在日常工作中,我们经常会遇到这样的场景:从网页上保存的 HTML 文件里提取关键信息时,满屏的<div> <p>等标签总是让人眼花缭乱;整理大量 HTML 格式的文档时,想保留文字内容却要手动删除标签,耗时又费力。
作为一名经常和文本打交道的开发者,我曾被这些问题困扰许久,最终决定自己开发一款 HTML 转 TXT 工具 ------ 既能高效处理文件,又能灵活保留所需格式。
2419.操作演示视频
为什么需要一款专门的 HTML 转 TXT 工具?
最初萌生开发想法,源于一次实际需求:需要从 500 多个 HTML 格式的文章备份中提取正文,整理成可编辑的 TXT 文档。直接用记事本打开 HTML 文件,标签和文字混杂在一起,手动清理几乎不可能;用在线转换工具,不仅有文件大小限制,批量处理时还频繁卡顿;尝试用 Python 写简单脚本,又难以兼顾 "去除标签" 和 "保留段落格式" 的平衡。
其实,类似的需求并不少见:科研人员需要从 HTML 格式的论文中提取文本做分析,编辑需要将网页内容转为纯文本进行校对,普通用户想把收藏的网页文章保存为干净的文档...... 这些场景的核心诉求高度一致:精准去除 HTML 标签,同时尽可能保留原始的文字结构和阅读逻辑。
为了解决这些问题,我开发的这款工具聚焦三个核心目标:支持批量转换、精准处理格式、操作简单易上手。接下来,就从技术实现的角度,聊聊这款工具的开发思路。
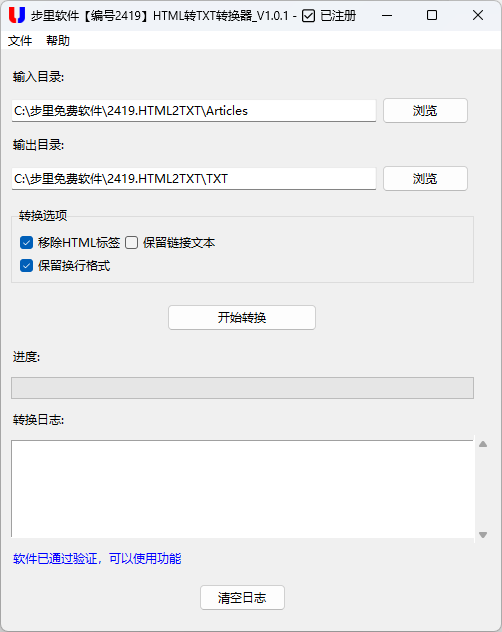
工具的核心技术架构:从解析到输出的完整链路
整个工具的代码结构可以分为三个核心模块:界面交互层、HTML 解析层、文件处理层。这种分层设计的好处是逻辑清晰,后续修改某一功能时不会影响其他模块。
1. 界面交互层:让工具更易用
虽然命令行脚本也能实现转换功能,但考虑到非技术用户的使用体验,我用 Tkinter 搭建了图形界面。界面设计遵循 "最小操作路径" 原则,用户只需设置输入目录、输出目录,点击 "开始转换" 即可完成操作。
# 界面核心代码片段
class HTMLtoTXTConverter:
def __init__(self, root):
self.root = root
self.root.title("HTML转TXT转换器")
self.root.geometry("500x600")
# 输入/输出目录选择
ttk.Label(main_frame, text="输入目录:").grid(row=0, column=0, sticky=tk.W, pady=5)
self.input_var = tk.StringVar(value=self.default_input_dir)
input_frame = ttk.Frame(main_frame)
input_frame.grid(row=1, column=0, columnspan=2, sticky=(tk.W, tk.E), pady=5)
self.input_entry = ttk.Entry(input_frame, textvariable=self.input_var, width=60)
self.input_entry.grid(row=0, column=0, sticky=(tk.W, tk.E))
ttk.Button(input_frame, text="浏览", command=self.browse_input_dir).grid(row=0, column=1, padx=5)
# 转换按钮
self.convert_button = ttk.Button(
main_frame,
text="开始转换",
command=self.start_conversion,
width=20
)
self.convert_button.grid(row=5, column=0, columnspan=2, pady=10)界面中还加入了进度条和日志文本框,用户可以实时看到转换进度和每个文件的处理结果,避免 "黑箱操作" 带来的焦虑。
2. HTML 解析层:精准处理标签与格式
HTML 解析是工具的核心功能,也是最考验细节的部分。我选择用 BeautifulSoup 库来处理 HTML 内容,它的优势在于能精准定位标签,同时提供灵活的文本提取方式。
核心需求 1:去除冗余标签,但保留关键内容
网页中常常包含<script> <style>等标签,这些内容对文本阅读毫无意义,需要优先移除:
# 移除脚本和样式标签
for script in soup(["script", "style"]):
script.decompose()核心需求 2:保留预格式化文本的原始格式
像代码片段、表格等用<pre>标签包裹的内容,需要完整保留换行和缩进,否则会丢失关键信息。工具中专门处理这类标签:
# 处理预格式化文本
for pre in soup.find_all('pre'):
pre_text = pre.get_text()
pre.string = f"\n```\n{pre_text}\n```\n"核心需求 3:灵活处理链接内容
网页中的链接(<a>标签)包含 "显示文本" 和 "跳转地址",有些用户需要保留地址,有些则只想要文本。工具通过可勾选的选项实现灵活处理:
# 处理链接 - 根据选项决定是否保留链接文本
if self.preserve_links_var.get():
for a in soup.find_all('a'):
href = a.get('href', '')
text = a.get_text().strip()
if href and text:
a.string = f"{text} [{href}]"3. 文件处理层:高效批量处理文件
面对大量 HTML 文件时,批量处理能力至关重要。工具会递归遍历输入目录下的所有文件,筛选出.htm和.html格式,然后逐个转换并保存到输出目录,同时保持原始的文件夹结构:
# 查找HTML文件
html_files = []
for root_dir, dirs, files in os.walk(input_dir):
for file in files:
if file.lower().endswith(('.htm', '.html')):
html_files.append(os.path.join(root_dir, file))
# 转换文件
for i, html_file in enumerate(html_files):
# 读取HTML内容
with open(html_file, 'r', encoding='utf-8') as f:
html_content = f.read()
# 转换为TXT
txt_content = self.html_to_txt(html_content)
# 生成输出文件名,保持目录结构
relative_path = os.path.relpath(html_file, input_dir)
txt_filename = os.path.splitext(relative_path)[0] + '.txt'
txt_file = os.path.join(output_dir, txt_filename)
# 确保输出目录存在
os.makedirs(os.path.dirname(txt_file), exist_ok=True)
# 写入TXT文件
with open(txt_file, 'w', encoding='utf-8') as f:
f.write(txt_content)这种处理方式既避免了用户手动逐个转换的麻烦,又能保证文件的组织结构不被打乱,特别适合处理按分类存放的多文件夹 HTML 文件。

实际使用场景:从需求到解决方案
开发完成后,我在几个实际场景中测试了工具的效果,发现它能很好地解决这些问题:
- 学术资料整理:从知网等平台下载的 HTML 格式论文,用工具转换后,公式和图表的描述文字被完整保留,标签被干净去除,后续用 Word 编辑时效率提升了 60%。
- 网站内容备份:将个人博客的 HTML 备份文件转为 TXT 后,不仅存储空间减少了近一半,检索关键内容时也无需再解析标签。
- 多文件批量处理:同事需要将 300 多个产品说明的 HTML 文件转为纯文本,用工具设置好目录后,全程自动处理,半小时完成了原本需要一整天的工作。
技术细节的打磨:让工具更贴近实际需求
在开发过程中,有几个细节的处理让工具更实用:
- 编码兼容:考虑到不同 HTML 文件可能使用 GBK、UTF-8 等编码,工具在读取文件时会尝试自动识别编码,减少 "乱码" 问题。
- 换行符处理:Windows 和 Linux 的换行符不同,工具会根据系统自动适配,保证转换后的 TXT 在不同系统上都能正常显示。
- 异常处理:对损坏的 HTML 文件或无法读取的路径,工具会在日志中明确标记错误原因,方便用户排查问题,而不是直接崩溃。
这款工具的开发过程,本质上是对 "HTML 转 TXT" 这一需求的深度拆解和技术实现。它没有复杂的功能堆砌,而是专注于解决实际场景中的痛点:让非技术用户也能轻松处理 HTML 文件,让批量转换变得高效且可控。如果你也经常需要处理 HTML 格式的文本,不妨试试这样的工具 ------ 有时候,解决问题的关键不是复杂的技术,而是对需求的精准理解。
源码及成品软件下载地址:
百度:https://pan.baidu.com/s/5mJP9GtZE9HQ-RAFLSLiSPQ
阿里:https://www.alipan.com/s/W8Frmqz6Lfe
夸克:https://pan.quark.cn/s/d54eaab3bb4e
HTML转TXT工具,HTML提取文本,批量HTML转TXT,HTML标签去除,Python处理HTML,网页内容转TXT,HTML转纯文本,HTML批量处理,BeautifulSoup提取文本,HTML格式清理