摘要 ---基于无人机的目标检测存在固有挑战,例如无人机图像中目标的高密度和重叠,以及不同照明条件下目标的模糊性,这使得识别变得复杂。传统方法通常难以在复杂背景下识别众多密集的小目标。为了应对这些挑战,我们提出LAM-YOLO,一种专为基于无人机的目标检测设计的模型。首先,引入照明遮挡注意力机制以增强不同光照条件下小目标的可见性。同时,融入Involution模块以改善不同特征层之间的交互。其次,我们使用改进的SIB-IoU作为回归损失函数,以加速模型收敛并提高定位精度。最后,我们实施了一种新颖的检测策略,引入了两个用于识别更小尺度目标的辅助检测头。我们的定量结果表明,在VisDrone2019公共数据集上,LAM-YOLO在mAP@0.5和mAP@0.5:0.95指标上优于Faster R-CNN、YOLOv9和YOLOv10等方法。与原始YOLOv8相比,平均精度提高了7.1%。此外,所提出的SIB-IoU损失函数在训练期间显示出更快的收敛速度,并且比传统损失函数有更高的平均精度。
关键词 ---基于无人机的目标检测,密集对象,注意力机制,辅助小目标检测头,YOLO(你只看一次)
https://arxiv.org/pdf/2411.00485
I. 引言
无人飞行器(UAV)在航空测绘中提供了卓越的灵活性,几乎可以在任何地点起降,并能够快速完成任务。其运营成本显著低于传统飞机和直升机。因此,基于无人机的目标检测监测在采矿调查1、交通监控2和农业评估3等领域变得越来越关键。无人机在复杂场景中捕获的小目标检测尤为重要。

然而,无人机捕获图像时不同的高度和角度,结合环境因素,导致目标在图像中呈现出不同的尺寸和光照条件。此外,当成像距离过大时,小目标容易聚集、重叠和遮挡,这可能导致漏检和误报4。如图1(a)-(d)所示,基于无人机的目标检测面临重大挑战。总体上,无人机图像中的小目标检测存在几个显著的障碍:
- 目标尺寸多样:基于无人机的目标检测图像通常包含不同尺寸的目标,小物体特别容易受到干扰。这使得准确识别变得复杂并降低了检测精度。
- 遮挡与重叠:小目标经常经历遮挡和重叠,导致漏检和误报。
- 环境可变性:飞行位置、光照条件、天气和传感器噪声的变化导致图像中小目标的对比度和清晰度降低,进一步使检测工作复杂化。
随着深度学习技术的进步,卷积神经网络(CNN)已成为目标检测的主要方法5, 6,特别是YOLO(You Only Look Once)系列方法7, 8。为了解决上述基于无人机的目标检测面临的挑战,一些研究人员在该领域做出了共同努力。Xu等人9在特征提取之前采用空间和通道注意力,以尽可能保留目标信息。Chen等人7通过在不增加模型参数的情况下提高收敛速度来解决低检测率和高漏检率问题,利用WIoU-v2损失函数进行优化。虽然Wang等人8引入了小目标检测头以捕获极小目标,但这些方法未能考虑到,在骨干网络之前添加注意力模块会在保留的信息中引入更多干扰信号,以及损失函数能否在真实框和预测框之间准确回归最终影响极小目标的检测。
目前,基于无人机航空图像的小目标检测已取得显著进展。尽管在特征提取方面仍存在未解决的问题,阻碍了基于无人机的目标检测实现高精度,但当前方法往往只是针对特定问题的补救措施,而非从根本上解决核心挑战。现有方法的不足体现在几个关键领域:1)漏检和误检问题加剧。在无人机航空图像中,由于遮挡和距离等因素,小目标的尺度差异显著。如果没有专门的辅助检测头来增强对这些小目标的识别能力,模型可能会漏检。2)注意力线性压缩计算:传统的注意力机制,使用类似于挤压激励网络(SENet)10和金字塔视觉变换器(PVT)11中的池化的线性计算,无意中将目标特征与主要背景噪声合并,稀释了背景中的目标特征。为了解决这些问题,我们需要提出一种学习范式,不仅能应对小目标随无人机高度变化而改变尺寸和尺度的挑战,还能通过专门设计的注意力机制,减轻复杂场景中光照和遮挡对小目标造成的漏检。
为了解决无人机航空图像中小目标面临的复杂性,本研究旨在通过改进特征提取、检测和训练策略来提高检测精度。我们提出了LAM-YOLO,它在YOLOv8架构的基础上,集成了多个照明遮挡注意力模块(LAM)。这种设计促进了深层和浅层图像信息的跨尺度融合,从而增强了模型进行精确定位的能力。我们利用Involution块来改进不同尺度特征图之间的交互,从而能够捕获细微的目标特征。为了优化模型训练,我们引入了一种改进的损失函数,以增强预测边界框的回归能力。此外,为了解决目标尺寸的不确定性问题,我们在原始检测头之上集成了一个用于小目标的辅助检测头,从而提高了检测极小物体的准确性。
本文的主要贡献如下:
- 增强的注意力机制:我们提出了照明遮挡注意力模块(LAM),它包含通道注意力、自注意力和重叠交叉注意力机制。此外,本研究引入这些模块以加强多尺度特征交互,使模型能够捕获更多关于小目标的信息,同时也能更密切地关注被遮挡的目标。
- 精细化的回归损失:我们将SIB-IoU(软交并边界框IoU)整合到边界框回归损失中,并利用缩放因子生成不同尺寸的辅助边界框用于损失计算。这种方法促进了更快、更高效的模型训练,从而加速模型收敛并提高精度。
- 辅助小目标检测头:为了解决无人机图像中目标尺寸变化的问题,我们设计了一种辅助特征检测策略。在标准YOLOv8的三个现有检测头基础上,本研究增加了两个专门用于极小目标的辅助检测头,增强了对小物体的敏感性和检测能力。
- 实验验证:我们对LAM-YOLO模型进行了检测实验。结果表明,与基线YOLOv8相比,在VisDrone2019数据集上的精度提高了7.1%。同时,对比实验也证明了其优于其他最先进方法的检测性能。
本文的其余部分组织如下:第二节回顾了几种基于深度学习的目标检测方法。第三节详细描述了所提出的模型,而第四节展示了实验结果。最后,第五节对本文进行了总结。
II. 相关工作
A. 目标检测方法
- 两阶段检测方法:两阶段检测方法,如Faster R-CNN系列12,首先提出显式的区域建议,随后对这些建议进行分类以进行检测。此外,R2-CNN13集成了一个全局上下文注意力模块和一个专为小目标设计的建议生成器,从而提高了网络的性能。后来也引入了许多变体,例如MM R-CNN14,MSA R-CNN15。虽然这些方法实现了较高的检测精度,但它们检测速度慢,无法满足对实时性要求严格的任务。
- 单阶段检测方法:单阶段方法,如CenterNet16、CSPPartial-YOLO17、EC-YOLOX18、LAR-YOLOv819和YOLO20,绕过了区域建议步骤,直接预测分类分数和边界框回归偏移,旨在实现实时性能的同时保持高精度。例如,变换器预测头(TPH)21在原始YOLO中添加了注意力机制,通过为特征图的不同区域分配不同的权重,显示出巨大的潜力。
- 基于变换器的检测方法:基于变换器的方法利用注意力模型建立序列元素之间的依赖关系,从而能够提取全局上下文信息22。例如,视觉变换器(ViT)23和Swin变换器24。作为第一个基于变换器的端到端目标检测算法,DETR25在特征提取后将建议框与真实框进行一对一匹配。后来也引入了许多变体,如ARS-DETR26、CDN-DETR27、Deformable DETR28。尽管变换器展现出有前景的检测性能,但其复杂性和大量的参数导致计算资源消耗巨大,推理效率降低。
考虑到无人机预警系统等应用对强大实时性能的需求,我们从三个角度提出了一种无人机图像目标检测算法,以平衡检测精度和推理效率:首先,在努力提升检测精度的同时,必须确保实时检测;因此,采用单阶段检测方法来提取目标的空间特征。其次,我们提出了一种高效的注意力机制,强调小目标的特征并利用多尺度上下文信息,从而解决小目标的漏检和遮挡问题。最后,必须修改损失函数,以更好地使预测边界框与真实框对齐。
B. 基于YOLO系列的无人机目标检测
YOLO系列方法20,29-32是单阶段目标检测的代表。尽管YOLO系列模型在目标检测方面取得了相当大的成功,但仍需要专门的设计来应对无人机应用中的复杂场景,以提高检测精度。为了解决这个问题,Lou等人33提出了一种新的下采样方法,并修改了YOLOv8的特征融合网络,以增强其对密集小目标的检测能力。Wang等人8提出了BiFormer注意力机制,将其集成到骨干网络中,从而产生了Focus Faster Net Block(FFNB)特征处理模块。该模块引入了两个新的检测尺度,显著降低了漏检率。Xu等人9提出了YOLO-SA网络,该网络集成了针对下采样步骤优化的YOLO模型和增强的图像集,通过融合RGB和红外图像,实现了一种检测小航空目标的新方法。然而,对于某些复杂背景,如强光照或暗夜条件干扰,以及像远距离自行车和行人这样的小物体,这些方法的现有检测精度仍有待提高。
当前方法主要关注检测头中的特征融合33、瓶颈层中的注意力机制8,33以及更强大的骨干特征提取9。然而,目前没有方法专门针对复杂光照和遮挡场景中远距离小目标的精确检测,这影响了基于无人机的目标检测系统的鲁棒性。为了解决这个问题,我们选择YOLOv8作为基础框架,并集成了专门设计的照明遮挡注意力机制(LAM)。此外,我们集成了一个辅助小目标检测头,以增强模型检测极小目标的能力。为了提高模型训练速度,我们提出了一种改进的损失函数来调节不同尺度辅助边界框的生成。
C. 视觉注意力机制
视觉注意力机制在计算机视觉任务中起着至关重要的作用34,通过关注重要元素同时忽略复杂的背景干扰和噪声,实现高质量的特征表示。深度学习中的视觉注意力机制分为通道注意力和空间注意力机制。挤压激励(SE)10块是一个众所周知的模块,它动态地关注通道特性。它使用全局平均池化将通道压缩为单个值,通过全连接网络应用非线性变换,并将结果乘以输入通道向量作为权重。ECA35通过消除全连接层并使用一维卷积层来减少模型冗余并捕获通道交互。SE和ECA都在通道域应用注意力机制,同时忽略了空间域。CBAM36通过使用大核卷积来聚合一定范围内的位置信息,将通道注意力和空间注意力结合起来。然而,这种设计选择可能导致计算成本增加,使其不太适合开发轻量级模型。此外,单个具有大卷积核的层只能捕获局部位置信息,无法捕获全局位置信息。
然而,在基于无人机的目标检测中,我们设计了一种专门的注意力机制来解决遮挡和变化的环境光照条件。具体来说,我们从环境光照对认知心理学影响的研究中获得灵感37。我们的设计受到光在人类认知中的调节作用的影响,特别是其对警觉性和注意力的影响。因此,我们的注意力机制通过动态调整网络在不同光照条件下对特征的敏感性来模拟这种非视觉效应,从而增强对复杂环境中小目标的识别。
III. 方法
A. LAM-YOLO的整体结构
我们提出了一种用于复杂环境中基于无人机的小目标检测的照明遮挡注意力机制YOLO(LAM-YOLO),如图2所示。它建立在YOLOv8的基础上,旨在实现实时检测、更快的训练时间,同时提高更高精度的性能。首先,在骨干网络和瓶颈的输出层中引入了照明遮挡注意力模块(LAM)。该模块结合了通道注意力和自注意力机制,以增强我们模块的光照认知能力。受Involution机制的启发,我们在骨干和颈部之间加入Involution38块,以增强和共享通道信息,减少特征金字塔网络(FPN)39初始阶段的信息损失。此外,我们提出了一种新颖的软内交边界框IoU(SIB-IoU)作为边界框回归损失,这不仅提高了性能,还减少了训练时间。最后,我们引入了两个分辨率为160x160和320x320的辅助检测头,以提高检测小目标的能力。
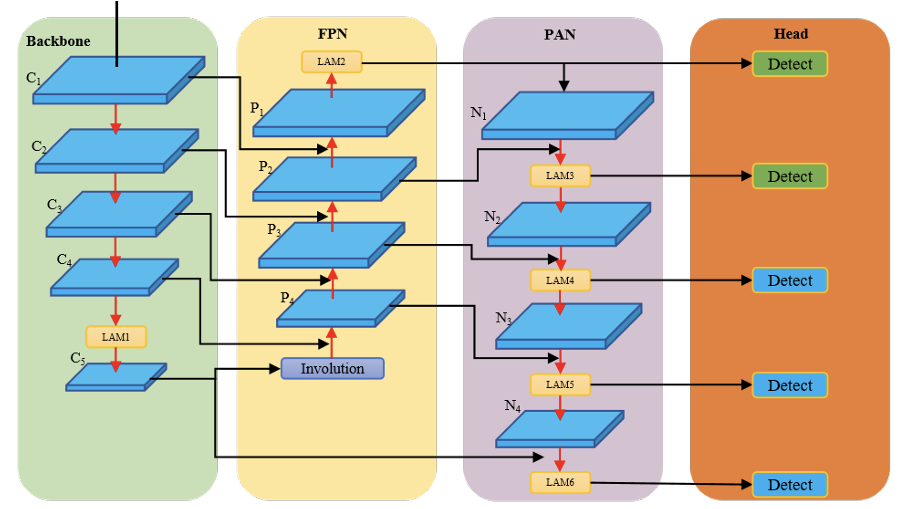
图2. LAM-YOLO结构。绿色部分是骨干,包含CSPDarkNet40;黄色部分是FPN39;紫色部分是PAN41;橙色部分是Head;蓝色检测头是原始的YOLOv8,绿色检测头是我们引入的辅助检测头。
B. 网络结构改进
- 照明遮挡注意力模块:由于无人机拍摄的图像距离较远,小物体比例高,且大多数小物体容易被遮挡。为了更好地被检测模型关注,我们在模型的骨干网络和颈部的输出部分提出了一种混合注意力模块,称为照明遮挡注意力(LAM)。LAM结合了通道注意力和基于窗口的自注意力机制,充分利用了它们的互补优势,利用了全局统计信息和强大的局部特征提取能力。
LAM的整体架构由三部分组成:浅层特征提取、深层特征提取和图像重建。对于给定的低分辨率输入 I L R ∈ R H × W × C i n I_{LR} \in \mathbb{R}^{H \times W \times C_{in}} ILR∈RH×W×Cin,我们首先使用一个卷积层来提取浅层特征 F 0 ∈ R H × W × C F_0 \in \mathbb{R}^{H \times W \times C} F0∈RH×W×C,其中 C i n C_{in} Cin和 C C C分别代表输入通道数和中间特征数。接下来,我们使用一系列残差混合注意力组(RHAG)和一个 3 × 3 3 \times 3 3×3卷积层 H c o n v ( ⋅ ) H_{conv}(\cdot) Hconv(⋅)进行深层特征提取。我们添加全局残差连接来集成浅层特征 F 0 F_0 F0和深层特征 F D ∈ R H × W × C F_D \in \mathbb{R}^{H \times W \times C} FD∈RH×W×C。最后,通过重建模块重建高分辨率结果。如图3所示,每个RHAG包含若干混合注意力块(HAB)、重叠交叉注意力块(OCAB)以及带有残差连接的 3 × 3 3 \times 3 3×3卷积层。对于重建模块,使用像素重排方法42来上采样融合后的特征。
-
Involution块 :在多尺度特征融合过程中,不同尺度的特征图可能无法充分交互,导致模型无法充分利用不同尺度的信息来检测小物体33。为了解决这个问题,我们在颈部添加了Involution块,它有助于通过重新分配通道和空间维度的信息来生成更丰富的特征表示,从而提高LAM-YOLO理解图像内容的能力,并在处理小而密集的物体时表现良好。Involution块如图4所示。Involution核 H ∈ R H × W × K × K × G \mathcal{H} \in \mathbb{R}^{H \times W \times K \times K \times G} H∈RH×W×K×K×G旨在结合在空间和通道域中表现出逆属性的变换,其中 H H H和 W W W代表特征图的高度和宽度, K K K是核大小, G G G是组数。每组共享相同的Involution核。具体来说,对于像素 X i , j ∈ R C \mathbf{X}{i,j} \in \mathbb{R}^{C} Xi,j∈RC(省略 C C C的下标),设计了一个特定的Involution核,记为 h ˉ i , j g ∈ R K × K \bar{h}{i,j}^{g} \in \mathbb{R}^{K \times K} hˉi,jg∈RK×K,对于 g = 1 , 2 , . . . , G g=1,2,...,G g=1,2,...,G,在所有通道上共享。最后,Involution的输出特征图 Y i , j \mathbf{Y}{i,j} Yi,j由以下公式获得:
Y i , j , k = ∑ ( u , v ) ∈ Δ K H i , j , u + ⌊ K / 2 ⌋ , v + ⌊ K / 2 ⌋ , ⌊ k G / C ⌋ X i + u , j + v , k \mathbf{Y}{i,j,k}=\sum_{(u,v)\in\Delta_K} \mathcal{H}{i,j,u+\lfloor K/2 \rfloor, v+\lfloor K/2 \rfloor, \lfloor kG/C \rfloor} \mathbf{X}{i+u,j+v,k} Yi,j,k=(u,v)∈ΔK∑Hi,j,u+⌊K/2⌋,v+⌊K/2⌋,⌊kG/C⌋Xi+u,j+v,k
H i , j = ϕ ( X Ψ i , j ) \mathcal{H}{i,j}=\phi\left(\mathbf{X}{\Psi_{i,j}}\right) Hi,j=ϕ(XΨi,j)其中 u u u和 v v v是核在二维空间(高度和宽度)中的偏移索引, Ψ i , j \mathbf{\Psi_{i,j}} Ψi,j索引像素集合, H i , j \mathbf{H_{i,j}} Hi,j是有条件的。
在图4中,为了便于演示(将 G G G设为1),X表示跨 C C C个通道的广播乘法, ∑ \sum ∑表示在 K × K K \times K K×K空间邻域内聚合的求和操作。因此,单个像素通道维度中包含的信息被隐式地分散在其空间附近,这对于获取丰富的感受野信息非常有用。
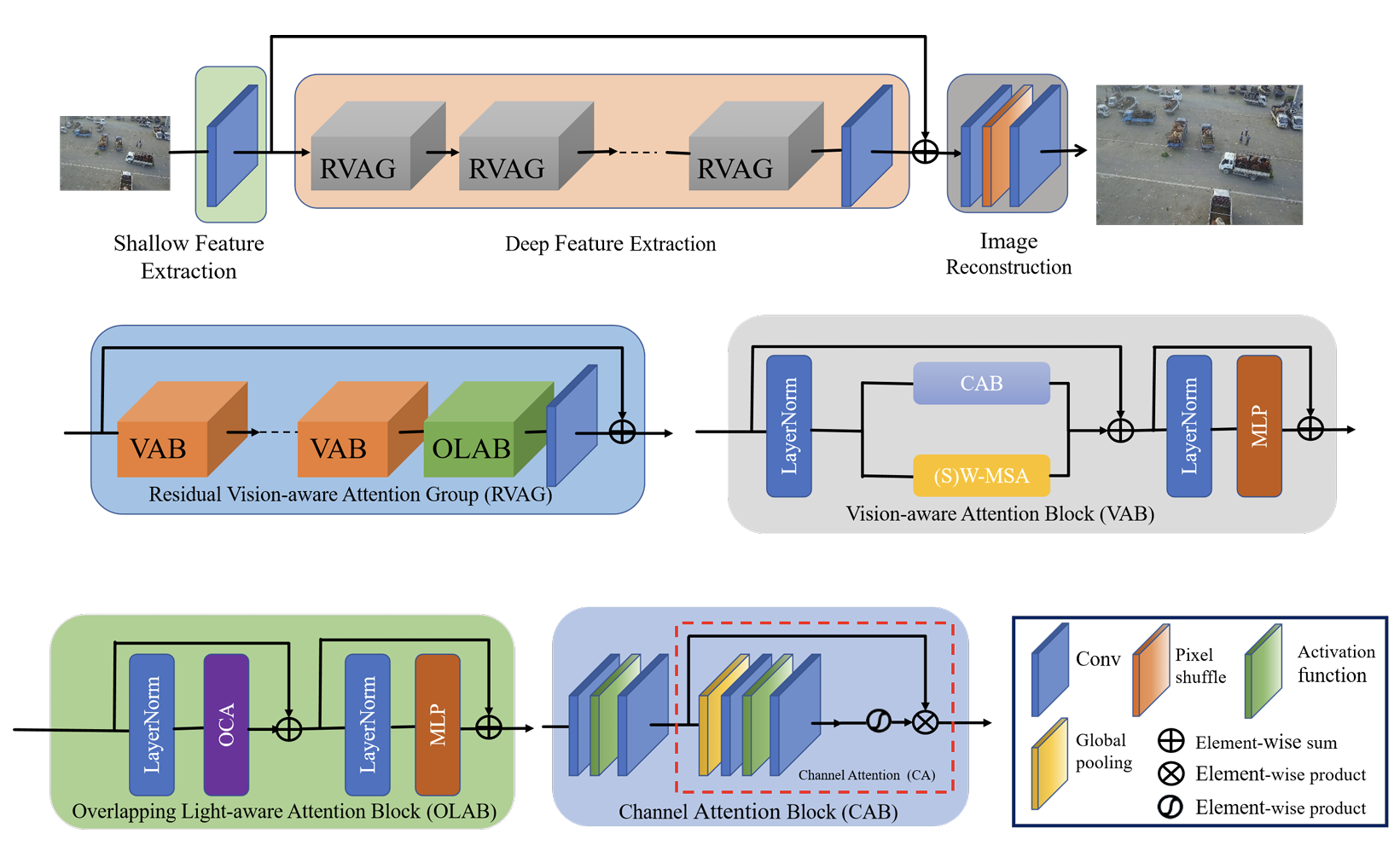
图3. 照明遮挡注意力模块。灰色模块代表残差视觉感知注意力组(RVAG),橙色模块代表视觉感知注意力块(VAB),绿色模块代表重叠光感知注意力块(OLAB)。
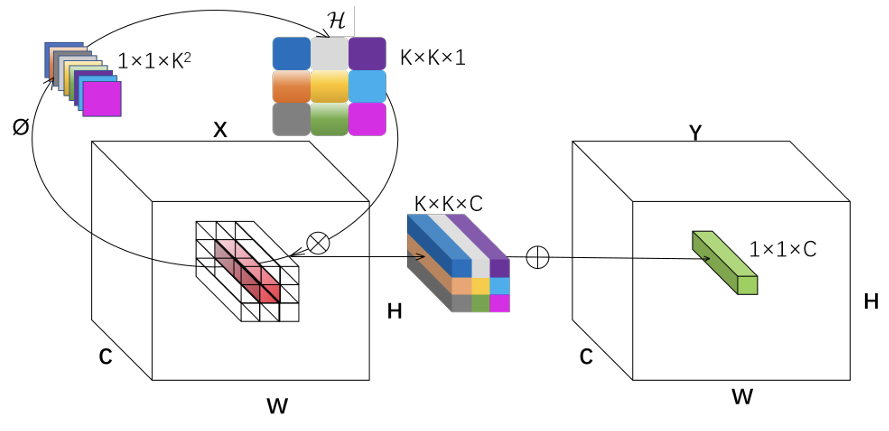
图4. Involution块的结构。
-
软内交边界框IoU:在无人机捕获的图像中,小物体的比例相当高,一个设计良好的损失函数可以提升检测性能。YOLOv8使用分布焦点损失(DFL)43和完全IoU(CIoU)44计算边界框回归损失,但CIoU在计算损失时没有平衡难易样本。此外,CIoU使用纵横比作为惩罚因子之一;然而,如果真实框和预测框共享相同的纵横比但具有不同的宽度和高度值,惩罚项无法准确反映两者之间的实际差异。这些点阻碍了其在无人机捕获的复杂航空场景中有效识别小物体的能力。
SCYLLA-IoU(SIoU)45首次引入了真实框和预测框之间的向量角度,重新定义了惩罚指标,提高了训练速度和推理精度,并加速了模型的收敛速度。考虑到锚框和GT框之间的角度对边界框回归的影响,将角度损失引入边界框回归损失函数,相关公式如下:
L S I o U = 1 − I o U + Δ + Ω 2 L_{SIoU} = 1 - IoU + \frac{\Delta + \Omega}{2} LSIoU=1−IoU+2Δ+Ω其中 Δ \Delta Δ是距离损失, Ω \Omega Ω是形状损失。
角度损失 Λ \Lambda Λ表示真实框中心点连接的最小角度:
Λ = sin ( 2 sin − 1 ( min ( ∣ x c g t − x c ∣ , ∣ y c g t − y c ∣ ) ( x c g t − x c ) 2 + ( y c g t − y c ) 2 + ϵ ) ) \Lambda = \sin\left(2\sin^{-1}\left(\frac{\min\left(\left|x_c^{gt} - x_c\right|, \left|y_c^{gt} - y_c\right|\right)}{\sqrt{\left(x_c^{gt} - x_c\right)^2 + \left(y_c^{gt} - y_c\right)^2 + \epsilon}}\right)\right) Λ=sin 2sin−1 (xcgt−xc)2+(ycgt−yc)2+ϵ min(∣xcgt−xc∣,∣ycgt−yc∣)其中 x c g t , y c g t x_c^{gt}, y_c^{gt} xcgt,ycgt表示真实框中目标 B g t B^{gt} Bgt中心点 b g t b^{gt} bgt的坐标, x c , y c x_c, y_c xc,yc表示预测中目标 B B B中心点 b b b的坐标。 ϵ \epsilon ϵ表示一个非常小的正数,以防止分母为零。
此项旨在根据角度的变化,优先调整锚框朝向最近的坐标轴(X轴或Y轴)。当角度为45°时, Λ \Lambda Λ等于1。如果中心点与X轴或Y轴对齐,则 Λ \Lambda Λ等于0。在考虑角度成本后,距离损失的定义如下:
Δ = 1 2 ∑ t = w , h ( 1 − e − γ ρ t ) , γ = 2 − Λ \Delta = \frac{1}{2} \sum_{t=w,h} \left(1 - e^{-\gamma \rho_t}\right), \quad \gamma = 2 - \Lambda Δ=21t=w,h∑(1−e−γρt),γ=2−Λ
{ ρ x = ( b x − b x g t w c ) 2 ρ y = ( b y − b y g t h c ) 2 \left\{\begin{aligned} \rho_x &= \left(\frac{b_x - b_x^{gt}}{w^c}\right)^2 \\ \rho_y &= \left(\frac{b_y - b_y^{gt}}{h^c}\right)^2 \end{aligned}\right. ⎩ ⎨ ⎧ρxρy=(wcbx−bxgt)2=(hcby−bygt)2其中 ρ t \rho_t ρt表示边界框宽度或高度的归一化距离, γ \gamma γ是根据角度损失 Λ \Lambda Λ调整的系数。 ρ x , ρ y \rho_x, \rho_y ρx,ρy分别表示边界框中心点在x和y方向上的归一化距离。 b x , b y b_x, b_y bx,by表示预测边界框中心点的坐标。 b x g t , b y g t b_x^{gt}, b_y^{gt} bxgt,bygt表示真实边界框中心点的坐标。 w c , h c w^c, h^c wc,hc表示覆盖目标框和预测框的最小边界框的宽度和高度。
形状损失 Ω \Omega Ω主要描述GT框和锚框之间的大小差异:
Ω = 1 2 ∑ t = w , h ( 1 − e ω t ) θ , θ = 4 \Omega = \frac{1}{2} \sum_{t=w,h} \left(1 - e^{\omega_t}\right)^\theta, \quad \theta = 4 Ω=21t=w,h∑(1−eωt)θ,θ=4
{ ω w = ∣ w − w g t ∣ max ( w , w g t ) ω h = ∣ h − h g t ∣ max ( h , h g t ) \begin{cases} \omega_w = \frac{|w - w_{gt}|}{\max(w, w_{gt})} \\ \omega_h = \frac{|h - h_{gt}|}{\max(h, h_{gt})} \end{cases} {ωw=max(w,wgt)∣w−wgt∣ωh=max(h,hgt)∣h−hgt∣其中 ω t \omega_t ωt表示边界框宽度或高度的归一化差异。 ω w , ω h \omega_w, \omega_h ωw,ωh分别表示边界框宽度和高度的归一化差异。 w , h w, h w,h表示预测边界框的宽度和高度。
SIB-IoU引入了尺度因子控制来生成不同尺度的辅助边界框以计算损失,并将其应用于现有的IoU。如图5所示,GT框和锚框分别表示为 b g t b^{gt} bgt和 b b b,GT框的中心坐标记为 ( x c g t , y c g t ) (x_c^{gt}, y_c^{gt}) (xcgt,ycgt),锚框的中心坐标记为 ( x c , y c ) (x_c, y_c) (xc,yc)。GT框的宽度和高度分别用 w g t , h g t w^{gt}, h^{gt} wgt,hgt表示,而锚框的宽度和高度用 w , h w, h w,h表示。缩放因子,记为变量ratio,通常范围在 0.5 , 1.5 0.5, 1.5 0.5,1.5。当该比例小于1时,表示辅助边界框小于实际边界框,与IoU损失相比,有效回归范围更窄。然而,梯度的绝对值大于IoU损失产生的梯度,这有利于高IoU样本的更快收敛。相反,当比例超过1时,更大尺度的辅助边界框扩展了有效回归范围,并提高了低IoU样本的回归性能。相关公式如下:
b l g t = x c g t − w g t ∗ ratio 2 , b r g t = x c g t + w g t ∗ ratio 2 b t g t = y c g t − h g t ∗ ratio 2 , b b g t = y c g t + h g t ∗ ratio 2 \begin{aligned} b_l^{gt} &= x_c^{gt} - \frac{w^{gt} * \text{ratio}}{2}, \quad b_r^{gt} = x_c^{gt} + \frac{w^{gt} * \text{ratio}}{2} \\ b_t^{gt} &= y_c^{gt} - \frac{h^{gt} * \text{ratio}}{2}, \quad b_b^{gt} = y_c^{gt} + \frac{h^{gt} * \text{ratio}}{2} \end{aligned} blgtbtgt=xcgt−2wgt∗ratio,brgt=xcgt+2wgt∗ratio=ycgt−2hgt∗ratio,bbgt=ycgt+2hgt∗ratio
b l = x c − w ∗ ratio 2 , b r = x c g t + w ∗ ratio 2 b t = y c − h ∗ ratio 2 , b b = y c g t + h ∗ ratio 2 \begin{aligned} b_l &= x_c - \frac{w * \text{ratio}}{2}, \quad b_r = x_c^{gt} + \frac{w * \text{ratio}}{2} \\ b_t &= y_c - \frac{h * \text{ratio}}{2}, \quad b_b = y_c^{gt} + \frac{h * \text{ratio}}{2} \end{aligned} blbt=xc−2w∗ratio,br=xcgt+2w∗ratio=yc−2h∗ratio,bb=ycgt+2h∗ratio
inter = ( min ( b r g t , b r ) − max ( b l g t , b l ) ) ( min ( b b g t , b b ) − max ( b t g t , b t ) ) \text{inter} = (\min(b_r^{gt}, b_r) - \max(b_l^{gt}, b_l))(\min(b_b^{gt}, b_b) - \max(b_t^{gt}, b_t)) inter=(min(brgt,br)−max(blgt,bl))(min(bbgt,bb)−max(btgt,bt))
union = ( w g t × h g t ) × ( ratio ) 2 + ( w × h ) × ( ratio ) 2 − inter \text{union} = (w^{gt} \times h^{gt}) \times (\text{ratio})^2 + (w \times h) \times (\text{ratio})^2 - \text{inter} union=(wgt×hgt)×(ratio)2+(w×h)×(ratio)2−inter
I o U i n n e r = inter union IoU^{inner} = \frac{\text{inter}}{\text{union}} IoUinner=unioninter结合SIoU和Inner-IoU得到公式如下:
L S I B _ I o U = L S I o U + I o U − I o U i n n e r L_{SIB\IoU} = L{SIoU} + IoU - IoU^{inner} LSIB_IoU=LSIoU+IoU−IoUinner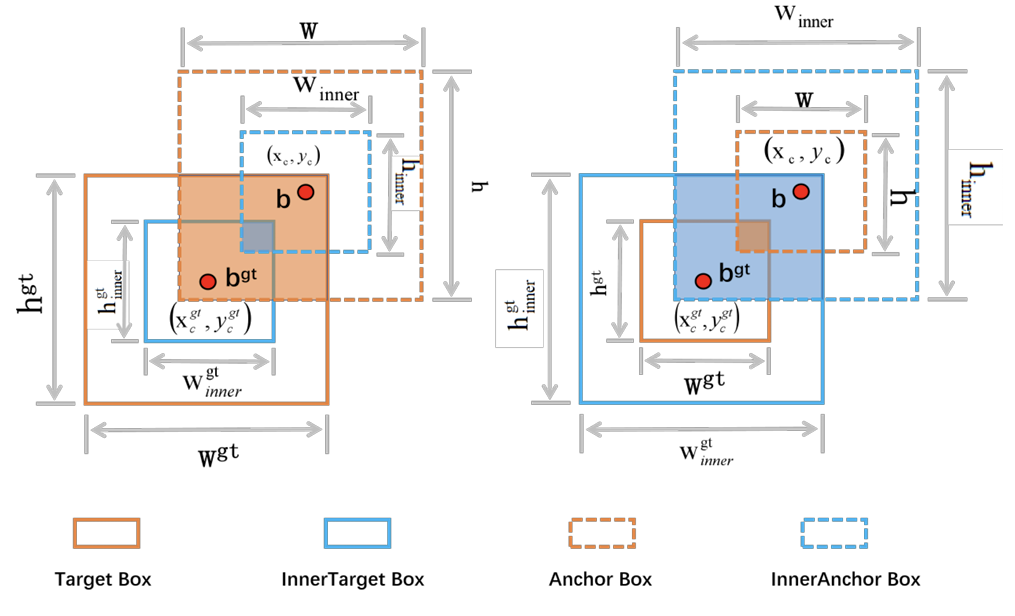
图5. Inner-IoU描述
IV. 实验与分析
在第四节中,我们在一个基于无人机的数据集上进行了实验,并与最先进(SOTA)方法的结果进行了比较,以评估LAM-YOLO的性能。本研究辅以详细的消融分析,以评估LAM-YOLO中每个组件的贡献。我们在实验分析中旨在解决以下关键问题:
- Q1:与最先进技术的比较分析:我们将LAM-YOLO与其他前沿方法进行比较,重点放在第四节B中的定量评估和视觉结果上。
- Q2:模块性能增益:第四节C详细说明了LAM-YOLO各模块带来的单独性能提升。
- Q3:最佳LAM数量:我们将LAM-YOLO与其他前沿方法进行比较,重点放在第四节C1中的定量评估和视觉结果上。
- Q4:损失函数的影响:在第四节C3中,我们验证了改进损失函数对训练的影响,并统计分析评估指标与训练周期之间的关系。
A. 实验设置
-
数据集 :我们使用VisDrone20198公共数据集,这些数据集由各种专业无人机摄像头在14个不同场景(包括不同地点(城市和农村)和密度(稀疏和拥挤))下捕获。VisDrone2019数据集包含10种检测目标,如行人、车辆和自行车;然而,类别样本的分布高度不均匀。图6展示了类别分布的样本统计。在该图中,纵轴表示边界框的高度,横轴表示其宽度。观察表明,点集中在左下象限,表明小物体在VisDrone2019数据集中占主导地位。这一趋势反映了无人机技术的实际应用,并与本文的研究背景和解决的问题非常吻合。
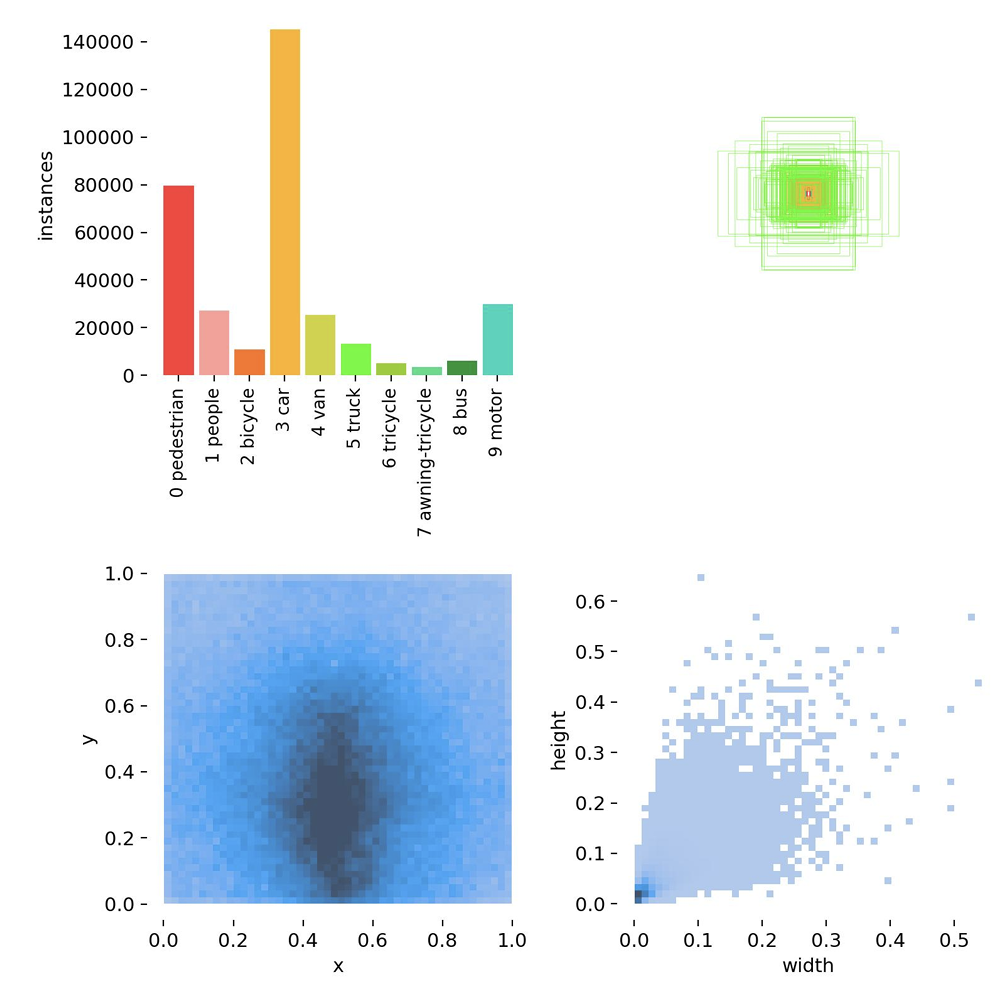
图6. VisDrone2019数据集中物体手动标注的信息。
-
实施细节 :在本实验中,使用了配备L20 GPU和48G运行内存的20 vCPU Intel® Xeon® Platinum 8457C处理器。模型训练期间的一些关键参数设置如表I所示。
表I:模型训练期间设置的一些关键参数
-
评估指标 :为了评估改进模型的检测性能,我们关注模型的准确性和复杂性,并采用精确率、召回率、 m A P 0.5 mAP0.5 mAP0.5、 m A P 0.5 : 0.95 mAP0.5:0.95 mAP0.5:0.95作为指标。
精确率定义为模型预测的正样本数与检测到的样本总数之比,计算公式如下:
P r e c i s i o n = T P T P + F P \mathrm{Precision} = \frac{TP}{TP + FP} Precision=TP+FPTP召回率是正确预测的正样本数与实际正样本总数之比:
Recall = T P T P + F N \operatorname{Recall} = \frac{TP}{TP + FN} Recall=TP+FNTP其中 T P TP TP(真正例)表示准确预测为正的正样本数量。 F P FP FP(假正例)表示被错误分类为正的负样本数量。 T N TN TN(真负例)表示准确分类为负的负样本数量。 F N FN FN(假负例)表示被错误分类为负的正样本数量。
平均精度 ( A P ) \mathrm{(AP)} (AP)等于精确率-召回率曲线下的面积:
A P = ∫ 0 1 P r e c i s i o n ( R e c a l l ) d ( R e c a l l ) AP = \int_0^1 \mathrm{Precision(Recall)}\, d(\mathrm{Recall}) AP=∫01Precision(Recall)d(Recall)平均精度 ( m A P ) \mathrm{(mAP)} (mAP)是所有样本类别的 A P AP AP值的平均值,表明训练后的模型在检测所有类别方面的有效性:
m A P = 1 N ∑ i = 1 N A P i \mathrm{mAP} = \frac{1}{N} \sum_{i=1}^{N} AP_i mAP=N1i=1∑NAPi其中 A P i AP_i APi表示第 i i i个类别的 A P AP AP值, N N N表示VisDrone2019训练数据集中的类别数 ( N = 10 ) (N=10) (N=10)。
B. 与最先进技术的比较
-
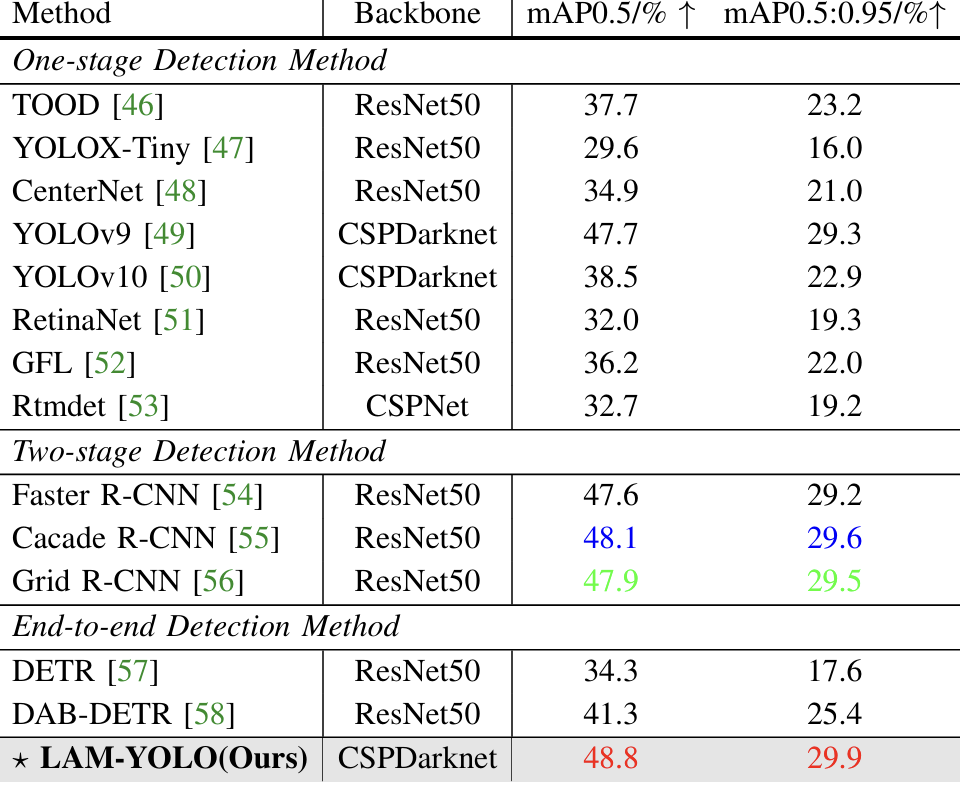
定量比较与分析 :我们将我们的模型与当前先进方法和最先进(SOTA)方法进行了比较,包括单阶段检测方法:TOOD 46、YOLOX-Tiny 47、CenterNet 48、YOLOv9 49、YOLOv10 50、RetinaNet 51、GFL 52和Rtmdet 53;两阶段检测方法:Faster R-CNN 54、Cascade R-CNN 55和Grid R-CNN 56;以及端到端检测方法:DETR 57、DAB-DETR 58。表II展示了多种目标检测模型在各种评估指标上的定量比较结果。评估指标包括 m A P @ 0.5 mAP@0.5 mAP@0.5和 m A P @ 0.5 : 0.95 mAP@0.5:0.95 mAP@0.5:0.95,分别衡量模型在不同阈值下的平均精度。 m A P @ 0.5 mAP@0.5 mAP@0.5表示IoU为0.5时的平均精度,而 m A P @ 0.5 : 0.95 mAP@0.5:0.95 mAP@0.5:0.95反映了在多个IoU阈值(从0.5到0.95,步长为0.05)下计算的平均mAP。从表II可以明显看出,两阶段和端到端方法的指标通常较高,而单阶段方法的指标相对较低。我们的模型作为单阶段方法, m A P @ 0.5 mAP@0.5 mAP@0.5指标达到了48.8, m A P @ 0.5 : 0.95 mAP@0.5:0.95 mAP@0.5:0.95值达到了29.9,相较于同为单阶段的YOLOv9模型, m A P 50 mAP50 mAP50和 m A P 50 : 95 mAP50:95 mAP50:95分别高出1.1%和0.6%。此外,与两阶段模型相比,我们的模型在 m A P 0.5 mAP0.5 mAP0.5指标上优于经典的Faster R-CNN和Cascade R-CNN模型。与Cascade R-CNN相比,我们的模型分别提高了0.7%和0.3%,展示了其在无人机目标检测任务中的出色性能。
表II:与其他最先进方法在四个评估指标上的比较,最佳结果用红色标出,次佳结果用蓝色标出,第三佳结果用绿色标出。

为了进一步评估我们模型的检测性能,我们进行了对比实验,重点关注三个关键方面:评估指标、混淆矩阵和模型推理结果。图7展示了改进模型在VisDrone2019数据集上的评估指标。图表从左到右、从上到下可视化了一致性平均值、精确率-召回率(P-R)曲线、准确率和召回率等关键指标。分析表明,LAM-YOLO在保持高召回率的同时实现了最佳检测精度。相应的混淆矩阵如图8所示。
总之,对比实验的结果表明,LAM-YOLO在检测性能上优于其他模型。我们的多尺度特征融合网络实现了五尺度检测,并结合了LAM,与上述评估的模型相比,在检测无人机小物体方面具有明显优势。
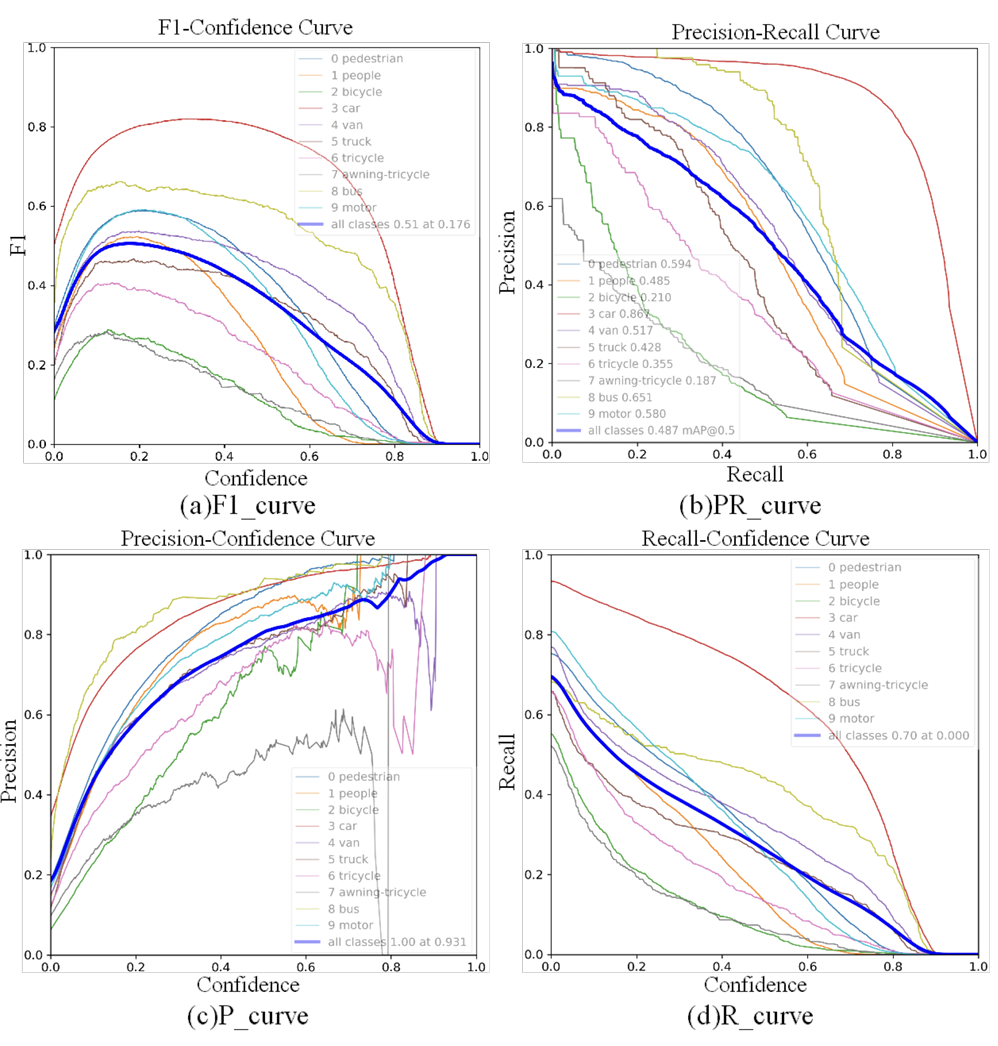
图7. 评估参数的可视化。(a)F1曲线。(b)PR曲线。©P曲线。(d)R曲线。
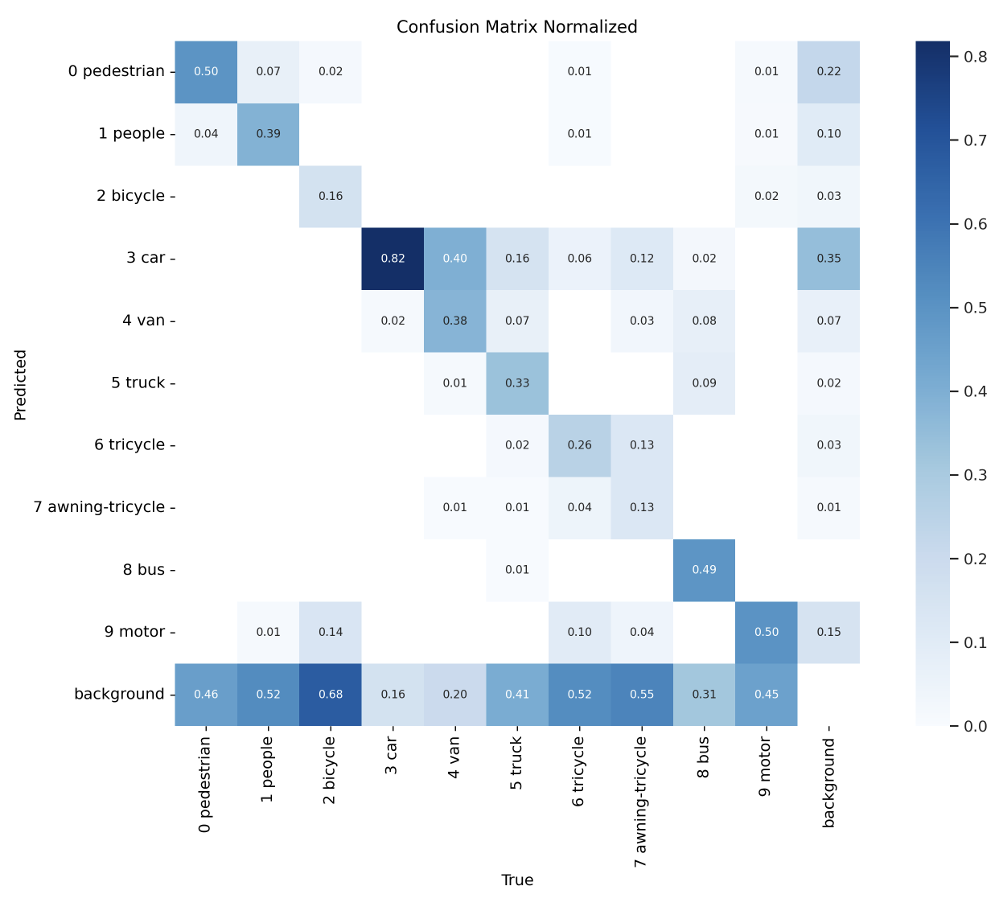
图8. LAM-YOLO模型的混淆矩阵图。颜色越深,相关系数越接近1。
-
定性比较与分析:为了评估LAM-YOLO的有效性,我们在低光照场景、强光环境、密集人群场景和夜间复杂遮挡道路场景中进行了全面比较。在这些不同的环境中,我们的模型表现出卓越的检测性能,显著提高了准确预测目标类别、识别车辆和其他物体的能力。改进的检测模型的有效性通过图9中呈现的视觉结果得到进一步证实。然而,尽管Cascade R-CNN可以检测到大多数目标,但在某些区域仍遇到漏检和边界框不准确的问题。CenterNet在处理遮挡和密集场景方面表现欠佳,导致漏检增加,并且在低光照条件下性能不足。DAB-DETR在这些场景中表现出不足,存在误检和漏检,特别是在强光环境中。Faster R-CNN在遮挡和夜间场景中表现相对稳定,但在其他场景中存在缺陷。虽然GFL可以识别一些目标,但其在密集区域的检测精度相对较低,表明其在小目标检测的灵敏度方面存在不足。
我们提出的模型在各种复杂环境中都表现出卓越的性能。改进的网络有效地捕获了全局相互依赖关系,降低了对遮挡和密集物体的漏检率,并显著提高了整体检测性能。其检测精度明显优于其他主流目标检测算法。这表明我们的模型在特征提取、目标定位和遮挡处理能力方面取得了实质性改进,从而更好地解决了实际应用中的各种挑战。

图9. 模型在VisDrone2019数据集上的改进视觉检测结果。第一行代表不同方法在低光环境下的识别性能,第二行代表不同方法在强光环境下的识别性能,第三行代表不同方法在遮挡环境下的识别性能,第四行代表不同方法在密集环境下的识别性能。红色边界框表示局部放大区域。
C. 消融研究
-
不同模型组件的消融:我们验证了每个提出的改进策略的有效性,并对模型进行了消融实验。结果如表III所示,每个改进策略都相应地提高了检测性能。第一个改进是增加了两个尺寸为160x160和320x320的检测头,这对于检测小目标特别有效,考虑到VisDrone2019数据集中小物体的普遍性,这是一个关键需求。P2检测头将精度提高了3.4%,P1检测头提高了1.6%。随后,照明遮挡注意力模块(LAM)混合注意力模块被逐步集成到每个输出层中,从而进一步提高了性能。Involution模块也有助于相对精度的提高,特别是在减少小目标的漏检率方面。总体而言,增强模型使平均检测精度提高了7.1%,在大多数检测指标上都有显著改进。
为了证明改进模型在增强检测性能方面的有效性,我们在改进模型和YOLOv8s之间进行了对比实验。如表IV的比较结果所示,展示了两个模型在各个类别上的AP值和所有类别的 m A P @ 0.5 mAP@0.5 mAP@0.5值。此外,改进模型的 m A P mAP mAP提高了7.1%。所有类别的AP值都有不同程度的提高,其中Pedestrian、People和Motor类别的增长超过10%。这些结果表明,改进模型有效地提高了检测精度。
此外,图10通过Grad-CAM更直观地展示了不同数量LAM对输入图像特征提取的影响。随着LAM层数从"Six LAM"逐渐减少到"Zero LAM",热图中的突出区域变得较弱且分布不均匀,表明模型对重要特征的关注度正在下降。在各种场景中,随着LAM的减少,对目标的关注区域也缩小,对远处目标的关注逐渐减弱。
表III:不同技术的模型比较。P2代表160 160的特征图大小,P1代表320320的特征图大小,LAMi(i=1,2,...6)代表不同位置的LAM。↑表示指标越高越好。

表IV:改进模型与YOLOv8s检测精度的比较

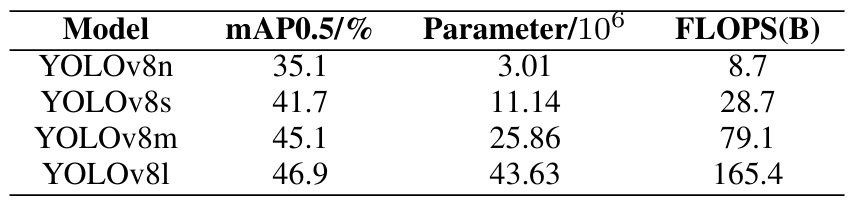
表V:不同尺寸的YOLOv8模型在VisDrone2019数据集上的性能比较
-
骨干网络的消融:YOLOv8在前身的基础上引入了新功能,增强了其对各种应用中广泛目标检测任务的适用性。官方发布了四个不同的YOLOv8模型:YOLOv8n、YOLOv8s、YOLOv8m和YOLOv8l,每个模型的大小和复杂程度不同。这些模型的参数详见表V。考虑到该模型旨在部署在无人机上,必须在准确性和复杂性之间取得仔细的平衡。在YOLOv8模型中,YOLOv8s在最小化复杂性的同时保持准确性方面提供了最佳的折衷方案。因此,我们的模型基于YOLOv8s架构开发。
为了验证改进模型在增强检测性能方面的有效性,在改进模型和YOLOv8之间进行了对比实验。如表IV的比较结果所示,改进模型的 m A P mAP mAP提高了7.1%。所有类别的AP值都有不同程度的提高,其中行人、人和摩托车类别的AP值提高了10%以上。实验结果表明,改进模型有效地提高了检测精度。
-
SIB-IoU损失函数的消融 :为了验证引入SIB-IoU的好处,我们在改进模型上使用SIB-IoU和其他主流损失函数进行了对比实验,同时保持一致的训练条件。结果如表VI所示。实验表明,当使用SIB-IoU作为边界框回归损失时,模型达到最佳检测性能。此外,使用SIB-IoU的模型的 m A P 50 mAP50 mAP50比使用CIoU的模型高0.7%,突出了SIB-IoU的有效性。
在另一组实验中,我们使用带有SIB-IoU和其他主流损失函数的改进模型验证了引入SIB-IoU的好处,如图11所示,表明当SIB-IoU作为边界框回归损失时,模型的检测性能最佳。此外,使用SIB-IoU的模型的 m A P 50 mAP50 mAP50比使用DIoU的模型高0.8%,进一步强调了SIB-IoU的有效性。图表显示,使用SIB-IoU的模型损失降低速度和mAP值增长速度更快。
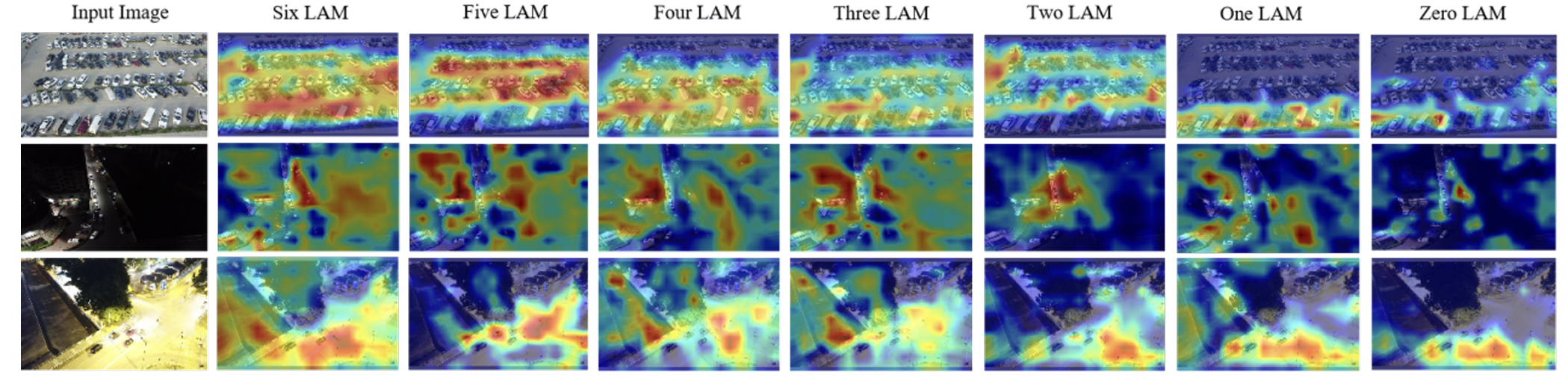
图10. 模型在VisDrone2019数据集上的改进视觉检测结果。热图越突出,网络对暗光和亮光区域的特征提取能力越强。
表VI:改进模型引入不同损失函数的检测结果比较
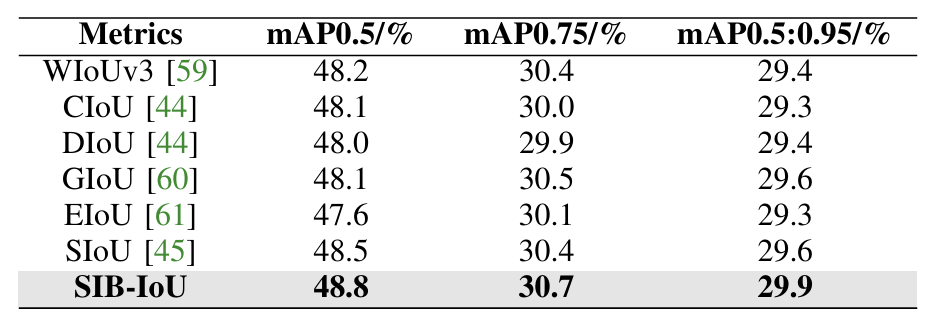
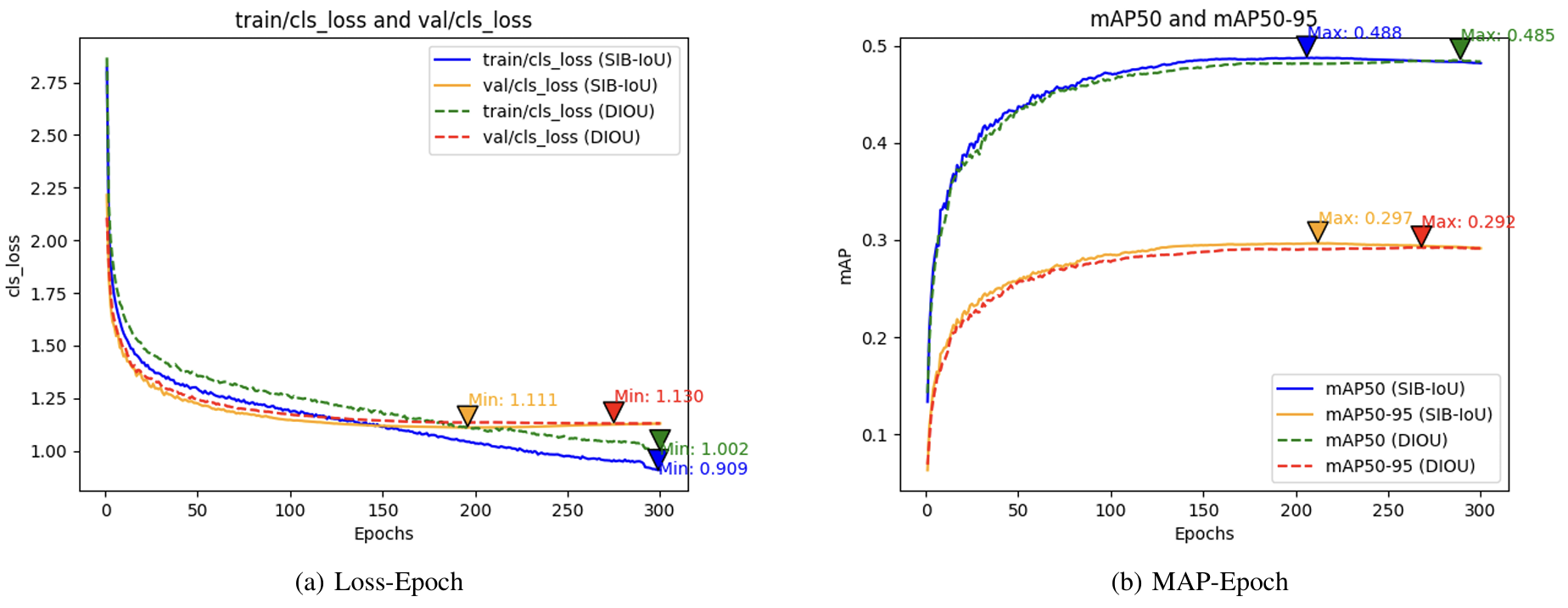
图11. (a)损失-周期和(b)mAP-周期上的检测方法的比较损失-指标曲线分析。我们的SIB-IoU损失表现出卓越的性能,其持续较高的训练速度证明了这一点,突显了其可以增强检测性能。
V. 结论
本文提出了LAM-YOLO,一种专为基于无人机的航空场景设计的目标检测模型。首先,将LAM注意力机制集成到骨干网络和颈部,强调特征图中的关键信息,以帮助模型准确识别和定位目标。此外,在颈部加入了Involution模块,以增强不同层次特征之间的交互。此外,我们采用SIB-IoU损失函数生成不同尺度的辅助边界框,有效提高了模型检测不同尺寸目标的能力。最后,引入了两个额外的辅助检测头,进一步扩展了模型的检测能力。这种方法融合了浅层和深层特征,显著降低了小物体的漏检率,并极大地提高了在高光和低光照条件下的检测精度。实验结果表明,与基线模型相比,LAM-YOLO模型的平均检测精度有显著提高。总体而言,未来的研究应侧重于在有效管理计算资源消耗的同时优化检测精度。
参考文献
1 D. Cao, B. Zhang, X. Zhang, L. Yin, and X. Man, "Optimization methods on dynamic monitoring of mineral reserves for open pit mine based on uav oblique photogrammetry," Measurement, vol. 207, p. 112364, 2023.
2 W. Sun, L. Dai, X. Zhang, P. Chang, and X. He, "Rsod: Real-time small object detection algorithm in uav-based traffic monitoring," Applied Intelligence, pp. 1-16, 2022.
3 J.G.A. Barbedo, "A review on the use of unmanned aerial vehicles and imaging sensors for monitoring and assessing plant stresses," Drones, vol. 3, no. 2, p. 40, 2019.
4 Y. Dai, M. Xiao, Y. Zhu, H. Wang, K. Guo, and J. Yang, "Background semantics matter: Cross-task feature exchange network for clustered infrared small target detection with sky-annotated dataset," arXiv preprint arXiv:2407.20078, 2024.
5 C. Hu, Y. Huang, K. Li, L. Zhang, Y. Zhu, Y. Peng, T. Pu, and Z. Peng, "Gradient is all you need: Gradient-based attention fusion for infrared small target detection," arXiv preprint arXiv:2409.19599, 2024.
6 Y. Xu, Y. Zhu, and Z. Chen, "Research on lung medical image based on convolution neural network algorithm," in Journal of Physics: Conference Series, vol. 1802, no. 3. IOP Publishing, 2021, p. 032111.
7 X. Chen, H. Jiang, H. Zheng, J. Yang, R. Liang, D. Xiang, H. Cheng, and Z. Jiang, "Det-yolo: An innovative high-performance model for detecting military aircraft in remote sensing images," IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024.
8 G. Wang, Y. Chen, P. An, H. Hong, J. Hu, and T. Huang, "Uav-yolov8: A small-object-detection model based on improved yolov8 for uav aerial photography scenarios," Sensors, vol. 23, no. 16, p. 7190, 2023.
9 S. Xu, X. Chen, H. Li, T. Liu, Z. Chen, H. Gao, and Y. Zhang, "Airborne small target detection method based on multi-modal and adaptive feature fusion," IEEE Transactions on Geoscience and Remote Sensing, 2024.
10 J. Hu, L. Shen, and G. Sun, "Squeeze-and-excitation networks," in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 7132-7141.
11 W. Wang, E. Xie, X. Li, D.-P. Fan, K. Song, D. Liang, T. Lu, P. Luo, and L. Shao, "Pyramid vision transformer: A versatile backbone for dense prediction without convolutions," in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 568-578.
12 S. Ren, K. He, R. Girshick, and J. Sun, "Faster r-cnn: Towards real-time object detection with region proposal networks," IEEE transactions on pattern analysis and machine intelligence, vol. 39, no. 6, pp. 1137-1149, 2016.
13 Y. Jiang, X. Zhu, X. Wang, S. Yang, W. Li, H. Wang, P. Fu, and Z. Luo, "R2cnn: Rotational region cnn for orientation robust scene text detection," arXiv preprint arXiv:1706.09579, 2017.
14 J. Li, Y. Tian, Y. Xu, X. Hu, Z. Zhang, H. Wang, and Y. Xiao, "Mm-rcnn: Toward few-shot object detection in remote sensing images with meta memory," IEEE Transactions on Geoscience and Remote Sensing, vol. 60, pp. 1-14, 2022.
15 S. A. S. M. S, Y. Chen, Y. K. Xie, and et al., "Msa r-cnn: A comprehensive approach to remote sensing object detection and scene understanding," Expert Systems with Applications, vol. 241, p. 122788, 2024.
16 K. Duan, S. Bai, L. Xie, H. Qi, Q. Huang, and Q. Tian, "Centernet: Keypoint triplets for object detection," in Proceedings of the IEEE/CVF international conference on computer vision, 2019, pp. 6569-6578.
17 S. Xie, M. Zhou, C. Wang, and S. Huang, "Csppartial-yolo: A lightweight yolo-based method for typical objects detection in remote sensing images," IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 17, pp. 388-399, 2024.
18 J. He, Y. Cheng, W. Wang, Y. Gu, Y. Wang, W. Zhang, A. Shankar, S. Selvarajan, and S.A.P. Kumar, "Ec-yolox: A deep-learning algorithm for floating objects detection in ground images of complex water environments," IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 17, pp. 7359-7370, 2024.
19 H. Yi, B. Liu, B. Zhao, and E. Liu, "Small object detection algorithm based on improved yolov8 for remote sensing," IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, vol. 17, pp. 1734-1747, 2024.
20 C.-Y. Wang, A. Bochkovskiy, and H.-Y. M. Liao, "Yolov7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors," in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2023, pp. 7464-7475.
21 X. Zhu, S. Lyu, X. Wang, and Q. Zhao, "Tph-yolov5: Improved yolov5 based on transformer prediction head for object detection on drone-captured scenarios," in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 2778-2788.
22 Y. Zhu, Y. Ma, F. Fan, J. Huang, K. Wu, and G. Wang, "Towards accurate infrared small target detection via edge-aware gated transformer," IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2024.
23 A. Dosovitskiy, "An image is Worth 16x16 words: Transformers for image recognition at scale," arXiv preprint arXiv:2010.11929, 2020.
24 Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, S. Lin, and B. Guo, "Swin transformer: Hierarchical vision transformer using shifted windows," in Proceedings of the IEEE/CVF international conference on computer vision, 2021, pp. 10012-10022.
25 N. Carion, F. Massa, G. Synnaeve, N. Usunier, A. Kirillov, and S. Zagoruyko, "End-to-end object detection with transformers," in European conference on computer vision. Springer, 2020, pp. 213-229.
26 Y. Zeng, Y. Chen, X. Yang, Q. Li, and J. Yan, "Ars-detr: Aspect ratio-sensitive detection transformer for aerial oriented object detection," IEEE Transactions on Geoscience and Remote Sensing, vol. 62, pp. 1-15, 2024.
27 Y. Yan and K. Niu, "Improved dn-detr for safety helmet wearing detection," in 2023 5th International Conference on Frontiers Technology of Information and Computer (ICFTIC), 2023, pp. 874-877.
28 H. Yin and L. Chen, "Enhanced road vehicle object detection based on improved deformable detr," in 2024 5th International Seminar on Artificial Intelligence, Networking and Information Technology (AINIT), 2024, pp. 2227-2230.
29 J. Redmon, "You only look once: Unified, real-time object detection," in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016.
30 J. Redmon and A. Farhadi, "Yolov3: An incremental improvement," arXiv preprint arXiv:1804.02767, 2018.
31 A. Bochkovskiy, C.-Y. Wang, and H.-Y. M. Liao, "Yolov4: Optimal speed and accuracy of object detection," arXiv preprint arXiv:2004.10934, 2020.
32 C. Li, L. Li, H. Jiang, K. Weng, Y. Geng, L. Li, Z. Ke, Q. Li, M. Cheng, W. Nie et al., "Yolov6: A single-stage object detection framework for industrial applications," arXiv preprint arXiv:2209.02976, 2022.
33 H. Lou, X. Duan, J. Guo, H. Liu, J. Gu, L. Bi, and H. Chen, "Dc-yolov8: small-size object detection algorithm based on camera sensor," Electronics, vol. 12, no. 10, p. 2323, 2023.
34 Y. Zhu, S. Tang, Y. Jiang, and R. Kang, "Dau-net: A regression cell counting method," in ISCTT 2021; 6th International Conference on Information Science, Computer Technology and Transportation. VDE, 2021, pp. 1-6.
35 Q. Wang, B. Wu, P. Zhu, P. Li, W. Zuo, and Q. Hu, "Eca-net: Efficient channel attention for deep convolutional neural networks," in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 11534-11542.
36 S. Woo, J. Park, J.-Y. Lee, and I. S. Kweon, "Cbam: Convolutional block attention module," in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 3-19.
37 H. Liu, F. Jin, H. Zeng, H. Pu, and B. Fan, "Image enhancement guided object detection in visually degraded scenes," IEEE transactions on neural networks and learning systems, 2023.
38 D. Li, J. Hu, C. Wang, X. Li, Q. She, L. Zhu, T. Zhang, and Q. Chen, "Involution: Inverting the inherence of convolution for visual recognition," in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2021, pp. 12321-12330.
39 T.-Y. Lin, P. Dollar, R. Girshick, K. He, B. Hariharan, and S. Belongie, "Feature pyramid networks for object detection," in Proceedings of the IEEE conference on computer vision and pattern recognition, 2017, pp. 2117-2125.
40 C. Y. Wang, H. Y. M. Liao, Y. H. Wu et al., "Cspnet: A new backbone that can enhance learning capability of cnn," in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 2020, pp. 390-391.
41 S. Liu, L. Qi, H. Qin, and et al., "Path aggregation network for instance segmentation," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 8759-8768.
42 W. Shi et al., "Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network," in Proceedings of the IEEE conference on computer vision and pattern recognition, 2016.
43 X. Li, W. Wang, L. Wu, and et al., "Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection," in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 21002-21012.
44 Z. Zheng, P. Wang, W. Liu, and et al., "Distance-iou loss: Faster and better learning for bounding box regression," in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 34, no. 07, 2020, pp. 12993-13000.
45 Z. Gevorgyan, "Siou loss: More powerful learning for bounding box regression," arXiv preprint arXiv:2205.12740, 2022.
46 C. Feng, Y. Zhong, Y. Gao, and et al., "Tood: Task-aligned one-stage object detection," in 2021 IEEE/CVF International Conference on Computer Vision (ICCV). IEEE Computer Society, 2021, pp. 3490-3499.
47 G. Zheng, L. Songtao, W. Feng, and et al., "Yolox: Exceeding yolo series in 2021," arXiv preprint arXiv:2107.08430, 2021.
48 K. Duan, S. Bai, L. Xie, and et al., "Centernet: Keypoint triplets for object detection," in Proceedings of the IEEE/CVF International Conference on Computer Vision, 2019, pp. 6569-6578.
49 C. Y. Wang, I. H. Yeh, and H. Y. M. Liao, "Yolov9: Learning what you want to learn using programmable gradient information," arXiv preprint arXiv:2402.13616, 2024.
50 A. Wang, H. Chen, L. Liu, and et al., "Yolov10: Real-time end-to-end object detection," arXiv preprint arXiv:2405.14458, 2024.
51 T. Lin, "Focal loss for dense object detection," arXiv preprint arXiv:1708.02002, 2017.
52 X. Li, W. Wang, L. Wu, and et al., "Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection," in Advances in Neural Information Processing Systems, vol. 33, 2020, pp. 21002-21012.
53 C. Lyu, W. Zhang, H. Huang, and et al., "Rtmdet: An empirical study of designing real-time object detectors," arXiv preprint arXiv:2212.07784, 2022.
54 S. Ren, "Faster r-cnn: Towards real-time object detection with region proposal networks," arXiv preprint arXiv:1506.01497, 2015.
55 Z. Cai and N. Vasconcelos, "Cascade r-cnn: Delving into high quality object detection," in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 2018, pp. 6154-6162.
56 X. Lu, B. Li, Y. Yue, Q. Li, and J. Yan, "Grid r-cnn," in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019, pp. 7355-7364.
57 N. Carion, F. Massa, G. Synnaeve, and et al., "End-to-end object detection with transformers," in European Conference on Computer Vision. Springer International Publishing, 2020, pp. 213-229.
58 S. Liu, F. Li, H. Zhang, and et al., "Dab-detr: Dynamic anchor boxes are better queries for detr," arXiv preprint arXiv:2201.12329, 2022.
59 Z. Tong, Y. Chen, Z. Xu, and et al., "Wise-iou: Bounding box regression loss with dynamic focusing mechanism," arXiv preprint arXiv:2301.10051, 2023.
60 H. Rezatofighi, N. Tsoi, J. Y. Gwak, and et al., "Generalized intersection over union: A metric and a loss for bounding box regression," in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2019, pp. 658-666.
61 Y. F. Zhang, W. Ren, Z. Zhang, and et al., "Focal and efficient iou loss for accurate bounding box regression," Neurocomputing, vol. 506, pp. 146-157, 2022.