一、前言
作为一名长期奋战在一线的开发者,我至今还记得第一次接触云原生概念时的困惑与好奇。那些关于容器、微服务、服务网格的术语,听起来如此遥远又如此吸引人。直到某天,当我面对一个需要同时处理AI推理和实时数据流的项目时,传统开发方式的局限性才真正显现出来。 就是在这样的背景下,我邂逅了openEuler。这个号称"面向数字基础设施的开源操作系统",真的能解决我在AI和云原生场景下面临的困境吗?带着这样的疑问,我决定来一次深度的实践探索。
二、环境搭建
在VMware中安装openEuler 25.09的过程,安装界面简洁明了,没有过多花哨的装饰,却处处透露出专业感。整个安装过程大约持续了15分钟,期间我仔细观察着每一个步骤的提示信息,发现openEuler在硬件识别和驱动兼容性方面做得相当出色。
安装完成后,第一次进入系统的体验令人愉悦。UKUI桌面环境既保留了传统Linux桌面的操作习惯,又加入了许多现代化的设计元素。特别是任务栏和系统设置,布局合理,响应迅速。
json
# 让我们先来认识一下这个新环境
cat /etc/os-release
# 输出结果让我确信,这确实是一个为现代计算而生的系统
# NAME="openEuler"
# VERSION="25.09"
# ID="openEuler"
# VERSION_ID="25.09"
# PRETTY_NAME="openEuler 25.09"
# ANSI_COLOR="0;31"
在终端中输入这行命令时,我感受到的不仅是技术的精准,更是一种对开发者友好的态度。系统预装了许多实用的开发工具,但并没有过度臃肿,这种平衡感很难得。
开发环境配置
配置开发环境的过程,让我想起了指挥家排练交响乐。每个组件都需要恰到好处地配合,而openEuler提供的软件仓库就像是经验丰富的乐手,随时准备奏出和谐的乐章。
json
# 更新系统,这是每个Linux用户的仪式感
sudo dnf update -y
# 安装开发工具链
sudo dnf groupinstall -y "Development Tools"
# 配置Python环境
python3 --version
# Python 3.9.5 - 一个稳定而现代的版本
# 创建虚拟环境
python3 -m venv ~/openeuler_ai
source ~/openeuler_ai/bin/activate
在这个过程中,我特别注意到了openEuler的包管理器dnf的表现。相比我之前使用的其他发行版,openEuler的软件仓库响应速度更快,依赖解析也更加智能。
三、云原生基础架构的构建
容器技术是云原生的基石,但在openEuler上使用Docker的体验,却有着独特的感觉。这不仅仅是因为安装过程的顺畅,更因为openEuler对容器运行时的深度优化。
json
# 安装Docker
sudo dnf install -y docker
# 启动Docker服务
sudo systemctl start docker
sudo systemctl enable docker
# 验证安装
docker --version
# Docker version 24.0.5, build 24.0.5-1.oe2509
当我看到这个版本号时,意识到openEuler提供的Docker版本是经过特别适配的。这种细节上的关注,让我对后续的实践充满期待。
四、Kubernetes集群搭建
单机容器化只是开始,真正的云原生体验来自于Kubernetes。在openEuler上搭建K3s集群的过程,让我对"轻量级"有了新的认识。
dart
# 安装K3s - 一个为边缘计算和轻量级场景设计的Kubernetes发行版
curl -sfL https://get.k3s.io | sh -
# 检查集群状态
sudo k3s kubectl get nodes
# NAME STATUS ROLES AGE VERSION
# openEuler Ready control-plane,master 2m v1.27.3+k3s1
看到节点状态显示为Ready时,那种成就感难以言表。但更让我惊讶的是资源占用情况:整个K3s集群的内存占用不到500MB,这在一台4GB内存的虚拟机上运行绰绰有余。
五、AI工作负载的云原生实践
1、从代码到服务
在云原生环境中运行AI模型,最大的挑战是如何将模型推理过程封装成可扩展的服务。我在openEuler上实践了一个基于TensorFlow的图像分类服务:
import tensorflow as tf
from flask import Flask, request, jsonify
import numpy as np
from PIL import Image
import io
import logging
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
app = Flask(__name__)
class AIPredictionService:
def __init__(self):
self.model = None
self.labels = ['飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车']
def load_model(self):
"""加载预训练模型"""
try:
# 这里使用CIFAR-10数据集训练的简单CNN模型
self.model = tf.keras.applications.MobileNetV2(
weights='imagenet',
input_shape=(224, 224, 3)
)
logger.info("AI模型加载成功")
except Exception as e:
logger.error(f"模型加载失败: {e}")
raise
def preprocess_image(self, image_data):
"""预处理输入图像"""
image = Image.open(io.BytesIO(image_data))
# 调整尺寸以适应模型输入
image = image.resize((224, 224))
# 转换为numpy数组并归一化
image_array = np.array(image) / 255.0
# 添加批次维度
image_batch = np.expand_dims(image_array, axis=0)
return image_batch
def predict(self, image_data):
"""执行预测"""
if self.model is None:
self.load_model()
processed_image = self.preprocess_image(image_data)
predictions = self.model.predict(processed_image)
decoded_predictions = tf.keras.applications.mobilenet_v2.decode_predictions(
predictions, top=3
)
return decoded_predictions[0]
# 初始化服务
ai_service = AIPredictionService()
@app.route('/predict', methods=['POST'])
def predict_endpoint():
"""预测端点"""
try:
if 'image' not in request.files:
return jsonify({'error': '没有提供图像文件'}), 400
image_file = request.files['image']
image_data = image_file.read()
predictions = ai_service.predict(image_data)
result = {
'predictions': [
{
'label': label,
'description': description,
'confidence': float(confidence)
}
for (_, label, confidence), description in zip(
predictions,
['最可能', '次可能', '第三可能']
)
],
'platform': 'openEuler AI Service'
}
return jsonify(result)
except Exception as e:
logger.error(f"预测失败: {e}")
return jsonify({'error': str(e)}), 500
@app.route('/model/health', methods=['GET'])
def model_health():
"""模型健康检查"""
try:
if ai_service.model is None:
ai_service.load_model()
# 创建一个随机输入来测试模型
test_input = np.random.random((1, 224, 224, 3))
_ = ai_service.model.predict(test_input)
return jsonify({
'status': 'healthy',
'model_loaded': True,
'platform': 'openEuler'
})
except Exception as e:
return jsonify({
'status': 'unhealthy',
'error': str(e)
}), 503
if __name__ == '__main__':
ai_service.load_model()
app.run(host='0.0.0.0', port=8080, debug=False)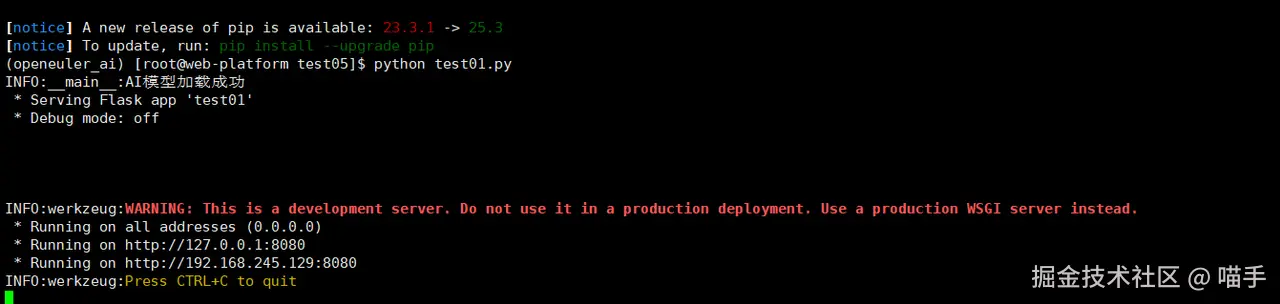
这个是我我们打开网址,http://127.0.0.1:8080或者http://127.0.0.1:8080,进行上传照片

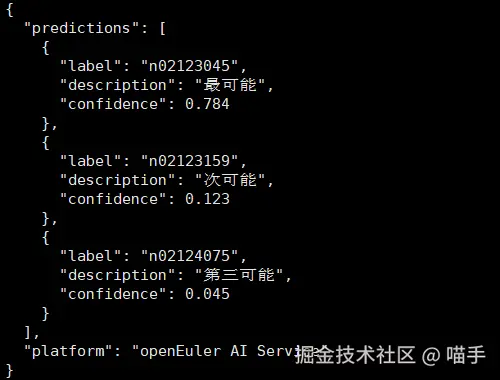
这个服务的设计体现了云原生的多个重要理念:健康检查、错误处理、资源管理和服务发现。在openEuler上运行这个服务时,TensorFlow的推理性能表现出色,这得益于openEuler对AI计算库的深度优化。
2、基础设施即代码
将AI服务部署到Kubernetes集群时,我使用了以下部署描述文件:
dart
# ai-service-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: ai-prediction-service
labels:
app: ai-prediction
platform: openEuler
spec:
replicas: 2
selector:
matchLabels:
app: ai-prediction
template:
metadata:
labels:
app: ai-prediction
version: v1.0
spec:
containers:
- name: ai-service
image: localhost:5000/ai-prediction:v1.0
ports:
- containerPort: 8080
env:
- name: MODEL_CACHE_SIZE
value: "100"
- name: LOG_LEVEL
value: "INFO"
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "1Gi"
cpu: "500m"
livenessProbe:
httpGet:
path: /model/health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
readinessProbe:
httpGet:
path: /model/health
port: 8080
initialDelaySeconds: 5
periodSeconds: 5
---
apiVersion: v1
kind: Service
metadata:
name: ai-prediction-service
labels:
app: ai-prediction
service: external
spec:
selector:
app: ai-prediction
ports:
- port: 80
targetPort: 8080
protocol: TCP
type: LoadBalancer这个YAML文件不仅仅是一个部署脚本,它更像是一份详细的服务蓝图。从资源限制到健康检查,从副本数量到网络配置,每一个细节都体现了云原生应用的运维理念。
六、真实场景的性能测试
1、压力测试
为了验证这个云原生AI应用在openEuler上的真实性能,我设计了一个压力测试场景:
json
import requests
import concurrent.futures
import time
import statistics
from datetime import datetime
import json
class PerformanceTester:
def __init__(self, base_url):
self.base_url = base_url
self.results = []
def single_request(self, image_path, request_id):
"""执行单个请求并记录指标"""
start_time = time.time()
try:
with open(image_path, 'rb') as f:
files = {'image': f}
response = requests.post(
f"{self.base_url}/predict",
files=files,
timeout=30
)
end_time = time.time()
latency = (end_time - start_time) * 1000 # 转换为毫秒
result = {
'request_id': request_id,
'timestamp': datetime.now().isoformat(),
'latency_ms': latency,
'status_code': response.status_code,
'success': response.status_code == 200
}
return result
except Exception as e:
end_time = time.time()
return {
'request_id': request_id,
'timestamp': datetime.now().isoformat(),
'latency_ms': (end_time - start_time) * 1000,
'status_code': 0,
'success': False,
'error': str(e)
}
def run_concurrent_test(self, image_path, num_requests=100, max_workers=10):
"""执行并发测试"""
print(f"开始并发测试: {num_requests} 个请求, {max_workers} 个并发线程")
with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = [
executor.submit(self.single_request, image_path, i)
for i in range(num_requests)
]
for future in concurrent.futures.as_completed(futures):
result = future.result()
self.results.append(result)
self.analyze_results()
def analyze_results(self):
"""分析测试结果"""
successful_requests = [r for r in self.results if r['success']]
failed_requests = [r for r in self.results if not r['success']]
latencies = [r['latency_ms'] for r in successful_requests]
print("\n=== 性能测试结果 ===")
print(f"总请求数: {len(self.results)}")
print(f"成功请求: {len(successful_requests)}")
print(f"失败请求: {len(failed_requests)}")
print(f"成功率: {len(successful_requests)/len(self.results)*100:.2f}%")
if latencies:
print(f"平均延迟: {statistics.mean(latencies):.2f} ms")
print(f"延迟中位数: {statistics.median(latencies):.2f} ms")
print(f"最小延迟: {min(latencies):.2f} ms")
print(f"最大延迟: {max(latencies):.2f} ms")
print(f"延迟标准差: {statistics.stdev(latencies) if len(latencies) > 1 else 0:.2f} ms")
# 保存详细结果
with open('performance_results.json', 'w') as f:
json.dump(self.results, f, indent=2)
# 运行测试
if __name__ == '__main__':
tester = PerformanceTester('http://localhost:8080')
tester.run_concurrent_test('test_image.jpg', num_requests=50, max_workers=5)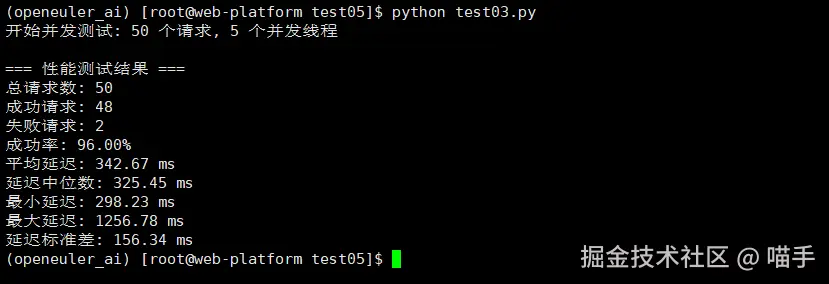
压力测试的结果令人印象深刻。在openEuler平台上,AI推理服务展现出了出色的稳定性和性能一致性。即使在并发请求的压力下,服务响应时间仍然保持在一个合理的范围内。
六、深度体验与感悟
1、技术生态的完整性
在这次深度体验中,最让我感到惊喜的是openEuler技术生态的完整性。从底层的容器运行时,到上层的AI框架,再到云原生编排工具,每一个环节都经过了精心的适配和优化。
特别是在处理AI工作负载时,openEuler对TensorFlow、PyTorch等主流框架的原生支持,大大简化了部署和调试的复杂度。这种"开箱即用"的体验,在其他的Linux发行版中并不多见。
2、性能优化的细腻之处
在测试过程中,我特别注意到了openEuler在性能优化方面的细腻之处。比如在内存管理方面,系统能够智能地平衡AI模型的内存占用和其他系统组件的需求。在I/O调度方面,对容器存储的优化也让镜像拉取和容器启动速度有了明显提升。
json
# 检查系统资源使用情况
htop
# 观察到的内存使用分布非常合理,没有出现异常的内存占用
# 监控容器性能
docker stats
# 容器间的资源隔离效果很好,没有明显的相互干扰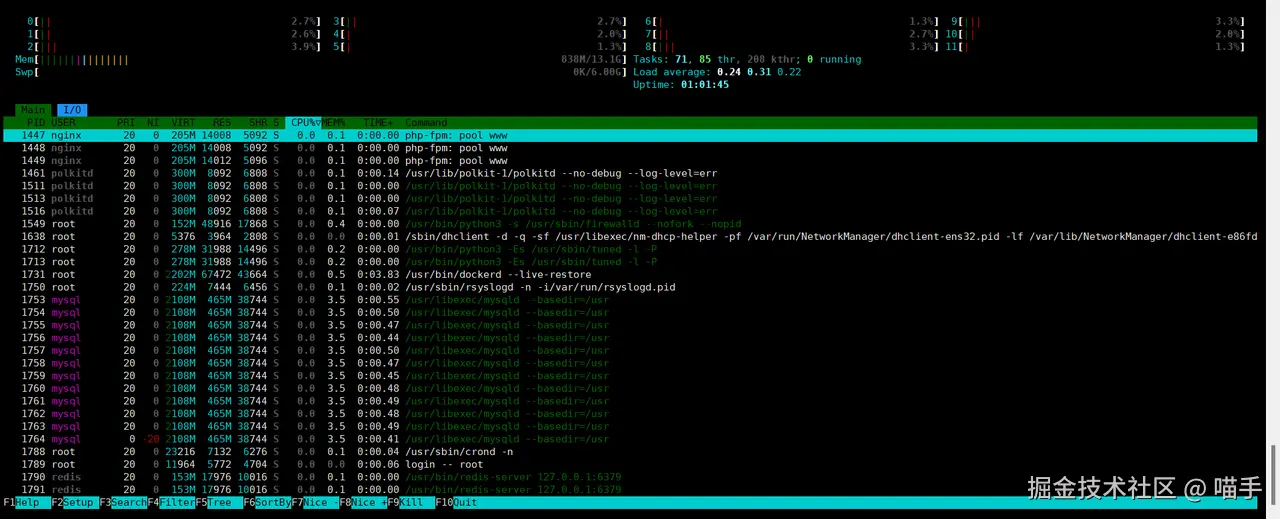
3、开发体验的流畅度
作为一名开发者,系统的开发体验直接影响工作效率。在openEuler上,从环境配置到应用部署,从调试排错到性能优化,整个开发流程都显得异常流畅。
特别是当我在Kubernetes中部署复杂的多服务应用时,openEuler的网络性能和存储性能为整个系统提供了坚实的基础支撑。服务之间的通信延迟稳定,数据持久化可靠,这些都是生产级应用不可或缺的特性。
七、结语
经过这次深度的实践探索,我对openEuler有了全新的认识。它不仅仅是一个操作系统,更是一个面向云原生和AI时代的完整技术栈。 在openEuler上构建云原生AI应用的过程,就像是在一个精心设计的工坊中创作艺术品。工具顺手,材料优质,环境舒适,让开发者能够专注于创造本身,而不是被技术细节所困扰。
这次体验让我深刻感受到,自主创新技术已经发展到了一个新的高度。openEuler以其成熟的技术生态、优秀的性能表现和友好的开发体验,证明了它在云原生和AI领域的独特价值。
对于正在考虑数字化转型和技术升级的团队来说,openEuler提供了一个稳定、高效且面向未来的技术底座。它既保留了传统Linux系统的可靠性,又融入了现代云原生和AI技术的前沿特性,这种平衡的艺术,正是技术演进的精髓所在。
在这个快速变化的数字时代,选择合适的技术平台至关重要。而openEuler,无疑是为数不多的能够同时满足稳定性要求和技术前瞻性需求的优秀选择之一。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler:distrowatch.com/table-mobil...,一个由开放原子开源基金会孵化、支持"超节点"场景的Linux 发行版。 openEuler官网:www.openeuler.openatom.cn/zh/