大模型训练技术总结
前言:大模型训练技术总体上为预训练-》按目标与方法选择合适的微调方式。
预训练(Pre-Training)
- 在大量未标记数据上训练模型,学习通用特征和语言模式(如语法、语义)。
- 不需要人工标注,常用互联网上海量文本进行训练。
微调(Fine-Tuning)
1、概述
- 在预训练之后,使用少量特定任务的标记数据对模型进行进一步训练。
- 目的是让模型适应具体任务(如情感分析、文本分类、问答等),提升在特定场景下的表现。
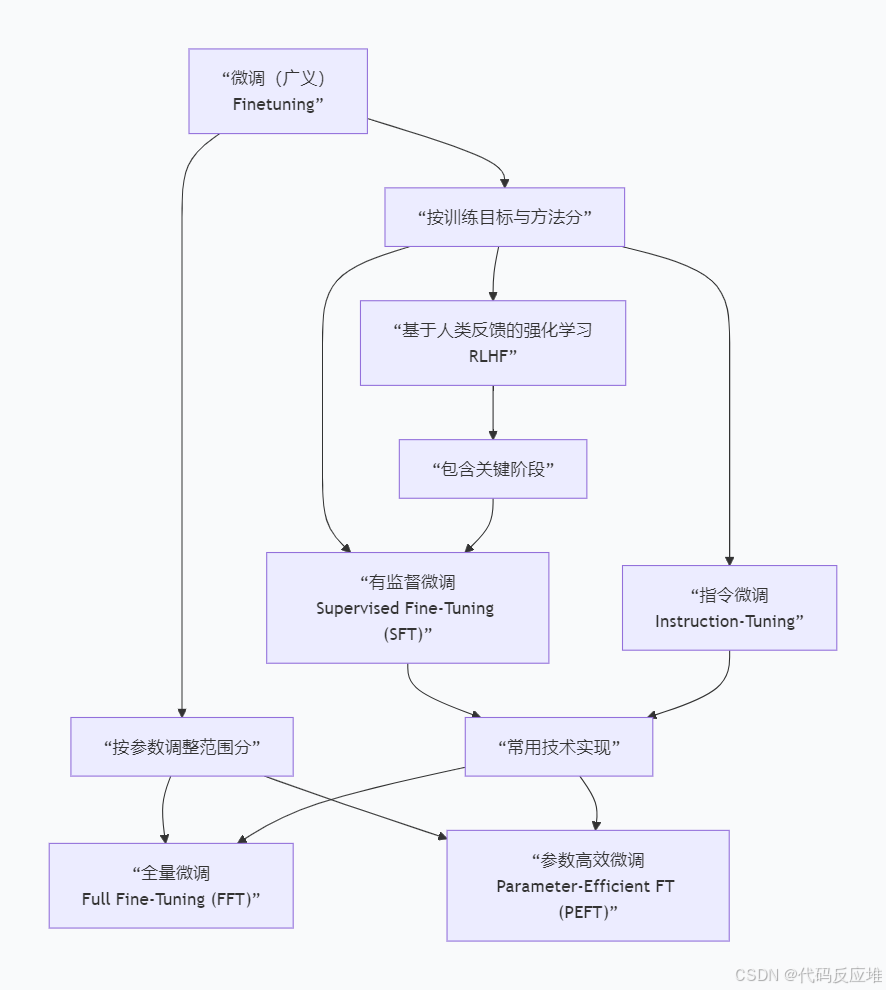
2、按参数调整范围分
2.1、全量微调(Full Fine-Tuning)
- 做法 : 解锁并更新预训练模型的全部参数。模型在特定任务数据上从头到尾重新学习一遍。
- 优点 : 通常能达到该任务上的最佳性能。因为模型的所有部分都可以根据新任务进行最优调整。
- 缺点 :
- 计算成本极高: 对于数十亿甚至万亿参数的大模型,需要巨大的GPU内存和算力。
- 存储成本高: 每个任务都需要保存一份完整的、参数不同的模型副本。
- 过拟合风险: 如果任务数据量小,训练所有参数容易导致模型"忘记"通用知识,只在少量数据上过拟合。
2.2、高效微调(Parameter-Efficient Fine-Tuning)
- 做法 : 冻结预训练模型绝大部分的原始参数(保持其知识不变) ,只新增或选择性地修改极小一部分参数来进行任务适配。
- 目的: 用极低的训练成本获得接近完全微调的性能。
- 常见技术 :
- Adapter(适配器): 在模型层之间插入小型可训练模块,只训练这些模块。
- Prompt Tuning(提示调优): 不修改模型本身,只优化输入时添加的一小段可学习"提示词"的嵌入向量。
- LoRA(低秩适应): 认为模型在适配时的参数变化是低秩的,因此通过训练两个小的低秩矩阵来"模拟"这个变化,而无需改动原始的大权重矩阵。
3、按目标与方法分
3.0 说明
按目标与方法分有监督微调、基于人类反馈的强化学习、指令微调,常用技术实现即上文的全量微调和高效微调。
3.1 监督微调(SFT)
Supervised Fine-Tuning利用"标准答案"进行训练。使用高质量的"输入-输出"配对数据(即明确的指令和期望的回答),以传统的监督学习方式微调预训练模型。
- 训练目标: 最小化模型输出与"标准答案"之间的差异(如交叉熵损失)。
- 适用场景 : 输出结果相对明确、有标准格式 的任务,如:
- 文本分类(正面/负面)
- 命名实体识别(找出人名、地名)
- 翻译(原文到译文的映射)
- 特点 : 方法直接,能快速教会模型执行特定、已知的任务,为模型提供明确的行为基础。
3.2 基于人类反馈的强化学习 (RLHF)
Reinforcement Learning from Human Feedback 利用"人类偏好"进行训练 。不再依赖"标准答案",关键阶段采用监督微调后让人类评估员对模型的多个输出进行排序或评分,这些偏好反馈被转化为奖励信号,通过强化学习算法(如PPO算法)来训练模型,使其输出更符合人类价值观。
训练目标: 最大化从人类反馈中学习到的"奖励模型"给出的分数。
适用场景 : 输出开放、主观、难以用单一标准答案衡量的生成式任务,如:
- 创意写作
- 开放域对话
- 总结、风格转换
特点 : 能够教会模型输出在质量、安全性、有用性和无害性上更符合人类复杂偏好的内容,使其行为"对齐"人类价值观。
3.3 指令微调(Instruction-Tuning)
Instruction-Tuning是提升模型理解和遵循自然语言指令 的通用能力,使其成为一个能处理多种未知任务 的"通用助手",使用海量、多样化任务 的"指令-输出"配对数据进行训练。模型学习的是根据指令泛化,而非记住某个具体任务,得到能响应"总结以下文章"、"将这句话翻译成法语"等各类指令的模型。
简单比喻:Fine-Tuning 是把一个大学生培养成某个领域的博士(专精);Instruction-Tuning 是培养他的通识能力和理解导师各种要求的能力(通用)。