在日常办公和内容处理中,我们经常会遇到这样的场景:下载的 HTML 网页保存了大量冗余标签,复制粘贴后格式混乱;积累的 WORD 文档需要提取纯文本进行汇总分析,手动复制效率极低;不同格式的文档(.html、.doc、.docx)混杂在一起,转换时需要切换多种工具...... 这些看似琐碎的问题,其实耗费了我们大量的时间成本。
作为一名长期与文档打交道的开发者,我和团队决定开发一款工具,专门解决多格式文档到纯文本的转换难题。经过多次迭代,我们最终完成了这款集 HTML 与 WORD 转换于一体的工具,今天想和大家分享其中的开发思路与功能实现。
2419.更新1.1
一、从用户痛点出发:我们为什么需要一款专业转换工具?
在开发初期,我们调研了大量用户的文档处理习惯,发现了三个核心痛点:
- 格式冗余问题 :HTML 文件中的
<script>、<style>等标签,WORD 中的复杂排版,都会干扰纯文本的提取; - 格式兼容性问题:.html、.htm、.doc、.docx 等格式需要不同的处理逻辑,普通用户难以掌握多种工具;
- 批量处理效率问题:面对成百上千个文档时,手动逐个转换几乎不可能完成。
基于这些需求,我们明确了工具的核心目标:用简单的操作实现多格式文档的批量、精准转换,保留有用信息的同时剔除冗余内容。
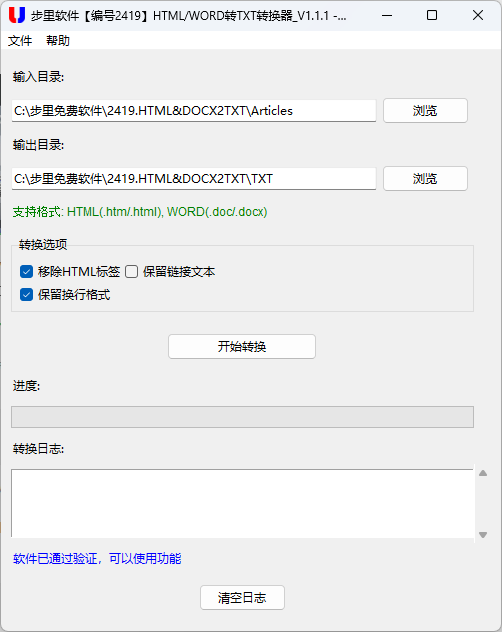
二、技术实现:如何让转换既精准又高效?
一款可靠的转换工具,核心在于对不同格式文件的解析逻辑。我们将工具分为三个核心模块:HTML 解析模块、WORD 解析模块、批量处理与界面交互模块,每个模块都针对具体问题设计了解决方案。
1. HTML 转 TXT:从标签海洋中提取有效文本
HTML 文件的转换难点在于如何剔除冗余标签(如脚本、样式),同时保留有价值的内容结构(如段落、链接、预格式化文本)。我们采用了 BeautifulSoup 库作为解析核心,配合自定义规则实现精准处理。
例如,对于 HTML 中的脚本和样式标签,我们直接移除以避免干扰:
# 移除脚本和样式标签
for script in soup(["script", "style"]):
script.decompose()对于预格式化文本(如<pre>标签包裹的代码块),我们保留其原始格式,用特殊符号标记边界:
# 处理预格式化文本
for pre in soup.find_all('pre'):
pre_text = pre.get_text()
pre.string = f"\n```\n{pre_text}\n```\n"针对链接内容,我们设计了可选功能:用户可以选择是否保留链接的 URL。当需要保留时,会将<a href="url">文本</a>转换为 "文本 url" 的形式:
# 处理链接 - 根据选项决定是否保留链接文本
if self.preserve_links_var.get():
for a in soup.find_all('a'):
href = a.get('href', '')
text = a.get_text().strip()
if href and text:
a.string = f"{text} [{href}]"最后通过处理换行和空白,确保输出文本的可读性:
# 处理换行和空白
if self.keep_line_breaks_var.get():
# 保留段落分隔
lines = text.splitlines()
cleaned_lines = []
for line in lines:
line = line.strip()
if line:
cleaned_lines.append(line)
text = '\n'.join(cleaned_lines)
2. WORD 转 TXT:兼顾.doc 与.docx 的解析逻辑
WORD 文档的转换比 HTML 更复杂,因为.doc 和.docx 采用了完全不同的文件格式(.docx 是 XML 压缩包,.doc 是二进制格式)。我们针对性地设计了两套解析方案:
对于.docx 文件,使用 python-docx 库直接解析其内部的 XML 结构,提取段落和表格内容:
def docx_to_txt(self, docx_path):
"""将DOCX文件转换为文本"""
doc = docx.Document(docx_path)
full_text = []
# 提取段落内容
for para in doc.paragraphs:
full_text.append(para.text)
# 处理表格内容
for table in doc.tables:
for row in table.rows:
row_text = []
for cell in row.cells:
row_text.append(cell.text)
full_text.append('\t'.join(row_text)) # 表格单元格用制表符分隔
full_text.append('\n') # 表格后加空行
return '\n'.join(full_text)对于.doc 文件,由于其二进制格式的特殊性,我们借助 win32com 库调用本地 WORD 程序进行解析,确保兼容性:
def doc_to_txt(self, doc_path):
"""将DOC文件转换为文本(使用win32com)"""
# 调用WORD应用
word = client.Dispatch("Word.Application")
word.Visible = False # 后台运行,不显示界面
try:
doc = word.Documents.Open(doc_path)
text = doc.Content.Text # 获取全部文本内容
doc.Close()
finally:
word.Quit() # 确保WORD进程退出
return text
3. 批量处理与交互设计:让工具更易用
为了提升效率,我们设计了批量处理功能:通过遍历指定目录下的所有文件,自动识别.html、.htm、.doc、.docx 格式,逐个转换并保存到输出目录:
# 查找支持的文件(HTML和WORD)
supported_files = []
for root_dir, dirs, files in os.walk(input_dir):
for file in files:
file_lower = file.lower()
if file_lower.endswith(('.htm', '.html', '.doc', '.docx')):
supported_files.append(os.path.join(root_dir, file))
# 转换文件
for i, file_path in enumerate(supported_files):
# 根据文件类型选择转换方法(HTML或WORD)
# ...转换逻辑...
# 生成输出文件并保存
# ...保存逻辑...
self.progress['value'] = i + 1 # 更新进度条在界面设计上,我们采用了 Tkinter 构建简洁的图形界面,用户只需选择输入 / 输出目录,勾选转换选项(如是否保留换行、是否保留链接),点击 "开始转换" 即可完成操作,无需任何代码基础。
三、实际应用:哪些场景能用到这款工具?
经过测试,这款工具在多个场景中都能发挥价值:
- 内容创作者:快速提取网页中的文字素材,剔除广告和冗余标签;
- 办公人员:将大量 WORD 文档转换为纯文本,方便进行内容检索和汇总;
- 研究者:处理爬取的 HTML 数据,提取有效信息用于分析;
- 学生群体:将课件中的 WORD 或网页内容转换为简洁文本,便于笔记整理。
在一次测试中,我们用工具处理了一个包含 200 个混合格式文档的文件夹,总耗时不到 3 分钟,而手动转换同样的内容至少需要 2 小时,效率提升显而易见。
四、开发总结:工具的价值在于解决实际问题
开发这款工具的过程,也是我们不断理解用户需求的过程。从最初单纯的 "格式转换",到后来加入 "保留链接""表格处理" 等细节功能,每一次迭代都源于真实场景的反馈。
如果你也经常被文档格式转换困扰,希望这款工具能帮你节省时间。毕竟,技术的价值从来不是炫技,而是让复杂的事情变得简单。
五、程序代码及成品软件下载:
夸克:https://pan.quark.cn/s/d54eaab3bb4e
123:https://www.123865.com/s/LkEvvd-wAlh
HTML 转 TXT 工具,WORD 批量转文本,doc 转 txt 方法,docx 转文本工具,HTML 标签移除工具,批量文档转换工具,网页文本提取工具,多格式文档转换方法,HTML 转纯文本,WORD 表格转文本