网页数据是大模型预训练的核心来源(如Common Crawl),但需先将HTML转换为结构化文本。现有工具(Trafilatura、Resiliparse)依赖启发式规则 (如文本密度、DOM树遍历规则),导致代码块、公式、表格等结构化元素丢失或损坏,进而影响大模型预训练效果。(工具未开源,仅看思路。)
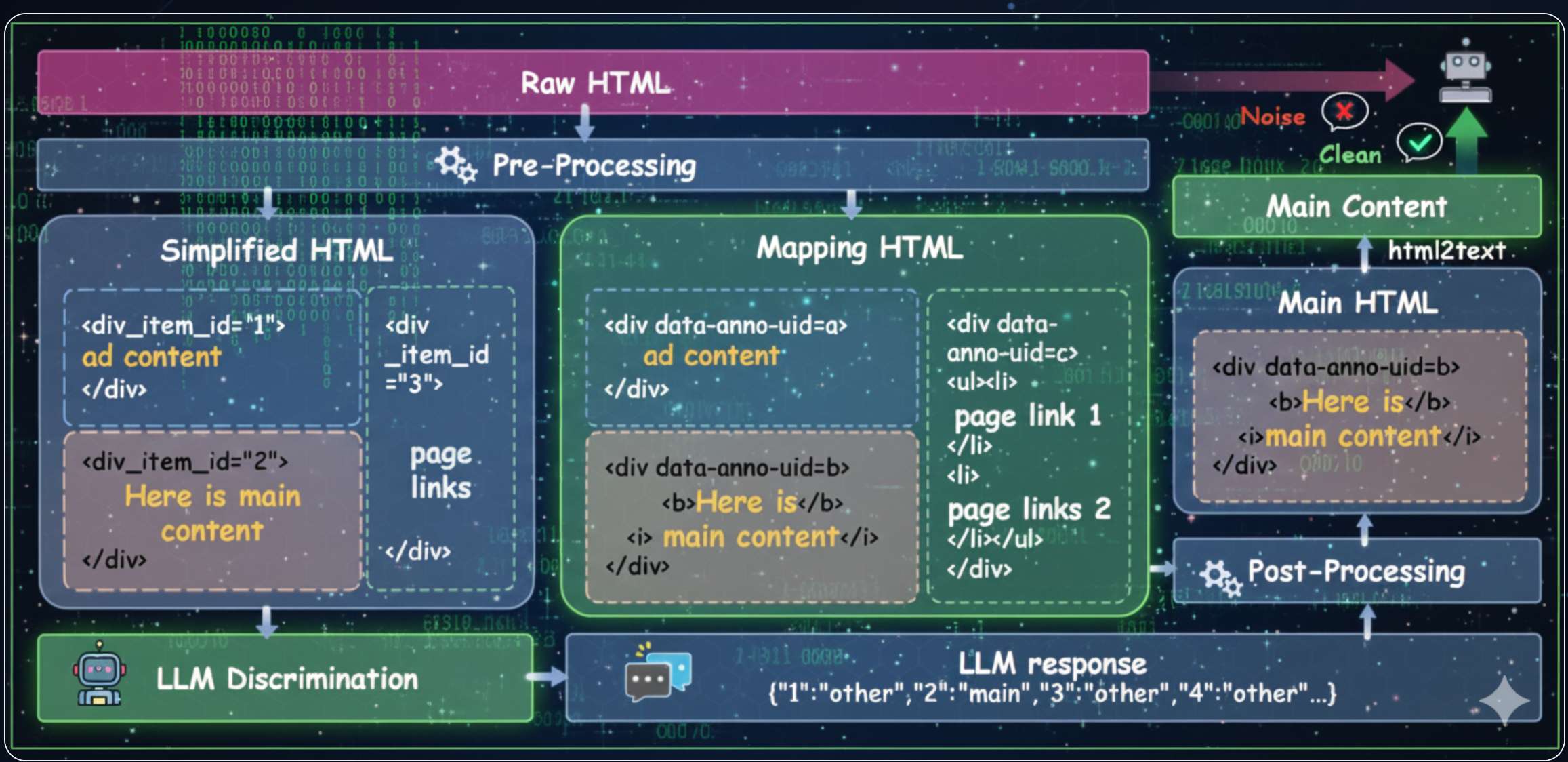
方法:MinerU-HTML pipline
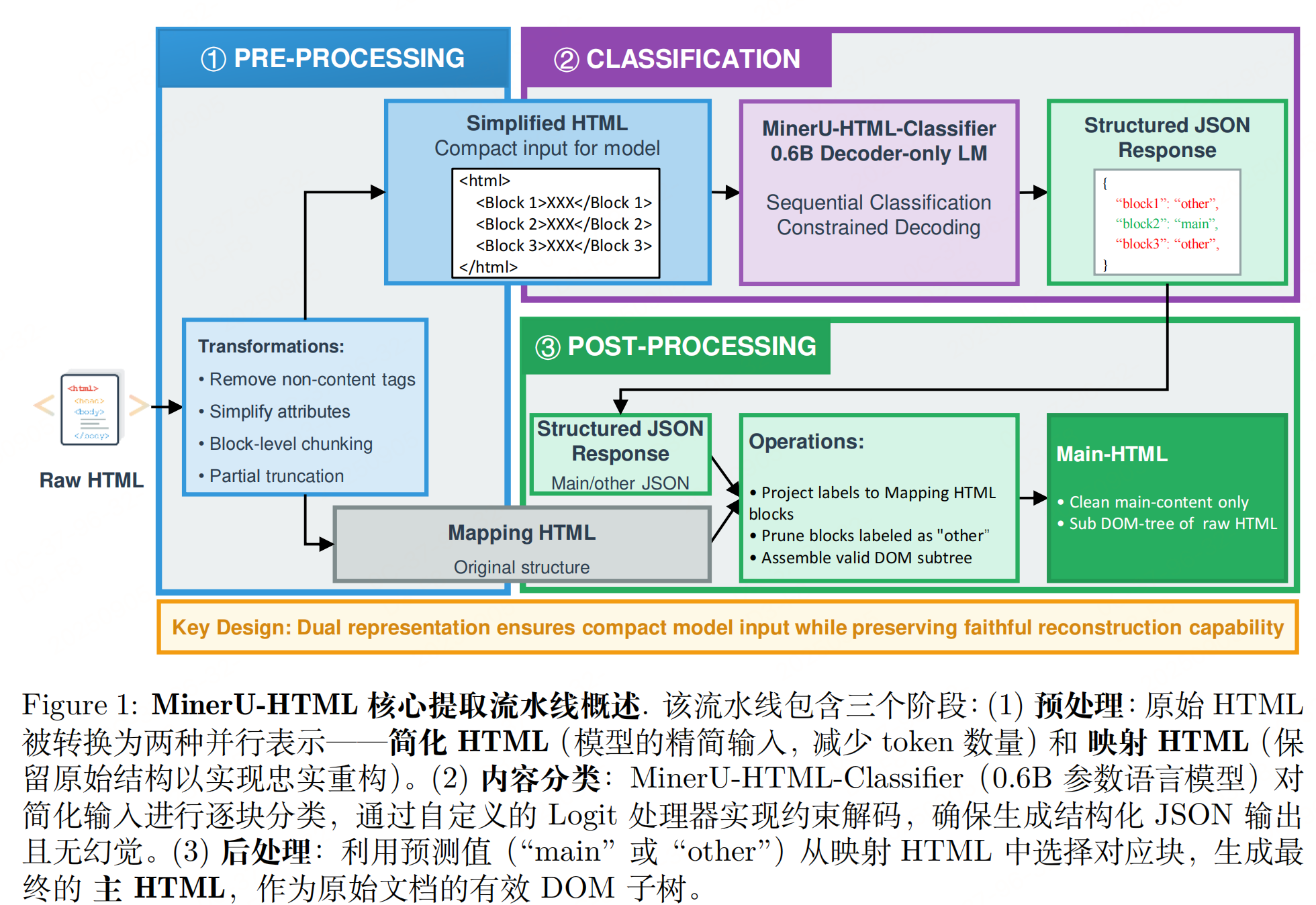
如上图,如果不依赖规则,那就设计一套语义感知的两阶段提取管道,将"HTML提取"从"固定预处理步骤"转化为为"语义理解任务"。整体流程为:原始HTML → 第一阶段(Main-HTML提取)→ 第二阶段(文档格式化)→ Markdown。
下面具体看下两个阶段:
1. 第一阶段:Main-HTML提取(核心是"语义化筛选主内容")
目标是从原始HTML中剥离冗余(广告、导航栏),保留主内容及完整结构。
(1)三步骤流程(单文档处理)
-
预处理:生成双路HTML
原始HTML包含大量渲染无关标记(如
<style>、<script>),直接输入模型会导致token爆炸。因此设计双路转换:- 简化HTML(Simplified HTML):移除非内容标签、保留关键属性(class/id)、按语义块分割(表格、列表视为原子块)、截断超长块,大幅减少模型输入token;
- 映射HTML(Mapping HTML):仅保留块级分割,不修改原始结构,用于后续忠实重建主内容。
双轨设计既降低了模型计算负担,又避免了结构信息丢失。
-
内容分类:序列标注+约束解码
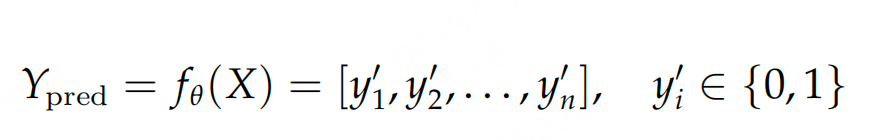
摒弃启发式规则,将"主内容筛选"转化为序列标注任务:将简化HTML的每个语义块标注为"main(主内容)"或"other(冗余)"。使用0.6B参数的Qwen3-0.6B(32K上下文窗口,支持100+语言),兼顾轻量性与语义理解能力;约束解码:通过确定性有限状态机(FSM)控制输出格式(JSON-like),仅允许"main/other"二选一,完全避免模型幻觉(生成不存在的内容)或格式错误。
-
后处理:重建Main-HTML:将标注结果映射回"映射HTML",剔除"other"块,保留的"main"块组成完整的DOM子树(Main-HTML),确保输出结构合法、内容忠实于原始文档。
(2)扩大规模
单文档模型推理成本高,无法直接应用于Common Crawl(数百亿文档)。论文利用"网页结构的规律性"(同一子域名的页面多来自相同模板),设计模板感知优化策略:
- 按子域名聚类,确保同集群页面结构相似;
- 每个集群选1个结构最丰富的页面,用完整模型管道处理;
- 将模型对该页面的标注结果,转化为可解释的XPath/CSS规则;
2. 第二阶段:文档格式化
Main-HTML仍是渲染导向的标记语言,需转换为LLM友好的Markdown格式。设计"中间表示+类型专用规则"的两阶段转换:
(1)第一步:HTML→结构化内容列表(JSON)
将Main-HTML解析为JSON格式的"内容列表",明确标注每个元素的语义类型(标题、段落、代码块、公式、表格等),并存储专属属性(如标题层级、代码语言、公式类型)。例如:
json
{
"type": "code",
"content": {"code_content": "...", "language": "Python"}
}(2)第二步:内容列表→Markdown
针对每种语义类型设计专用转换规则,确保格式保真:
- 代码块:保留缩进、语法标记,用```包裹;
- 公式:区分行内
($...$)与块级($$...$$),保留LaTeX/MathML完整语法; - 表格:简单表格直接转Markdown格式,复杂表格(合并单元格、嵌套)保留HTML结构以避免信息丢失;
- 标题/列表:严格遵循Markdown层级(#数量对应标题级别,-/*对应列表)。
MinerU-HTML 的迭代优化路径
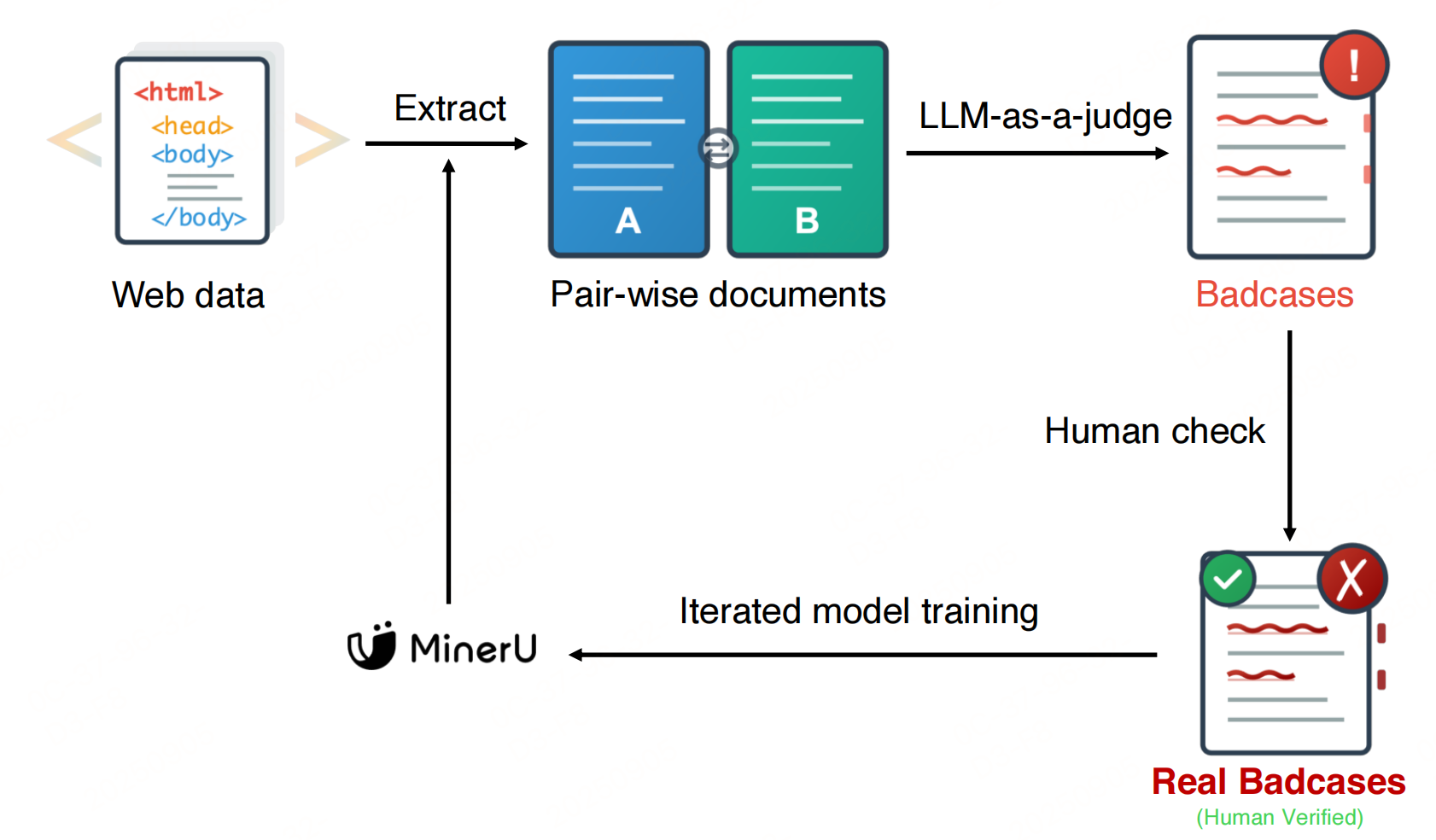
通过收集更多训练数据(包括失败案例),在扩展的数据集上重新训练,并利用基础模型能力的提升,可以系统性地改进基于模型的提取器。随着语言模型持续进步,这一方法具有天然的可扩展性和未来适应性。
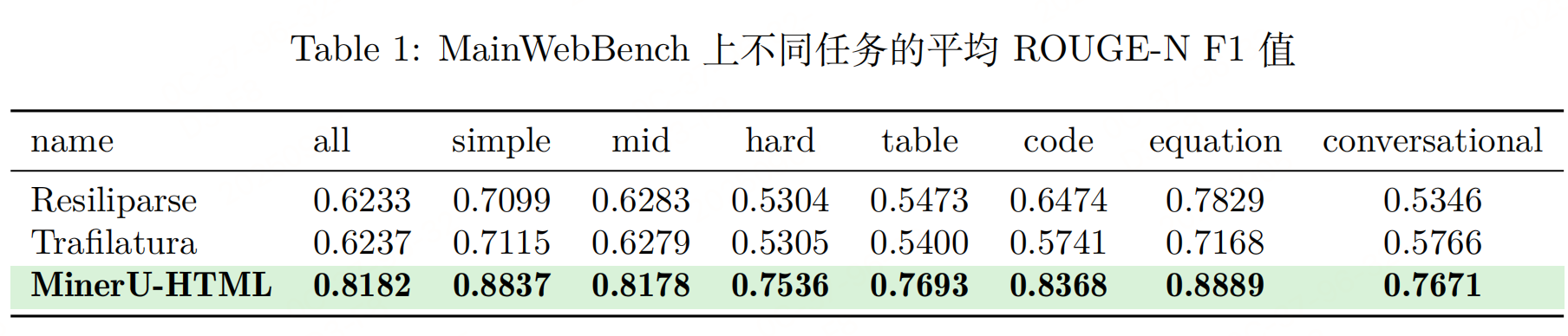
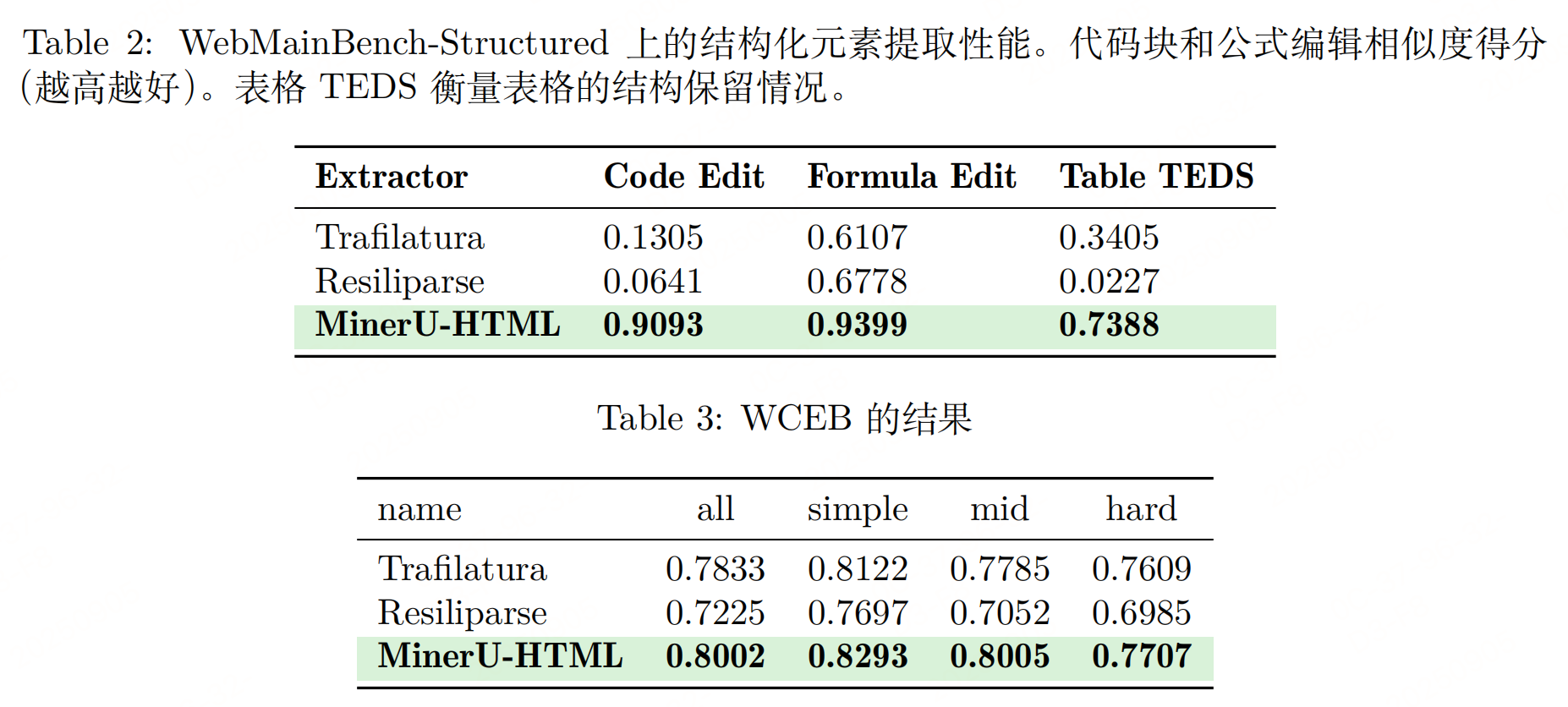
评估
参考文献:https://arxiv.org/pdf/2511.16397v1,AICC: Parse HTML Finer, Make Models Better ------ A 7.3T AI-Ready Corpus Built by a Model-Based HTML Parser