介绍
说到监控,很多人可能会第一时间想到各种指标,比如资源类的cpu,内存,磁盘使用率,或者应用层的请求数,成功率,延迟等。但是将应用程序中的异常文本导出为指标进行监控,这种情况却很少有人提到。 这个也是本片文章要介绍的内容,一个很简单但是很有用的监控利器,java异常监控。当然,这里也可以是其他语言的异常,比如python,go等。
优点说明
这里说明下java异常监控的几大优点:
- 简单:使用java异常监控的方式,可以很简单的发现线上的潜在问题,因为能触发异常的肯定是意外情况,只要有java异常,就能代表出现了一些意外的情况,同时排查起来也简单,不像是接口的请求数和成功率,如果出现异常指标,排查起来耗费时间,而且也很容易误报。
- 全面:监控指标时很多时候都是根据经验提前设置规则进行预警,比如cpu使用率,请求成功率等,但是如果发生了意料之外的情况则很可能监测不到。而java异常监控可以全面的监控到服务的问题,不管是业务代码抛出的异常,还是没有预想到的其他组件抛出的异常,都能被监控到。
- 有效:通过每天进行java异常巡检,能够有效的发现线上的异常,包括业务问题和组件问题,都能第一时间发现。同时也能有效的协助排查问题,比如线上出问题了,你看下java异常监控,就能知道是什么服务在报错,甚至可能可以直接根据异常锁定错误原因。
- 自定义 :开发可以自定义异常,当出现想要监控的情况时,在代码中打印异常日志,这些异常就会被抓取并展示出来,运维人员巡检时就会发现这些异常并提醒开发进行处理,这样开发就可以简单的增加自己想要关注的监控事项
使用方式
将java异常导入到prometheus生成指标后,就可以开始进行监控,这里说明几种监控的使用方式:
- 日常巡检:在grafana上展示java异常数据,每日进行巡检,可以及时发现线上的异常
- 问题排查:需要紧急排查线上问题时,可以展示最近几分钟的java异常,作为排查问题的参考
- 实时预警:配置报警规则,满足条件时实时报警,比如触发钉钉报警,用于快速发现线上的异常情况
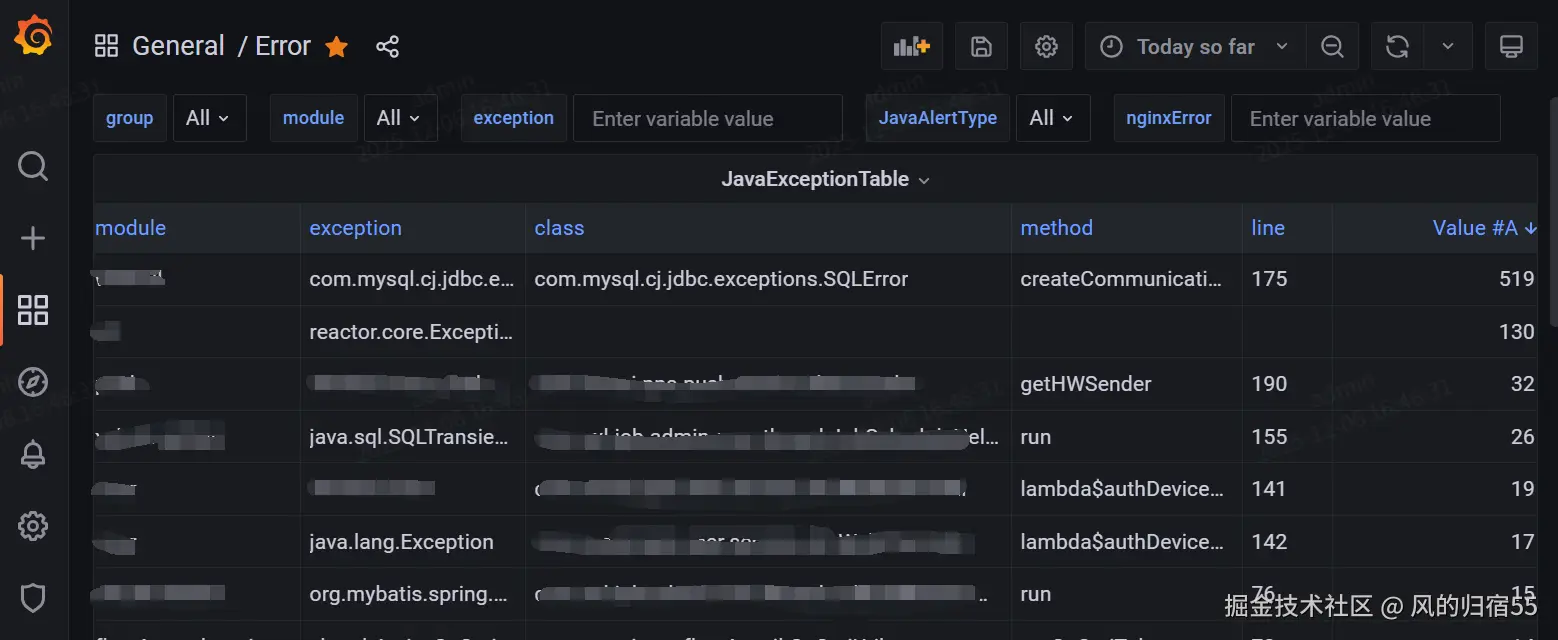
这里提供一个grafana展示的异常报警界面。
基础设施
- 需要有prometheus用于存储指标
- 需要有grafana用于查询展示指标
- 需要有日志集中收集系统,方便后续日志的统一处理
- 需要安装mtail用于解析和导出异常指标
实现流程
这个实现方式比较简单,这里先总体介绍下流程,首先是定义好指定的异常格式,然后再log4j这种日志框架中将异常日志额外存储到一个文件,接着依靠日志集中收集系统,将各个服务的异常日志收集到日志机器上,然后使用mtail追踪异常日志并解析为指标,将指标导出到prometheus。 指标数据生成后,就可以配置查询规则进行grafana展示以及进行实时报警了。
日志打印
第一步首先是定义好需要收集的异常级别,一般就是error级别,不需要额外指定,然后是异常的日志格式,这个可以根据自己的需要配置log4j这种框架的日志格式,可以打印抛出异常的方法,异常类,异常信息,所属模块等,这里提供一个log4j2的部分配置以供参考
ini
<Appenders>
<RollingFile name="error_log" fileName="${filepath}/error/${filename}.log"
filePattern="${filepath}/error/${filename}.log-%d{yyyy-MM-dd-HH}">
<ThrowableFilter type="useLocation" onMatch="ACCEPT" onMismatch="DENY"/>
<PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss}\t${module}\t%class\t%method\t%line\t%throwable{1}\t%m%n"/>
<Policies>
<TimeBasedTriggeringPolicy/>
</Policies>
<DefaultRolloverStrategy>
<Delete basePath="${filepath}" maxDepth="2">
<IfFileName glob="*.log-*" />
<IfLastModified age="1h" />
</Delete>
</DefaultRolloverStrategy>
</RollingFile>
<RollingFile name="error_log_for_throw" fileName="${filepath}/error/${filename}.log"
filePattern="${filepath}/error/${filename}.log-%d{yyyy-MM-dd-HH}">
<ThrowableFilter type="useThrowable" onMatch="ACCEPT" onMismatch="DENY"/>
<PatternLayout pattern="%d{yyyy-MM-dd HH:mm:ss}\t${module}\t%throwable{short.className}\t%throwable{short.methodName}\t%throwable{short.lineNumber}\t%throwable{1}\t%m%n"/>
<Policies>
<TimeBasedTriggeringPolicy/>
</Policies>
<DefaultRolloverStrategy>
<Delete basePath="${filepath}" maxDepth="2">
<IfFileName glob="*.log-*" />
<IfLastModified age="1h" />
</Delete>
</DefaultRolloverStrategy>
</RollingFile>
</Appenders>自定义日志打印
有个特殊的情况需要说明下,可以通过指定特殊的日志格式收集业务自定义异常,比如提前和开发说好,当出现需要关注的严重业务问题时,可以使用error级别打印日志,这样运维这边就会在巡检时发现并提醒开发处理。这种方式可以让开发自由的增加业务异常监控,提高了监控的全面性。
日志收集
这部分就是日志收集系统的作用,将各个服务的异常日志文件统一收集到日志机器上的一个文件中,用于后续的mtail解析
mtail解析和导出异常监控信息
把异常日志的文件路径配置到mtail的启动命令上,让mtail解析异常日志,这里提供一个参考的配置。修改后重启mtail就能以标准格式导出指标给prometheus了。
scss
counter java_error_log by ip,type,module,class,method,line,exception
getfilename() == "/java/error/log/file.log" {
/(?P<ip>[\S ]*)\t(?P<type>[\S ]*)\t([\S ]*)\t(?P<module>[\S ]*)\t(?P<class>[\S ]*)\t(?P<method>[\S ]*)\t(?P<line>[\S ]*)\t(?P<exception>[\S \t]*)[\n\t\S\s.]*/ {
java_error_log[$ip][$type][$module][$class][$method][$line][$exception]++
}
}prometheus抓取mtail导出的数据
配置prometheus抓取mtail的数据,这个增加个配置重启prometheus就行了
yaml
- job_name: 'mtail-moniter'
static_configs:
- targets: ['11.11.11.11:3903']
labels:
exporter: 'mtail'grafana展示异常数据
现在数据已经存入prometheus中了,可以通过grafana进行展示,这里也提供一个参考的grafana查询的sql,可以按照时间维度把最近出现的和 数量有增长的异常都查询出来. 其中 __range 和 {__from:date:seconds}都是grafana的变量
scss
(
sum(
java_error_log
- min_over_time(
java_error_log[$__range]
)
) by(module,class,exception,line,method) > 0
or (
sum(
java_error_log
) by(module,class,exception,line,method) > 0
unless
count(
java_error_log
@ ${__from:date:seconds}) by(module,class,exception,line,method) > 0
)
)结语
通过以上的简单配置就能拥有一个java异常监控,各位读者可以都去试试,这个监控方式在我司已经使用了很久了,能很有效的发现一些潜在问题。