目录
- 前言:当数据采集从工程难题变为自然语言指令
- 一、传统爬虫之痛:慢、贵、脆、难扩展
- [二、Bright Data AI Scraper Studio:用AI重新定义爬虫](#二、Bright Data AI Scraper Studio:用AI重新定义爬虫)
- 三、实际解决方案:快速实现某直聘岗位监控(含完整操作)
-
- [1.注册并进入 AI Scraper Studio](#1.注册并进入 AI Scraper Studio)
- [2.输入URL + 自然语言Prompt](#2.输入URL + 自然语言Prompt)
- 3.运行采集任务
- 4.使用api自动交付
- [四、三大方案如何选?Bright Data 采集能力全景图](#四、三大方案如何选?Bright Data 采集能力全景图)
- 五、不止于招聘:赋能AI、SEO、AEO多场景
前言:当数据采集从工程难题变为自然语言指令
作为长期深耕数据工程和AI基础设施的技术博主,我接触过市面上几乎所有的爬虫工具,坦白说,大多数工具要么门槛太高(需要写大量选择器和反反爬逻辑),要么灵活性太差(模板固定,一遇改版就废),更别提维护成本:一个网站结构变动,整个管道就得重写。
直到最近深度试用 Bright Data 全新推出的 AI Scraper Studio,我才真正看到"AI驱动数据采集"的落地可能。
它不是"低代码玩具",而是真正将大模型能力注入企业级数据管道的革命性工具------在这里,数据采集不再是"写代码",而是"说需求"。
"采集BOSS直聘上公开可见的Java开发岗位,包括职位名称、公司、薪资、工作地点,以及详情页中的技术栈关键词。"
------就这么一句Prompt,系统自动生成完整爬虫架构,5分钟上线,无需一行代码。
更关键的是:当BOSS直聘近期悄然改版,传统脚本全部失效时,用户只需进入内置IDE,可一键"Regenerate"自动修复,AI便自动分析新版页面结构,3分钟内重建有效提取逻辑,恢复高质量采集------覆盖阿里、华为、中软等头部企业,业务零中断。
这背后,是一套为AI平台、SEO团队、竞争情报部门量身打造的极速数据采集范式......
一、传统爬虫之痛:慢、贵、脆、难扩展
对于AI平台、数据服务商、业务风控或竞争情报团队而言,多网站数据采集是刚需,却长期面临四大困境:
- 开发成本高:每个新网站都要写新脚本,1个工程师 × 3天 = 1个爬虫
- 维护压力大:BOSS直聘改版一次,脚本全挂,半夜被PagerDuty叫醒
- 扩展性差:想从BOSS扩展到猎聘、LinkedIn?再招2个爬虫工程师
- 稳定性不可控:IP被封、验证码拦截、动态渲染失败......数据管道随时中断
更致命的是------市场机会稍纵即逝。当AIGC岗位需求爆发时,谁先拿到数据,谁就掌握定价权。
二、Bright Data AI Scraper Studio:用AI重新定义爬虫
Bright Data 最新推出的 AI Scraper Studio,终于把"用一句话生成可靠爬虫"这件事做成了------它不是一个又一个要调选择器的工具,而是一个能理解需求、自动构建并维护数据管道的AI协作者。
✅ 核心能力:自然语言 → 生产级爬虫
你只需:
- 输入目标URL(如 https://www.zhipin.com/web/geek/job?query=Java开发\&city=101010100)
- 写一句自然语言Prompt(如:"采集搜索结果页所有岗位的职位名称、公司、薪资、工作地点、经验要求、学历要求及详情页完整URL")
AI Scraper Studio 即刻:
- 自动生成完整爬虫任务
- 自动配置全球住宅代理(绕过反爬)
- 自动处理动态加载与详情页跳转
- 输出结构化JSON/CSV
还记得那个被老板要求"再加50个网站"的工程师吗?
在传统模式下,这是噩梦;
而在 AI Scraper Studio 中,这只是一个批量替换URL并微调Prompt的操作------底层框架不变,AI自动适配新页面结构,效率提升10倍以上。
三、实际解决方案:快速实现某直聘岗位监控(含完整操作)
以下是博主实测的 BOSS直聘 Java 岗位监控案例,全程无需编码:
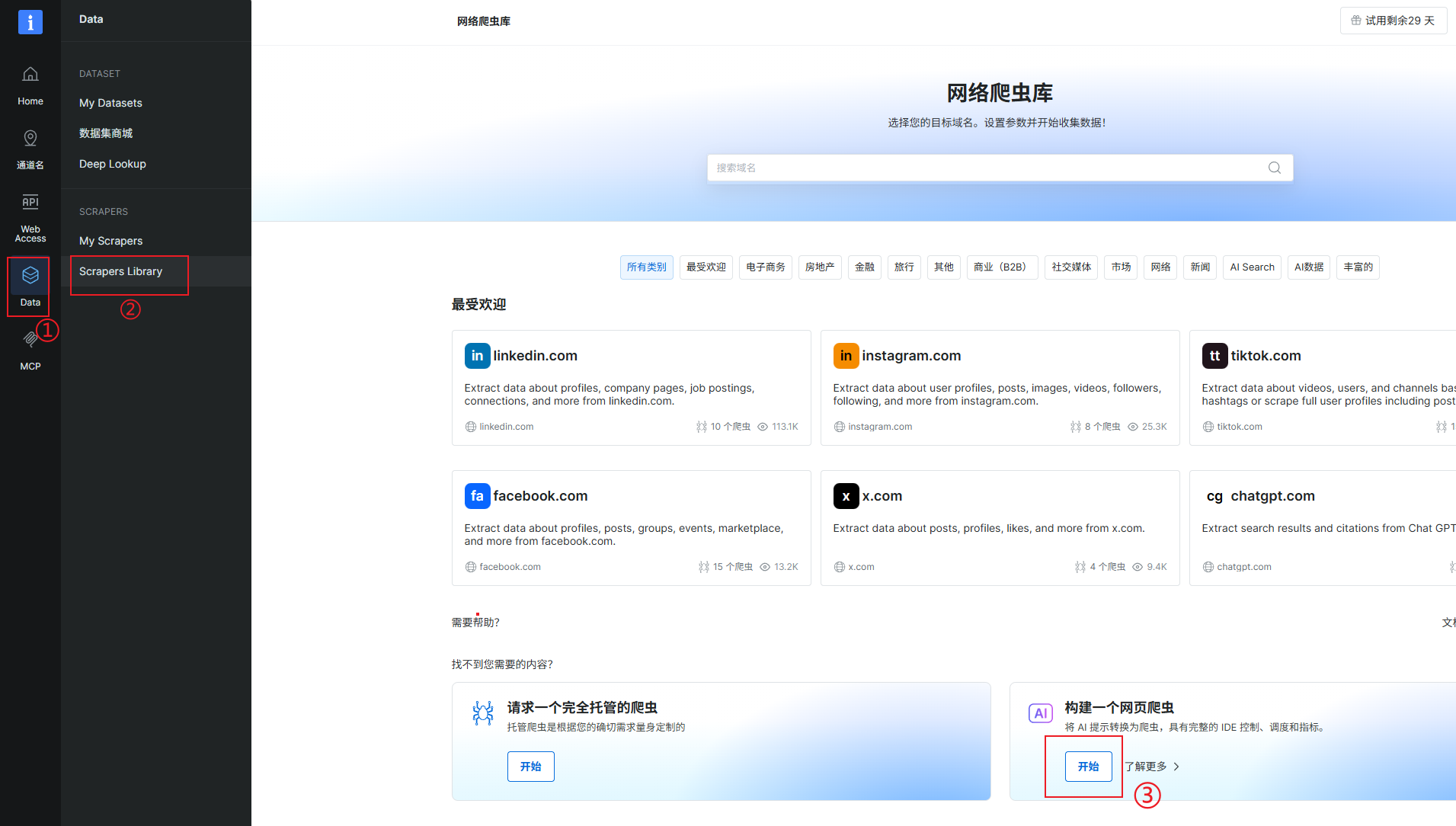
1.注册并进入 AI Scraper Studio
- 访问: Bright Data 官网,注册账号
- 进入 AI Scraper Studio(免费试用,每月享5000次请求)
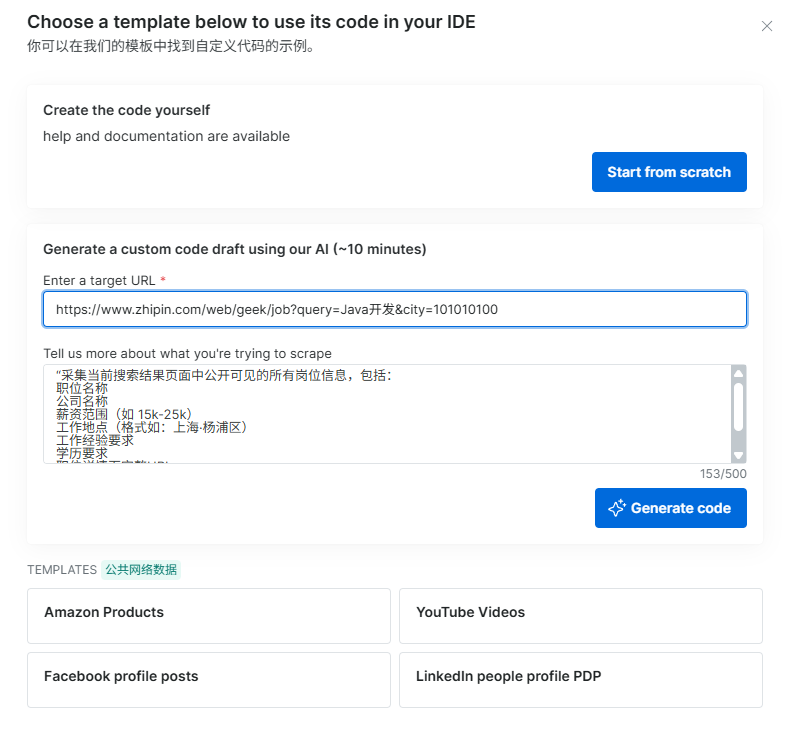
2.输入URL + 自然语言Prompt
目标URL:https://www.zhipin.com/web/geek/job?query=Java开发\&city=101010100(上海Java岗)
Prompt(关键!):"采集当前搜索结果页面中公开可见的所有岗位信息,包括:
职位名称
公司名称
薪资范围(如 15k-25k)
工作地点(格式如:上海·杨浦区)
工作经验要求
学历要求
职位详情页完整URL
请自动滚动加载并跳转至每个详情页,提取岗位描述中的技术栈关键词(如Java, SpringBoot, Redis等)。
点击 "Generate Code" 后,AI Scraper Studio 才真正开始工作------
它不会给你一段需要调试的代码片段,而是启动一个完整的无人值守工程流水线:理解你的需求、设计数据结构、生成抗反爬逻辑、并在真实网络环境中测试验证。
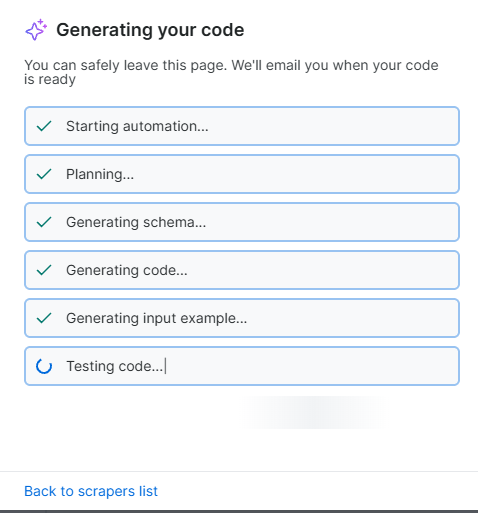
整个过程通常只需 1--3 分钟,但背后完成的工作,相当于人工开发 + 调试 + 测试的完整周期。
3.运行采集任务
项目生成并通过测试后,你会回到项目概览页。此时可点击 "预览(Preview)" 查看 AI 提取的样本数据,用于快速验证字段是否准确------此操作不消耗配额,也不执行全量采集。
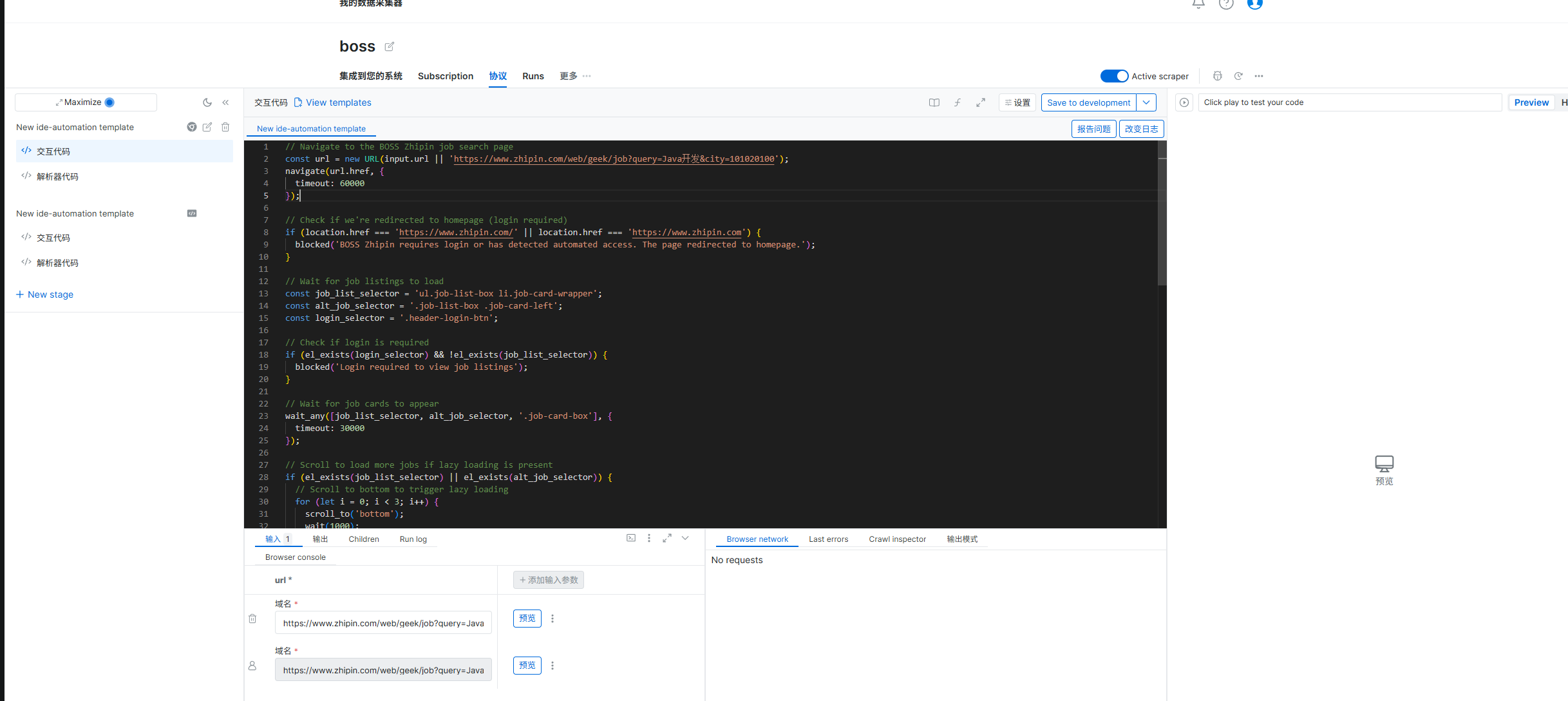
✅ 确认预览结果无误后,点击 "Start" 按钮即可启动完整采集任务。
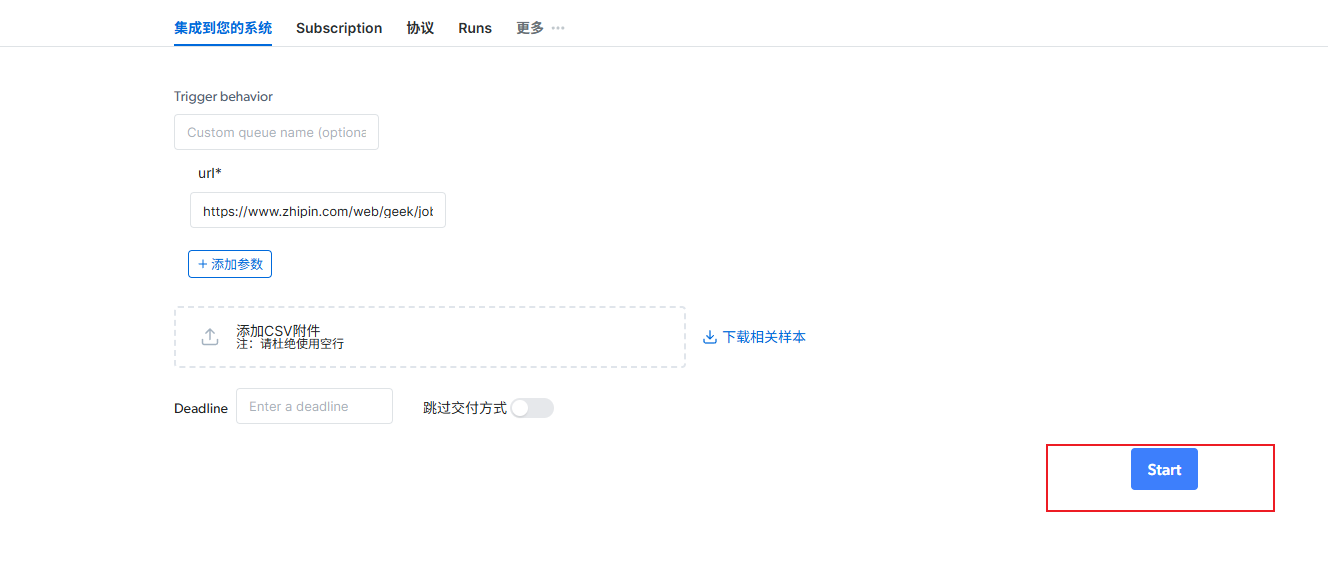
采集完成后,你可在 "Results" 标签页 下载数据,或通过 Webhook / API / 云存储(S3、GCS 等) 自动接收结果。
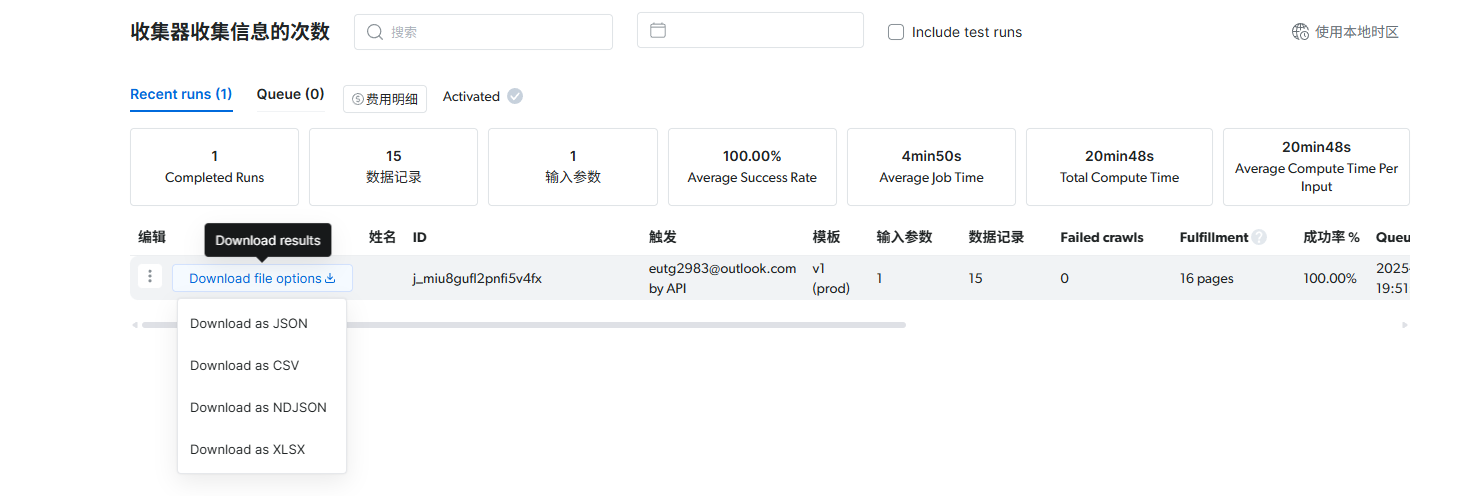
4.使用api自动交付
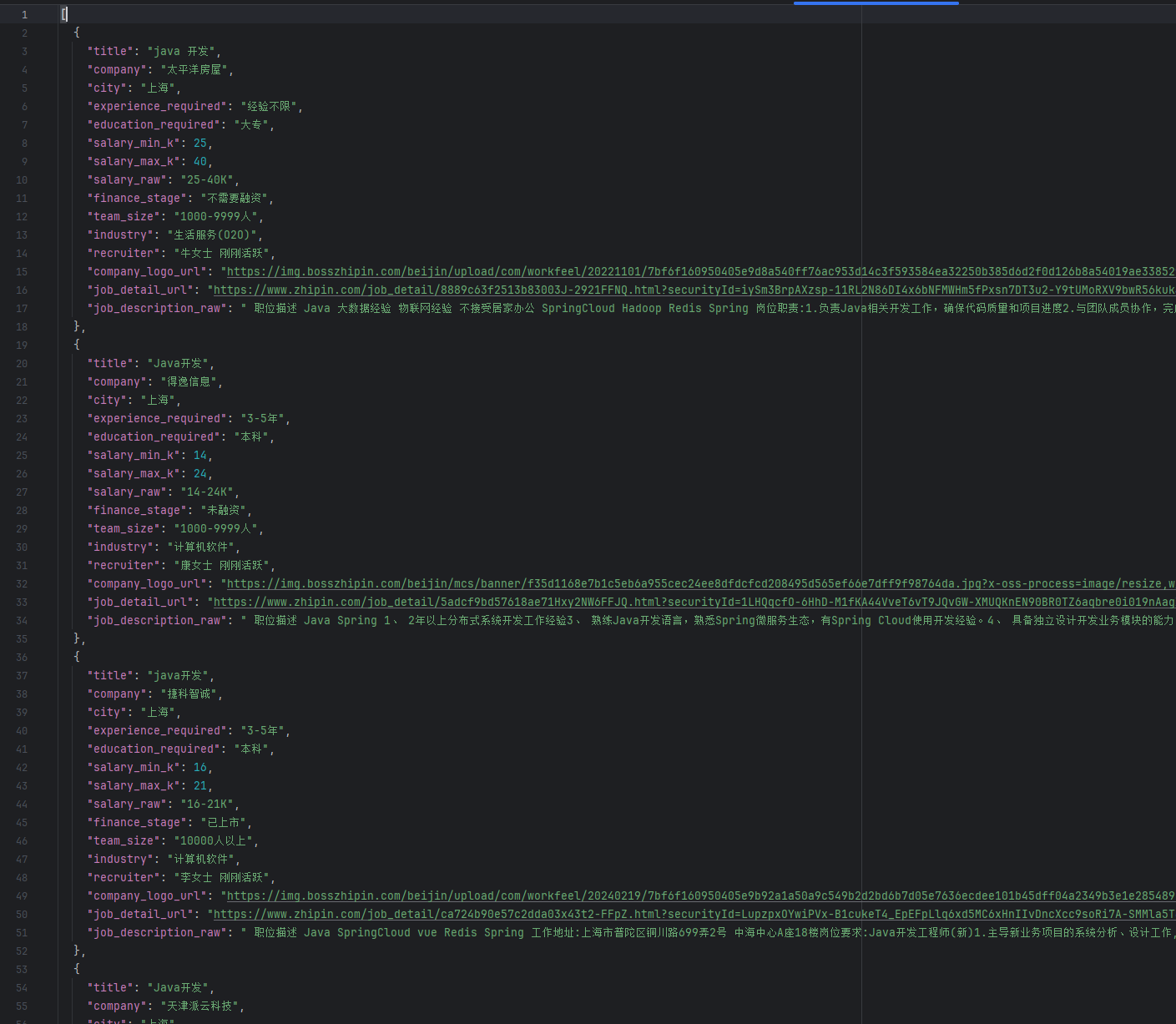
采集完成后,可通过 Dataset API 将结果自动拉取至本地,实现端到端自动化:
python
import requests
import json
# === 配置 ===
API_TOKEN = "" # ← 替换为你的实际 API Token
COLLECTION_ID = "" # ← 替换为你的实际 Job ID(即 COLLECTION_ID)
# === 请求 URL 和 Headers ===
url = f"https://api.brightdata.com/dca/dataset?id={COLLECTION_ID}"
headers = {"Authorization": f"Bearer {API_TOKEN}"}
response = requests.get(url, headers=headers)
if response.status_code != 200:
print(f"请求失败: {response.status_code} - {response.text}")
exit(1)
raw_text = response.text.strip()
if not raw_text:
print("返回为空")
exit(0)
# === 关键修复:尝试整体解析为 JSON(数组)===
try:
data = json.loads(raw_text)
if isinstance(data, list):
results = data
print(f"成功解析为 JSON 数组,共 {len(results)} 条记录")
elif isinstance(data, dict):
# 也可能是单个对象(虽然少见)
results = [data]
else:
raise ValueError("返回数据既不是数组也不是对象")
except json.JSONDecodeError:
# 如果整体解析失败,再尝试按 JSONL 逐行解析(兼容旧格式)
print("整体 JSON 解析失败,尝试 JSONL 模式...")
lines = raw_text.split('\n')
results = []
for i, line in enumerate(lines):
if line.strip():
try:
results.append(json.loads(line))
except json.JSONDecodeError:
pass # 忽略无效行
print(f"JSONL 模式解析出 {len(results)} 条记录")
# === 后续处理 ===
output_file = f"zhipin_jobs_{COLLECTION_ID}.json"
with open(output_file, "w", encoding="utf-8") as f:
json.dump(results, f, ensure_ascii=False, indent=2)
print(f"💾 已保存到 {output_file}")
# 预览
for item in results[:2]:
print(f"\n职位: {item.get('job_title')}")
print(f"公司: {item.get('company_name')}")
print(f"薪资: {item.get('salary')}")从api返回的结果文件可以看到,Bright Data 的 Dataset API 直接返回 格式规范、字段统一的 JSON 数组,无需额外解析 HTML 或处理乱码;开箱即用:每条记录已包含 job_title、company_name、salary、location 等关键字段,结构清晰,可直接用于后续分析;
四、三大方案如何选?Bright Data 采集能力全景图
在实际业务中,Bright Data 目前主流的数据管道搭建方式有三种:Web Scraper API 、IDE 自定义开发 、以及全新 AI Scraper Studio。不同方案各有优劣,适合不同团队和需求场景。
| 方案 | Web Scraper API | IDE 自定义开发 | AI Scraper Studio(推荐) |
|---|---|---|---|
| 适合人群 | 需要极简上手、无需开发、覆盖常用网站/结构化数据采集的用户 | 具备代码能力并拥有定制化复杂需求、愿意自行维护与升级爬虫脚本的技术团队 | 需快速扩展多域、追求极致效率与弹性的现代数据团队 |
| 上线速度 | ⚡ 极快(几分钟) | 🐢 慢(需开发+调试) | ⚡ 极快(自然语言生成脚本) |
| 灵活性 | 有限(仅支持预设模板和字段) | ⭐⭐⭐⭐⭐(任意网站、任意字段、完全可控) | ⭐⭐⭐⭐(Prompt 驱动 + 可进入 IDE 手动优化) |
| 维护成本 | Bright Data 全托管 | 客户自运维(脚本更新、反爬对抗等全负责) | AI 自愈 + 人工干预可选 |
| 典型场景 | 电商价格监控、标准商品信息抓取 | 极复杂反爬站点(如 BOSS直聘、LinkedIn) | 招聘聚合、SEO/AEO 监测、竞情分析、多渠道舆情 |
| 是否需要代码 | ❌ 零代码 | ✅ 必须具备 Puppeteer/Playwright 开发能力 | ❌ 初期零代码,✅ 后期可选代码增强 |
✅ 如果你既要速度,又要弹性,还要面向未来------AI Scraper Studio 是唯一选择。
五、不止于招聘:赋能AI、SEO、AEO多场景
Bright Data 不仅是招聘数据的采集利器,更是企业构建 全域数据感知能力 的核心引擎。一个平台,打通多维业务场景:
-
AI 训练数据构建
抓取技术博客、开源文档、学术论文、产品手册等高质量语料,为大模型微调与 RAG 提供可靠数据源。
-
智能 SEO 监测
自动追踪关键词排名变化、竞品 Meta 标签(Title/Description)更新、结构化数据变动,抢占搜索流量先机。
-
AEO(Answer Engine Optimization)优化
采集知乎、Quora、Reddit 等平台的高赞问答与专家观点,提炼用户真实意图,优化内容策略。
一个平台,覆盖从 AI 训练到增长运营的全链路数据需求。无论你是训练大模型、优化搜索排名,还是监控竞品动态,Bright Data 都能成为你的"外部数据感官"。
立即免费试用 Bright Data AI Scraper Studio,5 分钟开启 AI 驱动的数据采集!
每月享 5,000 次免费请求额度,零门槛快速上手。