一、基本情况
1.1 模型、数据库选择
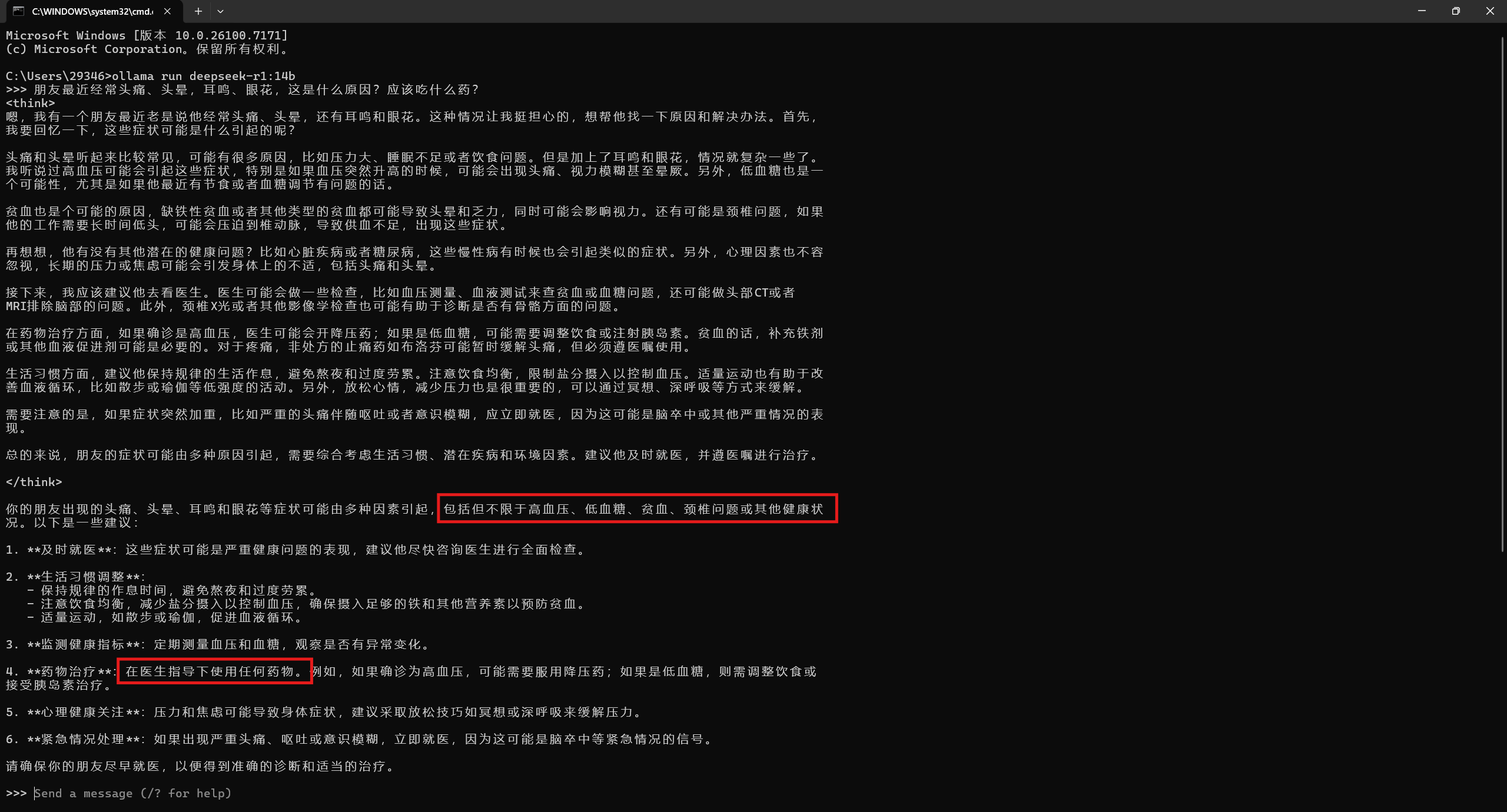
这里的推理模型选择了基于ollama本地部署的deepseek-r1:32b模型,在推理和文本生成能力上已经能够满足我们这次任务的需求。嵌入模型选择了bge-large-zh-v1.5模型,该系列模型常被用于作为中文文本语料的向量嵌入模型使用。
数据库选择了轻量级易用的向量数据库Chroma,它与python生态深度集成,适合中小型项目的部署。
1.2 知识库数据集介绍
这里的知识库数据集来自于网络上搜集的五个文件,可以看到均为pdf格式文件。

二、代码展示
2.1 knowledge_embedding.py
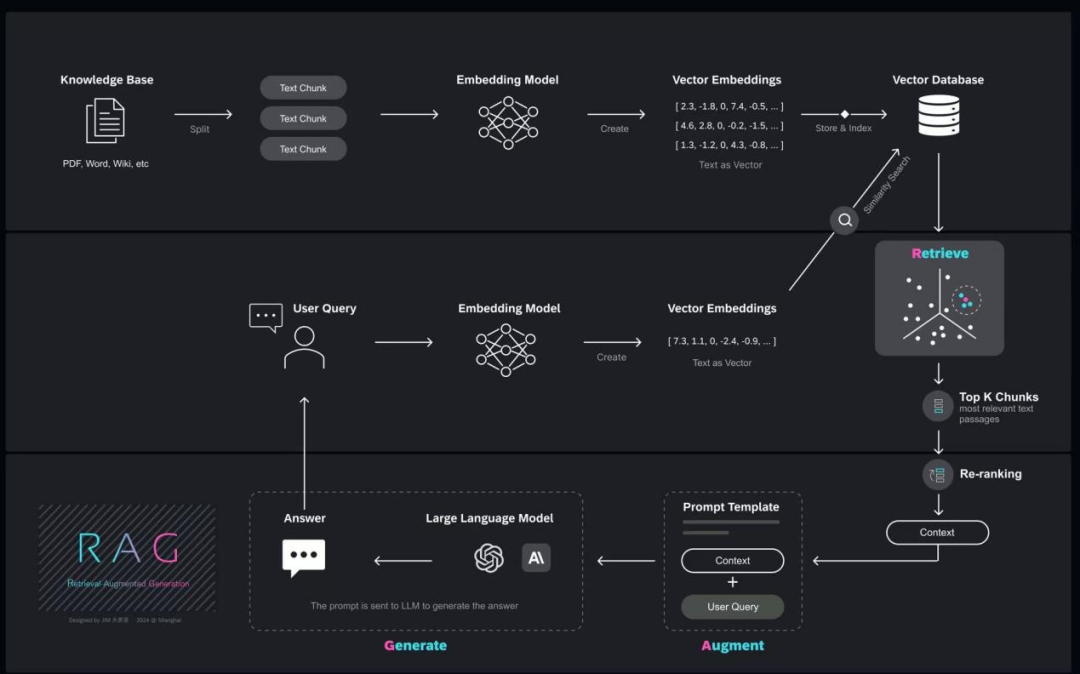
在这一部分主要流程就是读取pdf格式文件并转换为文档形式、将每个文档按照固定大小的chunk进行划分(有点类似于滑动窗口)、对每个chunk的文本生成嵌入向量及其对应的元数据、保存向量数据库。在构建向量数据库时可以做一些处理来增强后续检索的准确率,比如说在对所有文档进行chunk划分后,对于每一个chunk可以生成一段摘要和一系列使用者可能回根据这个chunk内容提出的问题,将这两部分内容分别存储在一个集合中,它们通过每个chunk的唯一标识id进行连接。还有就是可以调整chunk大小让其划分更加细致化即每段包含的内容更加精细,不过这样会增加计算和存储成本。在构建数据库时添加合适的元数据,可以使得模型推理的答案更加具有可解释性,比如回答完成后返回答案参考了那几篇文档的第几页,方便我们验证溯源。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
import argparse
from typing import List
from langchain_community.document_loaders import DirectoryLoader, PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
from langchain.schema import Document
import uuid
from tqdm import tqdm
# ------------ 配置参数 -----------
# PDF文档路径
DOCUMENT_PATH = r"D:\APP\Pycharm\LLM_RAG\my_knowledge\医疗问答系统"
# Chroma数据库路径
CHROMA_DB_PATH = r"D:\APP\Pycharm\LLM_RAG\chroma_db\medical"
# 嵌入模型
EMBEDDING_MODEL = "BAAI/bge-large-zh-v1.5"
class MedicalKnowledgeBuilder:
"""
医疗知识库构建器
"""
def __init__(self, document_path: str, chroma_db_path: str):
"""
初始化
Args:
document_path: PDF文档路径
chroma_db_path: Chroma数据库存储路径
"""
self.document_path = document_path
self.chroma_db_path = chroma_db_path
# 初始化嵌入模型
print(f"加载嵌入模型: {EMBEDDING_MODEL}")
self.embeddings = HuggingFaceEmbeddings(
model_name=EMBEDDING_MODEL,
model_kwargs={'device': 'cpu'}, # 或 'cuda' 如果有GPU
encode_kwargs={'normalize_embeddings': True}
)
def load_pdf_documents(self, batch_size: int = 5):
"""
加载PDF文档
Args:
batch_size: 批量处理大小
Returns:
List[Document]: 加载后的文档列表
"""
print(f"从 {self.document_path} 加载PDF文档...")
documents = []
pdf_files = []
# 收集所有PDF文件
for root, _, files in os.walk(self.document_path):
for file in files:
if file.lower().endswith('.pdf'):
pdf_files.append(os.path.join(root, file))
print(f"找到 {len(pdf_files)} 个PDF文件")
# 分批处理,避免内存溢出
for i in tqdm(range(0, len(pdf_files), batch_size), desc="加载PDF文件"):
batch_files = pdf_files[i:i + batch_size]
for pdf_file in batch_files:
try:
print(f"处理文件: {os.path.basename(pdf_file)}")
# 加载PDF文档
loader = PyPDFLoader(pdf_file)
docs = loader.load()
# 为每个文档添加基础元数据
for j, doc in enumerate(docs):
doc.metadata.update({
"source": pdf_file,
"file_name": os.path.basename(pdf_file),
"page": j + 1,
"doc_id": str(uuid.uuid4()),
})
documents.extend(docs)
print(f" 已加载: {os.path.basename(pdf_file)} - {len(docs)}页")
except Exception as e:
print(f"加载文件 {pdf_file} 时出错: {str(e)}")
continue
print(f"成功加载 {len(documents)} 个文档页面")
return documents
def split_documents(self, documents: List[Document], chunk_size: int = 800, chunk_overlap: int = 150):
"""
分割文档为块,优化中文医疗文本处理
Args:
documents: 文档列表
chunk_size: 块大小
chunk_overlap: 块重叠大小
Returns:
List[Document]: 分割后的文档块
"""
print(f"分割文档,块大小: {chunk_size}, 重叠: {chunk_overlap}")
# 创建针对中文医疗文本的文本分割器
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len,
separators=["\n\n", "\n", "。", "!", "?", ";", ",", "、", " ", ""],
keep_separator=True
)
# 分割文档
chunks = text_splitter.split_documents(documents)
print(f"文档分割完成,共 {len(chunks)} 个块")
return chunks
def add_chunk_metadata(self, chunks: List[Document]):
"""
为文档块添加基础元数据
Args:
chunks: 文档块列表
Returns:
List[Document]: 添加元数据后的文档块
"""
print("为文档块添加元数据...")
for i, chunk in enumerate(chunks):
# 添加块ID
chunk.metadata["chunk_id"] = str(uuid.uuid4())
# 添加块索引
chunk.metadata["chunk_index"] = i
# 添加字符数
chunk.metadata["char_count"] = len(chunk.page_content)
print(f"元数据添加完成,共处理 {len(chunks)} 个块")
return chunks
def create_vector_store(self, chunks: List[Document], collection_name: str = "medical_knowledge"):
"""
创建Chroma向量存储
Args:
chunks: 文档块列表
collection_name: 集合名称
Returns:
Chroma: 向量存储对象
"""
print(f"\n创建Chroma向量存储,集合: {collection_name}")
# 确保数据库目录存在
os.makedirs(self.chroma_db_path, exist_ok=True)
# 创建向量存储
vector_store = Chroma.from_documents(
documents=chunks,
embedding=self.embeddings,
persist_directory=self.chroma_db_path,
collection_name=collection_name,
collection_metadata={
"hnsw:space": "cosine",
"description": "中医医疗知识库",
"total_chunks": len(chunks)
}
)
# 持久化
vector_store.persist()
# 打印统计信息
self.print_statistics(chunks)
return vector_store
def print_statistics(self, chunks: List[Document]):
"""
打印文档统计信息
Args:
chunks: 文档块列表
"""
print(f"向量存储创建完成,保存到: {self.chroma_db_path}")
print(f"向量存储信息:")
print(f" - 文档块数量: {len(chunks)}")
print(f" - 集合名称: medical_knowledge")
print(f" - 嵌入维度: {self.embeddings.client.encode('测试').shape[0]}")
# 计算平均块大小
if chunks:
avg_chunk_size = sum(len(c.page_content) for c in chunks) / len(chunks)
print(f" - 平均块大小: {avg_chunk_size:.0f} 字符")
# 文件来源统计
sources = {}
for chunk in chunks:
source = chunk.metadata.get("source", "未知")
if source not in sources:
sources[source] = 0
sources[source] += 1
print(f" - 来源文件数: {len(sources)}")
def build_knowledge_base(self):
"""
构建完整的医疗知识库
"""
print("=" * 60)
print("开始构建医疗知识库 - 极简版")
print("=" * 60)
# 1. 加载PDF文档
print("\n步骤1: 加载PDF文档")
documents = self.load_pdf_documents(batch_size=3)
if not documents:
print("未找到PDF文档,程序退出")
return
# 2. 分割文档
print("\n步骤2: 分割文档")
chunks = self.split_documents(documents)
# 3. 添加元数据
print("\n步骤3: 添加元数据")
chunks = self.add_chunk_metadata(chunks)
# 4. 创建向量存储
print("\n步骤4: 创建向量存储")
vector_store = self.create_vector_store(chunks)
print("\n" + "=" * 60)
print("医疗知识库构建完成!")
print("=" * 60)
return vector_store
def main():
parser = argparse.ArgumentParser(description="医疗知识库构建工具 - 极简版")
parser.add_argument("--doc_path", type=str, default=DOCUMENT_PATH,
help="PDF文档路径")
parser.add_argument("--db_path", type=str, default=CHROMA_DB_PATH,
help="Chroma数据库存储路径")
parser.add_argument("--chunk_size", type=int, default=500,
help="文档块大小")
parser.add_argument("--chunk_overlap", type=int, default=100,
help="文档块重叠大小")
parser.add_argument("--batch_size", type=int, default=4,
help="批量处理大小")
args = parser.parse_args()
# 构建医疗知识库
builder = MedicalKnowledgeBuilder(
document_path=args.doc_path,
chroma_db_path=args.db_path
)
builder.build_knowledge_base()
if __name__ == '__main__':
main()2.2 knowledge_retrieve.py
这一部分主要是进行检索-增强环节了,主要就是定义了一个语义相似度检索器和大模型推理的提示词。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import os
import argparse
from typing import List
from langchain.chains import LLMChain
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import Chroma
from langchain_community.llms import Ollama
from langchain.prompts import ChatPromptTemplate
from langchain.schema import Document
# ------------ 配置参数 -----------
# 嵌入模型
EMBEDDING_MODEL = "BAAI/bge-large-zh-v1.5"
# LLM模型
LLM_MODEL = "deepseek-r1:14b"
# Chroma数据库路径
CHROMA_DB_PATH = r"D:\APP\Pycharm\LLM_RAG\chroma_db\medical"
# 集合名称
COLLECTION_NAME = "medical_knowledge"
class MedicalRetrievalPipeline:
"""
医疗知识检索与问答管道
"""
def __init__(self, chroma_db_path: str, embedding_model: str, llm_model: str):
"""
初始化
Args:
chroma_db_path: Chroma数据库路径
embedding_model: 嵌入模型名称
llm_model: LLM模型名称
"""
self.chroma_db_path = chroma_db_path
# 初始化嵌入模型
print(f"加载嵌入模型: {embedding_model}")
self.embeddings = HuggingFaceEmbeddings(
model_name=embedding_model,
model_kwargs={'device': 'cpu'}, # 或 'cuda' 如果有GPU
encode_kwargs={'normalize_embeddings': True}
)
# 初始化LLM
print(f"加载LLM模型: {llm_model}")
self.llm = Ollama(
model=llm_model,
temperature=0.1,
num_predict=2048
)
# 加载向量数据库
self.vector_store = self.load_vector_store()
def load_vector_store(self):
"""
加载Chroma向量数据库
Returns:
Chroma: 向量存储对象
"""
print(f"加载向量数据库: {self.chroma_db_path}")
if not os.path.exists(self.chroma_db_path):
print(f"错误: 向量数据库路径不存在: {self.chroma_db_path}")
return None
# 加载向量数据库
vector_store = Chroma(
persist_directory=self.chroma_db_path,
embedding_function=self.embeddings,
collection_name=COLLECTION_NAME
)
# 获取集合信息
collection = vector_store._client.get_collection(COLLECTION_NAME)
if collection:
print(f"向量数据库加载成功,文档数量: {collection.count()}")
else:
print("向量数据库加载失败,集合可能不存在")
return vector_store
def retrieve_documents(self, query: str, k: int = 5, score_threshold: float = 0.5):
"""
检索相关文档
Args:
query: 查询文本
k: 返回的文档数量
score_threshold: 相似度阈值
Returns:
List[Document]: 检索到的文档列表
"""
if not self.vector_store:
print("向量数据库未加载,无法检索")
return []
print(f"检索查询: '{query}'")
# 方法1: 相似度搜索
try:
# 使用相似度搜索
docs_with_scores = self.vector_store.similarity_search_with_relevance_scores(
query=query,
k=k
)
# 过滤低分文档
filtered_docs = []
for doc, score in docs_with_scores:
if score >= score_threshold:
filtered_docs.append(doc)
print(f" 相似度: {score:.3f} - 来源: {doc.metadata.get('file_name', '未知')}")
else:
print(f" 丢弃 (相似度低于阈值): {score:.3f}")
return filtered_docs
except Exception as e:
print(f"检索时出错: {str(e)}")
# 回退到简单检索
docs = self.vector_store.similarity_search(query, k=k)
return docs
def format_documents_for_context(self, documents: List[Document]) -> str:
"""
格式化文档为上下文字符串
Args:
documents: 文档列表
Returns:
str: 格式化后的上下文
"""
if not documents:
return "没有找到相关文档。"
context_parts = []
for i, doc in enumerate(documents, 1):
# 获取元数据信息
file_name = doc.metadata.get("file_name", "未知文件")
page = doc.metadata.get("page", "未知")
source = doc.metadata.get("source", "").split("\\")[-1] if "source" in doc.metadata else ""
# 构建文档头
doc_header = f"【文档 {i}】"
if file_name != "未知文件":
doc_header += f" 文件: {file_name}"
if page != "未知":
doc_header += f" 页码: {page}"
if source:
doc_header += f" 来源: {source}"
# 添加内容
doc_content = f"{doc_header}\n{doc.page_content}\n"
context_parts.append(doc_content)
return "\n".join(context_parts)
def build_medical_prompt(self, query: str, context: str) -> str:
"""
构建医疗问答提示词
Args:
query: 用户问题
context: 检索到的上下文
Returns:
str: 格式化后的提示词
"""
prompt_template = """
你是一位专业的医疗知识问答助手,请根据以下提供的医疗文档内容,准确、专业地回答用户的问题。
**重要指示:**
1. **严格基于文档**:你的回答必须完全基于提供的文档内容,不要添加文档以外的信息。
2. **专业术语**:使用专业、准确的医学术语。
3. **明确标注**:如果文档中没有相关信息,请明确说明"根据提供的文档,没有找到相关问题的信息"。
4. **结构清晰**:对于复杂问题,可以分点回答。
5. **中医特色**:如果是中医相关问题,注意体现中医特色和术语。
**医疗文档内容:**
{context}
**用户问题:**
{question}
**请根据上述文档内容回答问题:**
"""
return prompt_template.format(context=context, question=query)
def generate_answer(self, query: str, documents: List[Document], stream: bool = False):
"""
生成答案
Args:
query: 用户问题
documents: 检索到的文档
stream: 是否流式输出
Returns:
str: 生成的答案
"""
if not documents:
return "抱歉,在知识库中没有找到与您问题相关的信息。"
# 格式化上下文
context = self.format_documents_for_context(documents)
# 构建提示词
prompt_text = self.build_medical_prompt(query, context)
if stream:
# 流式输出
print("\n" + "=" * 60)
print("正在生成回答...")
print("=" * 60 + "\n")
# 使用LLM生成流式响应
response_stream = self.llm.stream(prompt_text)
full_response = ""
for chunk in response_stream:
print(chunk, end="", flush=True)
full_response += chunk
print("\n" + "=" * 60)
print("回答生成完成")
print("=" * 60)
return full_response
else:
# 非流式输出
print("\n正在生成回答...")
answer = self.llm(prompt_text)
return answer
def run_query(self, query: str, k: int = 5, stream: bool = True):
"""
执行完整的查询流程
Args:
query: 用户问题
k: 检索文档数量
stream: 是否流式输出
Returns:
str: 生成的答案
"""
print("=" * 60)
print("医疗知识问答系统")
print("=" * 60)
# 1. 检索相关文档
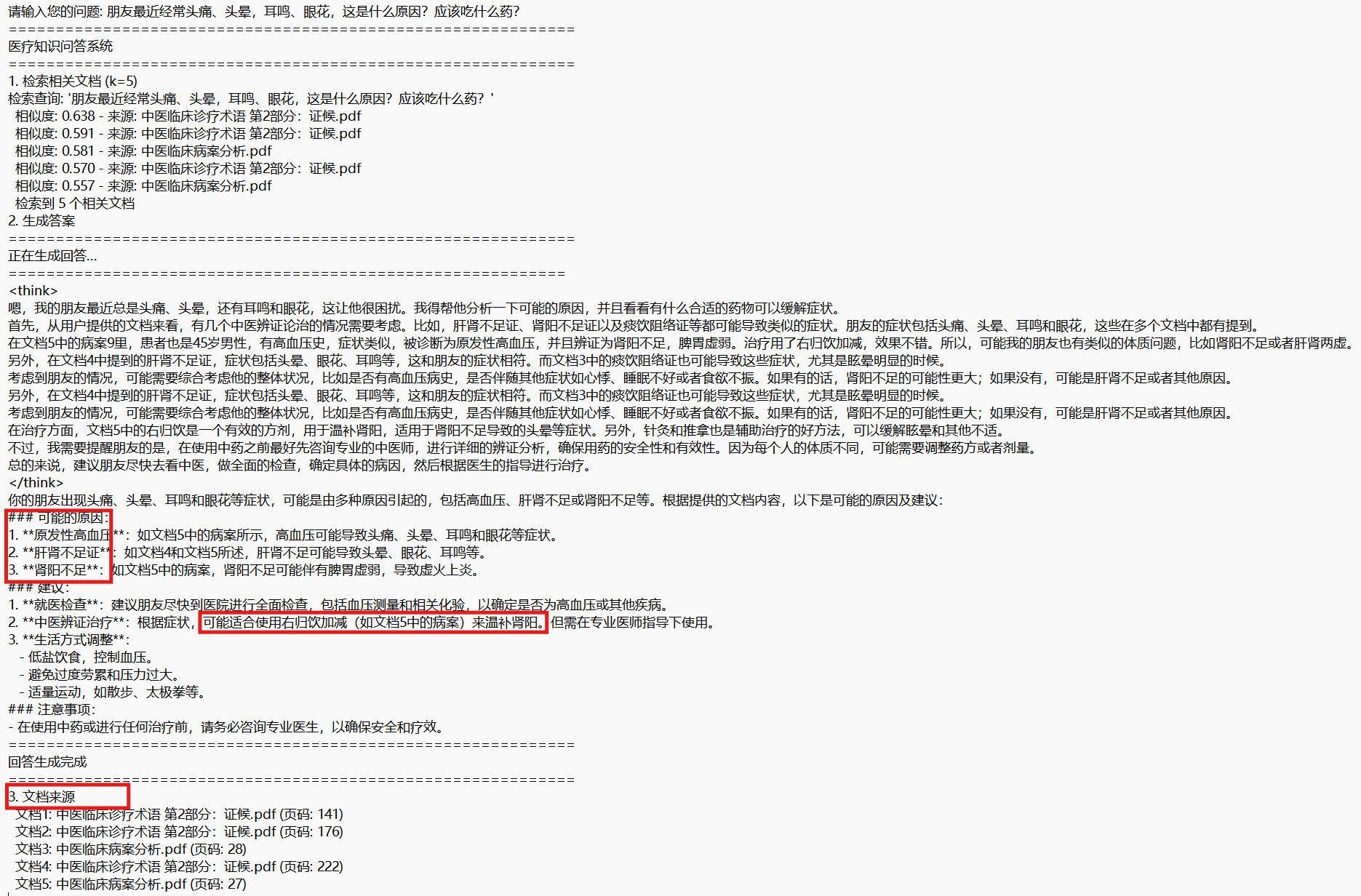
print(f"\n1. 检索相关文档 (k={k})")
documents = self.retrieve_documents(query, k=k)
if not documents:
print(" 未找到相关文档")
return "抱歉,在知识库中没有找到与您问题相关的信息。"
print(f" 检索到 {len(documents)} 个相关文档")
# 2. 生成答案
print(f"\n2. 生成答案")
answer = self.generate_answer(query, documents, stream=stream)
# 3. 显示文档来源
print(f"\n3. 文档来源")
for i, doc in enumerate(documents, 1):
file_name = doc.metadata.get("file_name", "未知文件")
page = doc.metadata.get("page", "未知")
print(f" 文档{i}: {file_name} (页码: {page})")
return answer
def main():
parser = argparse.ArgumentParser(description="医疗知识检索与问答系统")
parser.add_argument("--db_path", type=str, default=CHROMA_DB_PATH,
help="Chroma数据库存储路径")
parser.add_argument("--embedding_model", type=str, default=EMBEDDING_MODEL,
help="嵌入模型名称")
parser.add_argument("--llm_model", type=str, default=LLM_MODEL,
help="LLM模型名称")
parser.add_argument("--k", type=int, default=5,
help="检索文档数量")
parser.add_argument("--no_stream", action="store_true",
help="关闭流式输出")
args = parser.parse_args()
# 初始化检索管道
print("初始化医疗知识检索系统...")
pipeline = MedicalRetrievalPipeline(
chroma_db_path=args.db_path,
embedding_model=args.embedding_model,
llm_model=args.llm_model
)
# 交互式问答循环
print("\n" + "=" * 60)
print("医疗知识问答系统已启动")
print("输入 'exit' 或 'quit' 退出系统")
print("=" * 60)
while True:
try:
# 获取用户输入
query = input("\n请输入您的问题: ").strip()
if query.lower() in ["exit", "quit", "退出"]:
print("\n感谢使用医疗知识问答系统,再见!")
break
if not query:
print("问题不能为空,请重新输入")
continue
# 执行查询
pipeline.run_query(
query=query,
k=args.k,
stream=not args.no_stream
)
except KeyboardInterrupt:
print("\n\n程序被中断,正在退出...")
break
except Exception as e:
print(f"\n发生错误: {str(e)}")
print("请重新输入问题")
if __name__ == '__main__':
main()三、结果展示与对比