
AI工作流的概念及其在Java生态中的实现框架LangGraph4j
什么是工作流?
AI工作流是将多个AI任务、数据处理步骤和业务逻辑按照特定顺序组织起来的自动化流程。有了工作流就不需要让AI来判断是否该执行某个规定的任务。
在Java生态中,AI工作流类似于传统的工作流引擎,但专门为AI任务优化。是将AI能力工程化、工业化的重要手段。通过工作流编排,可以实现:
- 复杂AI任务的自动化执行
- 多模型协同工作
- 与现有业务系统的无缝集成
- 完整的监控和治理
为什么需要工作流?
在AI应用开发中,我们经常需要串联多个步骤,例如:获取用户输入、调用多个工具、条件判断、循环重试等。传统的方式是将这些步骤写在业务代码中,导致代码冗长、难以维护和扩展。工作流引擎通过将流程可视化、模块化,使得复杂的业务流程变得清晰、易于编排和调试。
传统模式:业务流程分散在各个Service方法中,逻辑耦合
工作流模式 :将业务流程抽象为有向图,节点代表操作单元,边控制流程走向
前言
目前比较流行的几种AI工作流平台,像Dify、Coze、阿里云百炼,它们只要通过拖拉拽的方式就能快速搭建工作流,上手简单、能够快速看到效果。**这些不需要写什么代码的工作流平台比较适合于从头开始的新项目,各个节点之间相对没那么复杂的场景。**而当涉及到一些复杂的业务时,这些平台就无法满足我们的需求,尤其是需要与现有逻辑业务深度集成时。
因此需要用到一款专门为java生态设计的工作流框架LangGraph4j,它不仅与SpringBoot深度集成,而且也与开发AI应用的框架LangChain4j兼容性很好。能够无缝融入现有的业务逻辑技术,可以直接复用项目已经开发的一些AI工具、逻辑、配置呀等,不需要因为引入工作流而从头开始重新开发。LangGraph4j还提供了各种特性,如循环执行、并发处理等让我们能够构建出智能化工作流程。LangGraph4j实现工作流需要通过编写java代码来实现,相比于像Dify这些工作流平台,虽然会有一定的学习成本,但是它的扩展性和可维护性好,哪怕业务逻辑变的越来越复杂,要新加入很多复杂业务,也能够很好的进行迭代。因此LangGraph4j适合于满足复杂的业务需求,也能很好支持已有的项目进行扩展。
学习LangGraph4j步骤建议:
- 先掌握核心概念(图、节点、状态、边)
- 跑通简单Demo,理解工作流执行过程
- 实现一个完整节点,理解状态流转
- 学习高级特性(并发、条件边、流式输出)
- 根据业务需求选择合适特性
本文下面会介绍LangGraph4j进行入门,学习并掌握实践LangGraph4j的高级特性。
LangGraph4j入门
1. 图(Graph)
LangGraph4j 使用有向图来定义工作流,图由节点(Nodes)和边(Edges)组成。与传统的DAG(有向无环图)不同,LangGraph4j 的图支持循环,这意味着可以很容易地实现重试、循环等逻辑。
2. 节点(Nodes)
节点是工作流中的执行单元,每个节点可以执行一段业务逻辑。节点可以是同步的,也可以是异步的。节点通过实现 NodeAction 或 AsyncNodeAction 接口来定义。
节点设计的三种开发模式
模式一:同步简单节点
// 适合快速操作,无IO阻塞
static NodeAction<MessagesState<String>> createSimpleNode() {
return node(state -> {
WorkflowContext ctx = WorkflowContext.getContext(state);
ctx.setCurrentStep("simple_node");
return WorkflowContext.saveContext(ctx);
});
}模式二:异步复杂节点(推荐)
// 适合网络请求、AI调用等IO操作
public static AsyncNodeAction<MessagesState<String>> create() {
return node_async(state -> {
WorkflowContext context = WorkflowContext.getContext(state);
// 关键:异常处理策略
try {
// 业务逻辑
ImageCollectionService service = SpringContextUtil.getBean(ImageCollectionService.class);
String imageListStr = service.collectImages(context.getOriginalPrompt());
// 更新状态
context.setImageListStr(imageListStr);
context.setCurrentStep("图片收集");
} catch (Exception e) {
// 错误处理:记录但不中断流程
log.error("图片收集失败,但继续执行: {}", e.getMessage());
context.setErrorMessage("图片收集失败: " + e.getMessage());
}
return WorkflowContext.saveContext(context);
});
}模式三:带参数配置的节点
// 工厂方法模式,支持配置
public class ImageCollectorNode {
private final int maxImages;
private final boolean enableConcurrent;
private ImageCollectorNode(int maxImages, boolean enableConcurrent) {
this.maxImages = maxImages;
this.enableConcurrent = enableConcurrent;
}
public static AsyncNodeAction<MessagesState<String>> create(
int maxImages,
boolean enableConcurrent) {
ImageCollectorNode instance = new ImageCollectorNode(maxImages, enableConcurrent);
return instance.createNode();
}
private AsyncNodeAction<MessagesState<String>> createNode() {
return node_async(state -> {
WorkflowContext context = WorkflowContext.getContext(state);
if (enableConcurrent) {
// 并发收集逻辑
} else {
// 串行收集逻辑
}
return WorkflowContext.saveContext(context);
});
}
}节点开发的核心原则
- 单一职责:一个节点只做一件事
- 幂等性:相同输入应产生相同输出(便于重试)
- 状态透明:节点只修改自己负责的状态字段
- 异常可恢复:错误应该记录在状态中,而不是抛出异常中断流程
3. 状态(State)
状态是工作流中节点之间共享的数据。LangGraph4j 提供了两种状态管理方式:
- 内置的AgentState:本质上是一个Map,通过Schema定义结构,使用Reducer来合并更新。
- 自定义上下文类:更推荐的方式,自己定义一个类来管理状态,然后将这个类的实例作为状态的一部分。
自定义状态类示例:
@Data
public class WorkflowContext {
private String currentStep;
private String originalPrompt;
private List<ImageResource> imageList;
// ... 其他字段
// 提供从状态中获取和保存的方法
public static WorkflowContext getContext(MessagesState<String> state) {
return (WorkflowContext) state.data().get("workflowContext");
}
public static Map<String, Object> saveContext(WorkflowContext context) {
return Map.of("workflowContext", context);
}
}4. 边(Edges)
边定义了节点之间的流转逻辑。分为两种:
- **普通边:**无条件跳转到下一个节点。
- **条件边:**根据当前状态动态决定下一个节点。
普通边示例:
graph.addEdge("nodeA", "nodeB"); // A完成后一定执行B条件边示例:
// 核心:条件边函数
private String routeAfterQualityCheck(MessagesState<String> state) {
WorkflowContext context = WorkflowContext.getContext(state);
QualityResult qualityResult = context.getQualityResult();
// 决策逻辑
if (qualityResult == null) {
return "error"; // 质检未执行
} else if (!qualityResult.getIsValid()) {
// 关键:实现循环重试机制
int retryCount = context.getRetryCount() != null ? context.getRetryCount() : 0;
if (retryCount < 3) {
context.setRetryCount(retryCount + 1);
return "retry"; // 重新生成
} else {
return "fail"; // 超过重试次数
}
} else {
// 质检通过,根据类型决定下一步
CodeGenTypeEnum type = context.getGenerationType();
return type == CodeGenTypeEnum.VUE_PROJECT ? "build" : "skip_build";
}
}
// 在图中使用条件边
graph.addConditionalEdges(
"code_quality_check", // 源节点
edge_async(this::routeAfterQualityCheck), // 路由函数
Map.of( // 目标节点映射
"retry", "code_generator", // 重试:回到代码生成
"build", "project_builder", // 构建:进入构建节点
"skip_build", END, // 跳过构建:直接结束
"error", "error_handler", // 错误:进入错误处理
"fail", "fail_handler" // 失败:进入失败处理
)
);边的四种设计:
1、线性流程(最简单)
start → A → B → C → end
2、条件分支(if-else)

3、循环重试(while)
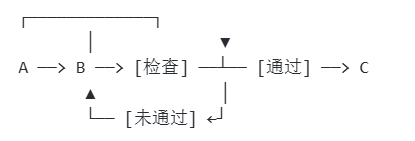
4、并行聚合(fork-join)
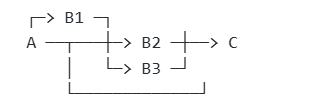
工作流开发步骤
1、定义工作流结构
先梳理业务流程,确定需要哪些节点,节点之间的顺序和条件分支。可以画一个流程图。
2、定义状态
根据业务流程,确定需要在节点之间共享哪些数据,设计状态类(WorkflowContext)。
3、开发节点
按照节点开发模式,逐个实现节点。可以先使用假数据模拟,确保流程跑通。
4、整合服务
在节点中注入需要的Spring Bean,实现真实的业务逻辑。
5、测试和调试
通过单元测试和工作流可视化,验证工作流的正确性。
LangGraph4j高级特性
Streaming 异步和流式处理。首先,通过 CompletableFuture,LangGraph4j允许非阻塞的异步操作。也就是说,当某个节点在等待LLM响应时,整个应用不会被阻塞,可以继续处理其他任务。LangGraph4j支持通过 Java 异步生成器来处理来自LLM和其他源的流式响应,可以实现SSE流式输出,提升用户体验。此外,流式处理不仅支持主流的输出,还能处理子流,并且在所有流输出完成后获取到最终结果。此外LangGraph4j还提供了并发、子图、断点、可视化等高级特性。
子图
如果一个工作流图特别复杂,或者其中的一些流程需要复用,就可以考虑子图功能。相当于把一个工作流拆分成
多个子模块,而且多个子图可以同时并发执行。子图功能不仅支持可视化,还支持流式处理。不过在操作节点方式下,需要自己处理流的传递。
有3种不同的使用方式,适合不同的场景:
1、直接添加:这种方式会将子图完全合并到父图中,无缝集成。在这种模式下,父图和子图共享所有状态,子图就像是父图的一个扩展部分。
2、编译添加:这种方式让子图和父图保持一定的独立性,只共享部分状态。适合需要一定独立性但又需要与主流程交互的场景。
3、操作节点:可以自己定义子图和父图之间的交互逻辑,包括状态的转换、数据的传递等,最灵活。适合需要复杂交互逻辑的场景。
断点
断点就是有时我们需要在某个关键节点暂停执行,等待人工判断确认。这个特性在实现"人在环路"(human-in-the-loop)的 AI系统时特别有用。比如在代码生成系统中,可能希望在生成代码后暂停执行,让人工审核代码质量,确认无误后再继续后续的构建和部署流程。相信大家都用过AI写代码,如Cursor的有些操作就会停下来,让用户来决定是否继续执行,这就是断点的使用,LangGraph4j的断点功能正是为这种场景设计的。
注意:使用断点功能时必须配合检查点器使用。因为图需要能够保存当前状态并在稍后恢复执行,要恢复执行只需要调用 GraphInput.resume()就可以了。
并发
为什么需要并发?
如果图片收集的4个工具(内容图片、插画、架构图、Logo)相互独立,要是使用串行执行,会非常浪费时间,而用并发就能大大提高执行效率,减少执行耗时。
1、并发处理的三种方案,推荐CompletableFuture(简单场景)或 LangGraph4j并发(工作流原生):
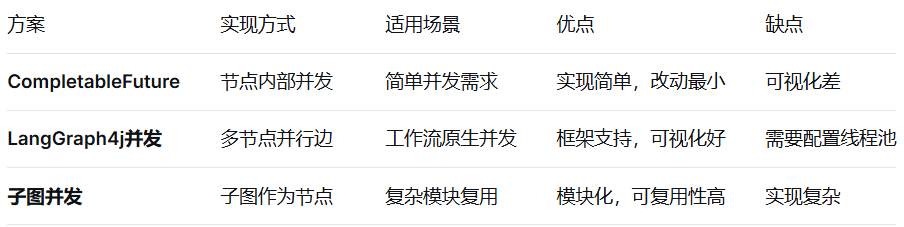
节点内部并发示例代码:
public static AsyncNodeAction<MessagesState<String>> create() {
return node_async(state -> {
WorkflowContext context = WorkflowContext.getContext(state);
// 1. 获取收集计划
ImageCollectionPlan plan = getPlan(context.getOriginalPrompt());
// 2. 创建并发任务
List<CompletableFuture<List<ImageResource>>> futures = new ArrayList<>();
// 内容图片
futures.add(CompletableFuture.supplyAsync(() ->
imageSearchTool.searchContentImages(plan.getContentQuery())
));
// 插画图片
futures.add(CompletableFuture.supplyAsync(() ->
illustrationTool.searchIllustrations(plan.getIllustrationQuery())
));
// 3. 等待所有完成
CompletableFuture.allOf(futures.toArray(new CompletableFuture[0])).join();
// 4. 聚合结果
List<ImageResource> allImages = futures.stream()
.map(CompletableFuture::join)
.flatMap(List::stream)
.collect(Collectors.toList());
context.setImageList(allImages);
return WorkflowContext.saveContext(context);
});
}LangGraph4j原生并发示例代码:
// 关键:配置线程池
ExecutorService pool = Executors.newFixedThreadPool(
4, // 并发数 = 图片类型数
new ThreadFactoryBuilder()
.setNamePrefix("image-collect-")
.setDaemon(true)
.build()
);
// 关键:运行时配置
RunnableConfig config = RunnableConfig.builder()
.addParallelNodeExecutor("image_plan", pool) // 从plan节点开始并发
.build();
// 图结构:多个节点从同一节点出发
graph.addEdge("image_plan", "content_collector");
graph.addEdge("image_plan", "illustration_collector");
graph.addEdge("image_plan", "diagram_collector");
graph.addEdge("image_plan", "logo_collector");
// 所有收集节点汇聚到聚合器
graph.addEdge("content_collector", "image_aggregator");
graph.addEdge("illustration_collector", "image_aggregator");
// ...并发配置的重点:
// 必须配置线程池才能生效
ExecutorService pool = ExecutorBuilder.create()
.setCorePoolSize(10)
.setMaxPoolSize(20)
.build();
RunnableConfig runnableConfig = RunnableConfig.builder()
.addParallelNodeExecutor("image_plan", pool)
.build();并发设计的核心问题:
1、资源竞争:多个线程访问共享状态 → 使用线程安全集合
2、错误处理:一个任务失败不影响其他 → 独立try-catch
3、超时控制:防止某个任务卡死 → 设置超时时间
4、结果顺序:并发结果顺序不确定 → 按类型分类聚合
流式处理
为什么需要流式输出?因为工作流步骤多,如果等AI输出完才一次性返回结果,那用户的体验感是不是很差,不知道的还以为卡住了,因此用户需要实时反馈,这时就可以使用流式输出。关键就是将工作流执行步骤作为事件流输出。
流式输出的实现方案
-
Flux方案(推荐):兼容性好,易整合
// 工作流执行方法(流式版)
public FluxexecuteWorkflowStream(String prompt) {
return Flux.create(sink -> {
Thread.startVirtualThread(() -> {
try {
// 1. 开始事件
sink.next(WorkflowEvent.start(prompt));// 2. 执行工作流,监听每一步 CompiledGraph<MessagesState<String>> workflow = createWorkflow(); for (NodeOutput<MessagesState<String>> step : workflow.stream(...)) { WorkflowContext context = WorkflowContext.getContext(step.state()); // 根据不同节点类型发送不同事件 String nodeName = step.nodeName(); switch (nodeName) { case "image_collector": sink.next(WorkflowEvent.imageCollect( context.getImageList().size() )); break; case "code_generator": // 这里可以更进一步:流式输出代码生成过程 sink.next(WorkflowEvent.codeGenerateStart()); // 需要修改代码生成节点,使其能推送进度 break; // ... 其他节点 } } // 3. 完成事件 sink.next(WorkflowEvent.complete(context)); sink.complete(); } catch (Exception e) { sink.next(WorkflowEvent.error(e)); sink.complete(); } }); });}
然后前端实时进行展示输出效果,示例代码如下:
// 前端EventSource监听
const eventSource = new EventSource('/api/workflow/stream?prompt=...');
eventSource.addEventListener('step_start', (e) => {
const data = JSON.parse(e.data);
updateProgress(data.stepName, data.progress);
});
eventSource.addEventListener('image_collected', (e) => {
const data = JSON.parse(e.data);
showImages(data.images); // 实时显示收集到的图片
});
eventSource.addEventListener('code_chunk', (e) => {
const data = JSON.parse(e.data);
appendCode(data.chunk); // 实时显示生成的代码
});- SseEmitter方案 :标准SSE实现(可以参考看我的大模型应用开发需要掌握的技术-AI智能体(Agent)构建文章https://blog.csdn.net/TheChosenOnev/article/details/155917880?fromshare=blogdetail&sharetype=blogdetail&sharerId=155917880&sharerefer=PC&sharesource=TheChosenOnev&sharefrom=from_link)
扩展
一、如何让AI学会从错误中改进?
**1、传统重试:**使用循环来完成简单的重复调用,示例代码如下:
for (int i = 0; i < 3; i++) {
String code = ai.generateCode(prompt);
if (checkQuality(code)) break;
}这会有个问题,AI不知道错在哪里,只是盲目重试。
2、智能重试:提供反馈指导,示例代码如下:
// 第一次生成
String codeV1 = ai.generateCode(prompt);
QualityResult check1 = qualityChecker.check(codeV1);
if (!check1.isValid()) {
// 构建改进提示词
String improvedPrompt = buildFixPrompt(prompt, check1.getErrors(), check1.getSuggestions());
// 第二次生成:带着问题和建议
String codeV2 = ai.generateCode(improvedPrompt);
QualityResult check2 = qualityChecker.check(codeV2);
if (!check2.isValid()) {
// 还可以继续,但通常2次就够了
}
}**3、工作流实现:**质检→反馈→重试循环,示例代码如下:
// 质检节点
public static AsyncNodeAction<MessagesState<String>> createQualityCheckNode() {
return node_async(state -> {
WorkflowContext context = WorkflowContext.getContext(state);
// 读取生成的代码
String codeContent = readCodeFiles(context.getGeneratedCodeDir());
// AI质检
QualityResult result = qualityCheckService.checkCodeQuality(codeContent);
// 关键:记录质检历史
List<QualityResult> history = context.getQualityHistory();
if (history == null) history = new ArrayList<>();
history.add(result);
context.setQualityHistory(history);
// 当前质检结果
context.setQualityResult(result);
return WorkflowContext.saveContext(context);
});
}
// 代码生成节点(支持重试)
public static AsyncNodeAction<MessagesState<String>> createCodeGenNode() {
return node_async(state -> {
WorkflowContext context = WorkflowContext.getContext(state);
// 关键:判断是否为重试
List<QualityResult> history = context.getQualityHistory();
String userMessage = context.getEnhancedPrompt();
if (history != null && !history.isEmpty()) {
// 最后一次质检结果
QualityResult lastResult = history.get(history.size() - 1);
if (!lastResult.getIsValid()) {
// 构建修复提示词
userMessage = buildFixPrompt(
userMessage,
lastResult.getErrors(),
lastResult.getSuggestions()
);
log.info("第{}次重试生成代码", history.size());
}
}
// 调用AI生成代码
Flux<String> codeStream = codeGeneratorFacade.generateAndSaveCodeStream(
userMessage,
context.getGenerationType(),
context.getAppId()
);
// 等待完成
codeStream.blockLast(Duration.ofMinutes(10));
return WorkflowContext.saveContext(context);
});
}二、循环失控(条件边导致无限循环)
解决示例代码如下:
private String routeWithLimit(MessagesState<String> state) {
WorkflowContext context = WorkflowContext.getContext(state);
// 添加循环计数器
Integer loopCount = context.getLoopCount();
if (loopCount == null) loopCount = 0;
if (loopCount > MAX_LOOPS) {
log.warn("超过最大循环次数: {}", MAX_LOOPS);
return "fail";
}
context.setLoopCount(loopCount + 1);
// 正常路由逻辑
if (needRetry(context)) {
return "retry";
} else {
return "next";
}
}三、 状态污染(节点A修改了节点B需要的字段,导致B出错)
解决示例代码如下:
// 使用不可变状态副本
public static AsyncNodeAction<MessagesState<String>> createSafeNode() {
return node_async(state -> {
WorkflowContext context = WorkflowContext.getContext(state);
// 创建副本,只修改需要的字段
WorkflowContext update = WorkflowContext.builder()
.originalPrompt(context.getOriginalPrompt()) // 保留原字段
.imageList(collectImages(context)) // 只修改本节点负责的字段
.currentStep("图片收集")
.build();
// 其他字段保持不变
return WorkflowContext.saveContext(update);
});
}四、 并发死锁(多个节点等待彼此释放资源)
解决示例代码如下:
// 1. 使用超时
ExecutorService pool = Executors.newFixedThreadPool(4);
RunnableConfig config = RunnableConfig.builder()
.addParallelNodeExecutor("start", pool)
.timeout(Duration.ofSeconds(30)) // 设置超时
.build();
// 2. 避免共享可变状态
// 并发节点只读取共享状态,写入各自独立字段
graph.addNode("content_images", node_async(state -> {
WorkflowContext ctx = WorkflowContext.getContext(state);
List<ImageResource> content = collectContentImages(ctx.getOriginalPrompt());
ctx.setContentImages(content); // 独立字段,不冲突
return WorkflowContext.saveContext(ctx);
}));
graph.addNode("illustrations", node_async(state -> {
WorkflowContext ctx = WorkflowContext.getContext(state);
List<ImageResource> illus = collectIllustrations(ctx.getOriginalPrompt());
ctx.setIllustrations(illus); // 独立字段,不冲突
return WorkflowContext.saveContext(ctx);
}));