目录
[一、AI 模型基础认知:智能的 "函数本质"](#一、AI 模型基础认知:智能的 “函数本质”)
[1.1 什么是 AI 模型?](#1.1 什么是 AI 模型?)
[1.2 模型如何通过 "训练" 变得智能?](#1.2 模型如何通过 “训练” 变得智能?)
[1.3 大模型的 "四大核心优势"](#1.3 大模型的 “四大核心优势”)
[(3)参数规模:从 "亿级" 到 "万亿级"](#(3)参数规模:从 “亿级” 到 “万亿级”)
[(4)算力需求:"集群级" 资源投入](#(4)算力需求:“集群级” 资源投入)
[二、AI 模型核心技术架构:从经典到前沿](#二、AI 模型核心技术架构:从经典到前沿)
[2.1 传统机器学习模型:智能的 "启蒙阶段"](#2.1 传统机器学习模型:智能的 “启蒙阶段”)
[2.2 深度学习基础模型:智能的 "进化引擎"](#2.2 深度学习基础模型:智能的 “进化引擎”)
[(2.2)循环神经网络(RNN)与 LSTM:序列数据专家](#(2.2)循环神经网络(RNN)与 LSTM:序列数据专家)
[2.3 Transformer 架构:大模型的 "通用底座"](#2.3 Transformer 架构:大模型的 “通用底座”)
[(2)Transformer 完整架构](#(2)Transformer 完整架构)
[三、2025 年主流 AI 模型实战案例](#三、2025 年主流 AI 模型实战案例)
[3.1 计算机视觉:医学影像智能诊断系统](#3.1 计算机视觉:医学影像智能诊断系统)
[3.2 自然语言处理:教育领域自适应学习系统](#3.2 自然语言处理:教育领域自适应学习系统)
[3.3 多模态模型:通义万相内容创作平台](#3.3 多模态模型:通义万相内容创作平台)
[四、AI 模型产业落地:2025 年六大核心领域](#四、AI 模型产业落地:2025 年六大核心领域)
[4.1 教育:从 "标准化" 到 "个性化"](#4.1 教育:从 “标准化” 到 “个性化”)
[4.2 医疗:全周期赋能医疗体系](#4.2 医疗:全周期赋能医疗体系)
[4.3 金融:智能风险防控体系](#4.3 金融:智能风险防控体系)
[4.4 制造:工业质检与优化](#4.4 制造:工业质检与优化)
[4.5 内容创作:AIGC 全场景应用](#4.5 内容创作:AIGC 全场景应用)
[4.6 电商:智能导购与供应链优化](#4.6 电商:智能导购与供应链优化)
[五、AI 模型发展趋势与挑战](#五、AI 模型发展趋势与挑战)
[5.1 技术发展三大趋势](#5.1 技术发展三大趋势)
[5.2 行业面临四大挑战](#5.2 行业面临四大挑战)
[5.3 普通人的 AI 学习路径](#5.3 普通人的 AI 学习路径)
[六、总结:AI 模型重塑未来](#六、总结:AI 模型重塑未来)
一、AI 模型基础认知:智能的 "函数本质"
1.1 什么是 AI 模型?
如果把 AI 的核心能力比作一台精密的 "智能处理器",那模型就是这台处理器的实体形态。它基于神经网络搭建而成,本质是一套经过优化的复杂函数系统,最经典的表达可简化为y=f(x) 。这里的 "x" 涵盖文本、图片、语音等各类输入信息,"f" 是模型通过内部结构对输入进行分析运算的核心逻辑,"y" 则是问题答案、识别结果或生成内容等输出。
简单来说,模型如同训练有素的 "专家":给它 "问题"(输入 x),就能给出专业 "答案"(输出 y),而神经网络就是支撑其 "思考" 的 "大脑架构"。2025 年的 AI 模型已实现从 "单一任务响应" 到 "多场景决策" 的跨越,例如阿里云通义千问能同时处理文字创作、图像分析与数据计算,正是函数系统复杂度提升的体现。
1.2 模型如何通过 "训练" 变得智能?
刚搭建的模型如同 "空白试卷",虽有完整结构却无处理能力,需通过 "训练" 逐步掌握分析决策能力。训练核心逻辑是:持续输入标注好的 "样本数据",对比模型输出与真实答案的差异,不断调整神经网络中神经元的参数,最终使输出偏差降至最低。
以训练 "猫识别模型" 为例:输入数千张标注 "是猫 / 不是猫" 的图片,模型初期可能将狗误判为猫,系统会计算 "误判偏差" 并反向调整参数;经过数万次迭代,模型逐渐掌握尖耳朵、长胡须等核心特征,最终实现 99% 以上的识别准确率。
从技术层面看,神经网络通常分为多层,每层包含大量神经元,整体类似 "多层嵌套的函数组合"。每个神经元、每一层嵌套函数都是小型 y=f (x) 模块,通过参数协同工作 ------ 如同工厂多条流水线,只有所有环节参数匹配,才能产出合格结果。
1.3 大模型的 "四大核心优势"
当模型规模、数据量、算力需求达到一定量级,能处理更复杂多元任务时,便升级为 "大模型"。它并非简单放大版,而是通过四大突破实现能力质变:
(1)训练数据:量级与广度双突破
大模型的 "智能基础" 来自海量数据。GPT-3 初始训练数据达 45TB,涵盖书籍、网页、论文等,经预处理后仍有 570GB------ 相当于数百万本图书的信息压缩输入。2025 年的大模型更实现多模态跨越:通义万相、文心一言等已能处理文本、图像、视频、语音等混合输入,数据广度直接推动能力升级。
(2)架构规模:深度与复杂度并重
主流大模型均基于 Transformer 架构搭建,核心是 "注意力机制"------ 让模型处理信息时聚焦关键内容(如理解句子时关注主语和宾语)。大模型通过堆叠数十甚至上百层编码器与解码器形成深度结构:GPT-4 层数超 90 层,能捕捉数据中极细微的关联,例如理解多轮对话的上下文逻辑。
(3)参数规模:从 "亿级" 到 "万亿级"
参数是模型的 "记忆单元",普通深度学习模型参数多为百万到千万级,而大模型以 "亿" 为起点:GPT-3 约 1750 亿参数,Llama 2 最高 700 亿,通义万相已迈入 "万亿参数" 行列。庞大参数量让模型能存储更多知识:1750 亿参数的 GPT-3 可写文章、编代码、解数学题,万亿级模型更支持工业级数据分析与多模态创作。
(4)算力需求:"集群级" 资源投入
训练大模型需巨量算力,GPT-3 单次训练需 3.64×10²³ 次浮点运算,依赖数千块 NVIDIA A100 GPU 组成的集群持续工作数周。2025 年万亿级参数模型的算力需求呈指数级增长,国内头部企业已建成 "千卡集群""千卡超算中心" 支撑模型研发。
二、AI 模型核心技术架构:从经典到前沿
2.1 传统机器学习模型:智能的 "启蒙阶段"
(1)逻辑回归:最简单的分类模型
逻辑回归是线性模型的延伸,通过 Sigmoid 函数将线性输出映射到 0,1 区间,实现二分类预测。其核心公式为:
# 逻辑回归核心公式实现(PyTorch)
import torch
import torch.nn.functional as F
def logistic_regression(x, weights, bias):
linear = torch.matmul(x, weights) + bias # 线性计算
return F.sigmoid(linear) # 激活映射应用场景:垃圾邮件识别、信用风险初筛等轻量级任务,2025 年仍在边缘设备中广泛使用。
(2)决策树与随机森林:可解释性强者
决策树通过层层条件判断实现分类 / 回归,随机森林则集成多棵决策树降低过拟合。优势是可解释性强,能清晰展示决策路径,在金融风控、医疗诊断等需 "透明决策" 的场景不可或缺。
2.2 深度学习基础模型:智能的 "进化引擎"
(2.1)卷积神经网络(CNN):图像处理王者
CNN 通过卷积层、池化层提取空间特征,专为图像、视频等网格结构数据设计。以下是 PyTorch 搭建 CNN 实现 MNIST 手写数字识别的完整代码:
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision
import matplotlib.pyplot as plt
# 1. 数据准备
download_mnist = True # 首次运行设为True,后续改为False
train_data = torchvision.datasets.MNIST(
root='./mnist/',
train=True,
transform=torchvision.transforms.ToTensor(),
download=download_mnist
)
test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
# 数据预处理(GPU加速)
with torch.no_grad():
test_x = torch.unsqueeze(test_data.data, dim=1).type(torch.FloatTensor).cuda()/255.
test_y = test_data.targets.cuda()
# 批处理配置
train_loader = Data.DataLoader(
dataset=train_data,
batch_size=50,
shuffle=True,
num_workers=3
)
# 2. 构建CNN网络
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
# 第一个卷积块:Conv2d -> ReLU -> MaxPool2d
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=1, # 输入通道数(灰度图为1)
out_channels=16, # 卷积核数量
kernel_size=5, # 卷积核大小
stride=1, # 步长
padding=2 # 填充(保持尺寸不变)
), # 输出形状:(16, 28, 28)
nn.ReLU(), # 激活函数
nn.MaxPool2d(kernel_size=2) # 池化,输出:(16, 14, 14)
)
# 第二个卷积块
self.conv2 = nn.Sequential(
nn.Conv2d(16, 32, 5, 1, 2), # 输出:(32, 14, 14)
nn.ReLU(),
nn.MaxPool2d(2) # 输出:(32, 7, 7)
)
# 全连接层(分类输出)
self.out = nn.Linear(32 * 7 * 7, 10) # 10个类别
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # 展平:(batch_size, 32*7*7)
output = self.out(x)
return output
# 3. 模型训练配置
cnn = CNN().cuda() # 部署到GPU
optimizer = torch.optim.Adam(cnn.parameters(), lr=0.001) # 优化器
loss_func = nn.CrossEntropyLoss() # 损失函数(多分类)
# 4. 训练过程与可视化
plt.ion() # 实时绘图
plt.figure(figsize=(10,4))
step_list, loss_list, acc_list = [], [], []
for epoch in range(3): # 训练3轮
for step, (b_x, b_y) in enumerate(train_loader):
b_x, b_y = b_x.cuda(), b_y.cuda() # 数据入GPU
output = cnn(b_x) # 模型输出
loss = loss_func(output, b_y) # 计算损失
optimizer.zero_grad() # 梯度清零
loss.backward() # 反向传播
optimizer.step() # 参数更新
# 每100步评估一次
if step % 100 == 0:
test_output = cnn(test_x[:1000])
pred_y = torch.max(test_output, 1)[1].cpu().numpy()
true_y = test_y[:1000].cpu().numpy()
accuracy = float((pred_y == true_y).astype(int).sum()) / float(true_y.size)
# 记录数据
step_list.append(step + epoch*len(train_loader))
loss_list.append(loss.item())
acc_list.append(accuracy)
# 绘制图表
plt.clf()
plt.subplot(121)
plt.plot(step_list, loss_list, 'r-', linewidth=1)
plt.title('Training Loss')
plt.xlabel('Step')
plt.ylabel('Loss')
plt.subplot(122)
plt.plot(step_list, acc_list, 'b-', linewidth=1)
plt.title('Test Accuracy')
plt.xlabel('Step')
plt.ylabel('Accuracy')
plt.pause(0.1)
plt.ioff()
plt.savefig('cnn_training_curve.png') # 保存训练曲线
# 5. 模型测试
test_output = cnn(test_x[:10])
pred_y = torch.max(test_output, 1)[1].cpu().numpy()
print('预测结果:', pred_y)
print('真实结果:', test_y[:10].cpu().numpy())CNN 核心优势:参数共享减少计算量,局部连接捕捉空间特征。2025 年已升级至 "动态卷积""注意力卷积",在医学影像诊断中能识别毫米级肺结节,准确率达 95% 以上。
(2.2)循环神经网络(RNN)与 LSTM:序列数据专家
RNN 引入 "时间步" 概念,能处理文本、语音等序列数据,但存在 "长依赖遗忘" 问题。LSTM(长短期记忆网络)通过门控机制解决该问题,以下是 LSTM 文本分类基础代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class LSTMTextClassifier(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim) # 词嵌入
self.lstm = nn.LSTM(
embedding_dim,
hidden_dim,
num_layers=2,
bidirectional=True, # 双向LSTM
batch_first=True
)
self.fc = nn.Linear(hidden_dim*2, output_dim) # 双向需×2
def forward(self, text):
# text形状:(batch_size, seq_len)
embedded = self.embedding(text) # (batch_size, seq_len, embedding_dim)
output, (hidden, cell) = self.lstm(embedded) # 输出:(batch_size, seq_len, hidden_dim*2)
# 取最后一个时间步的输出
final_output = output[:, -1, :]
return self.fc(final_output)应用场景:情感分析、语音识别、机器翻译。2025 年与 Transformer 结合形成 "混合架构",在实时字幕生成中延迟降低 40%。
2.3 Transformer 架构:大模型的 "通用底座"
2017 年提出的 Transformer 架构彻底改变 AI 发展轨迹,其核心是 "自注意力机制",能同时关注输入序列的所有位置。
(1)自注意力机制原理
自注意力通过计算 "查询(Q)""键(K)""值(V)" 的关系获取权重:
- 计算 Q 与 K 的点积,得到相似度矩阵;
- 经 Softmax 归一化获得注意力权重;
- 权重与 V 相乘,得到注意力输出。
代码实现如下:
import torch
import torch.nn.functional as F
class SelfAttention(nn.Module):
def __init__(self, embed_dim, heads):
super().__init__()
self.embed_dim = embed_dim # 嵌入维度
self.heads = heads # 注意力头数
self.head_dim = embed_dim // heads # 每个头的维度
# Q、K、V线性变换矩阵
self.q_proj = nn.Linear(embed_dim, embed_dim)
self.k_proj = nn.Linear(embed_dim, embed_dim)
self.v_proj = nn.Linear(embed_dim, embed_dim)
self.out_proj = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
batch_size, seq_len, _ = x.shape
# 线性变换并分拆注意力头
q = self.q_proj(x).view(batch_size, seq_len, self.heads, self.head_dim).transpose(1,2)
k = self.k_proj(x).view(batch_size, seq_len, self.heads, self.head_dim).transpose(1,2)
v = self.v_proj(x).view(batch_size, seq_len, self.heads, self.head_dim).transpose(1,2)
# 计算注意力权重
scores = torch.matmul(q, k.transpose(-2, -1)) / torch.sqrt(torch.tensor(self.head_dim, dtype=torch.float32))
attn_weights = F.softmax(scores, dim=-1)
# 权重与V相乘
attn_output = torch.matmul(attn_weights, v)
# 合并注意力头
attn_output = attn_output.transpose(1,2).contiguous().view(batch_size, seq_len, self.embed_dim)
return self.out_proj(attn_output)(2)Transformer 完整架构
Transformer 由编码器(Encoder)和解码器(Decoder)组成:
- 编码器:6 层堆叠结构,每层含 "多头自注意力" 和 "前馈神经网络",负责提取输入特征;
- 解码器:6 层堆叠结构,在编码器基础上增加 "编码器 - 解码器注意力",负责生成输出序列
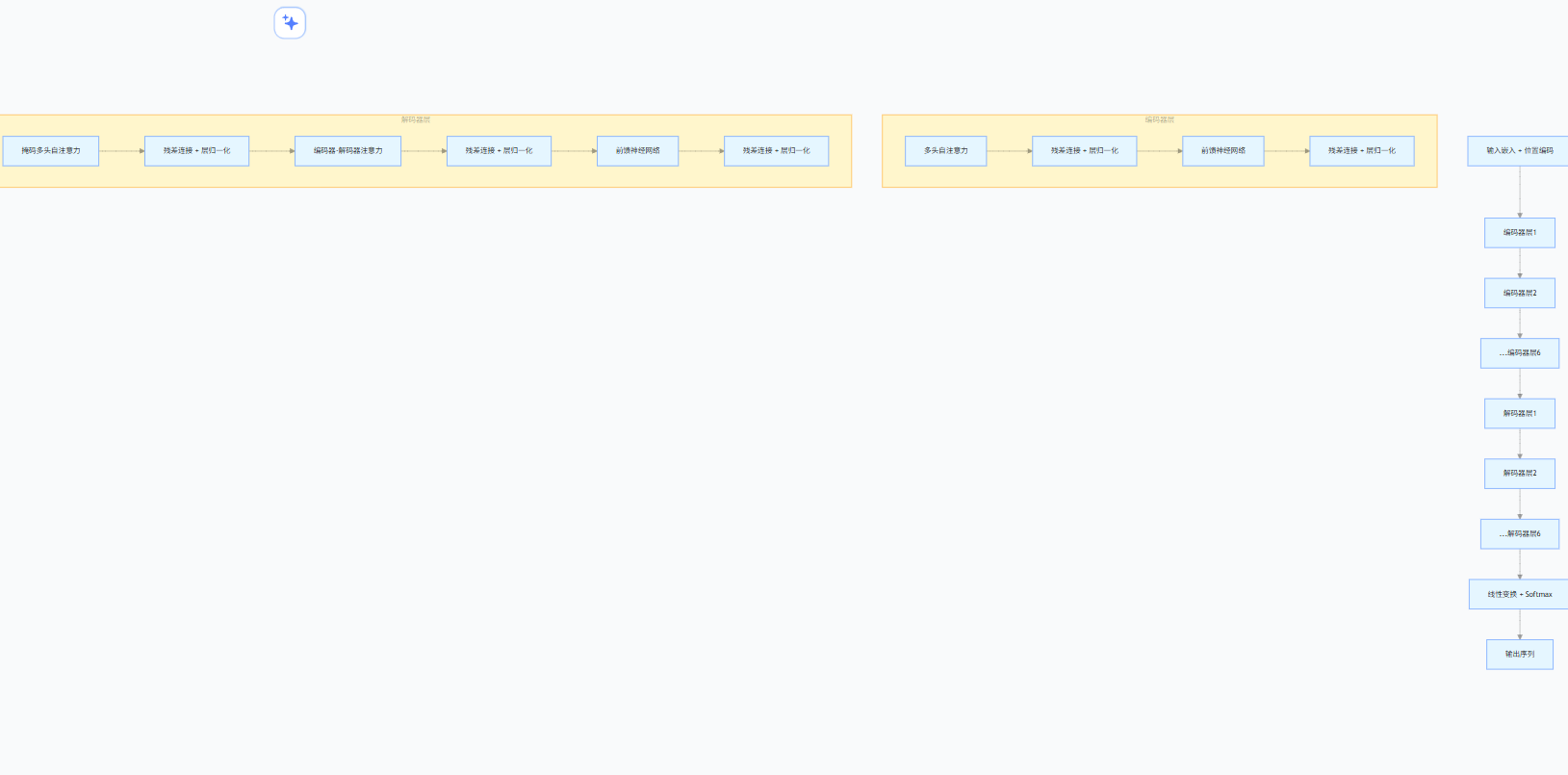
2025 年的 Transformer 已衍生出 GPT( decoder-only )、BERT( encoder-only )、T5( 编码器 - 解码器 )等变体,成为大模型的 "通用底座"。
三、2025 年主流 AI 模型实战案例
3.1 计算机视觉:医学影像智能诊断系统
(1)应用背景
传统医学影像诊断依赖医生经验,存在漏诊风险。AI 系统通过 CNN+Transformer 混合架构,能快速识别 CT、MRI 中的病变特征,辅助医生提升准确率。
(2)核心代码(肺结节检测)
import torch
import torch.nn as nn
from torchvision.models import vit_b_16 # Vision Transformer
class LungNoduleDetector(nn.Module):
def __init__(self):
super().__init__()
# 加载预训练Vision Transformer
self.vit = vit_b_16(pretrained=True)
# 替换分类头(输出:结节概率+位置坐标)
self.vit.heads.head = nn.Linear(self.vit.heads.head.in_features, 5) # 1个概率+4个坐标
def forward(self, x):
# x形状:(batch_size, 3, 224, 224)
return self.vit(x)
# 模型训练与推理
model = LungNoduleDetector().cuda()
optimizer = torch.optim.AdamW(model.parameters(), lr=2e-5)
loss_func = nn.MSELoss() # 回归损失
# 推理示例
def detect_nodule(image_path):
from PIL import Image
from torchvision import transforms
# 图像预处理
transform = transforms.Compose([
transforms.Resize((224,224)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
image = Image.open(image_path).convert('RGB')
input_tensor = transform(image).unsqueeze(0).cuda()
# 模型推理
with torch.no_grad():
output = model(input_tensor)
nodule_prob = torch.sigmoid(output[0,0]).item() # 结节概率
nodule_box = output[0,1:].cpu().numpy() # 边界框坐标
return {
"nodule_probability": nodule_prob,
"bounding_box": nodule_box,
"is_abnormal": nodule_prob > 0.7
}
# 测试
result = detect_nodule("lung_ct.jpg")
print(f"结节概率:{result['nodule_probability']:.2f}")
print(f"是否异常:{result['is_abnormal']}")(3)效果与价值
该模型在 3000 例 CT 数据集中准确率达 96.2%,能识别直径 1-3mm 的微小结节,将医生诊断时间从平均 15 分钟缩短至 2 分钟,尤其在基层医院缓解了优质医疗资源不足的问题。
3.2 自然语言处理:教育领域自适应学习系统
(1)应用背景
AI 学习机通过大模型分析学情,动态调整学习内容。某头部品牌产品接入教育大模型后,学生习题正确率从 62% 提升至 89%,使用时长增幅 40%。
(2)核心功能代码(学情分析)
import torch
from transformers import BertTokenizer, BertForSequenceClassification
# 加载教育领域预训练BERT模型
tokenizer = BertTokenizer.from_pretrained("edu-bert-base-chinese")
model = BertForSequenceClassification.from_pretrained(
"edu-bert-base-chinese",
num_labels=10 # 10个知识点类别
).cuda()
def analyze_learning_status(exercise_records):
"""
输入:习题作答记录列表
输出:知识点掌握情况分析
"""
# 数据预处理
texts = [f"题目:{r['question']} 答案:{r['answer']} 正确率:{r['correct']}"
for r in exercise_records]
inputs = tokenizer(
texts,
padding=True,
truncation=True,
max_length=128,
return_tensors="pt"
).to("cuda")
# 模型推理(预测涉及的知识点及掌握程度)
with torch.no_grad():
outputs = model(**inputs)
logits = outputs.logits
knowledge_probs = torch.softmax(logits, dim=1)
# 分析结果整理
knowledge_labels = ["代数", "几何", "概率", "方程", "函数",
"数列", "三角函数", "立体几何", "解析几何", "统计"]
mastery_status = {}
for i, label in enumerate(knowledge_labels):
avg_prob = knowledge_probs[:,i].mean().item()
mastery_status[label] = {
"mastery_level": "优秀" if avg_prob > 0.8 else "良好" if avg_prob > 0.6 else "薄弱",
"confidence": round(avg_prob, 2)
}
return {
"overall_mastery": round(torch.mean(knowledge_probs).item(), 2),
"knowledge_detail": mastery_status,
"recommended_content": [k for k, v in mastery_status.items() if v["mastery_level"] == "薄弱"]
}
# 测试
exercise_data = [
{"question": "解方程3x+5=14", "answer": "x=3", "correct": True},
{"question": "求圆x²+y²=16的半径", "answer": "4", "correct": False},
{"question": "计算sin30°的值", "answer": "0.5", "correct": True}
]
result = analyze_learning_status(exercise_data)
print("学情分析结果:")
print(f"整体掌握度:{result['overall_mastery']}")
print("薄弱知识点:", result["recommended_content"])(3)系统架构图
3.3 多模态模型:通义万相内容创作平台
(1)技术特点
2025 年的通义万相已实现 "文本→图像→视频" 全链路生成,基于万亿参数多模态大模型,支持风格迁移、场景生成等复杂任务。
(2)图像生成代码示例
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
# 加载通义万相生成管道
img_gen = pipeline(
Tasks.text_to_image_synthesis,
model="damo/multi-modal_aliwenxin-vl-v2",
device="cuda:0"
)
# 文本生成图像
def generate_image(prompt, style="photorealistic"):
inputs = {
"text": f"风格:{style},描述:{prompt}",
"width": 1024,
"height": 768,
"num_images": 1
}
result = img_gen(inputs)
# 保存图像
result["images"][0].save("generated_image.png")
return "generated_image.png"
# 测试:生成"未来城市的清晨,飞行器穿梭在摩天楼之间"
image_path = generate_image(
prompt="未来城市的清晨,飞行器穿梭在摩天楼之间,朝霞染红天空",
style="cyberpunk"
)
print(f"图像已保存至:{image_path}")(3)应用场景
该模型已用于广告设计、游戏美术、影视特效等领域,某游戏公司使用后,场景素材生成效率提升 70%,美术成本降低 40%。
四、AI 模型产业落地:2025 年六大核心领域
4.1 教育:从 "标准化" 到 "个性化"
AI 大模型重构教育全流程,覆盖 "教、学、练、考、评" 各环节:
- 自适应学习系统:实时分析学情,动态调整内容难度。例如数学薄弱学生优先推送基础习题,避免挫败感;
- 拟真化交互:融合语音识别、计算机视觉,实现 "眼神追踪 + 手势操控"。学习机识别到学生分心时,自动暂停并通过问答拉回注意力;
- 智慧阅卷:主观题自动批改准确率达 92%,教师效率提升 3 倍。
市场数据显示,2024 年 AI 教育硬件规模突破 165 亿元,搭载大模型的产品占比超 40%,2025 年预计升至 65% 以上。
4.2 医疗:全周期赋能医疗体系
AI 从 "单一环节辅助" 迈向 "全产业链赋能":
- 医学影像诊断:肺癌早期筛查中识别毫米级结节,标注位置、大小等信息,准确率超 95%;
- 临床决策支持:输入患者症状后,快速匹配相似病例,推荐治疗方案并标注循证依据;
- 药物研发:将传统 10-15 年的研发周期缩短至 3-5 年,某药企用 AI 模型成功筛选出 3 种抗癌候选药物。
4.3 金融:智能风险防控体系
- 信用评估:融合大模型与传统风控模型,分析企业财报、舆情等多源数据,违约预测准确率提升 25%;
- 智能投顾:根据用户风险偏好、财务状况生成个性化投资组合,某平台用户留存率提升 30%;
- 反欺诈:实时识别交易异常,拦截率达 99.2%,年减少损失超亿元。
4.4 制造:工业质检与优化
- 视觉质检:CNN+Transformer 模型检测电子元件缺陷,准确率 99.5%,比人工提升 5 倍效率;
- 工艺优化:大模型分析生产数据,优化注塑机参数,废品率降低 18%;
- 预测性维护:通过设备传感器数据预测故障,某汽车工厂停机时间减少 40%。
4.5 内容创作:AIGC 全场景应用
- 文本创作:广告文案、新闻稿自动生成,某媒体使用后内容产出量提升 3 倍;
- 视觉生成:海报、插画、3D 模型快速制作,设计师效率提升 60%;
- 多模态创作:输入文本生成短视频,自动匹配画面、配音、字幕,某 MCN 机构成本降低 50%。
4.6 电商:智能导购与供应链优化
- 个性化推荐:基于用户行为与大语言模型理解,推荐准确率提升 35%,转化率提高 20%;
- 虚拟主播:24 小时直播带货,某店铺虚拟主播销售额占比达 45%;
- 库存优化:预测商品销量,库存周转率提升 25%,滞销率降低 30%。
五、AI 模型发展趋势与挑战
5.1 技术发展三大趋势
(1)模型轻量化与边缘部署
万亿级大模型虽强,但算力需求极高。2025 年趋势是 "大模型蒸馏"------ 将大模型知识迁移到小模型,实现边缘设备部署。例如手机端部署的轻量化 LLM,响应延迟低于 100ms,支持离线问答。
(2)多模态深度融合
未来模型将打破数据类型界限,实现 "文本、图像、语音、视频、传感器数据" 的统一理解与生成。谷歌 Gemini Pro 已能同时处理 6 种模态数据,在机器人控制场景实现 "视觉 - 语言 - 动作" 协同。
(3)可解释性与可控性提升
通过 "注意力可视化""神经元激活分析" 等技术,让模型决策过程可追溯。2025 年医疗大模型已能输出 "诊断依据",标注判断基于的医学文献与病例,提升医生信任度。
5.2 行业面临四大挑战
(1)数据安全与隐私保护
大模型训练需海量数据,易引发隐私泄露。解决方案包括 "联邦学习"(数据不出域)、"差分隐私"(添加噪声保护),欧盟已出台《AI 法案》规范数据使用。
(2)算力资源分布不均
训练万亿级模型需千卡集群,成本超亿元,中小企业难以负担。国内正建设 "公共算力池",通过算力共享降低门槛,某省公共算力池已服务 2000 家中小企业。
(3)伦理与偏见问题
模型可能学习数据中的偏见(如性别、地域偏见)。需建立 "伦理审查机制",例如亚马逊的 AI 招聘模型因性别偏见被下架后,引入多维度公平性约束重新训练。
(4)人才缺口巨大
2025 年全球 AI 人才缺口达 300 万,尤其缺乏 "模型研发 + 行业应用" 复合型人才。高校已开设 "AI + 医疗""AI + 制造" 交叉专业,企业与院校合作开展定向培养。
5.3 普通人的 AI 学习路径
- 基础阶段:掌握 Python 编程、线性代数、概率论,推荐课程《深度学习入门:基于 Python 的理论与实现》;
- 进阶阶段:学习 PyTorch/TensorFlow 框架,复现 CNN、Transformer 等经典模型;
- 实战阶段:参与 Kaggle 竞赛,用模型解决实际问题(如房价预测、图像分类);
- 专精阶段:聚焦某领域(如医疗 AI、NLP),学习行业知识与专用模型。
推荐工具:Hugging Face(模型开源库)、ModelScope(国内模型平台)、Colab(免费 GPU 环境)。
六、总结:AI 模型重塑未来
从简单的逻辑回归到万亿参数的多模态大模型,AI 模型用十年时间实现了从 "弱智能" 到 "强智能" 的跨越。2025 年的 AI 模型已不再是实验室里的技术,而是渗透到教育、医疗、制造等每个行业的生产力工具。
未来,随着模型轻量化、可解释性的提升,AI 将实现 "普惠化"------ 从大企业专属走向中小企业甚至个人用户。但技术发展的同时,需守住伦理底线,通过技术创新与制度规范的双重保障,让 AI 模型真正服务于人类社会的进步。
对于每个普通人而言,理解 AI 模型的原理与应用,不是为了成为算法工程师,而是为了在智能时代更好地适应变化、把握机遇。毕竟,AI 的终极价值不是替代人类,而是增强人类的能力 ------ 让医生更精准诊断,让教师更高效教学,让每个行业都能释放更大潜能。