在后端开发中,我们常遇到一种场景:SQL 在本地开发环境(只有几百条数据)跑得飞快,一上线遇到生产环境(百万/千万级数据)就直接卡死甚至拖垮数据库。
核心原因在于"空表陷阱":当表数据量过少时,MySQL 优化器往往会直接选择全表扫描(Full Table Scan),因为此时扫描全表的成本比走索引(Index Dive + 回表)更低。这导致我们在开发阶段无法通过 EXPLAIN 发现潜在的慢查询(Slow SQL)。
要解决这个问题,必须在开发/测试环境构建"等量级"甚至"超量级"的仿真数据。
传统做法是写脚本或存储过程循环插入,但存在单线程慢、容易锁表、代码维护麻烦等问题。本文分享一个在 SQLynx 中利用内置功能,通过配置事务与批量提交策略,快速生成百万级压测数据的技巧。
01 场景准备
假设我们有一张 t_orders 表,这是最常见的需要做性能优化的场景。
sql
CREATE TABLE `t_orders` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL COMMENT '用户ID',
`order_no` varchar(32) NOT NULL COMMENT '订单号',
`amount` decimal(10,2) NOT NULL COMMENT '金额',
`status` int(11) NOT NULL DEFAULT '0' COMMENT '状态:0-待付,1-已付,2-发货,3-完成',
`create_time` datetime NOT NULL DEFAULT CURRENT_TIMESTAMP,
PRIMARY KEY (`id`),
KEY `idx_user_time` (`user_id`,`create_time`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;我们的目标是:往这张表里快速灌入 100 万条数据,且数据分布要尽量符合真实业务场景(有离散度),以验证 idx_user_time 索引的有效性。
02 测试数据配置
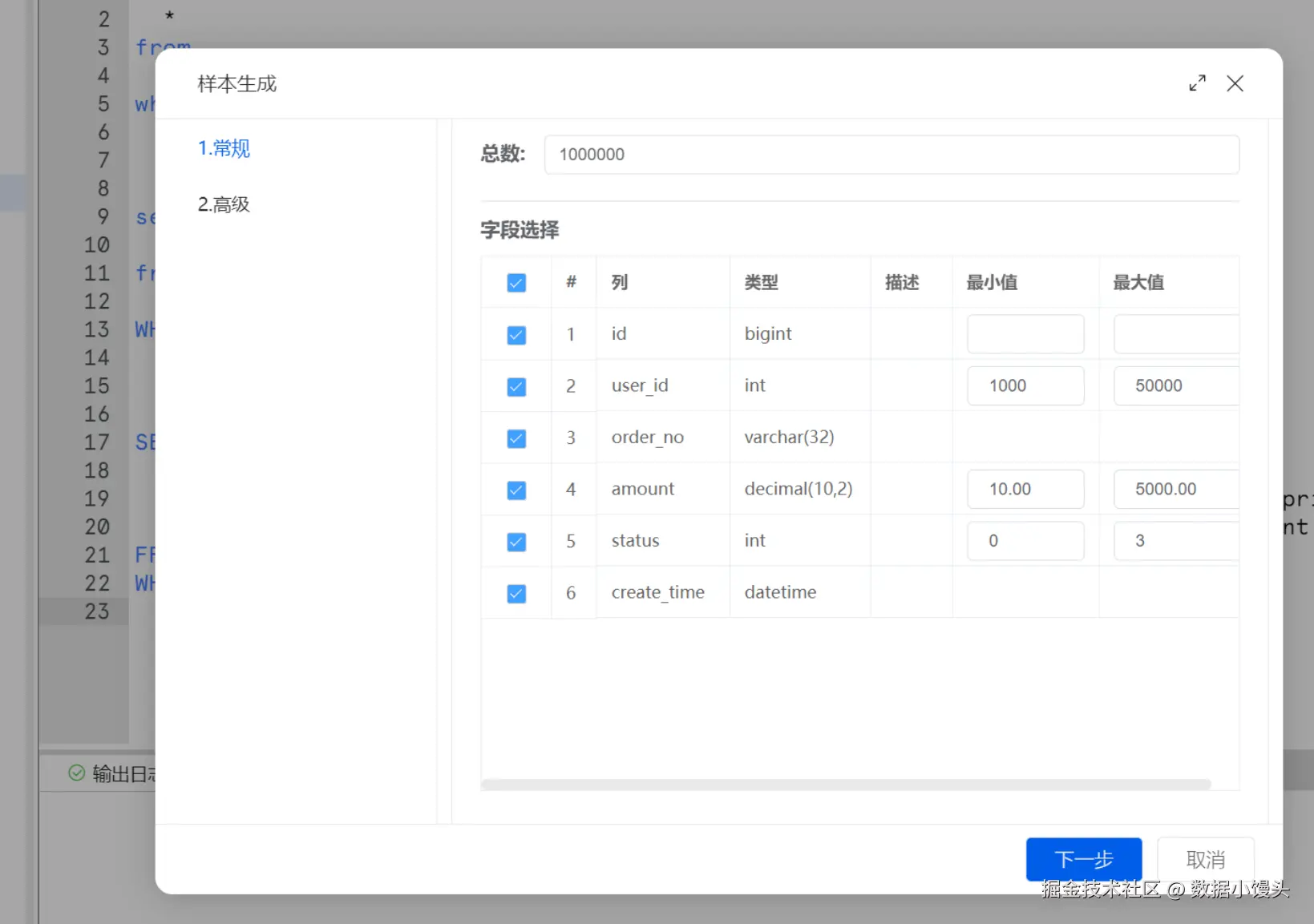
在 SQLynx 中选中表 t_orders,右键选择 "生成测试数据"。

这里不需要写代码,为了让测试结果真实,需要在弹窗中针对字段类型做如下配置:
-
user_id(模拟高离散度):
-
设置生成模式为"随机整数"。
-
范围设为 1000 - 50000。
-
技术解读: 模拟 5 万个不同用户的下单行为,测试索引的选择性。
-
amount(模拟金额):
-
设置生成模式为"随机浮点数"。
-
范围 10.00 - 5000.00。
-
status(模拟低离散度):
-
设置生成模式为"随机整数"。
-
范围 0 - 3。
-
技术解读: 状态字段通常基数很小,用于测试索引失效的边界情况。
03 事务与批量大小
这是从"慢速插入"到"极速写入"的关键一步。
如果在循环中每插入一条数据就 Commit 一次,100 万次网络 IO 和 100 万次 Binlog/Redo Log 刷盘会让写入速度极慢。
在配置界面,我们需要调整写入策略:
- 执行模式: 选择 "事务执行"。
- 批量大小: 可从 1000 开始逐步递增,测试最适合自己环境的最佳数值(如2000-5000的区间值)。
为什么要这样设?
- 减少 IO 开销: 设置 Batch=1000,意味着每 1000 条 INSERT 语句合并为一个网络包发送,且只进行一次磁盘刷盘。
- 避免长事务: 避免直接设置数值过大,如100000。过大的 Batch 会导致 Undo Log 膨胀,甚至可能触碰 MySQL 的 max_allowed_packet 限制导致报错。
- 模式选择: 选择 "追加数据"。

点击"确认",进入任务中心查看进度。通常在内网环境下,百万级数据的生成在几十秒~分钟级可完成。

04 验证效果:从 ALL 到 ref
数据到位后,我们可以进行测试。
测试 SQL: 查询某个用户最近的订单。
sql
SELECT * FROM t_orders WHERE user_id = 10086 ORDER BY create_time DESC LIMIT 10;场景 A:数据量 100 条(模拟开发环境)
执行 EXPLAIN,你可能会看到 type: ALL(全表扫描)。
- 现象: 耗时 0.00ms。
- 隐患: 开发者误以为性能完美。实际上是因为数据量太小,MySQL 优化器认为全表扫描成本低于读取索引树,因此主动放弃了索引。这掩盖了潜在的性能问题。
场景 B:数据量 100 万条(测试数据生成后)
再次执行 EXPLAIN。

-
type: ref:全表扫描(ALL)消失了,key 字段显示为 idx_user_time,说明索引被命中。
-
rows: 21:我们设置的用户 ID 范围是 1000-50000(基数约 4.9 万)。
-
验证: 总行数 100 万 / 用户基数 4.9 万 ≈ 20.4 行。
-
结论: rows: 21 与理论值一致。这证明了生成的随机数据具有均匀分布特性,没有出现数据倾斜。这种高离散度的数据真实还原了生产环境,验证了索引的高选择性。
05 总结
"造数"是后端开发和 DBA 的一项基础设施能力。
利用 SQLynx 的"生成测试数据"功能,可替代手写脚本的繁琐过程。
对于技术人员来说,在实际测试环境中,需要面对百万级、千万级数据的压测,采用便捷稳定的工具可有效帮助工作效率提升,是避免线上故障的最低成本路径。