如何理解多模态 RAG的具体含义?简而言之,多模态 RAG 是将检索增强生成技术扩展至多模态数据场景的系统架构 ,旨在支持对图像、语音、文本、视频等多种模态的查询输入与知识检索,并在此基础上生成连贯、准确的回答。根据当前的技术发展水平与实际落地经验,多模态 RAG 主要涵盖以下两个关键维度:富媒体文档问答和多模态输入问答
一、富媒体文档问答
这是多模态 RAG 最常见的应用形态。以一份包含文字、图片、表格和公式的 PDF 文档为例,系统通常需经历以下五个核心阶段:
( 1) 解析阶段(Parsing)
对原始文档进行多模态内容解析:提取文本内容,对图像、图表、公式等非文本元素分别进行识别与结构化处理(如 OCR 提取图中文字、表格转为结构化格式、公式识别等),形成可处理的多模态数据单元。
( 2) 索引阶段(Indexing)
将解析后的多模态内容转化为统一或对齐的表示形式(如文本归一化、向量嵌入等),并构建支持跨模态检索的知识库或向量索引,作为后续检索的基础。
( 3) 检索阶段(Retrieval)
当用户以自然语言提出查询时,系统根据查询语义从索引中检索最相关的多模态片段(可能包括文本段落、图像描述、表格摘要等),形成上下文证据集。
( 4) 增强阶段(Augmentation)
将检索到的多模态相关信息进行融合与组织,构造适合生成模型理解的输入上下文。此阶段可能涉及模态对齐、信息去重、关键内容提炼等处理。
( 5) 生成阶段(Generation)
大语言模型(或具备多模态理解能力的生成模型)基于增强后的上下文,综合文本与视觉等多源信息,生成准确、连贯且符合用户意图的回答。这一流程体现了多模态 RAG 在复杂文档理解与问答任务中的典型工作范式,兼顾实用性与可扩展性。
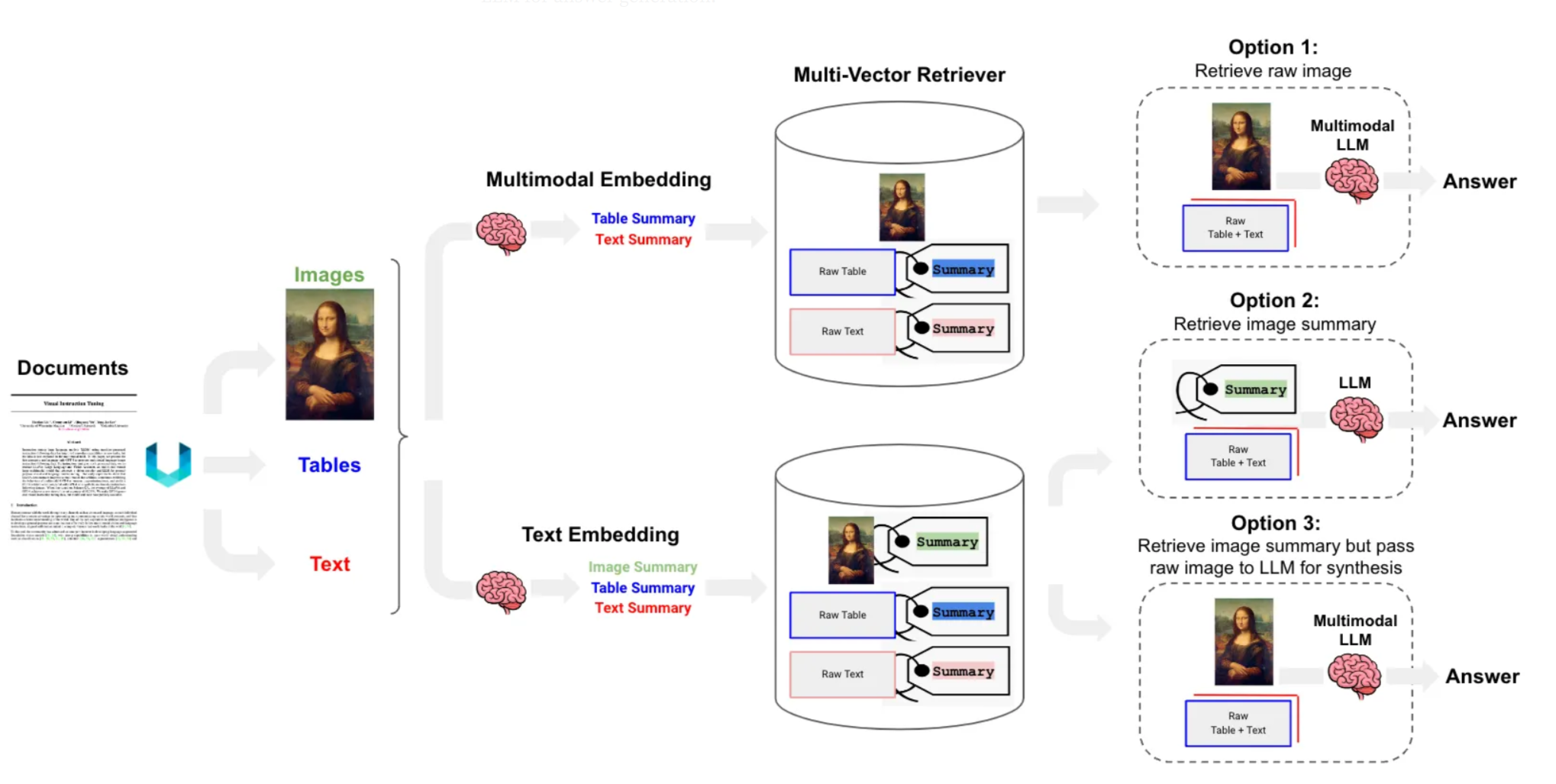
这要求系统不仅能识别图像中的内容,还需深入理解其中的结构化语义信息 ------例如图表的布局、表格的行列关系、公式或流程图的逻辑结构等,并将这些视觉信息与文本内容统一纳入知识检索体系 。完整的处理流程通常如下:
首先,系统对输入文档(如 PDF)进行多模态解析,分别提取文本内容和视觉元素(包括图像、表格、公式等),并将其转化为可检索的结构化或语义化表示;
随后,当用户以自然语言提出问题时,系统能够结合文本与视觉信息进行联合推理,生成准确、全面的回答。
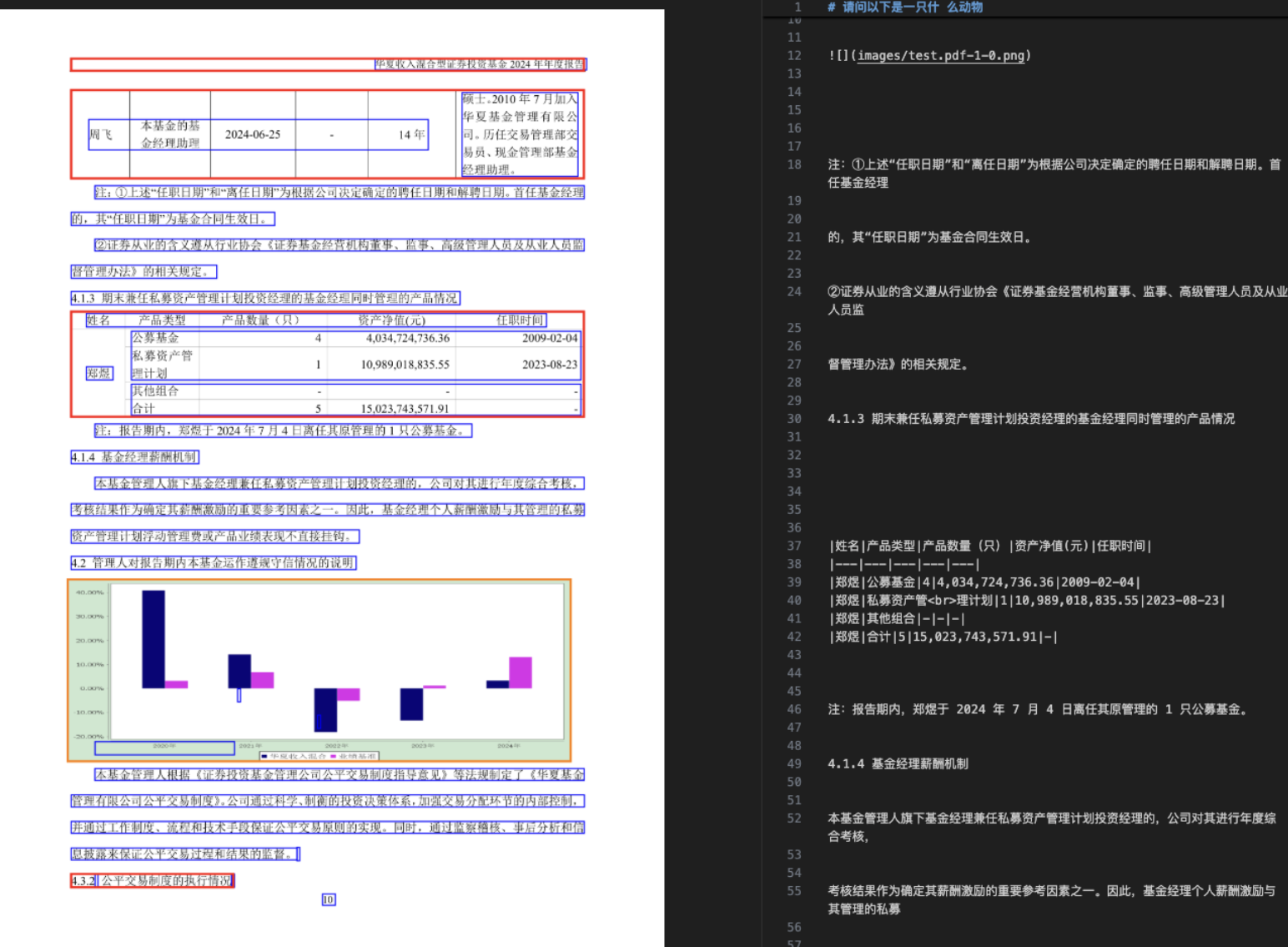
二、多模态输入问答
这一维度更进一步:用户的查询本身即为非文本模态 ,例如图像、音频或视频。典型场景包括:
- 上传一张产品故障的图片,让 AI 诊断可能的问题;
- 提供一段会议录音,要求系统分析其中讨论的核心主题;
- 上传一段视频片段,询问其中的关键事件或信息。
在此类场景下,系统首先需利用相应的多模态理解模型(如图像识别、语音识别、视频理解等)将非文本查询转化为结构化或语义化的中间表示(例如文本描述、嵌入向量等),再基于该表示从多模态知识库中检索相关上下文信息。
从技术实现的角度来看,我们需要构建一套端到端的能力体系,以支持以下关键环节。但实际上,多模态RAG并不只是简单地把图片和文字混在一起处理。在落地应用中远比这复杂。
|------------|------------------|----------------|
| 关键技术环节 | 核心挑战 | 解决方案 |
| 数据预处理 | 如何从复杂文档中提取结构化信息 | OCR、表格识别、公式解析 |
| 向量表示 | 如何将不同模态映射到统一语义空间 | 多模态嵌入模型(CLIP等) |
| 检索匹配 | 如何实现跨模态的相似度计算 | 统一向量空间或多管线检索 |
| 答案生成 | 如何融合多模态信息生成回答 | 视觉语言模型(VLM) |
这张表格清晰地呈现了多模态 RAG 的核心技术链条。它涉及解析 检索和生成模型两方面的多模态处理 :
- 在检索阶段 ,系统需要具备对图像、音频、视频等非文本内容的理解能力,并构建相应的索引结构与跨模态搜索算法,以实现语义对齐的高效检索;
- 在生成阶段 ,则往往依赖具备多模态融合理解能力的模型(如视觉语言模型 Vision-Language Model, VLM),将来自不同模态的检索结果进行整合,并生成准确、连贯的回答。
正因如此,多模态 RAG 被广泛视为对传统文本 RAG 的重要扩展与能力跃升,用户可以用任意模态(文本、图像、语音等)提问,系统也能基于多模态知识库给出高质量回答。而这一能力的背后,每个环节都依赖专门设计的技术模块协同工作。