本文以在系统实现文章计数为例,解析使用Redis+RabbitMQ+Mysql实现批量异步落库的架构。
设计目标
每次有一次更新就写一次数据库性能非常差,尤其是并发量提高,为了提高数据库读写性能,提高系统的吞吐量,用聚合+异步批量落库 的架构来优化。设计的目标很简单,就是设定专门的异步数据处理模块,该模块可以一次性将多条数据一次性异步批量写入数据库,而不是像同步单次一样每次有一条数据就需要写入数据库并且处理的接口函数还需要等待写入结束才能继续执行。由两个阈值来控制写入数据库时机分别是时间阈值和数量阈值。
实现的核心在于异步 和批量。
批量异步落库介绍
在开始介绍异步落库实现之前,先明确异步的概念。异步的反面是同步,同步的意思是串行执行 ,每个任务必须等到前一个任务做完才能做;异步可以理解为并行执行,有些任务对接下来的任务没有影响,那么对于这些任务,在下一个任务开始前简单做个处理,把任务给其他系统处理,然后继续做下一个任务,这样做的最大好处就是快,节省了处理时间,缺点就在于可靠性不如同步处理。
落库意为将数据存入数据库,异步落库就是用异步的方式写入数据库。为什么落库可以用异步方式执行,假设产生了一个点赞的消息,那么这一条点赞信息是否存入数据库对接下来的任务处理是没影响的(前端服务器可以直接完成点赞交互,后端不需要返回实时总数),因此写入数据库的任务就可以独立于点赞接口处理任务,用异步的方式来写入,这样后端处理就不需要等待写入数据库的过程,从而可以接近实时返回,提高吞吐量。
异步还有一个好处,因为不需要快速返回处理值,所以落库处理模块可以攒多条数据同时写入数据库,也就是批量写入 ,这样可以大大压缩总的RTT,减少对数据库的冲击。
实现
架构设计
下面分别解析批量异步落库的设计思路。
对于批量写入,需要一次攒下一批数据再写入数据库,那么需要有一个容器来暂时存数据,这个容器可以是任何可以存数据的:内存队列或缓存或其他,这个容器只要满足一个特点:读写性能好 ,因为这个容器会被频繁读写,放进去然后一会要拿出来放到数据库。对比之后我选择了Redis 作为容器来暂存数据,因为Redis作为缓存中间件,工作在内存中,读写性能都很好,同时可持久化的特点使得抗风险能力也更好。我把暂存在Redis的操作记作聚合。
批量的问题解决了,问题来到异步落库。把一个需要落库的任务记为一个事件(比如点赞计数+1),每一次主线程执行到事件产生,执行事件聚合后,继续执行下面任务。这个过程是同步执行的,因为Redis的读写性能很好,所以耗时可以忽略不计。然而,Redis不能无限暂存,需要在符合某个条件后把暂存的数据写到数据库,那么如何设计写数据库和Redis的关系?
- 一种方案是将数据库写入同样设计为同步写 ,具体操作是在写入Redis的时候判断是否满足写数据库条件,如果满足条件那么写数据库,写入成功再返回。这种方案的缺点是数据库写入操作耗时是Redis读写的数量级倍数,这会直接导致这一次接口响应速度变的很慢,甚至引发后续请求雪崩的问题。
- 另一种方案就是用消息队列来完成写入数据库写入和事件暂存的解耦,简单说就是异步写数据库。
显然第二种方案更好,消息队列就是一种可以暂存消息的中间件,一方发出一方接收。常见的有Kafka、RabbitMQ等,Kafka有非常高的吞吐量,常用于日志系统,RabbitMQ轻量并且也好实现,吞吐量虽然不如Kafka但也足够,并且RabbitMQ是Spring的内置消息队列。消息队列的原理都是类似的,本文以RabbitMQ为例来解析。
RabbitMQ介绍
下面是RabbitMQ的基本结构解析:
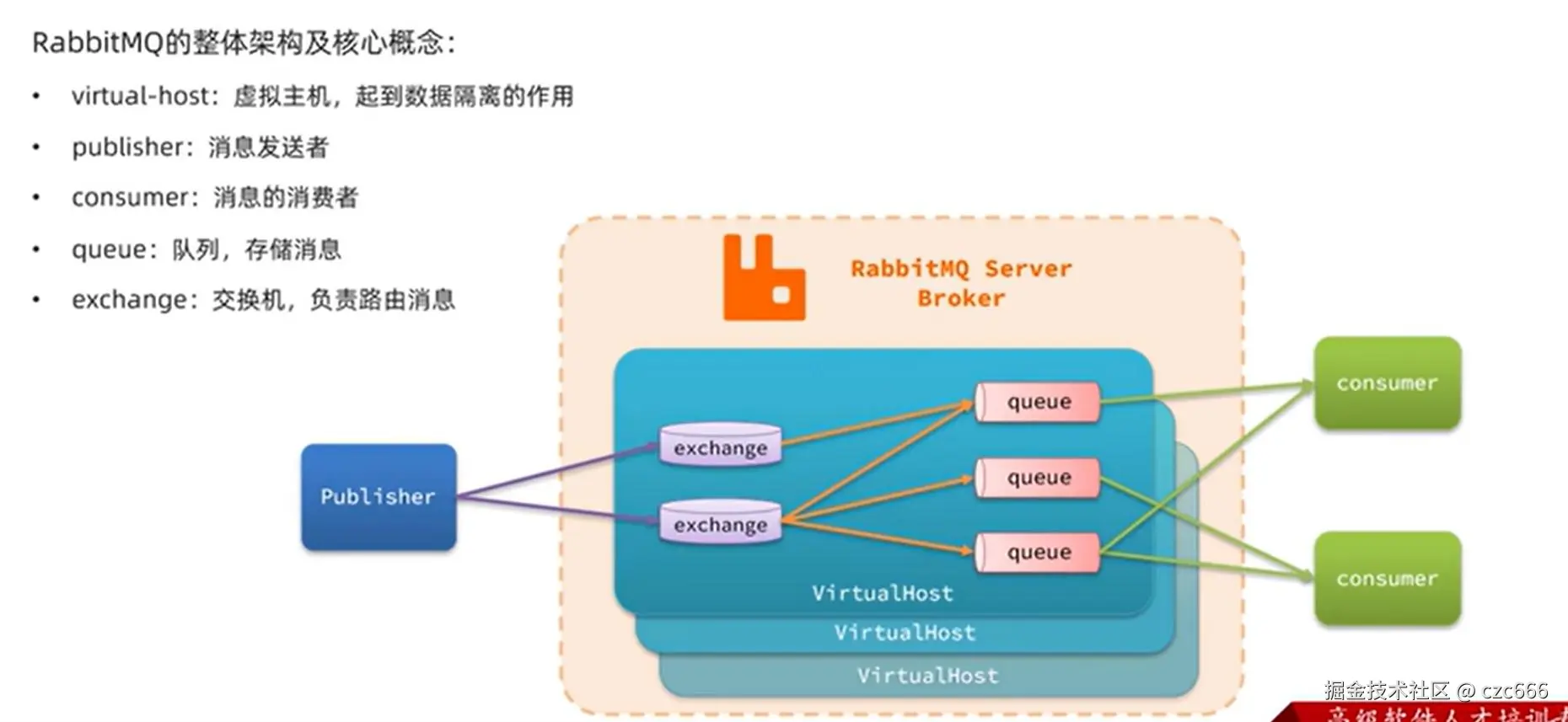
RabbitMQ在中间的框内,核心组件是交换机exchange和队列queue,交换机可以绑定多个队列,将消息推送交换机之后,交换机就会根据route key把消息推送到绑定的队列 ,route key指示了交换机要把数据转发给哪一个队列。消息队列两边分别是消息的生产者和消费者,消费者需要监听队列,取出消息并消费。
虚拟主机是起到隔离的作用,可以用于隔开不同的应用程序,相当于是不同的环境,不同的环境是不会相互干扰的。
更多的内容可以看一些教程视频做更多了解,这里不再展开,消息队列是一个比较重要的知识点。
具体实现
在架构设计部分梳理了架构的设计,大致的实现思路如下图所示
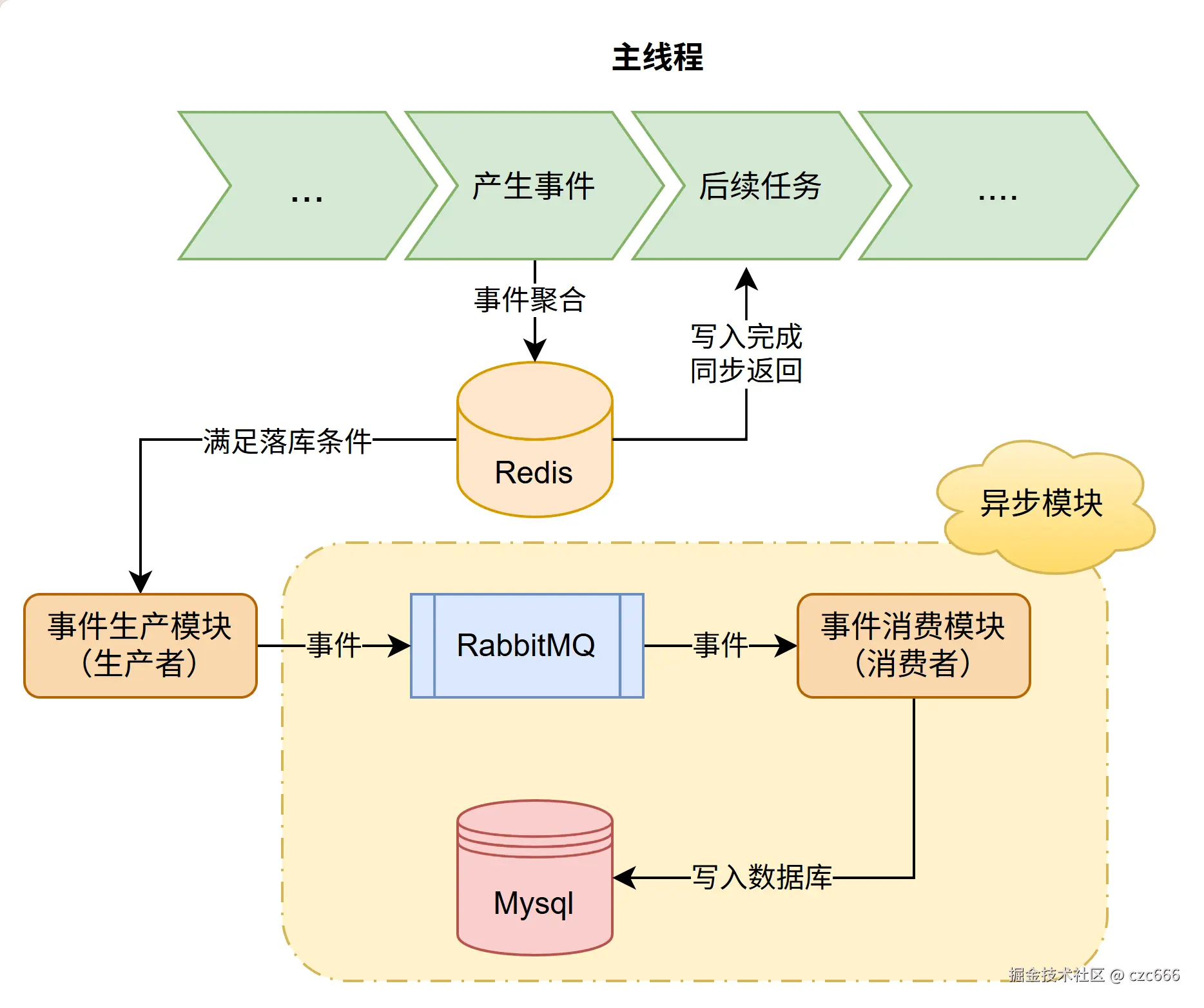
首先主线程执行到事件产生的代码,这时候需要先把事件暂存到Redis,也就是完成聚合操作,然后就可以同步返回继续执行,在过程中需要判断是否满足落库条件,满足的话由事件产生模块封装好时间发送给消息队列,后续就不用管了,由消息队列另一端的消费模块来处理落库任务。
下面结合代码解析。
事件聚合和发布
假设场景为有一张数据表专门存储文章的用户交互数量,比如用户给文章点赞那么需要给文章的点赞计数+1,当然也可能是其他的操作比如取消点赞/收藏/取消收藏...执行对应计数操作就可以。
现在有一个点赞操作,给点赞的缓存计数+1之后,需要执行聚合操作,把事件存到Redis中,主线程操作如下:
less
if(opeatationType.equals(LIKE.getCode())){ // 点赞事件
// 文章被点赞数+1
articleCountRedis.incrTotalCount(articleId, UserOperateFieldEnum.COL_LIKE,1);
// 事件聚合
articleCountRedis.aggregate(new OperationEvent(articleId, LIKE.getCode())); // 点赞
}其中aggrate对应了聚合操作,OperationEvent对应了一个操作事件,定义为:
arduino
/**
* 操作单元
*/
public class OperationEvent {
/**
* 目标对象id
*/
private Long targetId;
/**
* 操作代码
*/
private Integer operationCode;
}这个targetId定义了操作对象的ID,比如文章操作那么就是文章ID;operationCode为操作代码,对应了事件的代号,如点赞/取消点赞/收藏/取消收藏...都有一个对应的操作编码。聚合的写入内容设计只要保证后续写入数据库模块可以通过存入的事件列表恢复计数的变化量就可以 ,并且写入的内容应尽量简洁,否则一方面写入速度慢,一方面会大量消耗珍贵的缓存资源。
聚合需要保证线程安全,也就是需要避免同时读写一个Redis的key,因此引入Redisson锁来保证安全:
ini
RLock lock = redissonClient.getLock(String.format(REDISSON_KEY,shardId));其中shardId是分片号,是为了减少聚合冲突的,简单说就是按照id取模将id分到多个不同的容器中,从而将抢一把锁变为抢若干把锁,减少冲突。
拿到锁之后取得对应的key,聚合的核心操作如下:
ini
String key = String.format(INTERACTION_INCREASE, shardId,version);
// 增量池
long cnt = RedisUtil.rPush(key, JsonUtil.toJsonString(event),
30*RedisUtil.TTL_MINUTE+ NumUtil.randomLong(120));
// 达到长度就触发落库
if (cnt == aggregateMaxCount) { // 刚好等于才触发
publishFlag = true;
RedisUtil.incrBy(getVersionKey(shardId),1); // 版本号 +1
}version是聚合版本号,后续会展开说明,也可以先不关注。
key对应了存储的Redis的key,使用的是Redis的列表类型来存储,最重要的就是中间的Redis.rPush操作,这个函数会把事件存入Redis,每次存储事件后拿到实时的长度,然后判断是否到达长度阈值,如果到达长度阈值那么发布事件,把聚合的事件全部写入数据库。
发布事件还有一个定时任务也在控制,由于涉及到定时模块设计比较多,这里不再展示,简单说就是过一段时间执行发布事件。
发布事件的代码为
scss
public void countUpdatePublish(long shardId,String version) {
String key = String.format(INTERACTION_INCREASE,shardId,version);
// 读取全部的keys对应的redis数据,取出的每一条都是{articleId}:{operationCode}
List<String> eventList = RedisUtil.listAll(key);
if (eventList.isEmpty()) {
return; // 没有数据就可以返回了(待办清单空)
}
CountUpdateEvent updateEvent = CountUpdateEvent.builder()
.version(version)
.shardId(shardId)
.evevnList(eventList).build();
// 发布异步落库事件(注意是发到交换机)
rabbitTemplate.convertAndSend(RabbitMQConstant.ARTICLE_EVENT_EX, RabbitMQConstant.ARTICLE_COUNT_KEY, updateEvent);
}这一部分先利用RedisUtil.listAll取出所有存入的事件,然后封装为MQ接受的格式,然后使用rabbitTemplate.convertAndSend把事件发送到消息队列,这个ARTICLE_COUNT_KEY表示发送标识route-key,交换机会把消息转发到绑定了这个route-key的队列。
到这里事件发布结束,具体MQ的另一端消费者怎么做就跟Redis没关系了,这就是异步解耦的体现。
批量落库
批量落库对应了整体流程图中的事件消费模块,这个模块拿到RabbitMQ发送过来的数据,也就是事件列表并处理。
在Spring中,给函数加上下面的注解可以让这个函数变为消费者专门监听目标队列事件:
ini
@RabbitListener(queues = RabbitMQConstant.ARTICLE_COUNT_Q,ackMode = "MANUAL")这个的意思就是监听ARTICLE_COUNT_Q队列的事件,这个队列绑定了一个route-key,对应于上面发布事件的,因此就是监听上面那个发布事件。
通过事件回放得到每一篇文章对应的计数增量,事件回放指重新逐个统计存储的事件,像是重新回放一样
ini
// 事件列表
List<String> evevnList = updateEvent.getEvevnList();
// 事件回放得到更新增量
List<ArticleCount> articleCountList = new ArrayList<>();
Map<Long,Integer> indexMap = new HashMap<>();
for(String eventJson:evevnList){
OperationEvent event = JsonUtil.fromJson(eventJson,OperationEvent.class);
Long articleId = event.getTargetId();
int type = event.getOperationCode();
int index = indexMap.getOrDefault(articleId,-1);
if(index==-1){
articleCountList.add(ArticleCount.builder().articleId(articleId).build());
index = articleCountList.size()-1;
indexMap.put(articleId,index);
}
ArticleCount articleCount = articleCountList.get(index);
if(type== ArticleOperateTypeEnum.READ.getCode()){
articleCount.setReadCnt(NumUtil.null2Zero(articleCount.getReadCnt())+1);
}
// ...省略部分
else if(type== ArticleOperateTypeEnum.CANCEL_COLLECT.getCode()){
articleCount.setCollectCnt(NumUtil.null2Zero(articleCount.getCollectCnt())-1);
}
else if(type== ArticleOperateTypeEnum.NEW.getCode()){
; // 不管
}
}这样就得到了所有相关文章的增量列表,接下来需要更新所有相关文章的计数。
使用SQL的upsert可以合并insert+update的操作,非常方便,简单说就是如果不存在那么插入,存在那么更新,需要注意就是必须要有约束的主键,也就是能判定存在/不存在的键,对于文章就是文章的id。
使用upsert更新文章数据:
ini
articleCountMapper.upsertDeltaCountBatch(articleCountList);对应的SQL操作:
ini
<insert id="upsertDeltaCountBatch">
INSERT INTO article_count
(article_id, read_cnt, like_cnt, collect_cnt, comment_cnt, report_cnt, update_time)
VALUES
<foreach collection="articleCountList" item="item" separator=",">
(#{item.articleId},
<if test="item.readCnt != null">#{item.readCnt}</if>
<if test="item.readCnt == null">0</if>,
<if test="item.likeCnt != null">#{item.likeCnt}</if>
<if test="item.likeCnt == null">0</if>,
<if test="item.collectCnt != null">#{item.collectCnt}</if>
<if test="item.collectCnt == null">0</if>,
<if test="item.commentCnt != null">#{item.commentCnt}</if>
<if test="item.commentCnt == null">0</if>,
<if test="item.reportCnt != null">#{item.reportCnt}</if>
<if test="item.reportCnt == null">0</if>,
NOW())
</foreach>
ON DUPLICATE KEY UPDATE
read_cnt = GREATEST(IFNULL(read_cnt,0) + VALUES(read_cnt), 0),
like_cnt = GREATEST(IFNULL(like_cnt,0) + VALUES(like_cnt), 0),
collect_cnt = GREATEST(IFNULL(collect_cnt,0) + VALUES(collect_cnt), 0),
comment_cnt = GREATEST(IFNULL(comment_cnt,0) + VALUES(comment_cnt), 0),
report_cnt = GREATEST(IFNULL(report_cnt,0) + VALUES(report_cnt), 0),
update_time = NOW()
</insert>这段SQL的是一个批量插入/更新的代码段,使用循环方式逐个操作,完成一次SQL批量插入数据 。如果不存在那么插入,否则存在进入下面的ON DUPLICATE KEY UPDATE,这部分会拿出原本的值IFNULL(read_cnt,0)(0表示不存在就是0,为了防止报错)和现在的值VALUES(read_cnt)值相加,完成的就是加入增量的操作。
完成了插入操作之后,Redis中存储的相关数据就可以删除了,避免占用资源,调用删除函数删除所有已经存入数据库的数据。
RabbitMQ通知Redis删除的部分使用Spring Context实现,这是内存级的通知,需要注册一个监听函数,使用注解EventListener,函数默认监听跟接收参数相同的事件,如果要接收多个,需要另外设置。
typescript
@EventListener
protected void handleClearInteraction(InteractionUpdateEvent articleConsumerEvent){
// 调用redis清理函数功能
articleInteractionRedis.clearInteraction(articleConsumerEvent.getVersion());
}一个实际的批量异步落库过程如下
version聚合版本控制
前面在聚合的时候提到了version,之所以引入这个变量是为了解决下面这个问题:在一次聚合中把事件发送给数据库写入模块后,模块写入后需要在Redis删除已经写入的数据,但是数据是不断写入的,如何判定哪一些是已经写入数据库的?
有下面几个思路:
- 从Redis里面取出数据后直接把这一批数据给删除,发送给消息队列。这种方案最大的问题假如RabbitMQ或消息落库模块出现了问题,那么数据就永远消失了,无法恢复。
- 用一个
version来标记当前聚合的版本,一次更新事件对应了一个version,保证每次聚合写入的Redis key一定是最新的,历史事件每一个都对应了一个version,只有事件完成才会删掉这个version对应的key。这种方案的确定是引入了额外的工作量,实现更复杂。
显然第二种更好,也就是用version来标记每次发布的事件,对于删除Redis聚合内容,每一次的写入内容都有一个version,更新完之后MQ会把更新完成的版本发过来,然后redis端把这个版本删除就可以,版本号自增就行,保证不要重复。为了防止一直增加溢出,考虑设置每天检查是否超过阈值,超过重新置零。
总结
异步落库主要要解决的是吞吐量问题,用异步和批量的优化可以大大提高系统吞吐量,之前的一次实测得到大约500并发下可以取得大约500QPS的成绩,相比于直接写入数据库这样的成绩已经好了很多,如果要进一步优化那么需要更高阶的优化方案,如环形队列+批量聚合方案,后续会介绍系统如何不断优化,从一开始的并发错误到QPS 4000,本篇主要介绍基础的聚合+异步落库思路。
完整代码
本文章所有代码已开源,完全独立自主开发,支持Docker一键部署测试,地址:
Github :CCBlog-Github
Gitee :CCBlog-Gitee
如果这篇文章帮到了你,欢迎在 GitHub/Gitee 点个⭐,也欢迎在评论区写想要看的其他教程! 您的 Star + 反馈,就是我持续输出干货的最大动力!