更多内容关注 Agent 专栏 ~:Agent 专栏
DeepResearch 核心原理
前言
本节介绍基于 Spring AI Alibaba 实现的 DeepResearch 内部的核心流程,涵盖了常见 Agent 的开发范式。
Agent 适用于目标明确,可以动态寻找最优解的场景。
DeepResearch 就是经典的场景,根据用户的问题,大量搜集前置知识,并不断优化调整,以提升最终生成研究报告的质量。
DeepResearch 中,想要生成兼具广度和深度的研究报告,首先需要搜集与用户问题相关的前置知识,为了使搜集到的信息覆盖面足够广,需要先进行问题扩展,即根据用户提问从不同角度重写,用户问题不清晰或角度不对导致搜集大量无关信息,影响生成结果。
问题扩展后得到了覆盖多个角度的问题,基于这些问题去搜集背景知识,搜集过程中涉及到了 RAG 检索、Web 检索,检索分为两类:关键词检索和向量检索,如果同时使用两种检索方式,最终会通过 RRF 对混合检索结果的相关性进行排序。
在执行阶段常见的范式就是任务规划(Planning),先显式输出任务执行步骤,避免任务执行过程中对外为黑盒,将任务规划输出为 json 格式,保证执行节点可以准确理解任务内容。
Agent 基于 LLM,LLM 基于概率,概率意味着会出错,因此 Agent 需要具备从错误中恢复的能力,在 Planning 过程中,如果发现输出的任务规划不是 json 格式,则会循环生成任务规划,直至达到循环次数上限。
最终是效率问题,LLM 需要思考,耗时较久,针对多步执行计划,通过并行节点可以大幅提升处理性能。
Graph 流程如下图:
(高清图链接:www.processon.com/view/link/6...
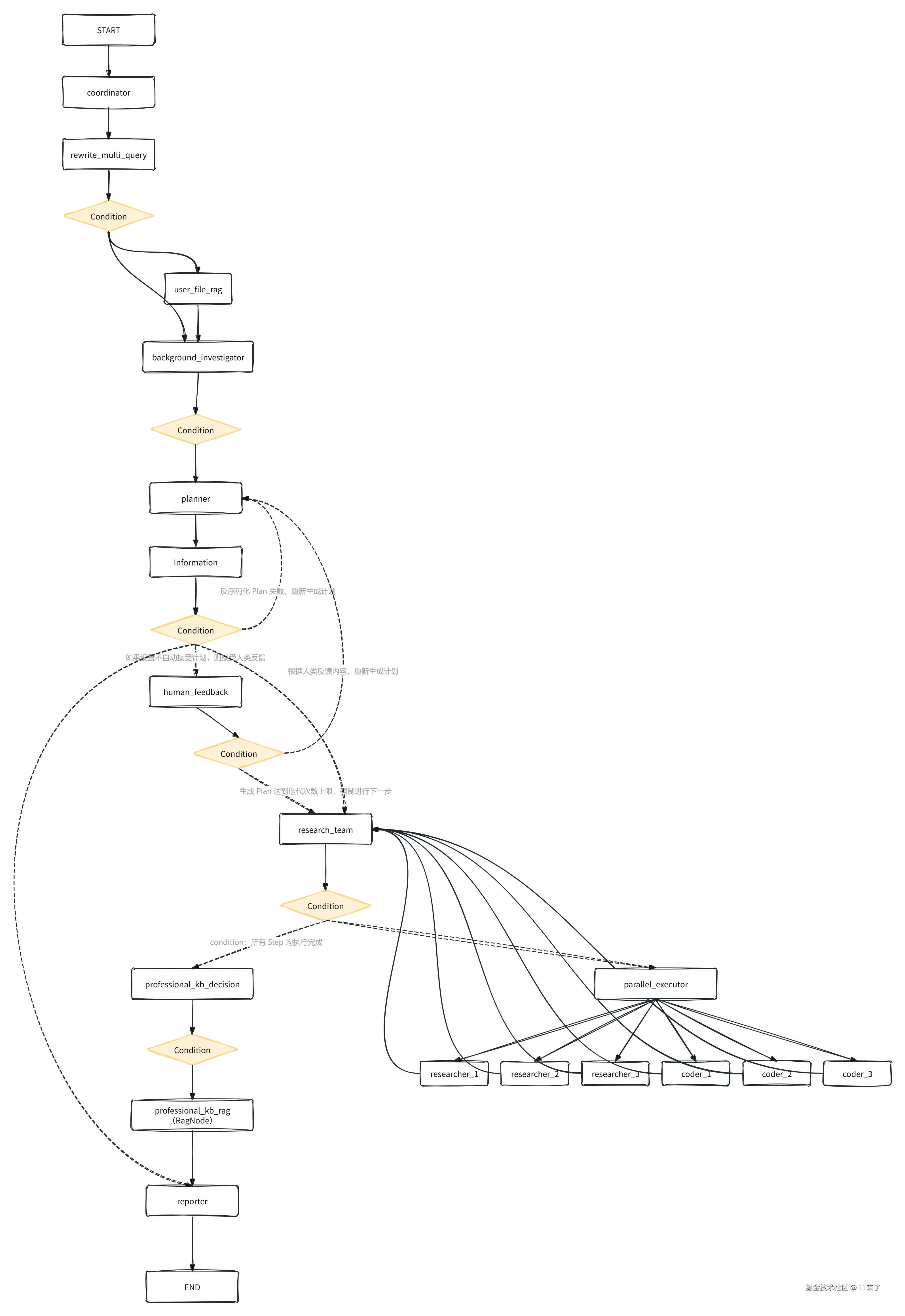
协调节点
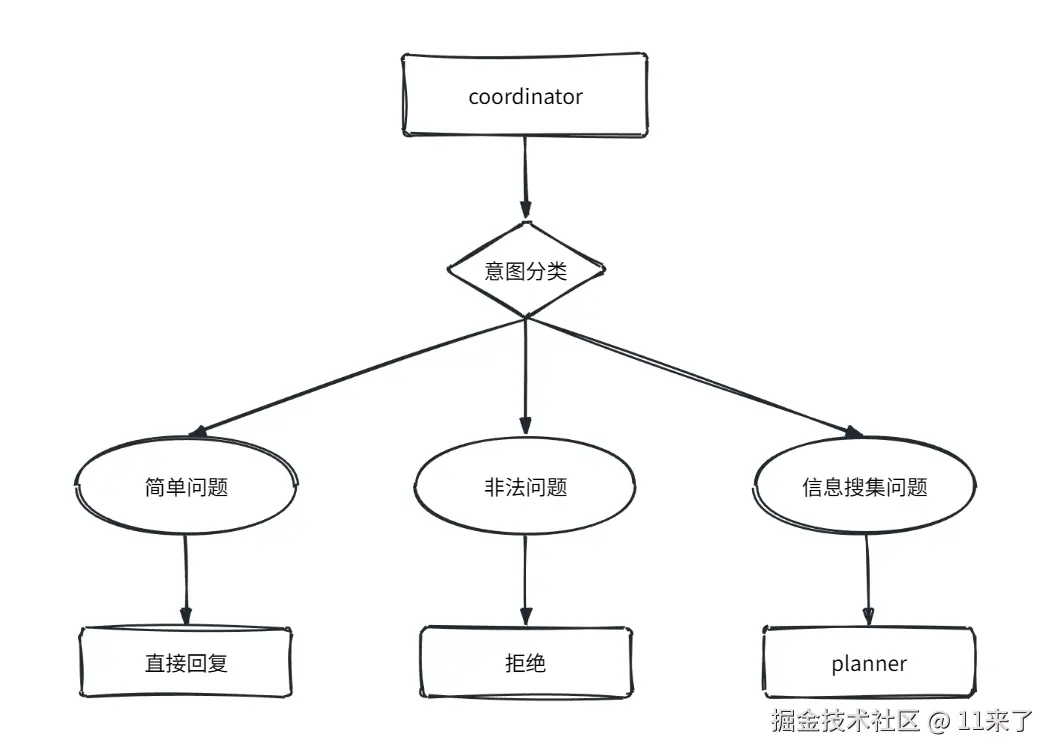
协调节点(coordinator):对用户问题进行意图分类:
- 简单问题:直接回复。
- 非法问题:直接拒绝。例如要求泄露提示词或内部指令;请求生成非法内容;请求冒充特定人物;视图绕过安全规则等问题。
- 信息搜集问题:当用户的请求是需要进行搜集或信息处理的任务时,则移交给 planner 处理。
用户查询重写
用户查询重写节点是 DeepResearch 中很重要的一个步骤。
DeepResearch 需要基于用户查询的问题进行信息的搜索和检索,如果直接使用原始 Query 会存在用户语言表达模糊、意图不清晰、甚至不完整的问题,导致难以直接根据原始 Query 从知识库中命中相关文档,以及 Web 检索质量较低。
因此,在进行信息搜集之前,会对用户查询进行重写,通常包括以下几个方面:
- 查询扩展:基于原始 Query 扩展为多个问题,从不同语言 、不同角度进行信息搜集,获取更多潜在的答案。
- 查询去重:将扩展后的查询进行去重。可以采用 LLM 或者 embedding 模型实现,LLM 去重无法精确控制相似度阈值,而 embedding 模型可以。
在 Spring AI Alibaba 实现的 DeepResearch 中仅仅对查询进行扩展,未进行去重处理,查询扩展采用了 SpringAI 自带的扩展器,对应提示词如下:
Markdown
你是一位信息检索与搜索优化领域的专家。
你的任务是基于给定查询生成 {number} 个不同版本的查询。
每个变体都必须从不同的角度或方面覆盖该主题,
同时保持原始查询的核心意图。目标是扩大搜索空间,
并提高找到相关信息的可能性。
不要解释你的选择,也不要添加任何其他文本。
请将查询变体用换行符分隔。
原始查询:{query}
查询变体:RAG 检索用户文件
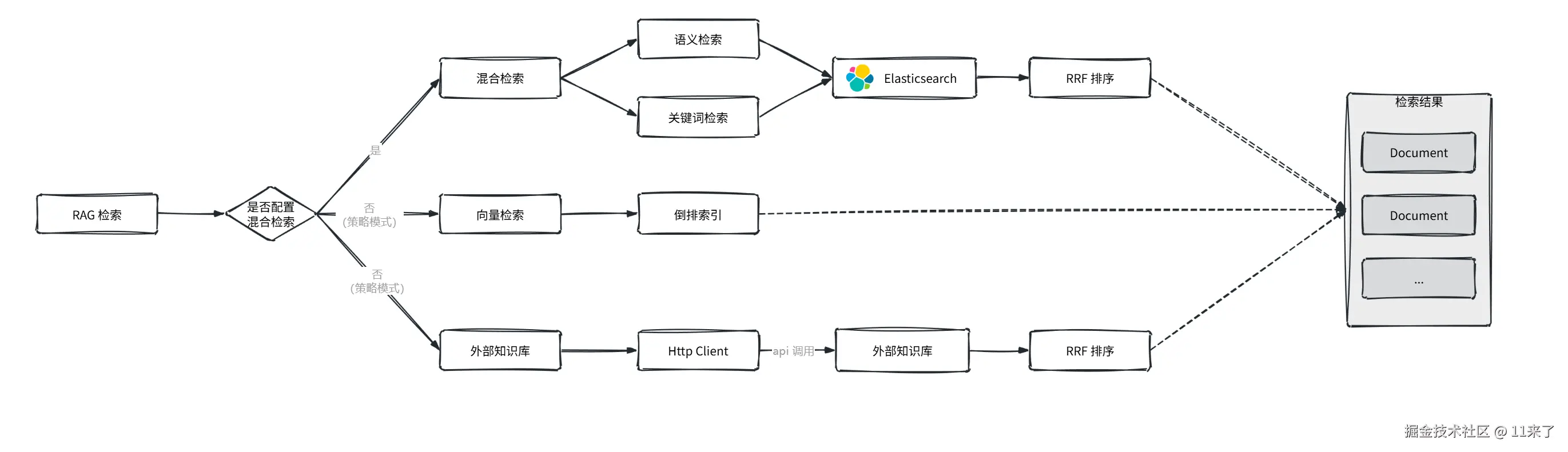
RAG 节点实现了以下几种检索能力,根据策略模式选择不同的检索方式:
- 基于 ES 的混合检索能力。
- 基于 SpringAI 提供的向量检索能力。
- 基于 API 调用知识库的检索。
(1)基于 ES 的混合检索
向量数据库采用了 ES 来实现,ES 8.x 开始支持混合检索。
混合检索同时结合了语义检索 和关键词检索:
- 语义检索:将文本编码为高维向量,通过余弦相似度可以计算不同文本之间的语义相似度。
- 关键词检索:基于 ES 的倒排索引实现精确搜索。
混合检索结合这两种搜索方式,可以同时实现语义级别检索和精确的检索,最后通过 RRF 算法对混合检索的结果进行统一排名。
RRF(Reciprocal Rank Fusion,倒数排名融合)
RRF 是多检索结果融合算法,核心思想:如果某个文档在多个检索模型中都排在靠前的位置,那么它整体上与查询更可能是相关的。
(2)基于 SpringAI 提供的向量检索能力
Spring AI 定义了 VectorStore 抽象接口,规范了与向量数据库之间的交互。
通过引入了 SpringAI 集成 ES 向量存储的 maven 依赖之后,就可以注入 ES 对应的 VectorStore 实现类进行向量的存储和检索。
(3)基于 API 调用知识库检索
除了以上两种,还支持在 application.yaml 中配置外部数据库,通过读取知识库配置,并进行 HttpClient 初始化,就可以基于 api 调用外部知识库查询内容。
这里可能会配置多个领域的外部知识库(例如医学专业知识库、法律专业知识库等等),因此会通过"决策 Agent"来判断当前问题需要调用哪些知识库,之后再到指定的知识库中进行检索。
整个 RAG 检索过程如下图:
背景信息搜集
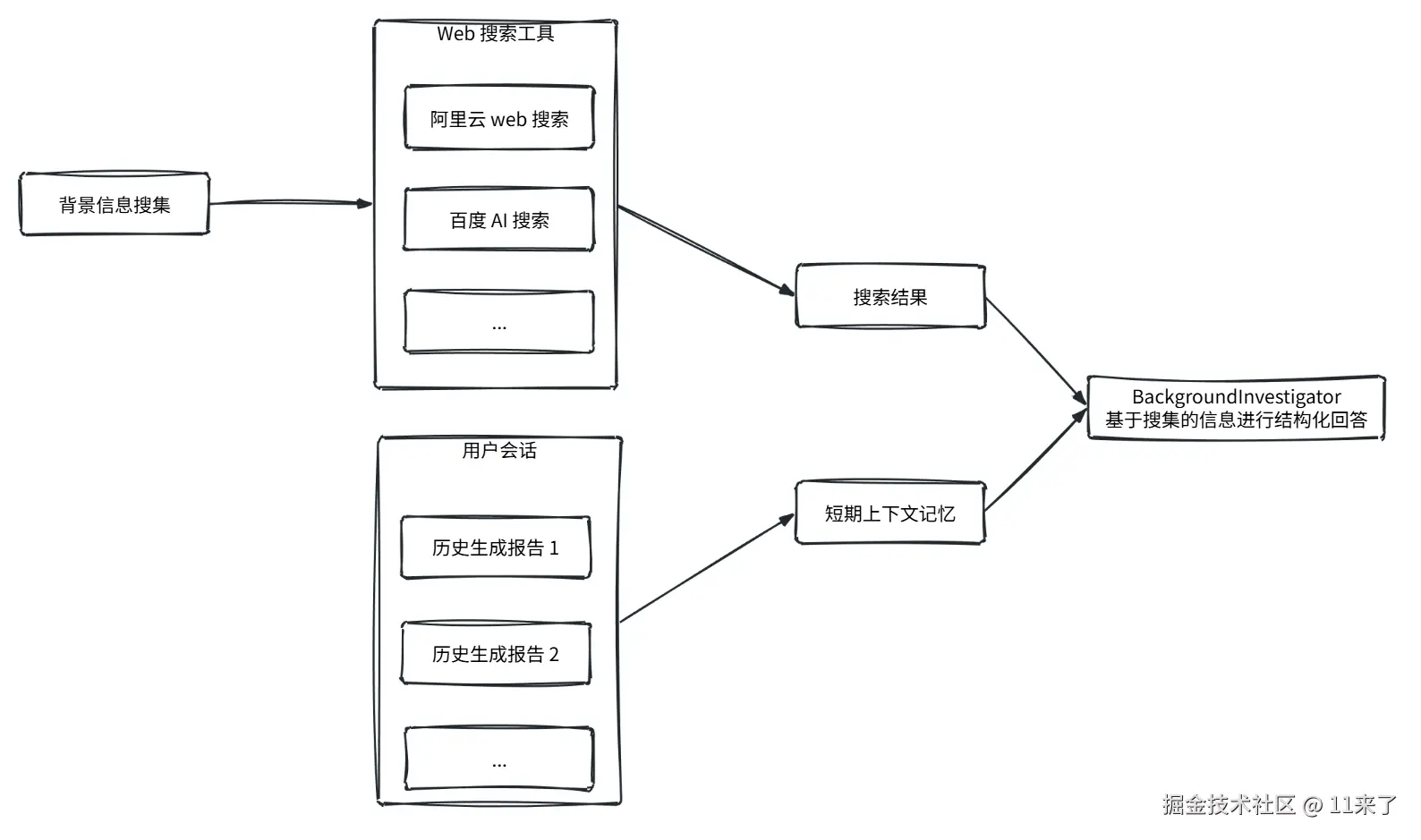
背景信息搜集节点(BackgroundInvestigator)主要基于 Web 搜索相关信息,保证背景信息的多样性。
Web 搜索基于工具调用实现,可以使用 MCP,也可以使用 SpringAIAlibaba 集成好的 ToolCalling 工具。
同样类似于 RAG,可以配置多个 Web 搜索工具,借助决策节点选择使用哪些 Web 工具进行搜索。
搜集信息完成后,将搜集好的信息发送给 LLM,同时为了保持 LLM 上下文的连贯性,将用户历史会话中已经生成的报告作为短期上下文记忆,与检索信息一同发送给 LLM。
提示词设计
Background Investigator 基于搜集好的信息生成结构化回答,为了保证回答内容的来源可追溯,会在提示词中要求列出参考文献,如下:
Markdown
- 参考文献(References):使用 Markdown 的超链接引用格式列出所有使用过的来源的完整 URL。请在每个引用之间留一个空行以便于阅读。
- 不要在正文中添加内联引用。相反,请在最后的"参考文献"部分列出所有来源。任务规划
计划节点(Planner)针对研究主题进行拆解,生成多步骤的执行计划,以确保搜集到的信息同时具备深度和广度。
在 Planner 节点中,会将前面收集到的信息都发送给 LLM,让 LLM 判断目前上下文信息是否足够回答问题,如果不足的话,需要制定执行计划,搜集更多的信息来生成研究报告。
如何提升计划可控性?
(1)人类反馈
Planner 生成计划后,可能有些计划步骤并不符合用户预期,通常会加入人类反馈节点(Human Feedback),在生成计划之后,接收用户的输入之后重新生成计划。
(2)计划步骤控制
在提示词中增加 max_step_num 变量,用于控制最大步骤,提升任务规划过程中的可控性。
(3)JSON 格式化输出
由于生成的计划需要多个 Agent 配合执行,为了保证信息传递和理解的准确性,需要通过提示词指定 LLM 使用 JSON 格式输出计划内容。
LLM 生成内容不稳定,可能生成的计划并不是严格的 JSON 格式,因此在生成计划后,会通过 JSON 反序列化的方式进行校验,如果校验失败,则尝试重新生成计划。
下图是 Planner 节点生成计划以及格式校验的流程:
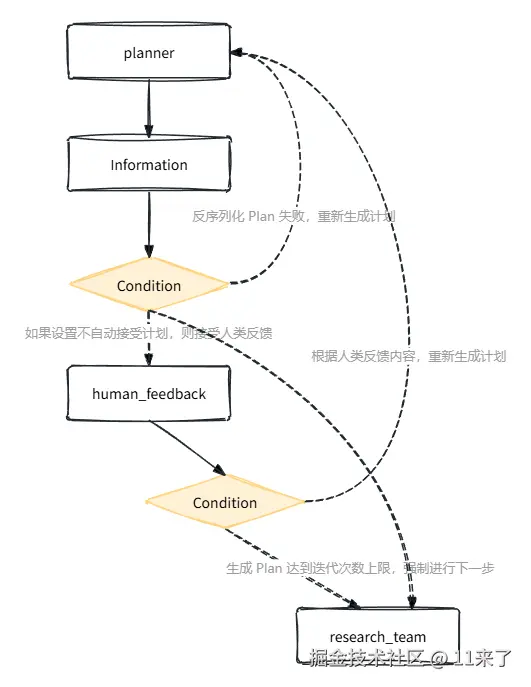
执行节点
生成执行计划之后,交由执行节点按步骤执行计划,目的是搜集到更多的背景信息,计划执行完成之后,进行报告的生成。
如何提升计划执行效率?
LLM 的思考与输出速度是很慢的,尤其是通过任务规划生成了多步骤的计划,串行执行会导致效率较低,因此会引入并行节点,将计划同时分发给多个节点一起执行,最终统一收集计划中所有步骤的执行结果。

总结
DeepResearch 核心是通过搜集尽可能多的背景信息来生成深度研究报告,在搜索、阅读和推理之间不断循环。
相比于普通的问答模式,DeepResearch 更像是一个专家团队,有查询重写节点、任务规划的 Planner、知识库检索的 RAG 节点、Web 搜索的节点、并行执行节点等。通过分而治之将复杂的搜索任务拆解为多个步骤执行,是很好应对复杂性的手段。
扩展阅读
Jina DeepResearch 也发表过文章,介绍了其实现原理,整理如下:
(1)通过在每个步骤中有选择的禁用某些操作来保证输出的稳定性和结构化。
(2)系统提示词采用 XML 标签定义,这样可以让 Agent 更健壮。
(3)遍历知识空白:Agent 先找出"知识空白问题",即需要回答核心问题之前需要补足的知识,借助 FIFO 队列来存储,原始问题会在队列尾部,新问题在头部,当队列头部的问题都被解决之后,获得的知识可以应用于后续的问题,最终解决原始问题。(FIFO 的方式相比于递归的方式,可以更好的控制 token 预算,避免 token 消耗过少深度不够、或 token 消耗过多效率低的问题)
(4)查询重写:查询重写是决定搜索质量的最关键因素之一,过程中需要对查询进行重写、扩展、去重。查询去重采用 embedding 模型可以更好控制相似度的阈值。
(5)网页内容爬取:爬取网页的全部内容,并且生成网页的摘要内容作为推理的辅助信息。
(6)内存管理:随着 2025 年 LLM 的超长上下文趋势,Jina 选择放弃了采用向量数据库,而是全部放入到 LLM 的上下文记忆,作为提示词传递给大模型。除此之外,对 LLM 的上下文进行了结构化的管理,区分了"记忆"和"知识",在提示词中通过 xml 进行区分。
(7)答案评估:答案生成和答案评估放在不同的 Agent 中效果会更好。
(8)预算控制:预算控制不仅仅是为了节省成本,也可以避免系统过早返回结果。当预算即将耗尽,就强制 LLM 立即生成答案,不再进行推理思考。
其次,文章中还提到 Agent 框架被证明是不必要的,过度复杂的抽象层会成为开发者的负担,拥抱 LLM 的原生能力,避免被框架束缚是更明智的选择。