准备工作:
确保你有一个包含所有 .xml 文件的文件夹。
明确你的数据集包含哪些类别(Classes),并按顺序填入代码中。
Python 转换脚本(XML转YOLO格式)
bash
import xml.etree.ElementTree as ET
import glob
import os
# ================= 配置区域 =================
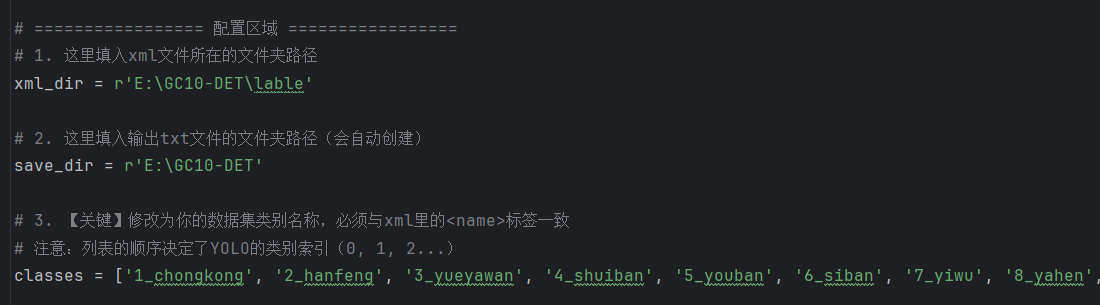
# 1. 这里填入xml文件所在的文件夹路径
xml_dir = './xml_data/'
# 2. 这里填入输出txt文件的文件夹路径(会自动创建)
save_dir = './yolo_txt_data/'
# 3. 【关键】修改为你的数据集类别名称,必须与xml里的<name>标签一致
# 注意:列表的顺序决定了YOLO的类别索引(0, 1, 2...)
classes = ['cat', 'dog', 'person']
# ===========================================
def convert(size, box):
"""
将 bbox (xmin, ymin, xmax, ymax) 转换为 yolo (x, y, w, h)
size: (width, height) 图像的宽和高
box: (xmin, xmax, ymin, ymax)
"""
dw = 1.0 / size[0]
dh = 1.0 / size[1]
# 计算中心点和宽高
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
# 归一化
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(xml_file):
in_file = open(xml_file, encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
# 获取图片尺寸
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
# 准备输出文件名
filename = os.path.basename(xml_file)[:-4]
out_file = open(os.path.join(save_dir, filename + '.txt'), 'w', encoding='utf-8')
for obj in root.iter('object'):
difficult = obj.find('difficult')
cls = obj.find('name').text
# 如果xml里标记为difficult且你想忽略,可以取消注释下面这行
# if difficult and int(difficult.text) == 1: continue
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
# 解析 VOC 坐标
b = (float(xmlbox.find('xmin').text),
float(xmlbox.find('xmax').text),
float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
# 转换为 YOLO 格式
bb = convert((w, h), b)
# 写入文件: class_id x_center y_center width height
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
in_file.close()
out_file.close()
if __name__ == '__main__':
# 创建输出文件夹
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 获取所有xml文件列表
xml_files = glob.glob(os.path.join(xml_dir, '*.xml'))
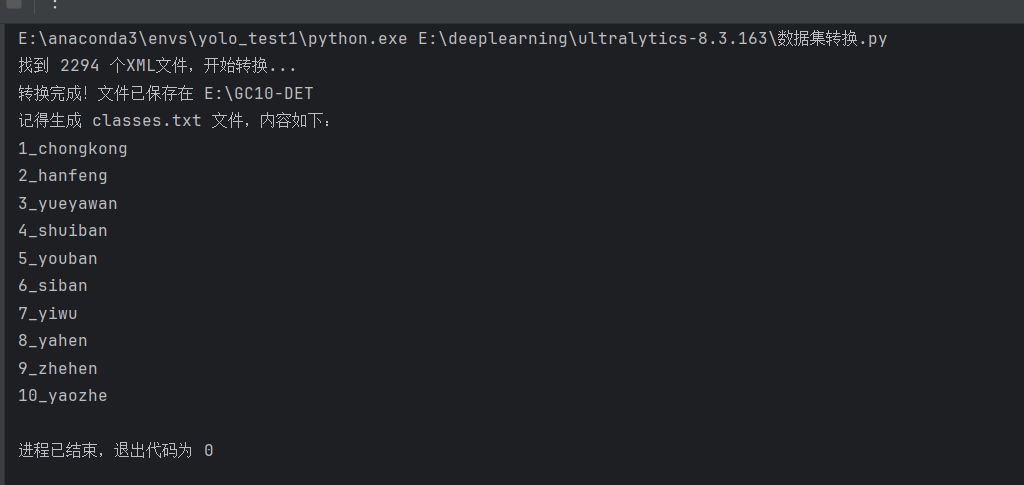
print(f"找到 {len(xml_files)} 个XML文件,开始转换...")
for xml_file in xml_files:
convert_annotation(xml_file)
print(f"转换完成!文件已保存在 {save_dir}")
print("记得生成 classes.txt 文件,内容如下:")
for c in classes:
print(c)修改如下所示
运行结果
可视化转换后的YOLO格式数据(在图片上画框)
这个脚本会自动读取图片和它对应的 YOLO 格式 .txt 文件,逆向计算回绝对坐标,并在图片上画出框和类别名称。如果画出来的框精准地贴合目标,说明你的转换是成功的。
运行后会弹出一个窗口(按任意键切换下一张图片,按q键退出程序 ):
位置准确性 :检查框是否严丝合缝地包围了物体。如果框发生了整体偏移或者大小不对(比如框比物体大很多,或者只有物体的一半),说明之前的转换公式或者图片宽高读取有问题。
类别正确性 :看框上的文字标签(如 cat)是否和图片里的物体对应。如果狗被标成了猫,说明 classes 列表的顺序填错了。
YOLO 格式校验/可视化脚本
bash
import cv2
import os
import random
import glob
# ================= 配置区域 =================
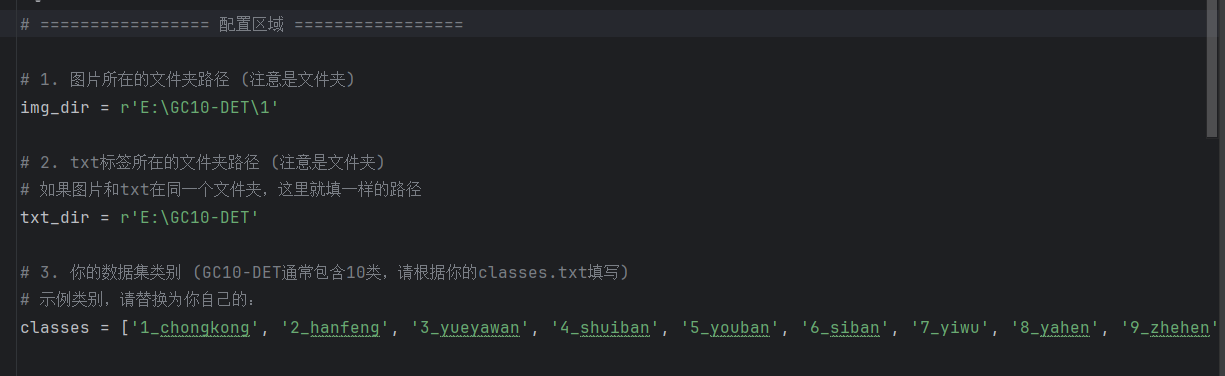
# 1. 图片所在的文件夹路径 (注意是文件夹)
img_dir = r'E:\GC10-DET\images'
# 2. txt标签所在的文件夹路径 (注意是文件夹)
# 如果图片和txt在同一个文件夹,这里就填一样的路径
txt_dir = r'E:\GC10-DET\labels'
# 3. 你的数据集类别 (GC10-DET通常包含10类,请根据你的classes.txt填写)
# 示例类别,请替换为你自己的:
classes = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
# ===========================================
def check_random_sample():
# 支持的图片格式
img_formats = ['*.jpg', '*.jpeg', '*.png', '*.bmp']
images = []
for fmt in img_formats:
images.extend(glob.glob(os.path.join(img_dir, fmt)))
if len(images) == 0:
print(f"错误:在 {img_dir} 下没找到任何图片!")
return
# 随机选一张图片
img_path = random.choice(images)
print(f"正在检查图片: {img_path}")
# 推导对应的txt路径
# 获取文件名(不带后缀),例如 'img_01'
basename = os.path.basename(img_path).rsplit('.', 1)[0]
txt_path = os.path.join(txt_dir, basename + ".txt")
if not os.path.exists(txt_path):
print(f"错误:找不到对应的标签文件: {txt_path}")
print("请检查:\n1. txt文件是否在指定目录下?\n2. txt文件名是否与图片一致?")
return
# === 开始可视化 ===
img = cv2.imread(img_path)
if img is None:
print("图片文件损坏,无法读取")
return
h, w, _ = img.shape
print(f"图片尺寸: {w}x{h}")
with open(txt_path, 'r') as f:
lines = f.readlines()
if not lines:
print("警告:该图片对应的txt文件是空的(即没有标注目标)")
# 生成随机颜色
colors = [[random.randint(0, 255) for _ in range(3)] for _ in range(len(classes) + 10)]
for line in lines:
parts = line.strip().split()
if len(parts) != 5: continue
cls_idx = int(parts[0])
cx, cy, bw, bh = map(float, parts[1:])
# 反归一化坐标
x_center = cx * w
y_center = cy * h
width = bw * w
height = bh * h
x_min = int(x_center - width / 2)
y_min = int(y_center - height / 2)
x_max = int(x_center + width / 2)
y_max = int(y_center + height / 2)
# 获取类别名
label_name = classes[cls_idx] if cls_idx < len(classes) else f"Class {cls_idx}"
color = colors[cls_idx]
# 画框
cv2.rectangle(img, (x_min, y_min), (x_max, y_max), color, 2)
# 画标签
cv2.putText(img, label_name, (x_min, y_min - 5),
cv2.FONT_HERSHEY_SIMPLEX, 0.7, (0, 0, 255), 2)
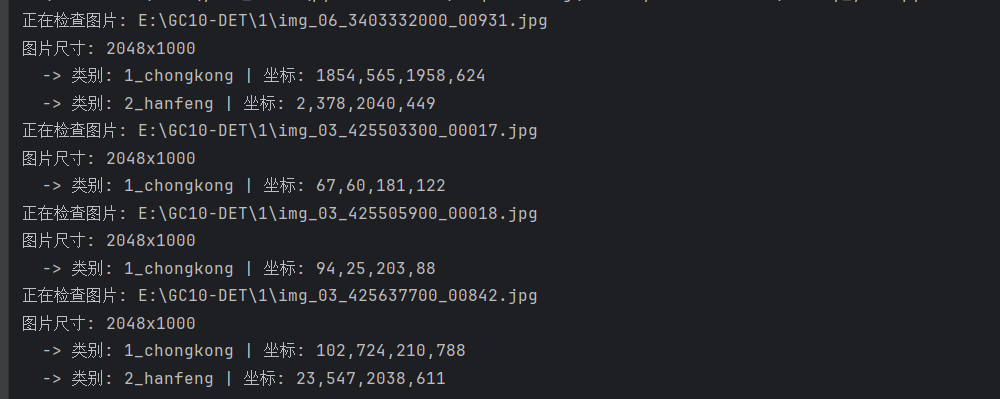
print(f" -> 类别: {label_name} | 坐标: {x_min},{y_min},{x_max},{y_max}")
# 显示 (按任意键查看下一张,按 'q' 退出)
window_name = 'Press Any Key for Next, Q to Quit'
cv2.namedWindow(window_name, cv2.WINDOW_NORMAL) # 允许调整窗口大小
cv2.resizeWindow(window_name, 1024, 768) # 防止图片过大占满屏幕
cv2.imshow(window_name, img)
key = cv2.waitKey(0)
cv2.destroyAllWindows()
# 如果没按q,就递归调用自己再看一张
if key != ord('q'):
check_random_sample()
if __name__ == '__main__':
check_random_sample()我的修改,按照自己的路径去进行修改
运行结果