传统爬虫太耗时?AI一键生成企业级爬虫架构
回顾我们之前对数据采集领域的探讨,从《Python爬虫进阶:如何构建可持续的数据采集流程》到《亮数据(Bright Data) vs 快代理:海外数据采集代理方案对比》,再到《亮数据(Bright Data)Web Scraper IDE:为规模化数据采集而生》,一个核心脉络始终清晰:企业数据采集正从"技术实现"转向"流程化、规模化、可持续的运营"。
在过往的文章中,我们深入分析了:
- 传统爬虫在IP封锁、验证码、动态渲染面前举步维艰;
- 代理IP的管理是数据采集稳定性的生命线,而Bright Data的全球代理网络在其中展现出了显著优势;
- Web Scraper IDE 通过提供浏览器集成环境,将爬虫的编码、调试、部署和调度一体化,极大地提升了复杂采集任务的开发效率。
然而,我们也不止一次地提到,即便有了强大的IDE和代理,编写和维护爬虫代码本身,依然是一项高门槛、耗时费力的工作。业务部门一个紧急的数据需求,仍可能让开发团队加班数个日夜。
今天,这个最后的瓶颈被打破了。
Bright Data 最新推出的 AI Scraper Studio ,正是在我们之前探讨的所有坚实基础上,迈出的革命性一步。它标志着企业级数据采集正式进入了 "自然语言驱动" 的时代。
什么是 AI Scraper Studio?从"编码"到"描述"的范式转移
AI Scraper Studio 是一款基于AI驱动的企业级爬虫构建平台。它继承了我们之前盛赞的 Web Scraper IDE 的所有强大调度、代理和部署能力,但彻底改变了其使用方式。
现在,用户无需编写一行代码,只需输入自然语言 prompt,系统即可自动生成完整的爬虫脚本与API,实现从"描述需求"到"获取结构化数据"的全流程自动化。
这就像是为你配备了一位不知疲倦、精通全球网络协议、且能瞬间理解你意图的数据采集专家。
它精准解决了我们反复提及的痛点
回顾我们之前讨论的挑战,AI Scraper Studio 给出了直接答案:
- 告别高成本开发与维护(《Python爬虫进阶》的核心难题):无需手动编写、调试爬虫代码,AI自动生成脚本,将开发时间从"天/小时"缩短至"分钟"。
- 根除反爬与代理管理之忧(《亮数据 vs 快代理》的核心议题):直接集成Bright Data久经考验的全球代理与智能解封核心。
- 实现真正的规模化与可持续(《Web Scraper IDE》的设计初衷):在IDE提供的强大运维骨架之上,注入了AI的"智能大脑",让轻松管理数百个域名的定时采集任务成为现实。
- 快速响应业务变化:从业务想法的提出到数据输出,分钟级完成,让数据驱动决策不再滞后。
Bright Data 解决方案的进化:三大核心优势
-
Prompt 驱动,极速上线 输入目标网站和抓取需求,如"采集该网站所有产品价格和评价",AI 自动生成脚本并部署,无需编码。这可以看作是 Web Scraper IDE "可视化"操作的终极形态。
-
自愈与弹性扩展 它完美继承了Bright Data解决方案的灵魂------稳定与韧性。结合全球代理与智能解封系统,轻松应对网站封锁与结构变化。
-
全可见、全可控 这是对 Web Scraper IDE 优秀基因的传承 。当AI生成的脚本在极端复杂场景下需要微调时,你依然可以一键"Open in IDE",进入我们熟悉的那个强大编码环境,进行手动优化,兼具AI的效率与代码级的极致控制。
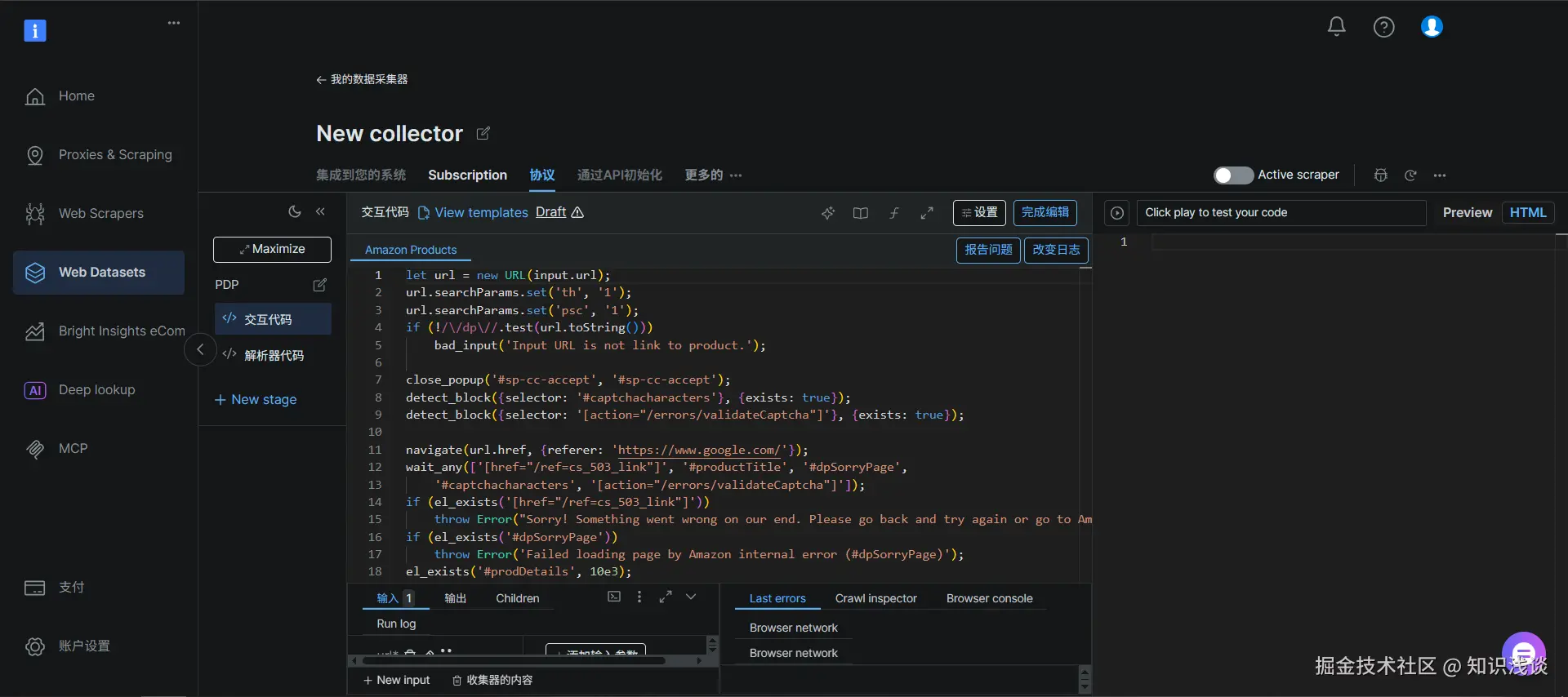
实践操作:三步体验 AI Scraper Studio 的颠覆性效率
下面,我们以一个真实场景------"采集亚马逊中联想电脑的相关信息,如产品图片,文字描述,评价信息" 为例,全程演示AI Scraper Studio如何将我们之前文章中提到的复杂流程极度简化。
第一步:进入AI Scraper Studio并输入指令
-
登录Bright Data控制台。如果你读过《亮数据(Bright Data)Web Scraper爬虫》,你会对这个界面感到熟悉。在左侧菜单栏找到 "Web Datasets" 并点击进入。
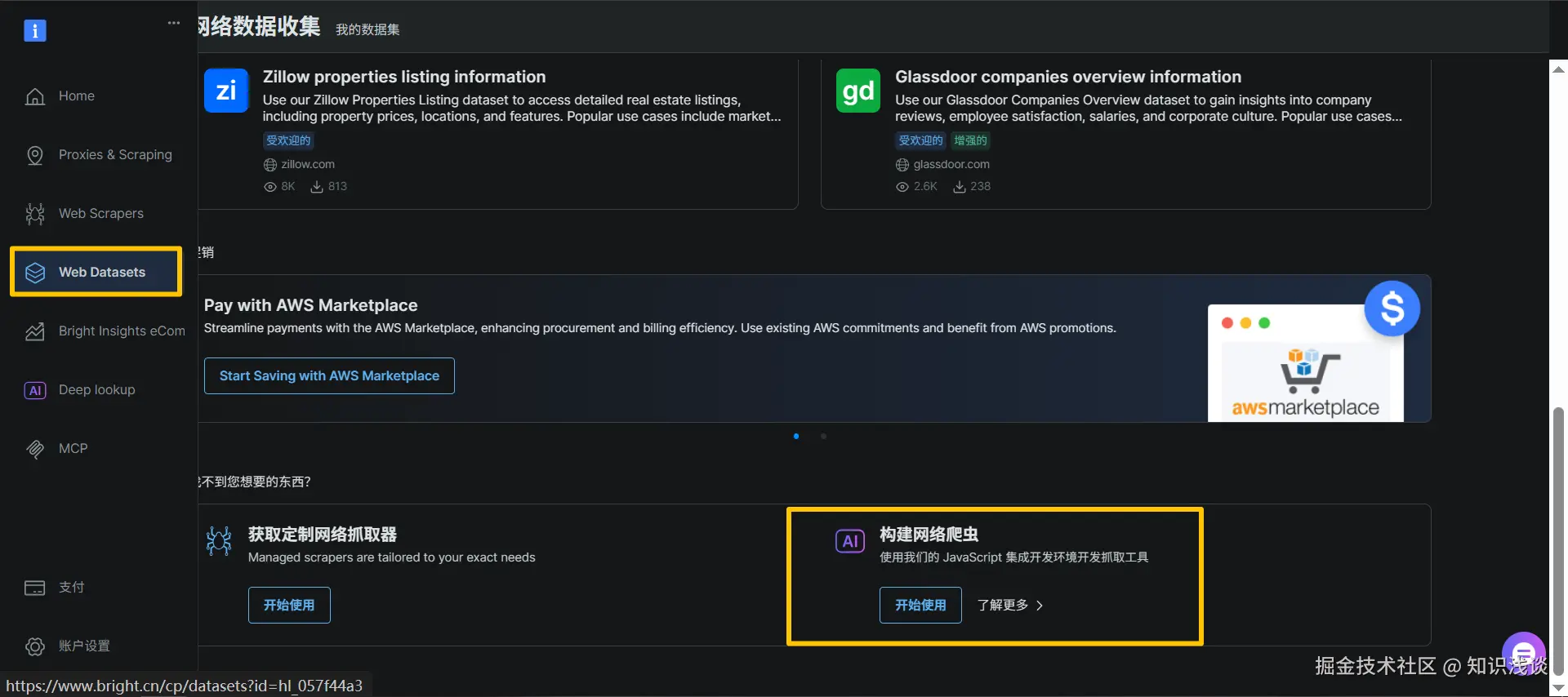
-
点击 "构建网络爬虫 中的快速使用 按钮,现在你看到了新的弹窗界面。
-
在核心输入框中,你只需要填写两项:
- 目标网站URL :例如我用的一个联想电脑商品
https://www.amazon.com/dp/B0FMLCQZM8?ref=dlx_black_dg_dcl_B0FMLCQZM8_dt_sl7_39_pi&pf_rd_r=AXZRY7YBXPF6B1RPEGR6&pf_rd_p=c709f9c4-cab6-4bd6-ad01-5c9a8bff3739&th=1 - 自然语言Prompt :清晰地描述你的需求,例如:"获取这个商品的图片URL、文字描述以及评价信息。"
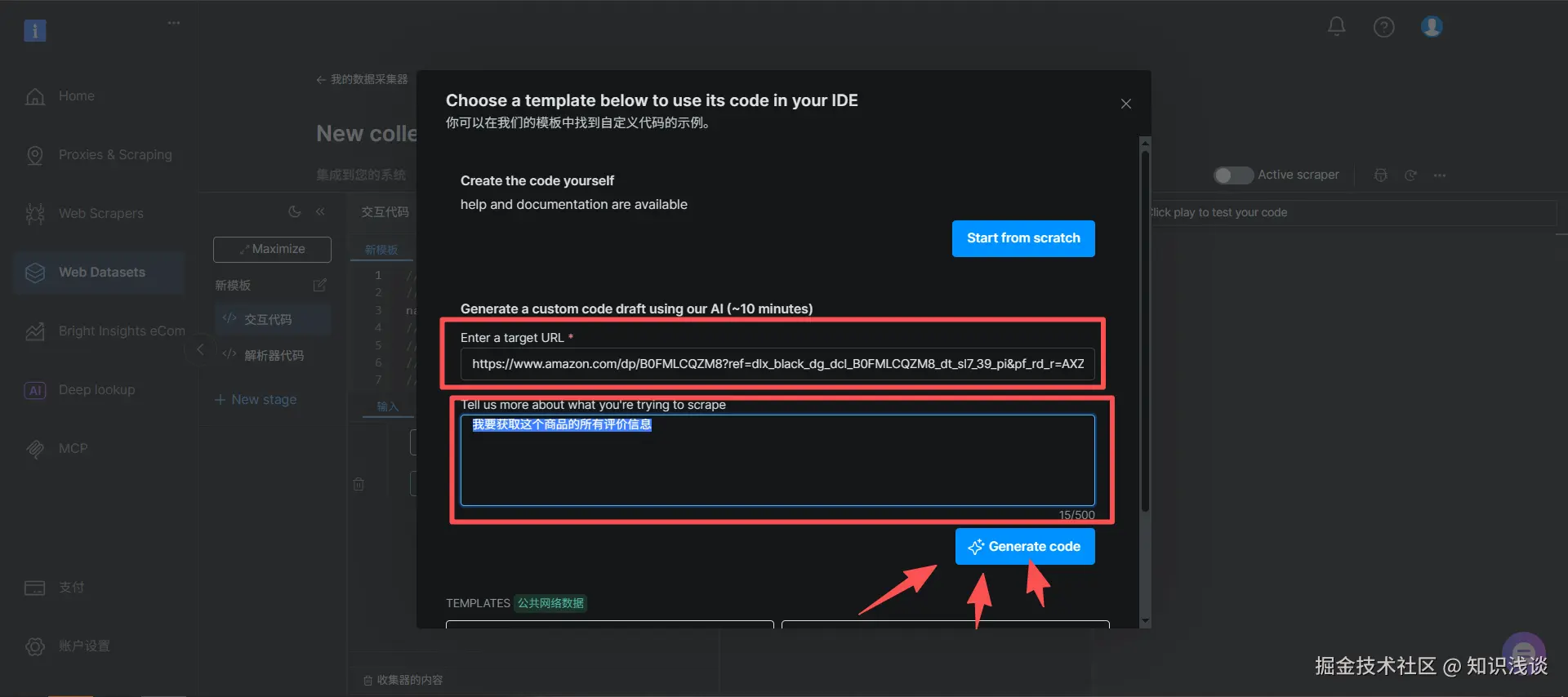 (上图:简洁直观的输入界面,是通往海量数据的起点)
(上图:简洁直观的输入界面,是通往海量数据的起点)
- 目标网站URL :例如我用的一个联想电脑商品
第二步:AI自动生成,一键运行获取数据
点击"Generate code"按钮后,AI引擎开始工作。它会自动分析目标网页的结构,理解你的自然语言指令,并在后台生成完整的爬虫代码。这个过程通常只需要1-10分钟,而以往这可能需要一个开发者数小时的工作。
完成后,界面会直接跳转到爬虫的预览和测试页面 。你可以立即看到AI帮我们写好的代码,点击交互代码-->点击preview-->点击运行测试按钮然后 就看到程序在运行了 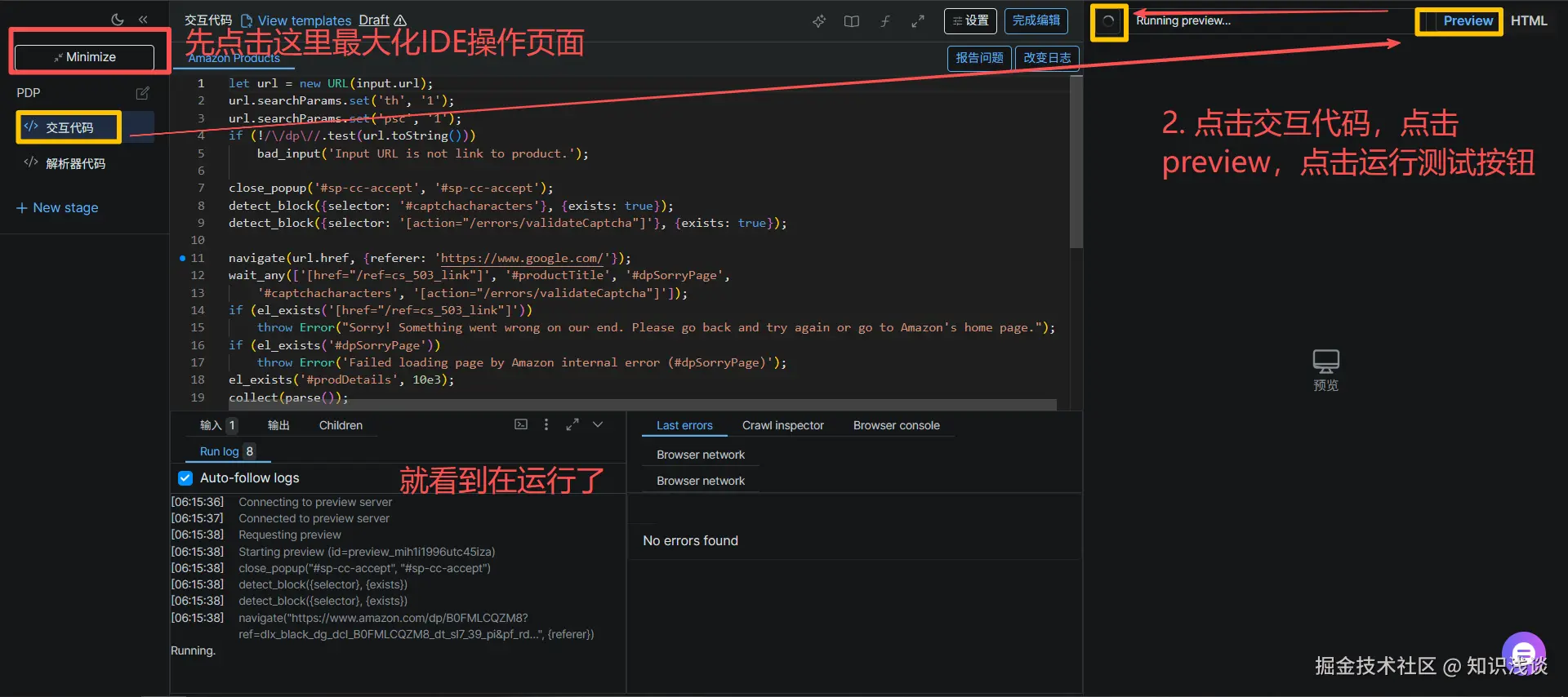 最后会生成完整的结构化数据结果,以清晰的JSON格式呈现。这正是之前手动在 Web Scraper IDE 中我们努力调试想要得到的最终结果,现在由AI自动完成了。
最后会生成完整的结构化数据结果,以清晰的JSON格式呈现。这正是之前手动在 Web Scraper IDE 中我们努力调试想要得到的最终结果,现在由AI自动完成了。 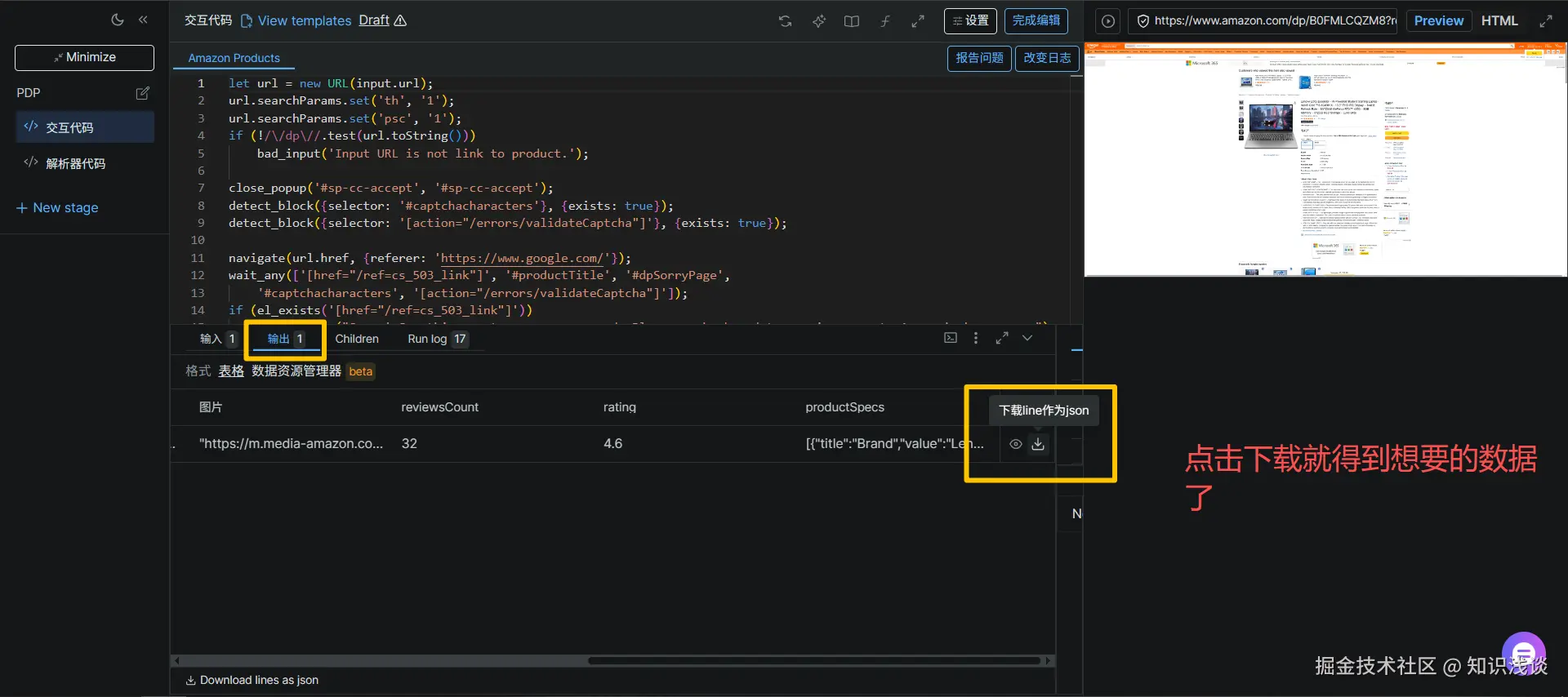
(上图:AI自动生成的结构化数据,格式规整,可直接使用)
第三步:定制与支持,让爬虫完美适配业务
现在,这个爬虫就已经部署在Bright Data的云端平台上了。你可以设置定时按照你想要的时间定时运行 ,采集任何你想要的数据,只需要点击Subscription,然后设置定时任务的规则,最后点击Active scraper,激活定时任务,最后生成的数据都会在输出结果中保存。 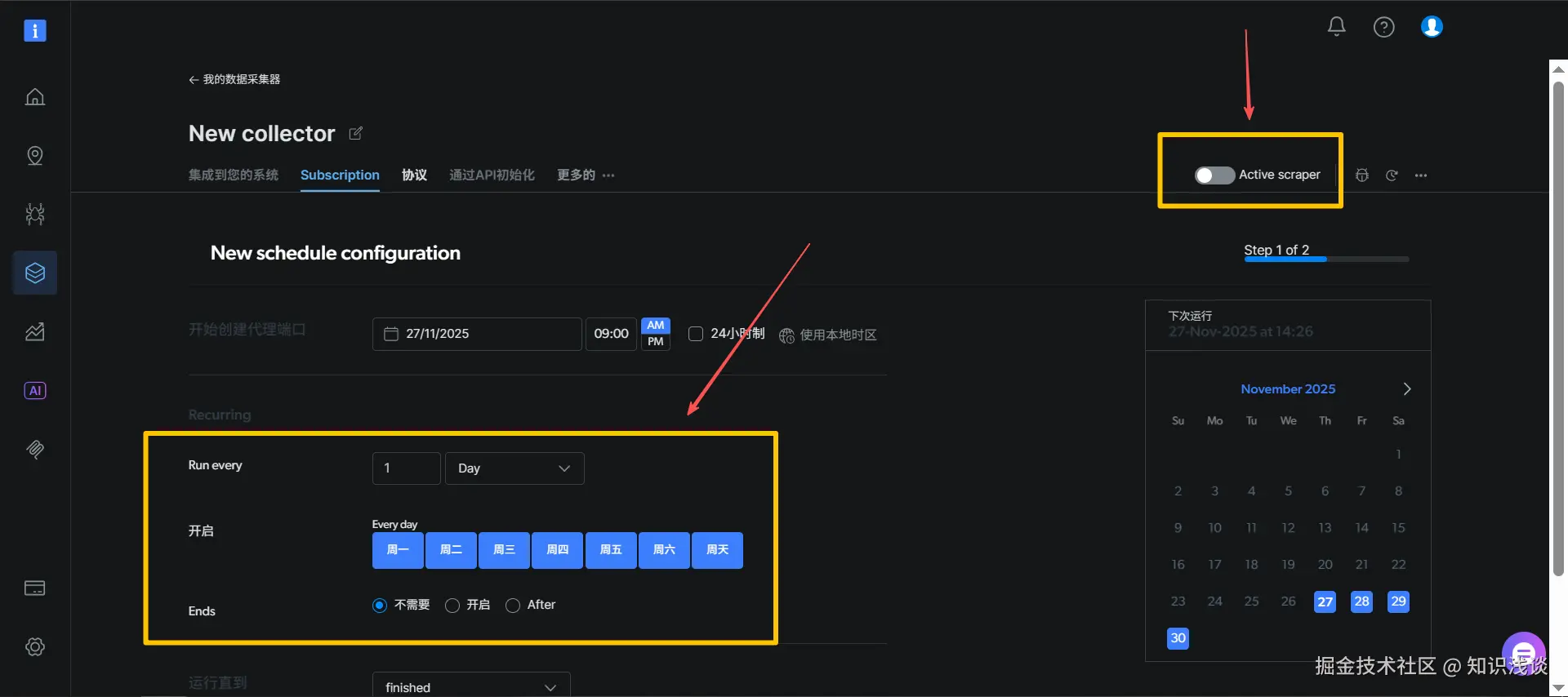
如果遇到复杂情况怎么办? 比如,你需要完成的功能生成的代码出现了问题,或者需要指定的格式化的输出结果。
这时,你可以点击界面上的 "更多" 按钮,既可以联系技术支持,技术团队会及时高效解决用户遇到的问题。另外如果你是一名工程师,也可以在线查看、调试和修改JavaScript代码,实现任何深度的定制。这确保了方案的灵活性没有上限。 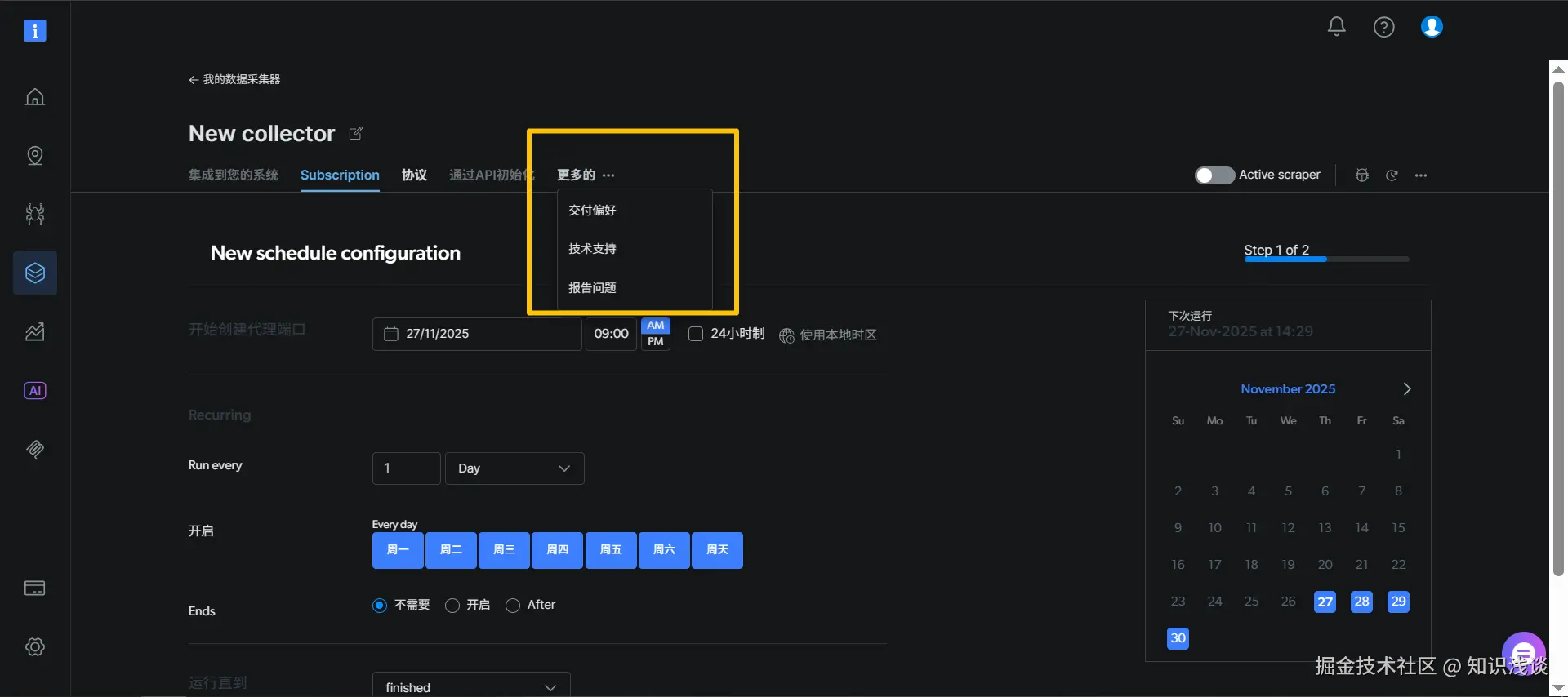 (上图:在IDE中可对AI生成的代码进行精细调整,继承所有强大功能)
(上图:在IDE中可对AI生成的代码进行精细调整,继承所有强大功能)
结语:站在过往经验的肩膀上,迈向智能采集的新纪元
从手动编写Python爬虫应对反爬,到使用专业的Web Scraper IDE进行规模化部署,再到今天用自然语言驱动AI Scraper Studio,我们清晰地看到了一条技术赋能、降低门槛、提升效率的演进之路。
Bright Data AI Scraper Studio 不是对过去的否定,而是对它们价值的升华。 它将我们之前探讨的所有关键技术------稳定的代理IP、强大的IDE、自动化的调度------封装成了一个更智能、更易用的接口。
无论你是苦于爬虫维护的开发者,还是急需数据但缺乏技术资源的业务人员,现在,你都拥有了将"数据想法"瞬间变为"数据资产"的能力。
立即注册 Bright Data AI Scraper Studio 免费试用,体验最新AI驱动爬虫,免费获取$10 美金试用额度。亲身体验从"一句话"到"海量数据"的极速转换,解决我们一直以来关注的数据采集核心难题。