参考文章:DeepSeek-V2:
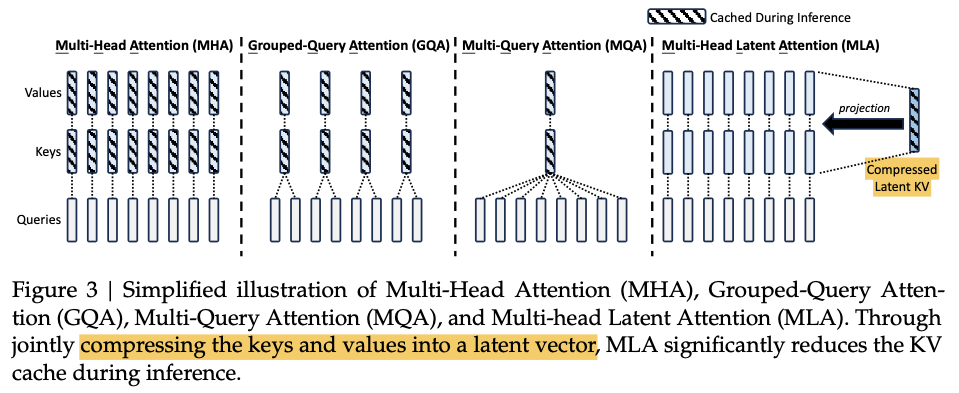
Multi-Head Attention (MHA)示意图:
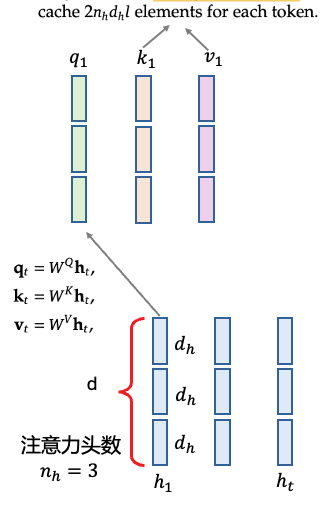
Grouped-Query Attention (GQA)

减小KV head的数量,多个Query head共用一个KV head
Multi-Query Attention (MQA)
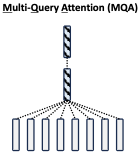
只有一个KV head,多个Query head共用一个KVhead
Multi-head Latent Attention(MLA)示意图:
MLA在DeepSeek-V2论文中被提出,
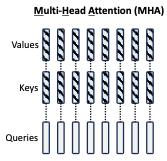
在生成QKV时,先将向量都down projection到低维度。
对于KV head部分,都由一个共用的低维度向量表示来up pojection出来多个head
在推理时,KV cache只用保存这个低维度的向量,在计算时由up projection还原到多个head的高维空间,这样做的好处是减小了KV cache
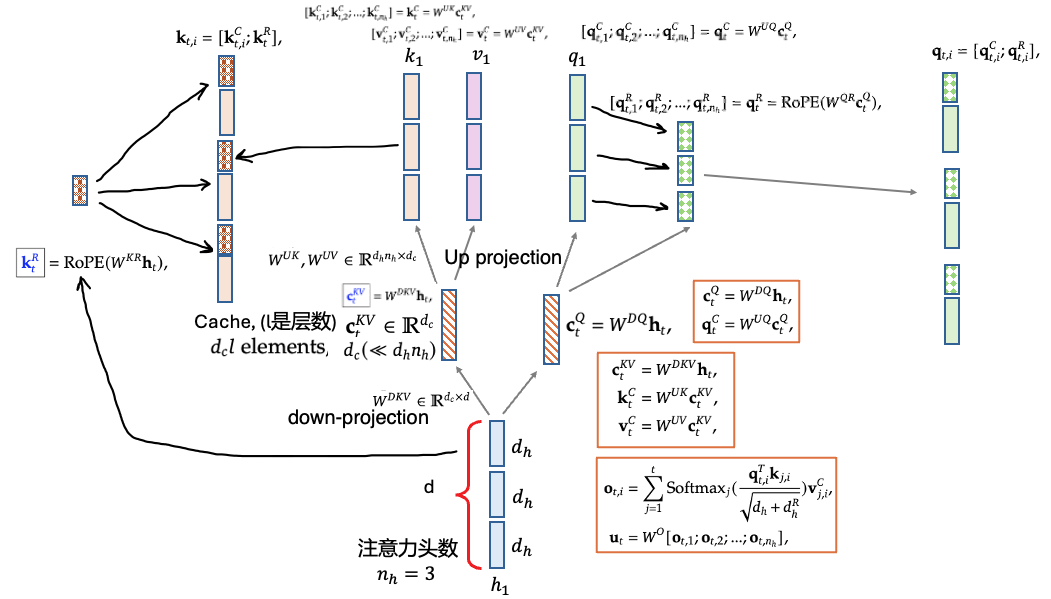
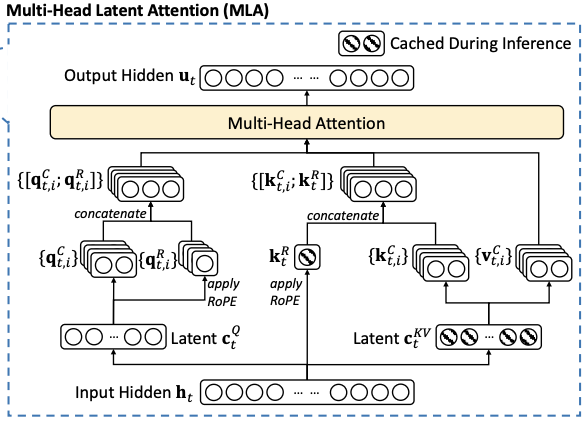
原论文中画的MLA的示意图:
具体计算方式:
其中的W^UK可以和W^UQ合并,W^UV和W^O可以合并
