【声明】本博客所有内容均为个人业余时间创作,所述技术案例均来自公开开源项目(如Github,Apache基金会),不涉及任何企业机密或未公开技术,如有侵权请联系删除
背景
上篇 blog
【Ubuntu】【Gitlab】拉出内网 Web 服务:http.server 单/多线程分析(四)
分析了 Python http.server 即使在多线程情况下,也会受到 GIL 的限制,只能实现高并发(处理 IO 密集型任务),而不能做到高并行(CPU 密集型任务),因为同一时刻只能有 1 个线程在跑 Python 代码,整个 CPython 进程只有一把 GIL 锁

下面继续分析
Python http.server 单/多线程分析
下面再多说一下,多线程对这些 IO 密集型任务是有效的原因
- 首先,Python 标准库中的 IO 操作,比如
socket.recv(),file.read(),time.sleep()默认是阻塞的 - CPython 在进入这些系统调用(syscall)之前,会主动释放 GIL
- 等待系统调用返回后,再重新获取 GIL,继续执行 Python 代码
- 在这种场景下,如果 Python 程序启用了 threading 多线程,那么在一个线程释放 GIL 锁时,另一个线程就可以获取 GIL 锁去执行其任务
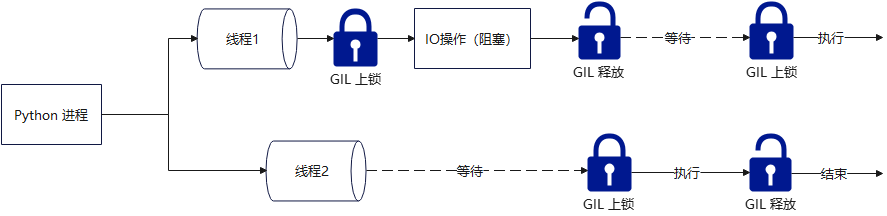
所以,IO 操作本身是阻塞的(线程会卡在系统调用上),但对 Python 解释器来说是非阻塞的(因为 GIL 被释放了,其他线程能跑 Python 代码),这就是多线程 Web 服务器(比如 ThreadingHTTPServer)能处理多个连接的原因,因为每个线程在等网络数据时都会让出解释器
OK,上面提到了 IO 操作是阻塞的,下面也分析下
首先,得先了解 IO 操作的定义,IO = Input & Output,输入输出操作,指的是程序与外部设备或系统交换数据的过程,常见的 IO 操作包括(Python 标准库为例):
- 磁盘 I/O :读写文件,比如 open('file.txt').read()
- 网络 I/O :发送接收 HTTP 请求,数据库查询等,比如
socket.recv(),requests.get() - 终端 I/O :打印,等待用户输入等,
print(),input() - 设备 I/O:读取摄像头,传感器数据等
其核心特征为 IO 操作需要等待外部世界的响应,而外部世界通常比 CPU 慢几万到几百万倍 ,这里特别说下 time.sleep(),严格来说,time.sleep() 不是 IO 操作,但其在 CPython 中的行为类似于 IO 阻塞(会释放 GIL 锁),从而让其他线程有机会运行,所以表现和 IO 操作是一样的,可以归为一类
OK,上面分析完 IO 操作的定义,下面再分析 IO 操作的阻塞行为,首先先要理解阻塞的含义:
- 阻塞(Blocking):当程序发起一个操作后,必须等待它完成才能继续执行下一行代码
- 非阻塞(Non-blocking):程序发起操作后立即返回,不管有没有结果,程序可以先干别的
对软件开发人员来说,阻塞式模型更符合直觉,比如有下面一段代码
python
data = file.read() # 先把数据拿到再说,拿到才能处理,中间怎么拿到的不关心
process(data) # OK,拿到数据了,开始处理可以看到,程序只关心拿到数据后,对其进行处理,并不关心数据是怎么拿到的,如果这个时候是程序是非阻塞的,在 file.read() 调用之后立即返回(也不管数据拿没拿到,获取数据的行为一般是耗时的),那这个时候 process 处理就会出错,因为数据压根没拿到

所以一般操作系统和编程语言默认提供阻塞 IO,就是为了让代码写起来简单
但从速度层面来说:
- CPU 速度 ≈ 纳秒级(10⁻⁹ 秒)
- 外设磁盘读取 ≈ 毫秒级(10⁻³ 秒),时间慢 100 万倍!
- 网络请求 ≈ 几十毫秒到几秒,慢几千万倍!
所以如果 CPU 在等 IO 操作时不挂起当前任务,而是疯狂轮询,会浪费大量 CPU 资源 ,此时系统会变卡,所以操作系统设计为,当线程发起 IO 请求时,内核将其挂起(放入等待队列),直到 IO 完成才唤醒它,这就是阻塞的本质:让出 CPU,避免空转
OK,本篇先到这里,如有疑问,欢迎评论区留言讨论,祝各位功力大涨,技术更上一层楼!!!更多内容见下篇 blog