引言
在过去几年里,人工智能的快速发展让我们看到了前所未有的创新速度。从传统机器学习,到如今的大型语言模型,技术的每一次跃迁,都在悄然改变着我们开发、生产和使用技术的方式。然而,这些突破背后往往依赖着强大的计算资源,尤其是GPU。对于需要大规模计算或实时推理的AI应用来说,GPU几乎是必不可少的加速引擎。然而,光有GPU远远不够。如何在云原生环境中调度GPU,并且让Kubernetes正确识别它们?如何让大模型能够稳定运行?对于很多开发者和运维工程师来说,这些都是实实在在的挑战。
好消息是,利用KubeSphere和Kubernetes的结合,使我们能够在openEuler上以非常云原生的方式来部署GPU应用。结合Ollama也使得在企业或本地环境中运行LLM变得更加轻松。接下来就跟我一起从零开始完成这样一个过程:
为Kubernetes集群扩容GPU节点 → 配置GPU Operator→ 在KubeSphere上部署Ollama → 拉取模型并验证GPU推理是否可用。
前期准备
让我们先从硬件入手。并不是所有人都有足够预算或条件获取 A100、H100 这样的旗舰GPU,因此实验环境中,我们使用了两张较旧但仍能工作的显卡:
Tesla M40(24GB):显存大、适合加载中等模型,但算力不算强。
Tesla P100(16GB):显存稍小,但单精度性能比M40强得多。
尽管算不上高端,但对于大模型轻量推理场景来说完全够用,也便于演示 GPU 调度的机制。
接下来在每个节点运行openEuler 22.03 LTS SP3。这是一个非常稳定的企业级发行版,对云原生场景有良好支持。在所有操作之前,务必注意对任何拥有外网的节点,都必须先完成系统更新,再重启一次。这样能避免后续依赖安装失败或出现兼容性问题。
使用KubeKey为集群扩容
KubeKey 是一个专为 Kubernetes/KubeSphere 设计的集群部署工具,它的最大优势之一就是扩容和缩容非常方便。扩容 GPU 节点也一样,只需要两步:
首先修改集群配置文件,之后执行add nodes命令。
首先我们需要修改KubeKey的集群配置文件。在Control-1节点中,找到之前部署集群时使用的YAML文件,在其中把两台 GPU 节点添加到spec.hosts列表,之后在spec.roleGroups.worker中加上它们的名称。通过这些修改告诉KubeKey,集群准备要接纳新的node节点。
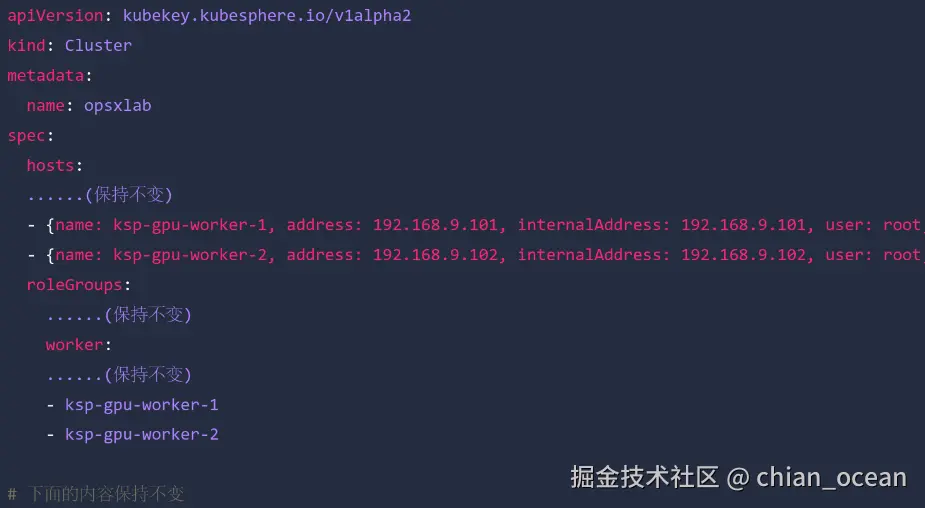
之后使用KubeKey一键扩容。可以先查看一下现有集群结构:
arduino
kubectl get nodes -o wide然后执行扩容命令:
bash
export KKZONE=cn
./kk add nodes -f ksp-v341-v1288.yaml在您执行完KubeKey的扩容命令后,接下来的过程将是全自动且高效的,旨在将新节点无缝整合到您的云原生平台。KubeKey会首先进行细致的环境检查并请求您的确认,一旦您输入"yes"允许继续,安装和整合工作便会迅速展开,其中涉及的关键步骤包括建立安全的SSH连接、验证新节点的系统环境、安装所有必要的Kubernetes组件,以及最关键的,将节点正式注册到现有的集群管理之下。整个自动化流程通常不到十分钟就能圆满完成。当安装和注册过程成功结束后,集群中的节点总数会从原先的6个增加到8个。
验证扩容是否成功
打开你的 Control-1 节点,访问:
arduino
http://{control-plane-ip}:30880进入集群管理界面,你就能看到所有节点一目了然,GPU节点也将自动显示其资源情况。
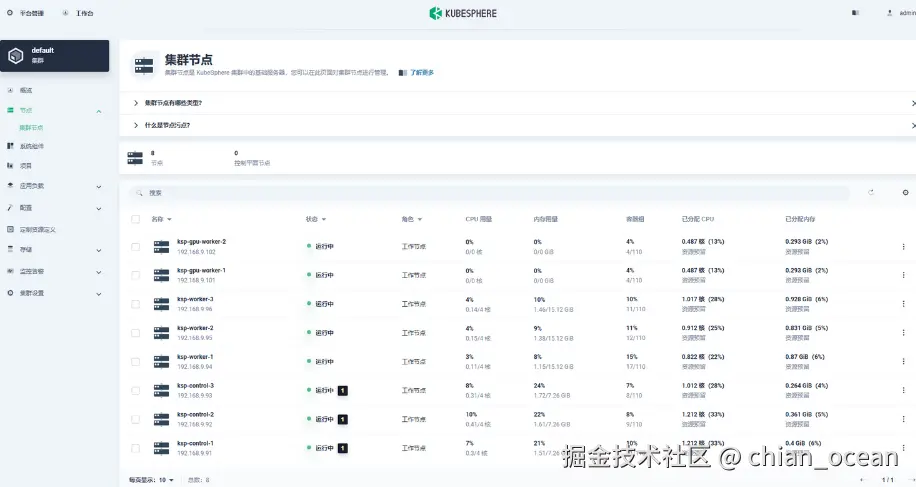
之后通过命令行再次确认:
arduino
kubectl get nodes -o wide你会看到新的GPU节点处于"Ready"状态,且显示其 IP、内核版本、操作系统信息等。至此,GPU节点已经正式加入Kubernetes。

安装NVIDIA GPU Operator
光有GPU还不够,Kubernetes并不会自动识别GPU。为了让系统能够调度GPU,我们需要使用NVIDIA GPU Operator。这个Operator在集群中扮演着至关重要的角色,其核心工作是实现对GPU资源的自动化和深度管理。它首先会全面地识别节点中的GPU硬件,确保系统正确地掌握可用的加速计算能力。随后,它会提供并部署关键的GPU device plugin,这是实现容器化应用访问GPU所必需的桥梁。此外,该Operator还负责持续地管理GPU的监控、驱动程序状态以及节点特性,确保这些组件始终处于最佳运行状态。最后,它会确保这些宝贵的计算资源正确地Kubernetes注册为GPU资源,从而让用户能够通过标准的Kubernetes API机制来请求和调度这些硬件加速能力。
GPU Operator 虽然能自动安装驱动,但openEuler不支持自动驱动安装,因此必须提前在两台GPU节点上手动安装。先从官方NVIDIA显卡驱动下载地址下载驱动
执行下面的命令,之后重启。
arduino
chmod u+x NVIDIA-Linux-x86_64-550.54.15.run
./NVIDIA-Linux-x86_64-550.54.15.run服务器重启完成后,再次执行安装命令,会自动执行构建、安装的任务。
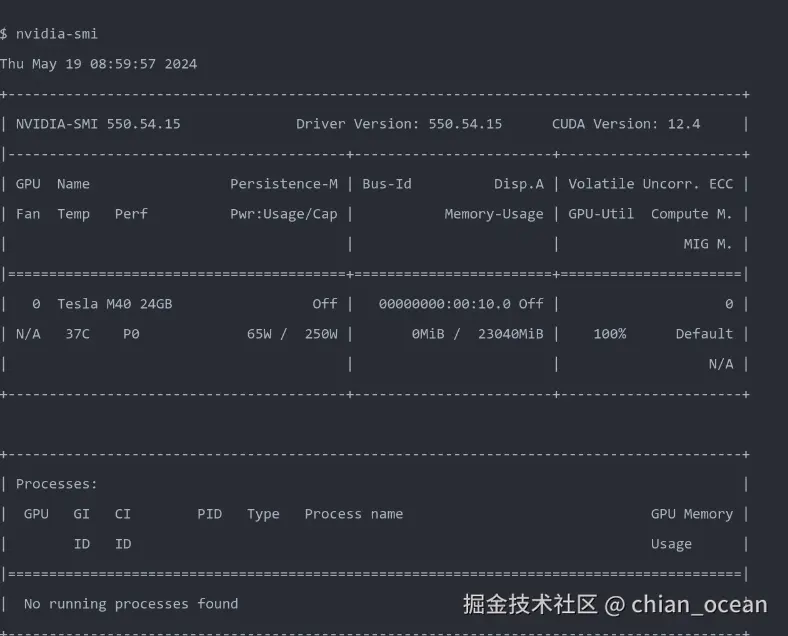
驱动安装成功后,再继续下一步。
检查是否启用了NFD
执行下面的代码:
kubectl get nodes -o json | jq '.items\[\].metadata.labels | keys | any(startswith("feature.node.kubernetes.io"))'
如果返回true,说明当前集群已经有节点特性标签,不需要Operator再部署NFD。
使用Helm安装GPU Operator
添加 NVIDIA 的 Helm 仓库:
csharp
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo update安装GPU Operator:
arduino
helm install -n gpu-operator --create-namespace gpu-operator nvidia/gpu-operator --set driver.enabled=false安装过程可能会拉取多个镜像,耐心等待。
验证GPU是否被识别
查看Operator的Pod状态:
arduino
kubectl get pods -n gpu-operator查看GPU资源注册情况:
perl
kubectl describe node ksp-gpu-worker-1 | grep "^Capacity" -A 7如果看到:
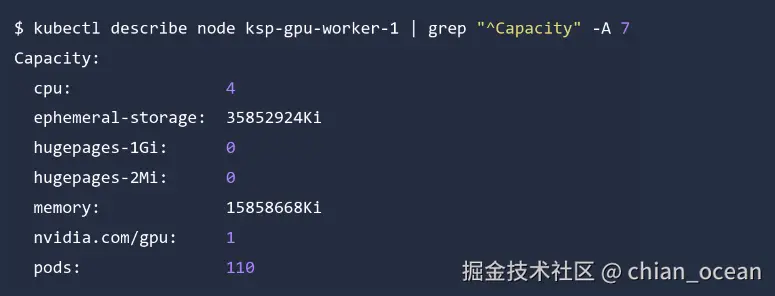
恭喜你!GPU 已成功被Kubernetes注册。
测试一下
尝试在Pod中运行NVIDIA-SMI,只需创建一个使用CUDA镜像的Pod
kubectl apply -f cuda-ubuntu.yaml从结果中可以看到 pod 创建在了 ksp-gpu-worker-2 节点。

然后查看日志:
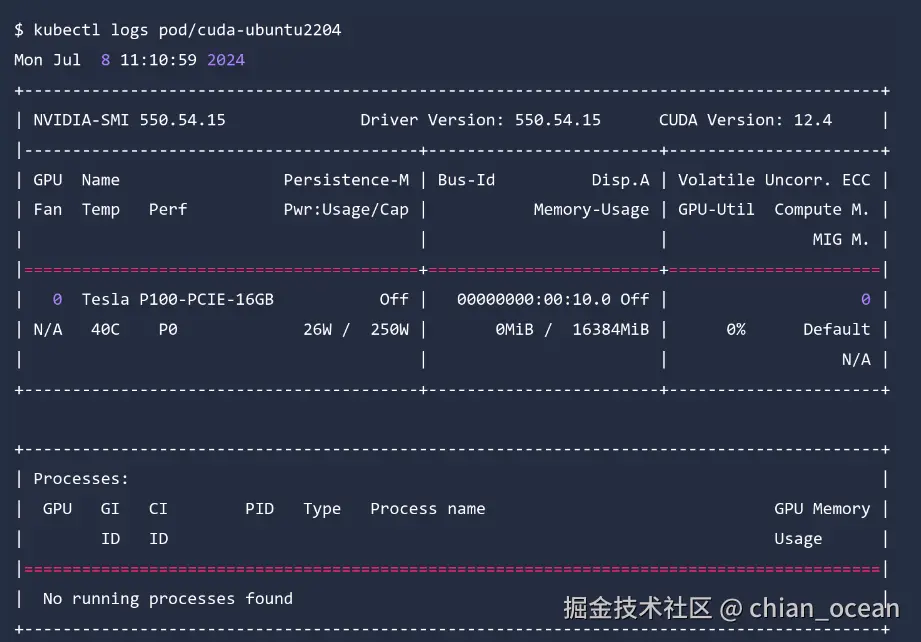
bash
kubectl logs pod/cuda-ubuntu2204如果能看到熟悉的NVIDIA-SMI输出,就说明GPU能够在容器中正常使用。
在KubeSphere中部署Ollama
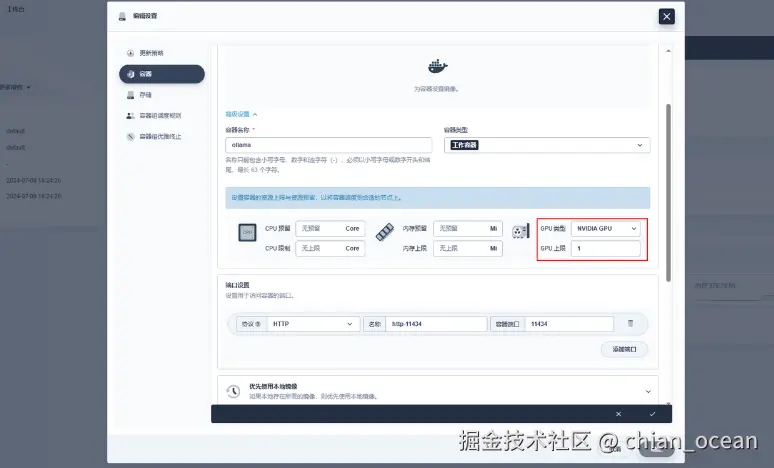
接下来我们要部署Ollama。首先需要准备部署文件,Yaml文件中应该包括:Deployment、Service、HostPath数据目录、GPU资源声明。
yaml
kind: Deployment
apiVersion: apps/v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
replicas: 1
selector:
matchLabels:
app: ollama
template:
metadata:
labels:
app: ollama
spec:
volumes:
- name: ollama-models
hostPath:
path: /data/openebs/local/ollama
type: ''
- name: host-time
hostPath:
path: /etc/localtime
type: ''
containers:
- name: ollama
image: 'ollama/ollama:latest'
ports:
- name: http-11434
containerPort: 11434
protocol: TCP
resources:
limits:
nvidia.com/gpu: '1'
requests:
nvidia.com/gpu: '1'
volumeMounts:
- name: ollama-models
mountPath: /root/.ollama
- name: host-time
readOnly: true
mountPath: /etc/localtime
imagePullPolicy: IfNotPresent
restartPolicy: Always
---
kind: Service
apiVersion: v1
metadata:
name: ollama
namespace: default
labels:
app: ollama
spec:
ports:
- name: http-11434
protocol: TCP
port: 11434
targetPort: 11434
nodePort: 31434
selector:
app: ollama
type: NodePort之后执行:
kubectl apply -f deploy-ollama.yaml等待Pod启动后,使用:
xml
kubectl logs <pod-name>你会看到 GPU 已被成功检测。
拉取大模型
首先进入容器下载模型:
sql
kubectl exec -it <ollama-pod> -- ollama pull qwen2:1.5b几分钟后,模型文件就会下载到hostPath目录中。

测试推理
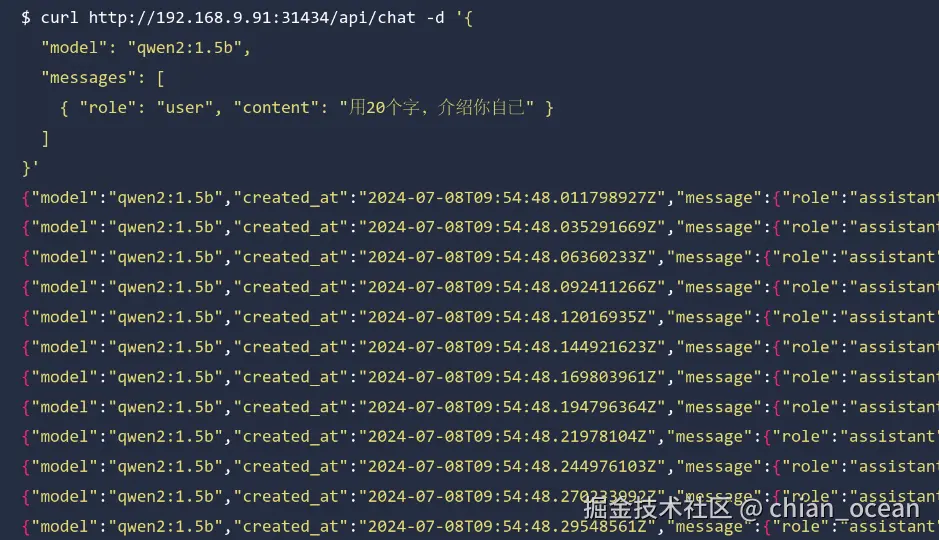
我们来使用 curl 发送一个请求:
vbnet
curl http://<node-ip>:31434/api/chat -d '{
"model": "qwen2:1.5b",
"messages": [
{ "role": "user", "content": "Introduce yourself in 20 words." }
]
}'如果能得到AI回复,那就意味着Ollama和GPU调度都成功了。
查看GPU调度情况
查看节点资源:
perl
kubectl describe node ksp-gpu-worker-1 | grep "Allocated resources" -A 9可以看到Worker节点已分配的GPU资源

之后查看GPU实时使用:
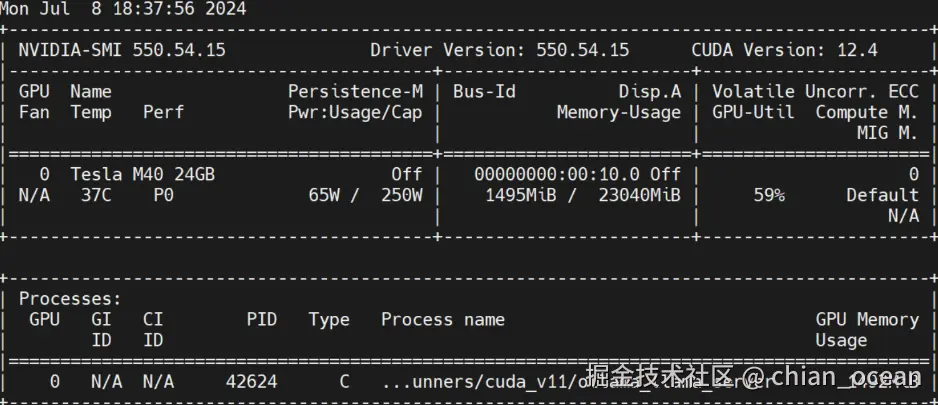
nvidia-smi -l你会看到Ollama进程正占用GPU显存并进行推理计算。
总结
通过上面的步骤,我们已经成功建立了一条完整、高效的GPU云原生AI管理链路。它始于扩容GPU节点进入Kubernetes,这一步为AI工作负载奠定了硬件基础。随后,安装了GPU Operator,确保Kubernetes能够识别并管理这些加速资源,这是实现容器与硬件交互的关键。在资源就绪后,我们测试了GPU在容器中的运行状态,确认环境的稳定性与可用性,紧接着部署了Ollama这一便捷的工具,并最终成功地拉取模型并使用GPU进行了推理。通过这套标准化的流程,我们能够搭建起一个可用、可扩展、支持大模型部署的GPU云原生环境。
如果您正在寻找面向未来的开源操作系统,不妨看看DistroWatch 榜单中快速上升的 openEuler: distrowatch.com/table-mobil... 发行版。 openEuler官网:www.openeuler.openatom.cn/zh/