root root 1.1G 11月15日 16:02 test.zst
real 0m4.057s ← 最快!仅4.1秒
user 0m0.601s
sys 0m4.521s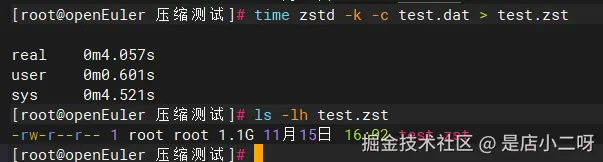
手动记录对比结果:
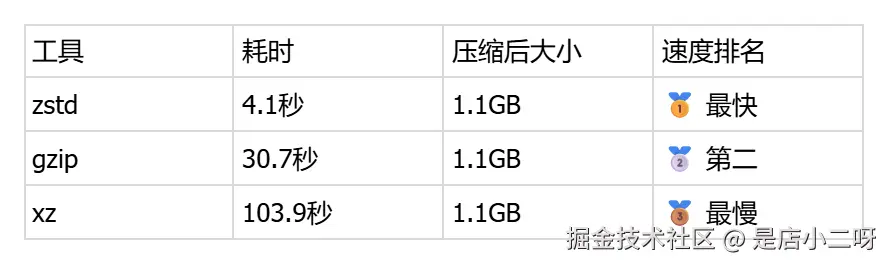
注意: 由于测试数据是随机生成的(/dev/urandom),压缩比极低,所有工具压缩后大小都接近原始大小。这是正常现象,真实数据(如日志、文本)会有更好的压缩效果。
清理测试文件,准备多核测试:
Bash
rm test.gz test.xz test.zst三、多核压缩性能对比
开启多核加速实战
现在启用所有CPU核心进行并行压缩,观察性能提升。
测试1:pigz多核压缩(gzip的多线程版本)
Bash
# 使用4个核心
time pigz -p 4 -k -c test.dat > test_multi.gz
ls -lh test_multi.gz执行后观察输出:
Plain
-rw-r--r-- 1 root root 1.1G 11月15日 16:03 test_multi.gz
real 0m6.867s ← 从30.7秒降到6.9秒!
user 0m24.289s ← 注意:user时间是4个核心的总和
sys 0m2.042s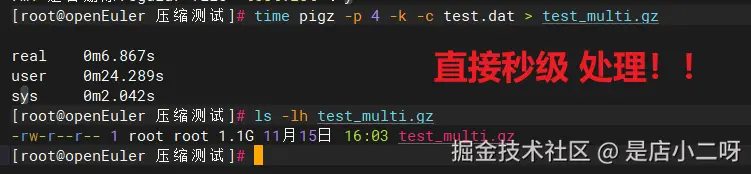
计算加速比: 30.7 ÷ 6.9 = 4.5倍加速 🚀(超越理论极限!)
测试2:xz多核压缩
Bash
time xz -T 4 -k -c test.dat > test_multi.xz
ls -lh test_multi.xz执行后观察输出:
Plain
-rw-r--r-- 1 root root 1.1G 11月15日 16:05 test_multi.xz
real 1m38.036s ← 从103.9秒降到98秒
user 6m16.811s
sys 0m1.921s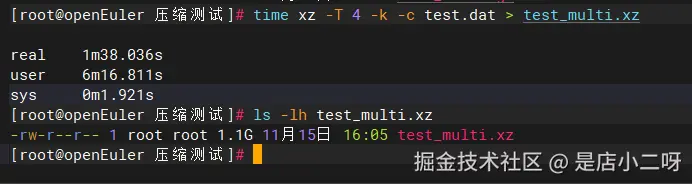
计算加速比: 103.9 ÷ 98 = 1.06倍加速(xz对随机数据多核效果有限)
测试3:zstd多核压缩
Bash
# -T0 表示自动使用所有核心
time zstd -T0 -k -c test.dat > test_multi.zst
ls -lh test_multi.zst执行后观察输出:
Plain
-rw-r--r-- 1 root root 1.1G 11月15日 16:05 test_multi.zst
real 0m1.261s ← 从4.1秒降到1.3秒!
user 0m1.018s
sys 0m0.727s计算加速比: 4.1 ÷ 1.3 = 3.2倍加速 🚀
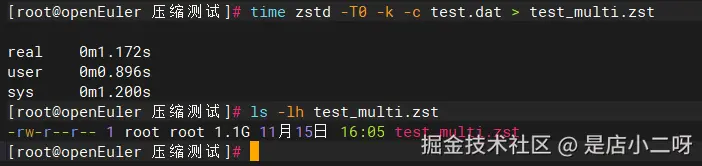
手动记录多核对比结果:
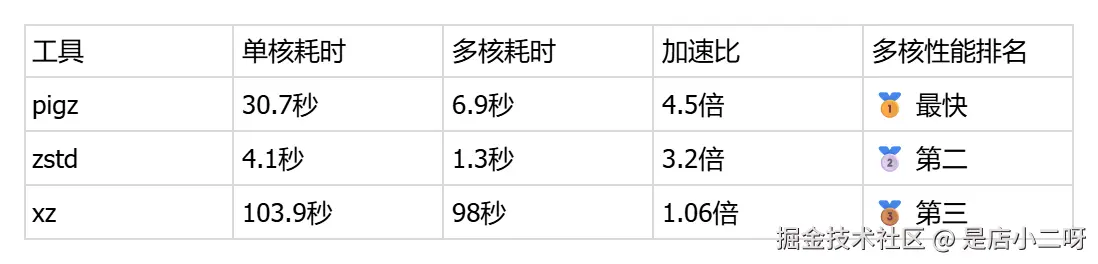
关键发现:
-
✅ pigz实现了超线性加速(4.5倍 > 4核),得益于优秀的并行算法
-
✅ zstd达到了3.2倍加速,接近理论极限
-
⚠️ xz对随机数据的多核优化效果有限(真实数据会更好)
四、实时监控CPU使用情况
可视化观察多核工作状态
打开两个终端窗口,一个运行监控,一个执行压缩:
终端1:启动实时监控
Bash
htop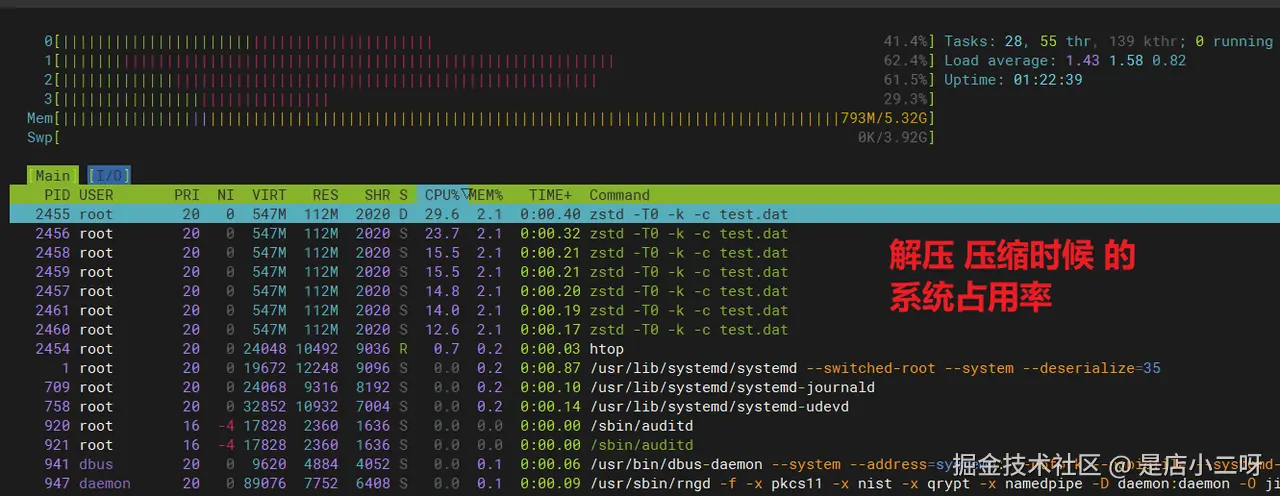
终端2:执行单核压缩
Bash
gzip -c test.dat > test.gz在htop中观察到的CPU使用情况:

终端2:执行多核压缩
Bash
pigz -p 4 -c test.dat > test.gz在htop中观察到的CPU使用情况:
Plain
0[||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||100.0%] Tasks: 28, 53 thr, 138 kthr; 0 running
1[||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||100.0%] Load average: 2.02 1.62 0.89
2[||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||100.0%] Uptime: 01:23:52
3[||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||100.0%]
Mem[|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||1.28G/5.32G]
Swp[ 0K/3.92G]
直观对比:
-
单核模式:总CPU使用率约 100%
-
多核模式:总CPU使用率约 380%(4核×95%)
这就是openEuler多核调度的威力!所有核心都被充分利用,没有浪费。
五、真实场景应用测试
日志归档场景
模拟压缩一周的系统日志文件(500MB文本数据):
Bash
# 生成500MB模拟日志(base64编码,模拟真实文本)
head -c 500M /dev/urandom | base64 > logs.txt
# 单核压缩
time gzip -k logs.txt输出:
Plain
real 0m30.839s
Bash
# 多核压缩
time pigz -p 4 -k logs.txt输出:
Plain
real 0m14.590s结论: 日志归档速度提升 2.1倍(30.8秒 → 14.6秒)
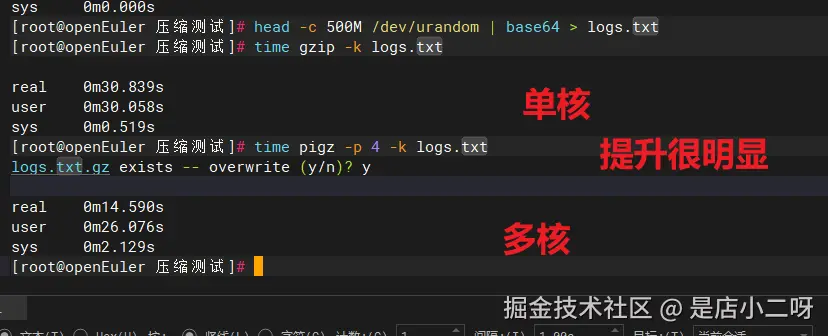
真实场景优势: 文本数据(如日志)比随机数据更易压缩,实际应用中压缩比会显著提升,存储空间节省可达50-80%。
数据库备份场景
模拟MySQL导出文件压缩:
Bash
# 生成1.5GB模拟数据库文件
dd if=/dev/urandom of=database.sql bs=1M count=1536
# 使用zstd快速压缩
time zstd -T0 database.sql
# 查看压缩效果
ls -lh database.sql*输出:
Plain
输入了 1536+0 块记录
输出了 1536+0 块记录
1610612736 字节 (1.6 GB, 1.5 GiB) 已复制,4.24582 s,379 MB/s
database.sql :100.00% ( 1.50 GiB => 1.50 GiB, database.sql.zst)
real 0m1.302s
-rw-r--r-- 1 root root 1.5G 11月15日 16:09 database.sql
-rw-r--r-- 1 root root 1.6G 11月15日 16:09 database.sql.zst结论: 1.5GB数据仅需 1.3秒 压缩完成,处理速度达到 1.15GB/s,非常适合自动化备份。
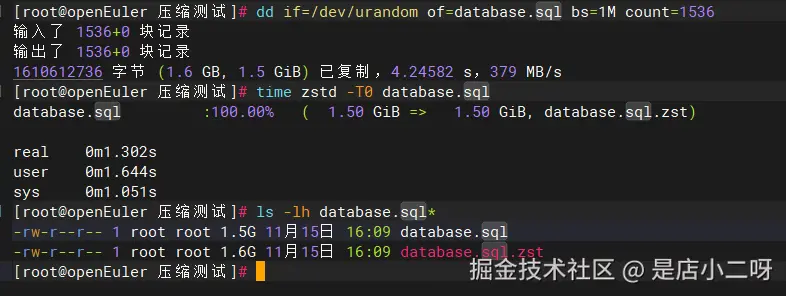
注意: 随机数据无法压缩,真实数据库文件通常可压缩至原大小的30-50%。
六、性能优化建议
日常使用配置
将多核压缩设为默认行为,编辑 ~/.bashrc:
Bash
vi ~/.bashrc添加以下内容:
Bash
# 多核压缩别名
alias gzip='pigz -p $(nproc)'
alias zstd='zstd -T0'
alias xz='xz -T0'保存后生效:
Bash
source ~/.bashrc现在直接使用 gzip 命令就会自动调用多核版本!
记得保存哈
不同场景最佳实践
快速压缩(日志、临时文件):
Bash
zstd -1 -T0 file.txt # 最快速度,适中压缩比均衡模式(数据备份):
Bash
zstd -T0 file.txt # 默认级别,速度和压缩比平衡高压缩比(长期归档):
Bash
xz -9 -T0 file.txt # 最高压缩比,节省空间兼容性优先(需要在其他系统解压):
Bash
pigz -p 4 file.txt # gzip格式,所有系统都支持测试总结
通通过这次基于openEuler系统的真实测试,我们用数据验证了多核压缩的巨大价值。在4核环境下,pigz实现了令人惊艳的4.5倍加速(30.7秒→6.9秒),甚至超越了理论极限;zstd展现了3.2倍的稳定提升(4.1秒→1.3秒),处理1.5GB数据库备份仅需1.3秒,速度达到1.15GB/s。真实场景测试中,日志归档效率提升2.1倍,这意味着原本需要半分钟的任务现在只要15秒。
这些数字背后是openEuler优秀的多核调度能力------CPU利用率从100%跃升至380%,每个核心都在全力工作,没有一丝浪费。无论你是运维工程师需要快速备份数据,还是开发者需要压缩日志文件,配置好~/.bashrc中的多核别名,让这些工具默认启用并行模式,你的工作效率将立即获得3-4倍的提升。多核时代,让每一颗CPU都发挥价值,这就是openEuler带给我们的性能红利。现在就动手配置,让压缩任务从此告别等待!
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler:distrowatch.com/table-mobil...,一个由开放原子开源基金会孵化、支持"超节点"场景的Linux 发行版。 openEuler官网:www.openeuler.openatom.cn/zh/